
Awni Hannun
@awnihannun
Followers
34K
Following
8K
Media
642
Statuses
4K
Just in time for the holidays, we are releasing some new software today from Apple machine learning research. MLX is an efficient machine learning framework specifically designed for Apple silicon (i.e. your laptop!). Code: Docs:
100
709
4K
DeepSeek R1 (the full 680B model) runs nicely in higher quality 4-bit on 3 M2 Ultras with MLX. Asked it a coding question and it thought for ~2k tokens and generated 3500 tokens overall:
161
582
6K
DeepSeek R1 671B running on 2 M2 Ultras faster than reading speed. Getting close to open-source O1, at home, on consumer hardware. With mlx.distributed and mlx-lm, 3-bit quantization (~4 bpw)
128
620
6K
If you want to really feel the future, take your iPhone out of its case and run a Deep Seek 7B reasoning model on it:

86
258
5K
DeepSeek R1 distilled to Qwen 1.5B easily runs on my iPhone 16 with MLX swift. Here's the 4-bit model reasoning entirely on device at almost 60 toks/sec:
92
371
4K
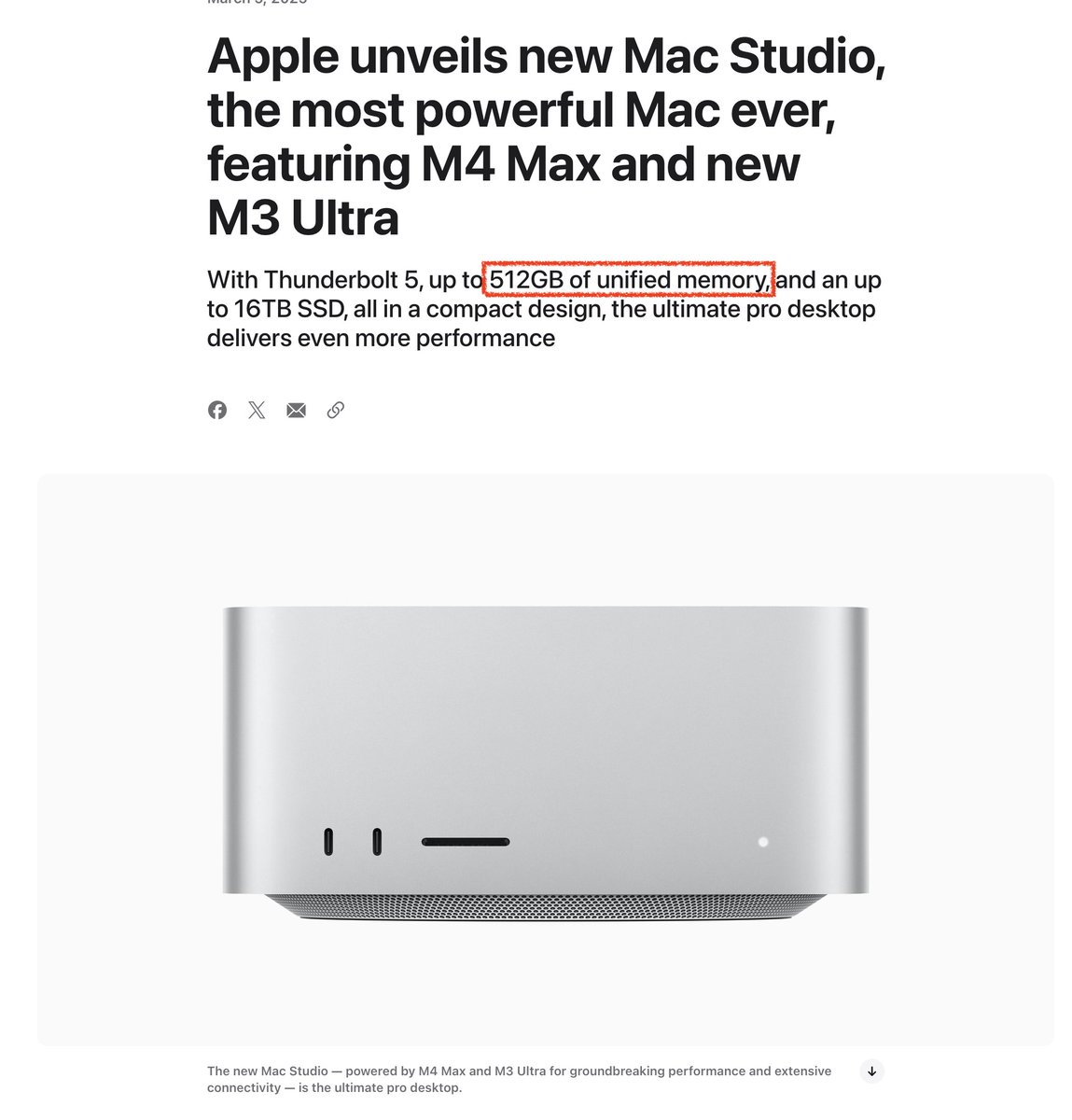
512 GB in a single Mac Studio!. That will fit 4-bit Deep Seek R1 with room to spare.
160
197
4K
Llama 3.2 1B in 4-bit runs at ~60 toks/sec with MLX Swift on my iPhone 15 pro. It's quite good and easily runs on-device:
60
245
3K
Quantized Gemma 2B runs pretty fast on my iPhone 15 pro in MLX Swift. code & docs: Comparable to GPT 3.5 turbo and Mixtral 8x7B in .@lmsysorg benchmarks but runs efficiently on an iPhone. Pretty wild.
19
113
622
Read a bit about Grokking recently. Here's some learnings:. "Grokking" is a curious neural net behavior observed ~1 year ago (. Continue optimizing a model long after perfect training accuracy and it suddenly generalizes. Figure:

38
307
2K
Wow, DeepSeek R1 Distill Qwen 7B (in 4-bit) nailed the first hard math question I asked it. Thought for ~3200 tokens in about 35 seconds on M4 Max with mlx-lm.
39
158
2K
Fun ML math fact of the day: logsoftmax is an idempotent function. Applying it more than once has no effect. (Makes sense if you think of it as a kind of normalization). Short proof:

11
182
1K
Whisper Turbo already runs locally on macOS with mlx_whisper. Transcribes 12 minutes in 14 seconds on an M2 Ultra (~50X faster than real time). pip install mlx_whisper. Example:

25
102
1K
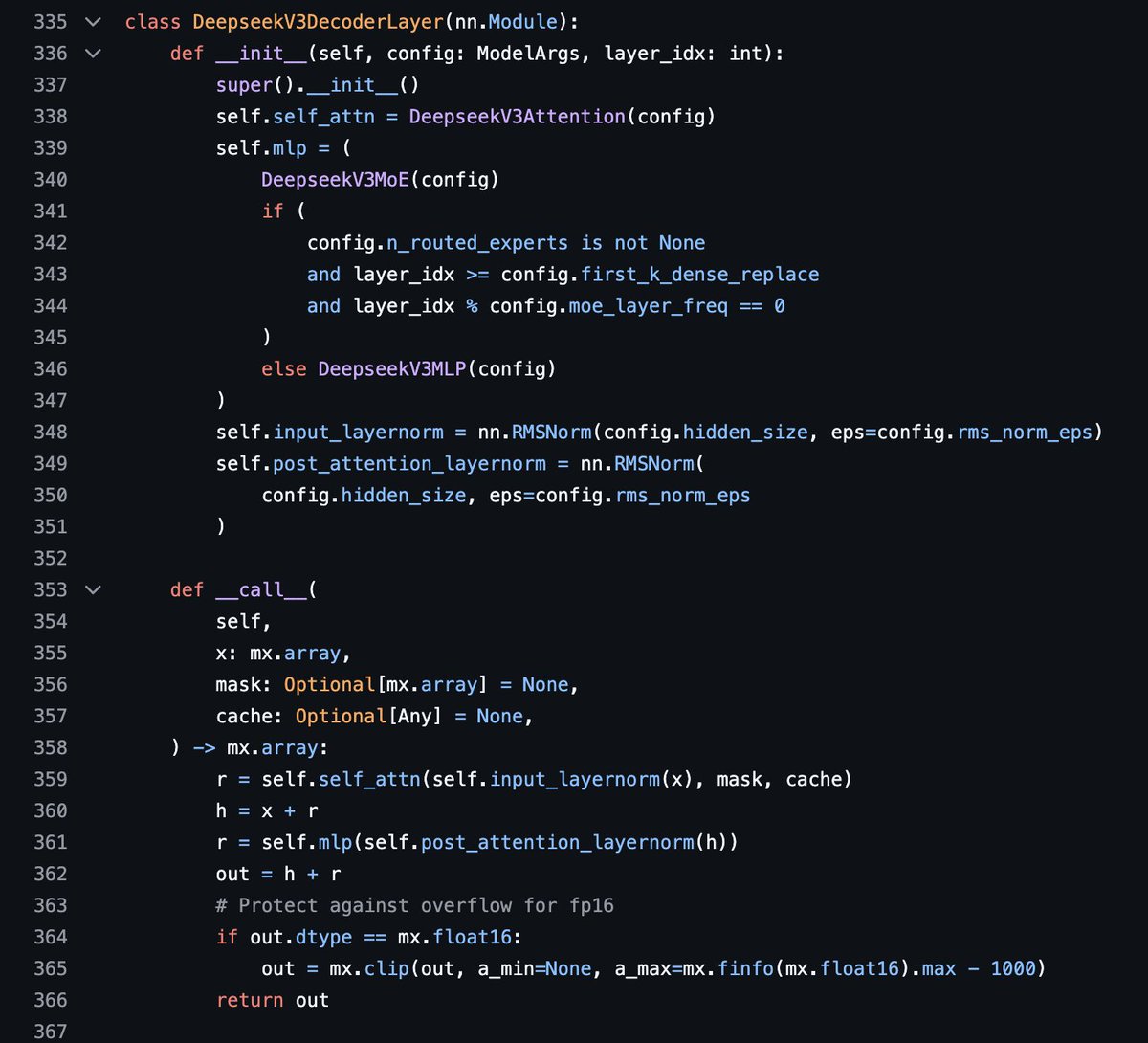
The DeepSeek V3 model file is ~450 lines of code in MLX LM. Includes pipeline-parallelism and all. Good way to see how it all works.
26
165
1K
First results are in. Llama 4 Maverick 17B active / 400B total is blazing fast with MLX on an M3 Ultra. Here is the 4-bit model generating 1100 tokens at 50 tok/sec:
43
132
1K
The new Deep Seek V3 0324 in 4-bit runs at > 20 toks/sec on a 512GB M3 Ultra with mlx-lm!
42
165
1K
Fine-tuning Mistral 7B with LoRA on a 32 GB M1 (laptop!) in MLX. Updated example uses less RAM + support for custom datasets 🚀
27
155
1K
QwQ-32B evals on par with Deep Seek R1 680B but runs fast on a laptop. Delivery accepted. Here it is running nicely on a M4 Max with MLX. A snippet of its 8k token long thought process:

Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1. Blog: HF: ModelScope: Demo: Qwen Chat:

38
125
1K
Hanging out with the big kids:.PyTorch 8 years old.TF 9 years old.Jax 6 years old.MLX 6 months old

19
51
1K
DeepSeek v3 in 3-bit runs pretty fast (~17 toks/sec) on 2 M2 Ultras with mlx-lm and mlx.core.distributed. Model is 671B params (!) with 37B active:
54
123
1K
The Transformer architecture has changed surprisingly little from the original paper in 2017 (over 7 years ago!). The diff:. - The nonlinearity in the MLP has undergone some refinement. Almost every model uses some form of gated nonlinearity. A silu or gelu nonlinearity is.
24
144
1K
Sesame’s 1B conversational speech model is available in MLX!

