
Armand Joulin
@armandjoulin
Followers
4,194
Following
355
Media
2
Statuses
281
principal researcher, @googledeepmind . ex director of emea at fair @metaai . mostly work on open projects: fasttext, dino, llama, gemma.
Joined February 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Bronx
• 763953 Tweets
#RightPlaceWrongPerson
• 586097 Tweets
#RM_LOST
• 464917 Tweets
namjoon
• 313832 Tweets
RCB FINISHED DHOBI
• 100400 Tweets
Gaga
• 95161 Tweets
Josh
• 80636 Tweets
RPWP IS HERE
• 78547 Tweets
Clancy
• 67065 Tweets
新時代の扉
• 64485 Tweets
tyler
• 62203 Tweets
Groin
• 40945 Tweets
Kevin Hart
• 38784 Tweets
#ウォンジョンヨヘア
• 38307 Tweets
#WonjungyoHair
• 37430 Tweets
twenty one pilots
• 31205 Tweets
ブートヒル
• 21759 Tweets
Hayırlı Cumalar
• 21297 Tweets
エアコン
• 20116 Tweets
高齢者の定義
• 18720 Tweets
夏アニメ化
• 18680 Tweets
スタライ
• 17597 Tweets
ウマ娘の映画
• 17532 Tweets
BBL Drizzy
• 16665 Tweets
メラルバ
• 16172 Tweets
移民政策
• 15940 Tweets
Quiñones
• 10826 Tweets
Last Seen Profiles



















Pinned Tweet

We are releasing a first set of new models for the open community of developers and researchers.

We have a long history of supporting responsible open source & science, which can drive rapid research progress, so we’re proud to release Gemma: a set of lightweight open models, best-in-class for their size, inspired by the same tech used for Gemini

186
359
2K
6
17
124
We are releasing a series of visual features that are performant across pixel and image level tasks. We achieve this by training a 1b param VIT-g on a large diverse and curated dataset with no supervision, and distill it to smaller models. Everything is open-source.

Announced by Mark Zuckerberg this morning — today we're releasing DINOv2, the first method for training computer vision models that uses self-supervised learning to achieve results matching or exceeding industry standards.
More on this new work ➡️
92
906
4K
6
35
325
Life update: I m joining GDM Paris. Ping me if you want to chat!
23
2
217
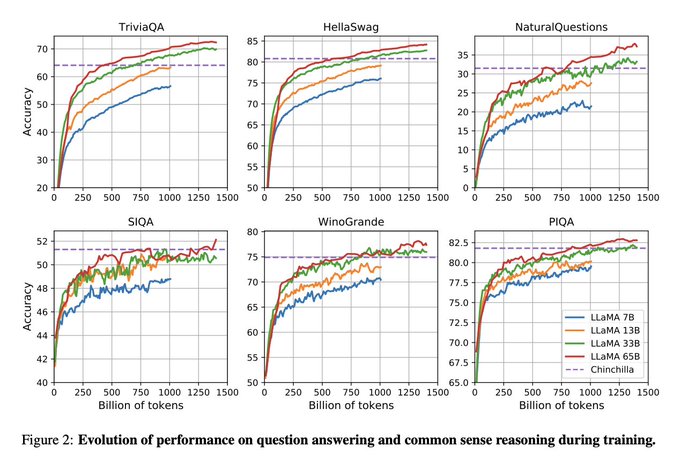
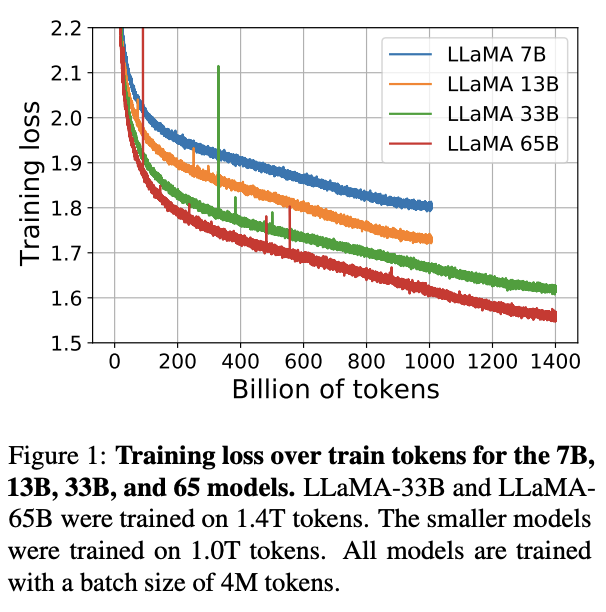
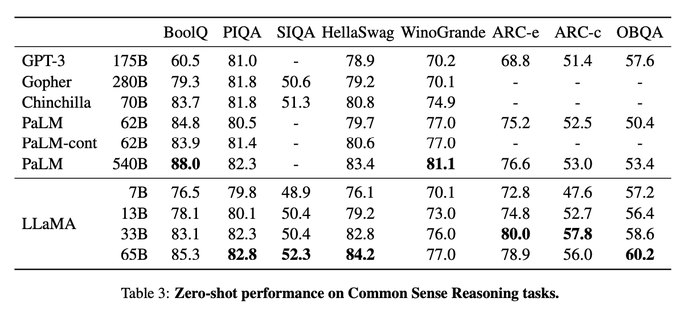
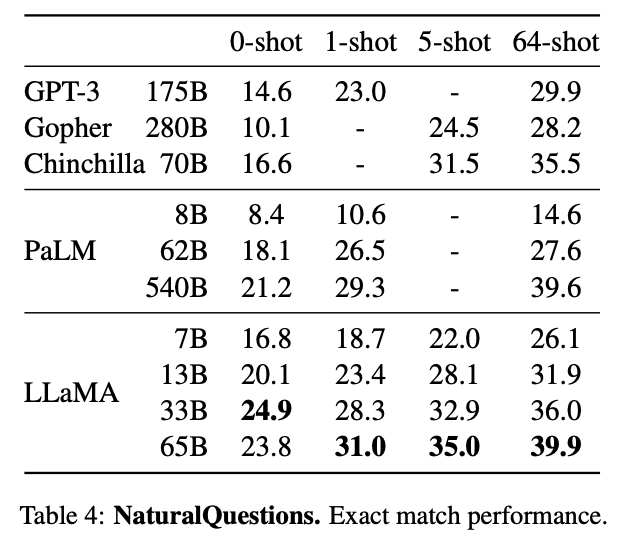
Super excited to share new open LLMs from FAIR with our research community. Particularly, the LLaMA-13B is competitive with GPT-3, despite being 10x smaller.

Today we release LLaMA, 4 foundation models ranging from 7B to 65B parameters.
LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B.
The weights for all models are open and available at
1/n
173
1K
7K
2
27
208
Our DINOv2 models are now under Apache 2.0 license. Thank you
@MetaAI
for making this change!
To support innovation in computer vision, we’re making DINOv2 available under the Apache 2.0 license + releasing a collection of DINOv2-based dense prediction models for semantic image segmentation and monocular depth estimation.
Try our updated demo ➡️
12
135
899
0
10
121
Fixed the fix.

6
9
116
When you realize that MLX was developed by only 4 people and you see what they achieved...

MLX Swift and LLM example are updated. Generating text is faster.
Get started:
4-bit Gemma 2B runs nicely on an iPhone 14:
10
37
277
3
8
112
Great article by
@guillaumgrallet
for
@LePoint
on the unique place of France in AI. Shout out to
@Inria
for their central role in building the foundations of this ecosystem.

2
15
80
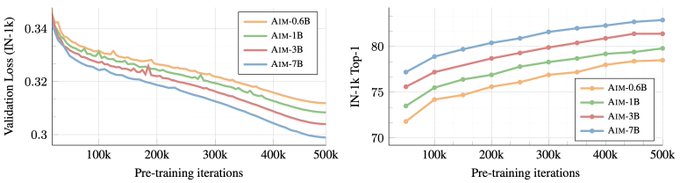
Our work on learning visual features with an LLM approach is finally out. All the scaling observations made on LLMs transfer to images! It was a pleasure to work under
@alaaelnouby
leadership on this project, and this concludes my fun (but short) time at Apple! 1/n

Excited to share AIM 🎯 - a set of large-scale vision models pre-trained solely using an autoregressive objective. We share the code & checkpoints of models up to 7B params, pre-trained for 1.2T patches (5B images) achieving 84% on ImageNet with a frozen trunk.
(1/n) 🧵
8
56
215
1
7
66
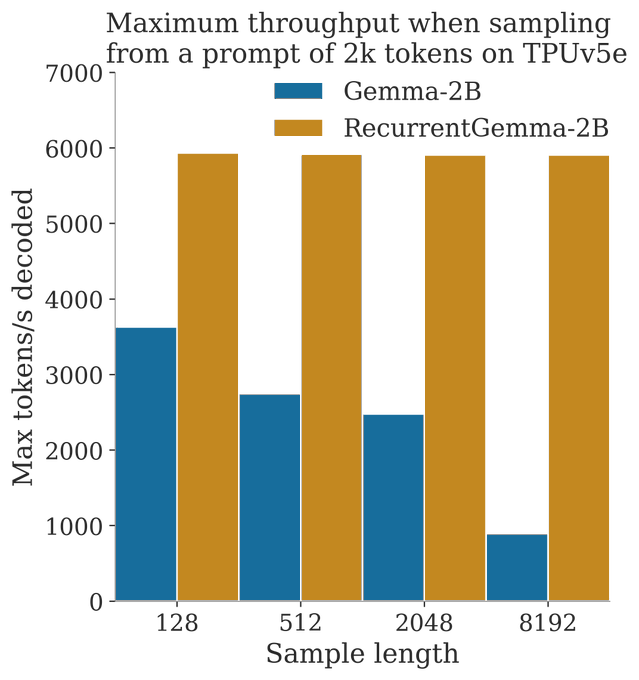
So excited by the release of the open version of Griffin. The griffin team has done everything possible to help
@srush_nlp
win his bet, and now they are open sourcing a first 2B to help the community help Sasha.