28
67
1K
Next level: QLoRA fine-tuning 4-bit Llama 3 8B on iPhone 15 pro. Incoming (Q)LoRA MLX Swift example by David Koski: works with lot's of models (Mistral, Gemma, Phi-2, etc)
27
120
923
Cool new macOS app built with MLX Whisper:. Nutshell - Meeting transcription that runs fully on device.

16
75
933
Qwen3 235B MoE (22B active) runs so fast on an M2 Ultra with mlx-lm. - 4-bit model uses ~132GB.- Generated 580 tokens at ~28 toks/sec
29
77
898
Llama 3.1 8B running in 4-bit on my iPhone 15 pro with MLX Swift. As close as we've been to a GPT-4 in the palm of your hand. Generation speed is not too bad. Thanks @DePasqualeOrg for the port.
21
100
861
DeepSeek R1 (the 680B MOE) is ~20% faster in the latest mlx / mlx-lm. 4-bit model on 3 M2 Ultras generates 4k tokens at a respectable 15 toks/sec. Plus some QoL improvements:.- Only downloads the local shard (much faster startup).- Distributed launcher ships with MLX
29
96
858
@mrsiipa IMO the GPU programming model is the most important thing to learn, and it's pretty much the same for Metal, CUDA, etc. The diff syntax are all bijections of one another. if you know one, you can learn another quickly. For learning on a Macbook checkout Metal GPU puzzles with.
15
40
780
We’re hiring people to work with us on MLX. If you’re interested, can write fast GPU kernels, and have machine learning experience, reach out. More here:
16
85
737
MLX was open sourced exactly one year ago 🥳. It's now the second most starred and forked open source project from Apple -- after the Swift programming language.
Just in time for the holidays, we are releasing some new software today from Apple machine learning research. MLX is an efficient machine learning framework specifically designed for Apple silicon (i.e. your laptop!). Code: Docs:
53
57
759
MLX Swift example can also QLoRA fine-tune Llama 3.2. Here's the 1B fine-tuning on my iPhone 15 Pro at > 150 toks/sec. A this rate only takes a few minutes to learn some decent adapters fully on-device.
14
108
749
Just using MLX to fine-tune TinyLlama with LoRA locally on a 8 GB Mac Mini. Code: That's 1.1B parameter TinyLlama which just finished training on 3T tokens. Happy new year! Looking forward to more Local LLMs in 2024

15
99
736
4-bit quantized DBRX runs nicely in MLX on an M2 Ultra. PR:

Meet #DBRX: a general-purpose LLM that sets a new standard for efficient open source models. Use the DBRX model in your RAG apps or use the DBRX design to build your own custom LLMs and improve the quality of your GenAI applications.
25
105
709
Llama 3 announced a few hours ago. Already running locally on an iPhone thanks to MLX Swift. 🚀.

Llama 3 running locally on iPhone with MLX. Built by @exolabs_ team @mo_baioumy.h/t @awnihannun MLX & @Prince_Canuma for the port
16
67
694
Apple Intelligence Foundation Language Models technical report is out. By @ruomingpang and team. Link:


As Apple Intelligence is rolling out to our beta users today, we are proud to present a technical report on our Foundation Language Models that power these features on devices and cloud: 🧵.
5
106
675
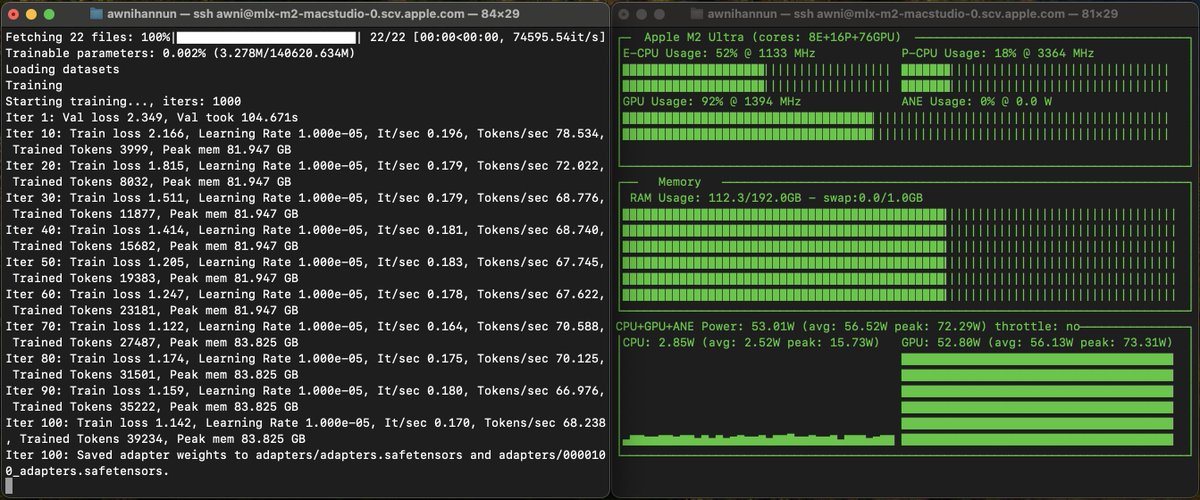
QLoRA fine-tuning Mixtral 8x22B on a single M2 Ultra. 176B params, 1 device, 🚀
15
78
662
Very excited Llama4 are MOEs. They are going to fly with MLX on a Mac with enough RAM. Here's the min setup you'd need to run each model in 4-bit:


Introducing our first set of Llama 4 models!. We’ve been hard at work doing a complete re-design of the Llama series. I’m so excited to share it with the world today and mark another major milestone for the Llama herd as we release the *first* open source models in the Llama 4

22
73
666
If you can write extremely fast GPU kernels and want to work with us at Apple Machine Learning Research on MLX, DM / reach out, we are hiring!.
14
96
648
Llama 3.3 70B 4-bit runs nicely on a 64GB M3 Max with in MLX LM (~10 toks/sec). Would be even faster on an M4 Max. Yesterday's server-only 405B is today's laptop 70B:

"a new 70B model that delivers the performance of our 405B model" is exciting because I might just be able to run a quantized version of the 70B on my 64GB Mac - looking forward to some GGUFs of this.
15
69
633
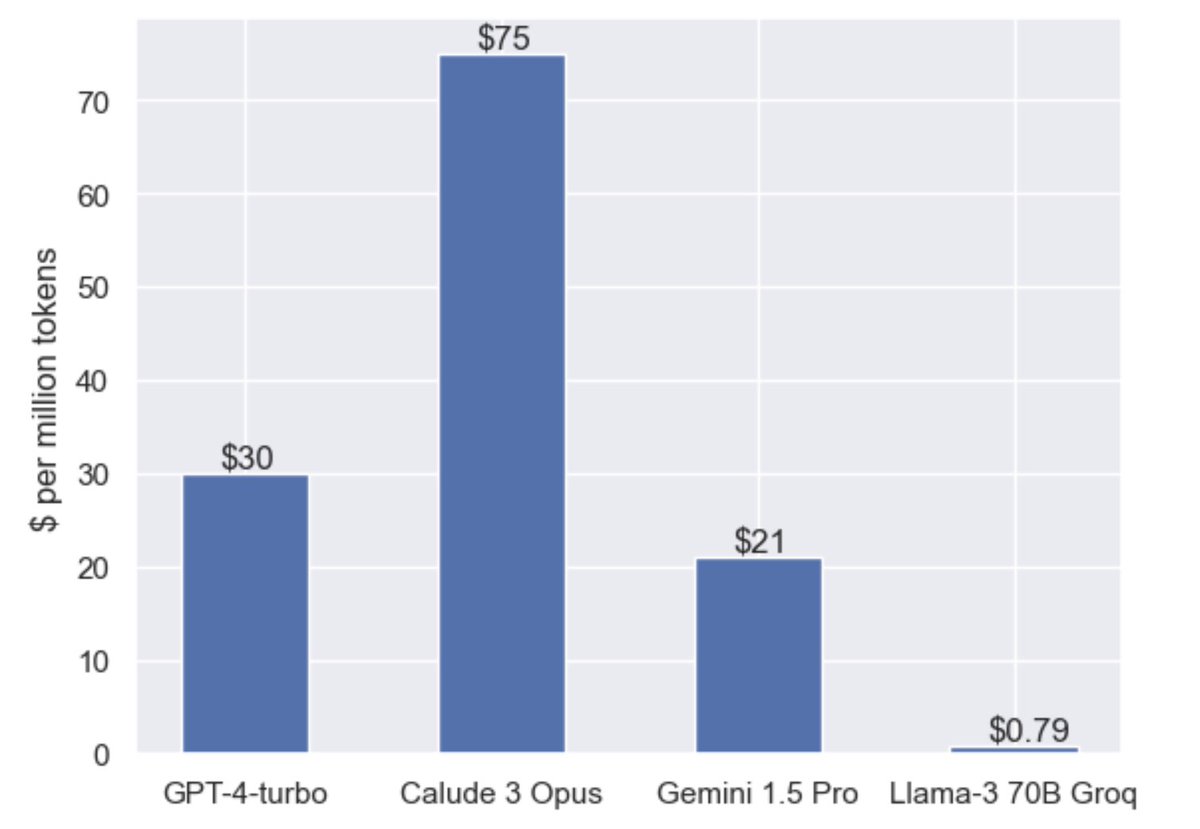
This is an important chart for LLMs. $/token for high quality LLMs will probably need to fall rapidly. @GroqInc leading the way.
23
71
589
Mixtral 8x7B in MLX Runs on an M2 Ultra. 🚢🚢


magnet:?xt=urn:btih:5546272da9065eddeb6fcd7ffddeef5b75be79a7&dn=mixtral-8x7b-32kseqlen&tr=udp%3A%2F%3A6969%2Fannounce&tr=http%3A%2F%3A80%2Fannounce. RELEASE a6bbd9affe0c2725c1b7410d66833e24.
25
55
585
Fine-tuning Phi-2 with QLoRA on an 8GB M2 (!). No need to compromise between speed, quality, and resource usage. This model is nice across the board (and it's all MIT). Code:

12
90
587
SmolLM2 135M in 8-bit runs at almost 180 toks/sec with MLX Swift running fully on my iPhone 15 Pro. H/t the team at @huggingface for the small + high-quality models.
15
66
574
The latest MLX Whisper is even faster. Whisper v3 Turbo on an M2 Ultra transcribes ~12 minutes in 12.3 seconds. Nearly 60x real-time. pip install -U mlx-whisper

19
45
577
Nice new video tutorial on fine-tuning locally with MLX. Covers everything from environment setup and data-prep to troubleshooting results and running fine-tunes with Ollama.


🔥 Fine-tune AI models on your Mac? Yes, you can!. Sharing my hands-on guide to MLX fine-tuning - from an former @Ollama team member's perspective. No cloud needed, just your Mac. #MLX #MachineLearning.
4
84
578
The crew at Hugging Face 🤗 made a bunch of pre-converted MLX models!. Llama, Phi-2, Mistral, Mixtral (and instruct and code variations where available)!. Easier than ever to get started running them locally. Checkout the MLX Community
19
103
553
Fun example: Fine tune a Mistral 7B in MLX locally on your WhatsApp chat history. Completely local, no need to send data anywhere. Code:
If anyone is interested - here is the repo. Its pretty good tbh.
8
60
565
With the latest MLX, 4-bit Llama 3 8B runs nicely on an 8GB M2 mini. 512 tokens at 18.8 toks-per-sec
20
53
544