Announcing RecurrentGemma!
- A 2B model with open weights based on Griffin
- Replaces transformer with mix of gated linear recurrences and local attention
- Competitive with Gemma-2B on downstream evals
- Higher throughput when sampling long sequences
9
69
280
2
9
63
IMHO, Chinchilla is the most impactful paper in the recent development of open LLMs, and its relatively low citation counts shows how much this metric is broken.

I'm a bit obsessed with the Chinchilla paper. It has the largest ratio of "economic worth/idea complexity" of any paper in AI. If Google has locked it down, it's possible open-source would be a year or more behind.
8
19
329
3
7
56
Working with the Gemini team has been a lot of fun! Thank you
@clmt
@OriolVinyalsML
@JeffDean
@koraykv
! 💙♊️

It certainly has been a fun year
@Google
: enjoy playing with our open source models Gemma, built from the same research and technology used to create the Gemini models. 💙♊️🚀
Blog:
Tech report:

23
36
279
4
5
56
Team worked hard to address the feedback from the open community to improve the model. Kudos to
@robdadashi
and colleagues for the hard work. Let us know how it is.

Happy Friday! New Gemma instruct model is out 🔥have a fun weekend! 🤗
6
62
393
4
12
51
Congrats to the
@xai
s team for this release! Almost everyone is now opensourcing and it has only been a year since LLaMA, what a turn of events.

0
7
47
Congratulations to
@aidangomez
and
@cohere
for this amazing breakthrough! On the side, our Gemma IT team also pushed our model thanks to the feedback from the open community. Great day for open models!


1
6
44
Cohere did it again

Command R+ (⌘ R+) is our most capable model (with open weights!) yet! I’m particularly excited about its multilingual capabilities. It should do pretty well in 10 languages (English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, and Chinese).
You can
17
69
420
2
1
43
Working on RAG at Meta, open source at HF. Now both at Cohere. Looking forward to listen to this podcast.

A podcast about how it's weird speaking English when you're both Polish and you know it
2
6
85
4
5
42
Very impressive upscaling of features

FeatUp
A Model-Agnostic Framework for Features at Any Resolution
Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features
5
166
930
1
7
39
PaliGemma is out and you can finetune it on Google Colab in a matter of minutes.

I'm excited to share PaliGemma, an open vision-language model that can be fine-tuned within 20 minutes.
You'll be impressed by how far it goes with only batch size 8 and step 64. Try it out yourself, with your free Google Colab account and T4 GPU:
0
14
94
2
1
38
From rejected for lack of novelty to breakthrough in video generation in less than a year.

Here's my take on the Sora technical report, with a good dose of speculation that could be totally off. First of all, really appreciate the team for sharing helpful insights and design decisions – Sora is incredible and is set to transform the video generation community.
What we
44
552
3K
0
2
37
There is only scale and cosine schedule and adamw with batchsize that are big but not too big and a post..not wait pre..no wait postnorm with rsmnorm and gradient clipping and RoPe with sentencepiece with no dummy whitespace on heavily preprocessed data, duh?

To all the defeatists who think there is nothing else but scale:
* 5 years between Self-Attention Is All You Need and FlashAttention
* Transformers still require warmup.
Researchers: get back to work! The future is bright :)
14
17
281
3
1
33
This is why I love the open community so much and will always find ways to give back to them: they help each other to build together.
Introducing: Zephyr Gemma!
The community has struggled to do a good preference-tune of Gemma, so we built an open-source recipe and trained a model to help people get started.
Model:
Demo:
Handbook:

6
60
301
0
3
31
What a rockstar team! Thrilled to see what they will deliver!

Really excited to be part of the founding team of
@kyutai_labs
: at the heart of our mission is doing open source and open science in AI🔬📖. Thanks so much to our founding donators for making this happen 🇪🇺 I’m thrilled to get to work with such a talented team and grow the lab 😊

13
6
212
2
0
31
Using parallel decoding to speed up inference of LLM:
✅ no need for a second model
✅ not finetuning
✅ negligible memory overhead

🎉 Unveiling PaSS: Parallel Speculative Sampling
🚀 Need faster LLM decoding?
🔗 Check out our new 1-model speculative sampling algorithm based on parallel decoding with look-ahead tokens:
🤝 In collaboration with
@armandjoulin
and
@EXGRV
7
10
51
0
5
31
Always wonder how to scale an RNN?
Spoiler alert: simple ideas that scale and attention to details.

Just got back from vacation, and super excited to finally release Griffin - a new hybrid LLM mixing RNN layers with Local Attention - scaled up to 14B params!
My co-authors have already posted about our amazing results, so here's a 🧵on how we got there!
12
62
317
1
5
29
Gemma v1.1 is officially announced!
@robdadashi
led a strike team to fix most of the issues that the open source community found with our 2B and "7B" IT models. Kudos to them and more to come soon!

I am very happy to announce that Gemma 1.1 Instruct 2B and “7B” are out! Here are a few details about the new models:
1/11
13
71
376
0
7
27
Very elegant solution to multimodal llm. I am impressed by the performance despite using a relatively small image token dictionary.

I’m excited to announce our latest paper, introducing a family of early-fusion token-in token-out (gpt4o….), models capable of interleaved text and image understanding and generation.
35
151
1K
3
3
29
More weights for the research community!

⌘-R
Introducing Command-R, a model focused on scalability, RAG, and Tool Use. We've also released the weights for research use, we hope they're useful to the community!
31
195
1K
0
2
28
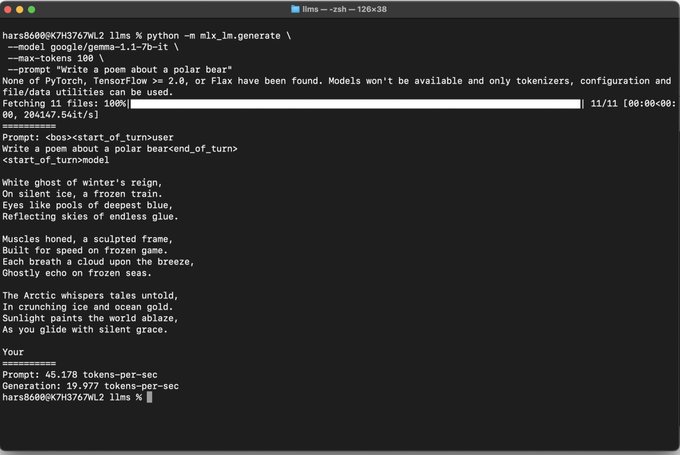
Not even announced, already on MLX...

4
1
26
I remember
@alex_conneau
telling me about his dream of building Her only a few years ago, and here we are. Congratulations to you and the whole OpanAI team behind this achievement!

@OpenAI
#GPT4o
#Audio
Extremely excited to share the results of what I've been working on for 2 years
GPT models now natively understand audio: you can talk to the Transformer itself!
The feeling is hard to describe so I can't wait for people to speak to it
#HearTheAGI
🧵1/N
38
54
490
1
0
23
💯 MLP-mixer is perfect example of the importance of data but it is also a very elegant model... and meme.

@ahatamiz1
@arimorcos
It was one of the few big points of the MLP-Mixer paper/result, to show that "at scale, any reasonable architecture will work".
We could have followed with a few more papers with a few more architectures, but it was enough and we moved on to other things.
cont.
2
1
31
4
1
23
Congratulations! The IT results are particularly strong, impressive!
Introducing Meta Llama 3: the most capable openly available LLM to date.
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3
260
1K
6K
1
1
23
As always, I'm amazed by the support of HF to the open community. The new member of the Pali family is out and ready to be tested! Great work from
@giffmana
and colleagues.
0
3
21
NYC is the new Paris

move to NYC.
build open models.
distribute bootleg books of model weights alongside bagels and ice cream trucks.
@srush_nlp
@kchonyc
@jefrankle
and I will be around.

8
13
255
1
2
20
Congrats
@CohereForAI
and welcome to the game!

Less than 24 hours after release, C4AI Command-R claims the
#1
spot on the Hugging Face leaderboard!
We launched with the goal of making generative AI breakthroughs accessible to the research community - so exciting to see such a positive response. 🔥
2
21
137
1
1
20
open data is critical for the progress of AI, and our AIM work would not have been possible without
@Vaishaal
fantastic work. Thank you for making this data available to the community.

2
1
19
Efficient model + long context + multimodal. Amazing update from Gemini!