Fine-tuning TinyLlama 1.1B with LoRA in MLX is pretty fast, even on an 8GB M2!. No quantization needed.
16
72
538
To make it even easier to get started with LLMs and MLX, we made our 🤗 Hugging Face example a python package:. pip install mlx-lm. Gets you a simple API and commands to generate text with thousands of Hugging Face models. Package + docs: Example:

13
72
539
Google / DeepMind over the past 5 weeks:. Train LLMs longer (Chinchilla-70B) and larger (PALM-540B) with multi-modal inputs (Flamingo) and multimodal outputs (Gato)!. 🤯.
4
48
531
Benchmarked the whole Qwen3 family on an M4 Max with mlx-lm (except the 235B that doesn't fit). Stats generating 512 tokens, models in 4-bit:

17
57
546
In the latest MLX small LLMs are a lot faster. On M4 Max 4-bit Qwen 0.5B generates 1k tokens at a whopping 510 toks/sec. And runs at over 150 tok/sec on iPhone 16 pro. On M4 Max, not sped up:
38
49
518
MLX Data is now fully pip installable!. pip install mlx-data. Package includes everything you need to process text, images, and audio. And it runs super fast on Apple silicon. Docs: Example:

9
70
500
An excellent guide to get started fine-tuning locally with MLX + LoRA:.


I’ve created a step-by-step guide to fine-tuning an LLM on your Apple silicon Mac. I’ll walk you through the entire process, and it won’t cost you a penny because we’re going to do it all on your own hardware using Apple’s MLX framework.
4
71
493
Running SDXL in MLX on my M1 laptop. Only takes a few seconds to generate 4 images, model loading and all:
11
34
491
A pre-converted Mistral 7B to 4-bit quantization runs no problem on an 8GB M2 🚀
Big update to MLX but especially 🥁. N-bit quantization and quantized matmul kernels! Thanks to the wizardry of @angeloskath. pip install -U mlx

12
54
476

Using MLX to run a 4-bit quantized 70B Llama on an M2 Ultra. Fast + RAM to spare!
13
46
467
Learn about LoRA fine-tuning LLMs locally with MLX in this new blog post:


My blog on fine-tuning LLMs using MLX was just published on @TDataScience. I'm deeply impressed with what @awnihannun and Apple have built out. 3 key takeaways from my blog:.💻Technical Background: Apple’s custom silicon and the MLX library optimize memory transfers between CPU,

5
53
479
Try out QLoRA for low RAM fine-tuning in MLX. Our LoRA example now supports quantization!. Just for fun, I'm fine-tuning a Mistral 7B on an 8GB (!) M2 🚀. Code:

15
72
467
Achievement unlocked:. 100 tokens-per-sec, 4-bit Mistral 7B in MLX on an M2 Ultra

15
41
456
Nice new article by Pranav Jadhav: GPT-2, from scratch, in MLX . Companion code:

7
74
462
The 236B DeepSeek coder V2 runs at 25 toks/sec on a single M2 Ultra. Not bad for such a large model:
19
34
440
Exciting new project: MLXServer. An easy way to get started with LLMs locally. HTTP endpoints for text generation, chat, converting models, and more. Setup: pip install mlxserver.Docs: Example:


Mustafa (@maxaljadery) and I are excited to announce MLXserver: a Python endpoint for downloading and performing inference with open-source models optimized for Apple metal ⚙️ . Docs:
35
55
408
Made a demo to do test-time-scaling with mlx-lm and a R1-based reasoning model. Same idea as S1:.- To force a response, swap "Wait" for "</think>".- To think more, swap "</think>" for "Wait". Runs fast with 4-bit Qwen 32B on an M3 max:
20
58
454