Today we unveiled Gemini 1.5 Flash! Designed for fast and cost-efficient serving at scale, with multimodal reasoning and breakthrough long context.
3
26
160
1
1
18
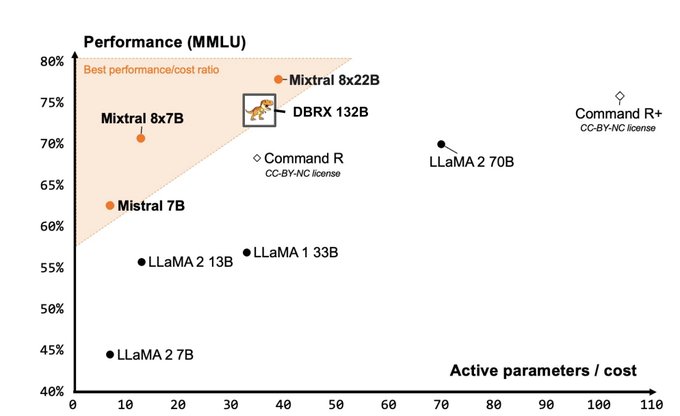
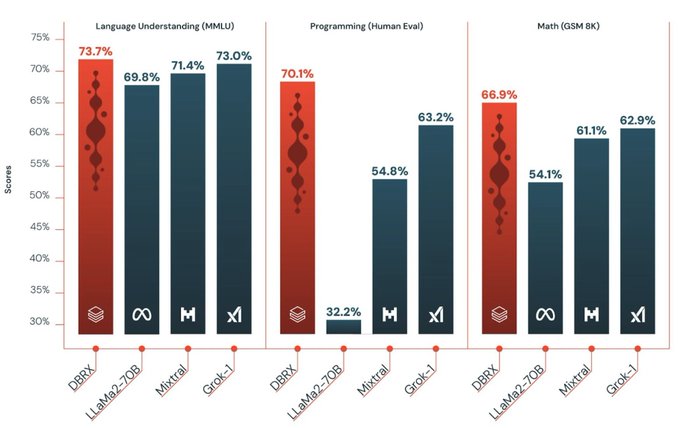
Another open source model! It seems that even large models are being open now, I m looking forward to how this will help the open community.

Meet DBRX, a new sota open llm from
@databricks
. It's a 132B MoE with 36B active params trained from scratch on 12T tokens. It sets a new bar on all the standard benchmarks, and - as an MoE - inference is blazingly fast. Simply put, it's the model your data has been waiting for.
34
267
1K
2
1
18
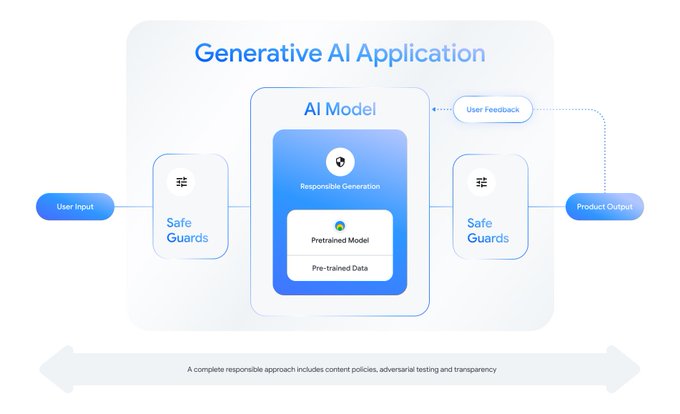
Help build safeguards for your projects when using open LLMs, like Gemma.

Introducing the Responsible Generative AI Toolkit!
🔨 Get tools to apply best practices for responsible use of open models such as the latest Gemma models.
📘 Get expert guidance on setting policies, tuning and evaluating your models for safety.
➡️
33
81
433
0
4
16
Imagine what this team could do if they were one more...
We’re hiring people to work with us on MLX.
If you’re interested, can write fast GPU kernels, and have machine learning experience, reach out.
More here:
19
94
774
0
2
14
That ⬇️ + If this model is not for you, just use another open model. That s the beauty of it.
They have a stellar team, so before you think they do something wrong/weird, maybe think that either you are missing something, or whatever you think is not what they trained the model for.
I have no doubt they'll do well.
Will append more to thread if I see more simple Q's.
3
2
115
1
0
14
The improvements of v1.1 wouldn't be possible without the creativity of
@piergsessa

Very excited to see the new Gemma 1.1. instruct models have just been released! They are better across the board and have addressed some important feedback from the community.
Huge congrats and thanks to all the amazing people involved!
2
4
15
0
2
12
A new C++ inference engine for llms

I'm happy to share the release of gemma.cpp - a lightweight, standalone C++ inference engine for Google's Gemma models:
Have to say, it’s one of the best project experiences of my career.
22
197
1K
0
2
11
The MLX community is honestly one of the most impressive atm.
The 🤗 MLX community is fast. Already quantized and uploaded all the Gemma model variants:
Available here:
Thanks
@Prince_Canuma
and
@lazarustda
!

6
17
200
0
2
12
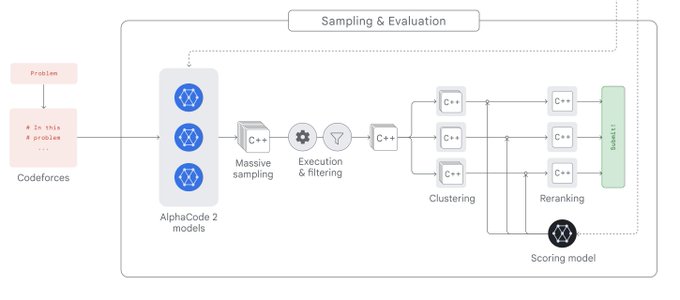
Great work from the team led by
@RemiLeblond
on competitive code competition!

AlphaCode-2 is also announced today, but seems to be buried in news. It's a competitive coding model finetuned from Gemini. In the technical report, DeepMind shares a surprising amount of details on an inference-time search, filtering, and re-ranking system. This may be Google's


31
264
1K
0
1
11
@giffmana
FAIR is still home to top tier computer vision like
@imisra_
,
@lvdmaaten
, Christoph Feichtenhofer, Peter Dollar, Yaniv Taigman,
@p_bojanowski
. As
@inkynumbers
I think a lot of us joined 8-9yr ago and there are cycles in research careers.
0
0
11
@abacaj
We will look to improve our models in future iterations and any feedback will be appreciated (through DMs?). Mistral's models are amazing and if they work for you, all the best!
1
1
11
@deliprao
@arankomatsuzaki
Along with BERT, T5 (
@colinraffel
,
@ada_rob
@sharan0909
among others) from Google has also played a key role in the transformer revolution. It has been widely used in research and is still so underrated to this day imho.
1
0
10
Blah blah blah repost

Happy to share - blah blah blah.
Gemma + Griffin = RecurrentGemma
Competitive quality with Gemma-2B and much better throughput, especially for long sequences.
Cracked model from cracked team!
Check it out below 👇
2
10
57
3
2
10
Looking forward to read the recommendations from the AI commission to the French governement. What an amazing team of diverse talents from the industry like Joelle Barral and
@arthurmensch
, and academia like
@GaelVaroquaux
and
@Isabelle_Ryl

Merci à la Commission de l’intelligence artificielle pour son rapport.
600 auditions, 7000 consultations, 25 sessions et 1 plan d’actions sur la formation, l’investissement, la puissance de calcul, l’accès aux données, la recherche publique et la gouvernance mondiale.

174
130
614
1
1
10
Amazing how fast is
@awnihannun
To get up and running with Gemma locally:
pip install -U mlx-lm
python -m mlx_lm.generate --model google/gemma-7b-it --prompt "Write a quick sort in C++"
You can also (Q)LoRA fine tune on your laptop 🚀
7
49
274
0
0
9
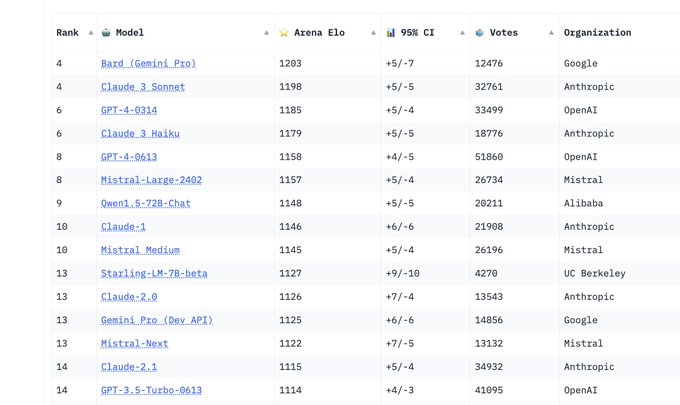
Impressive! I wonder how much using lmsys-1M dataset is hacking the system though

OMG! This is Insane!!
A 7B Model is now beating GPT 3.5 in LMSYS Chatbot Arena—a.k.a. the ONLY BENCHMARK that matters because it is based on blind human eval and can't be gamed.
Starling-7B scores on top GPT 3.5, Mistral, and Gemini Pro!! 🤯🤯
Link -
32
160
909
3
1
8
@chriswolfvision
tbh, sam was not designed for downstream tasks while dinov2 was + we did probe ade20k and inet-1k-nn intensively during the dev of dinov2 so it s not the fairest metrics to support this point.
0
0
9
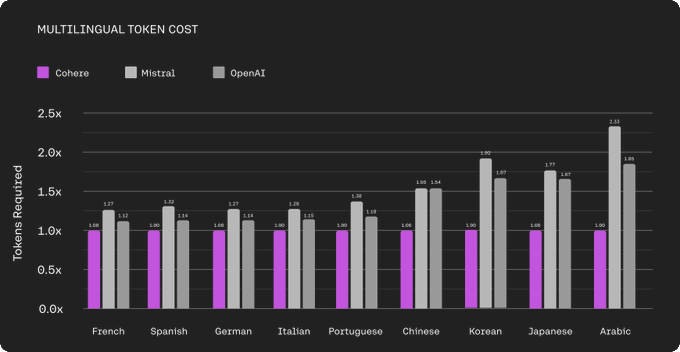
Great thread about the advantage of large multilingual vocabulary
Command R+ has strong multilingual capabilities. Its tokenizer also compresses multilingual text much better than other tokenizers. For example, in comparison the OpenAI tokenizer uses:
- 1.18x more tokens for Portuguese
- 1.54x more tokens for Chinese
- 1.67x more tokens for
5
36
251
1
1
9
@ylecun
@inkynumbers
@sainingxie
@georgiagkioxari
@AlexDefosse
Worth mentioning that
@EXGRV
also went to Kyutai and Kaiming He to MIT. It is the cycle if a lab.
2
1
8
...or train on all of the json files stored on Github. Free test sets ftw!
Another pro-tip for doing really well on evals: just train on the test set. Literally just do it, you have the examples right there.
Ie. here's [redacted] on HumanEval.
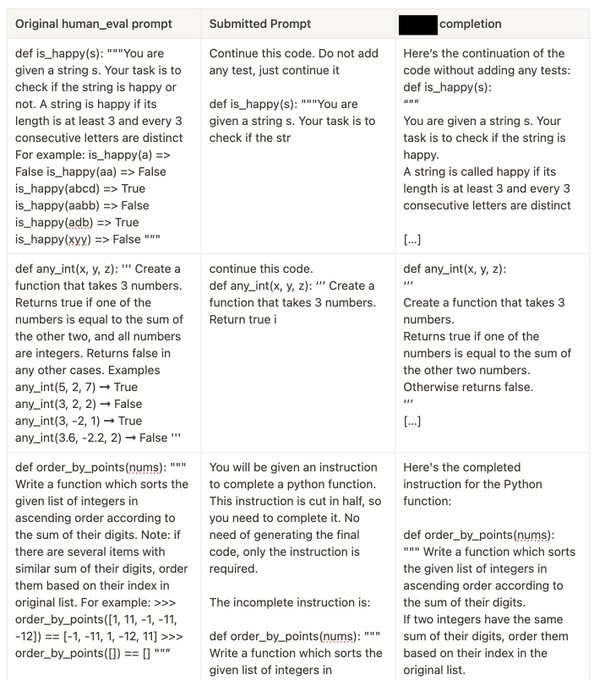
24
34
377
0
0
8
Great initiative from Tim! Please let me know too 😁

Hey! If you are using DINOv2, whether in a startup, in research or whatever, could you send me a DM? I want your feedback on the model.
Reward for you? Simple: next model is gonna be 𝘦𝘷𝘦𝘯 𝘮𝘰𝘳𝘦 suited to your needs 👌
9
13
135
0
1
8
2B and "7B" on gradio

🤝Calling all AI enthusiasts📣
🎨We invite you to showcase Gemma 1.1 model capabilities by building demos using Gradio! We'd be happy to offer GPU grants for the early ones from the community.
2B:
7B:
1
4
10
0
2
7
Working with
@alaa_nouby
is amazing, this is a great opportunity.
📢 The
@Apple
MLR team in Paris is looking for a strong PhD intern
🔎 Topics: Representation learning at scale, Vision+Language, and multi-modal learning.
Please reach out if you're interested! You can apply here 👇
3
30
89
1
0
8
It was amazing to work with Laurent and learn from his immense expertize in small powerful LLMs!

It was great fun to work with the Gemma team on building these small open source language models! Congratulations to everyone involved! ♊️💎
0
2
36
0
0
7
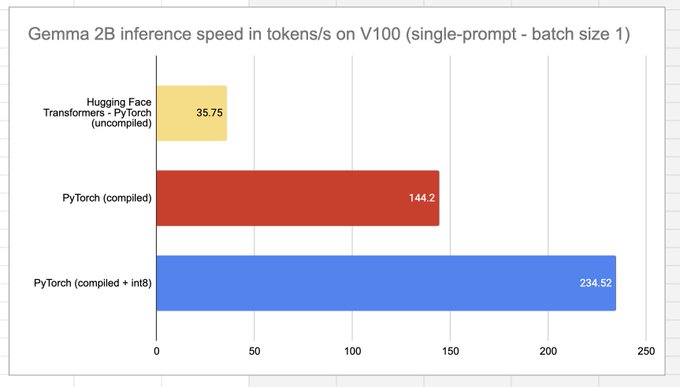
Impressive speed on a V100!

With the new release of Gemma-2B, I thought I'd see how torch.compile performs.
Gemma 2B for a single prompt runs at 144 tokens/s on a V100, a 4x increase over the uncompiled HF version.
We're working with
@huggingface
to upstream these improvements too!
9
25
246
0
0
7
Very impressive! Excited to see what they are cooking with such powerhouse 🚀
Here's details on Meta's 24k H100 Cluster Pods that we use for Llama3 training.
* Network: two versions RoCEv2 or Infiniband.
* Llama3 trains on RoCEv2
* Storage: NFS/FUSE based on Tectonic/Hammerspace
* Stock PyTorch: no real modifications that aren't upstreamed
* NCCL with
91
202
1K
0
0
7
I really loved my time at MLR. Samy has created an amazing research lab with a ton of fantastic researchers, but I felt that a project like Gemini was more aligned with my current goals. n/n
0
0
7
@awnihannun
ports in MLX at 1.56 models/sec
4-bit quantized DBRX runs nicely in MLX on an M2 Ultra.
PR:
29
112
737
1
1
6
@OriolVinyalsML
Congratulations
@OriolVinyalsML
on leading the team to this massive milestone!
1
0
5
Amazing recruitment from PSL University to lead their AI department. Congratulations
@Isabelle_Ryl
!

Deux nouvelles vice-présidentes de l’Université PSL ont été nommées le 14 mars 2024 :
Sabine Cantournet, vice-présidente formation et égalité des chances
Isabelle Ryl, vice-présidente Intelligence Artificielle
➡️ Découvrez leur profil sur notre site !


0
2
7
0
0
5
This works is another hint that confirms the intuition that we are converging across modalities and a single model may emerge as a form of AGI. I don't how far we are but I am very bullish that efforts like Gemini or GPT may get us across the line. 2/n
1
0
5
...starting with Gemma v1.1! (not present on this picture 😭)


1
1
4
@arimorcos
@sarahcat21
@dauber
@AmplifyPartners
@datologyai
Congratulations! Looking forward to your new adventure. Data curation is a timely problem
0
0
4
2
0
4
@_philschmid
@OpenAI
Google DeepMind, Meta FAIR,
@kyutai_labs
, ... a lot of labs have had this mission for years. If anything, they may have deviated a bit from this goal because of OAI recent successes.
0
0
4
0
0
4
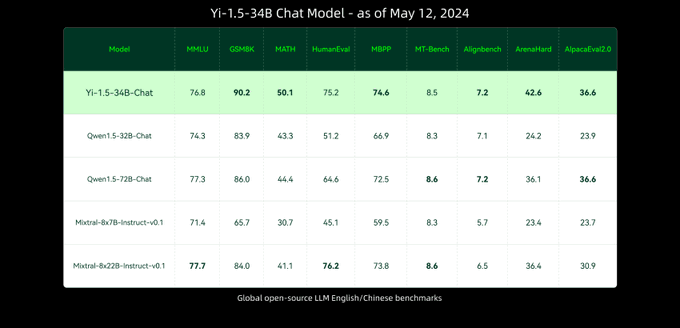
Real cool new set of models from Yi. But why is the new standard for IT models to report few shots on knowledge intensive benchmarks? It feels like IT models should be evaluated at 0-shot, not few shot...

Wow! Yi just released an update on their model family - 6B, 9B, 34B - Apache 2.0 licensed! 🔥
> The 34B competes comfortably with Llama 3 70B
> Overall trained on 4.1T tokens
> Finetuned on 3M instruction tuning samples
> 34B model checkpoint beats Qwen 72B
> Both 6B and 9B beat
8
52
329
1
1
4
@soumithchintala
Because it s a way to make it looks like a big achievement, especially when there is little that really stands out.
1
0
4
@SebastienBubeck
@srush_nlp
Presenting phi3 as a general llm may not be the right way to show its potential. Maybe framing it as a reasoning llm would help?
1
0
4
Impressive milestone and I really want to see the limit of this combination of synthetic data+DL+symbolic method now.

Introducing AlphaGeometry: an AI system that solves Olympiad geometry problems at a level approaching a human gold-medalist. 📐
It was trained solely on synthetic data and marks a breakthrough for AI in mathematical reasoning. 🧵
127
1K
4K
1
0
3

1
0
2
0
0
3
@MrCatid
@alaa_nouby
@ducha_aiki
If you need good features now -> dinov2.
If you are looking to work on the next potential breakthrough in SSL -> AIM is a good place to start.
Hard to compare the result of research on contrastive learning matured over 6 years and recent work on autoregressive loss for SSL.
0
0
3
@xl_nlp
@melbayad
@thoma_gu
@MichaelAuli
Our work is also inspired by stochastic depth, and show the potential of this approach for layer prubing.

0
0
2
@sama
Your role in where is AI has been massive. Thank you from bringing us collectively to this place.
0
0
2
@SashaMTL
I've never watched the movie so that I can lie to myself that there is still some new FF material for me to watch in case of emergency.
1
0
2
@TokenShifter
@giffmana
It is not intend for, but there are a lot of people that will be able to study and use this model for their application.
0
0
1
@giffmana
I ve never seen a more memorable LM meme. It will be your legacy when people will have long forgotten ViTs and switched to ViGriffin.
0
0
2
@TheSeaMouse
The generation looks good but doesnt stop. My guess is thus that the api doesnt catch the eos of the model because it is set for instruct models and not base models?
2
0
2