The video is a Llama v1 7B model implemented in MLX and running on an M2 Ultra. More here: * Train a Transformer LM or fine-tune with LoRA.* Text generation with Mistral.* Image generation with Stable Diffusion.* Speech recognition with Whisper
12
47
433
As part of our goal to make MLX a great research tool, we're expanding support to new languages like Swift and C, making experimentation on Apple silicon easier for ML researchers. Video generating text with Mistral 7B and MLX Swift 👇. MLX is an array framework for machine
20
60
433
405B Llama 3.1 running distributed on just 2 macbook pros! . Here's the @exolabs_ + MLX journey:. 940AM: @Prince_Canuma opens PR for Llama 3.1 in MLX LM. Partially finished but has to OOO for birthday. 1140AM: @ac_crypto updates Prince's first PR. 130PM: I merged the PR after.
2 MacBooks is all you need. Llama 3.1 405B running distributed across 2 MacBooks using @exolabs_ home AI cluster
18
73
438
Nice video guide to set up a DeepSeek R1 model running locally with MLX + @lmstudio as a local coding assistant in VS Code + @continuedev


PSA: It takes <2 minutes to set up R1 as a free+offline coding assistant 💁♀️. Big shout out to @lmstudio and @continuedev! 🫶
6
64
441
Phi-2 in MLX Super high quality 2.7B model from Microsoft that runs efficiently on devices with less RAM

Hey @awnihannun, I've now got an MLX implementation of phi-2 working! Missing the generate function rn, but will put together a PR tonight or tomorrow morning. Free to help make it faster?

10
63
430
This might be the most accessible way to learn Metal + GPU programming if you have a M series Mac. All 14 GPU puzzles (increasing order of difficulty) in Metal with MLX custom kernels to do it all from Python.

Introducing Metal Puzzles! By @awnihannun's request I've ported @srush_nlp's GPU Puzzles from CUDA to Metal using the new Custom Metal Kernels in MLX!.
1
43
432
With the latest MLX, generating text with LLMs is getting faster and using less memory. In the past couple weeks we've improved ~30% on most models. When MLX first came out 16-bit Phi-2 couldn't run on an 8GB M1. Now it runs pretty quick with RAM to spare:
19
45
420
LoRA fine-tuning Llama 3 8B in 16-bit on an M2 Ultra with MLX. Some stats:.- Batch size 4, 16 LoRA layers.- 530 tokens per second.- Avg power 94 W.- Peak mem 20GB

17
47
421
How does Apple Intelligence get a high-quality LLM on device?. - The on-device model is ~3B parameters. Already pretty small (~6GB in 16-bit). - Quantized with "accuracy recovering adapters". Quantize and freeze base model and train low-rank adapters for 10B tokens. - LoRA.
8
54
408
Just ported Gemma from @GoogleDeepMind to MLX. Gemma is almost identical to a Mistral / Llama style model with a couple of distinctions that you model mechanics might interested in 👇.
11
57
408
We're hiring research scientists and engineers to join our group in MLR (machine learning research) at Apple. Checkout the links below for more info and don't hesitate to reach out if you have any questions!.
9
65
392

MLX has an MIT License Now Phi2 has an MIT License Now MLX + Phi2 has an MIT License 🚀.
6
55
396
Two really nice recent papers from Apple machine learning research: . - Scaling laws for MoEs.- Scaling laws for knowledge distillation. Work by @samira_abnar @danbusbridge et al.


4
61
405
Here's a step-by-step walkthrough (with screenshots) to build a simple app to run LLMs on an iPhone with MLX Swift:

3
38
405
MLX LM + Aider + Qwen 2.5 for fully local + high quality coding assistance:

7
43
406
We’re hiring someone to work with us on MLX at Apple. Join the most cracked team to advance the frontier of ML and systems. DMs open.
13
42
401
Cool new work from some colleagues at Apple: more accurate LLMs with fewer parameters and fewer pre-training tokens. Also has MLX support out of the box! . Code here:

Apple presents OpenELM. An Efficient Language Model Family with Open-source Training and Inference Framework. The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and

7
64
392
Hunyuan-Large by Tencent is a 389B param MOE (52B active). It's the largest open-weights MOE. In some benchmarks it exceeds Llama 3.1 405B. With MLX's new 3-bit quant it just barely fits on a single 192GB M2 Ultra!. And runs at a very decent >15 toks/sec:
9
41
391
New Mixtral 8x22B runs nicely in MLX on an M2 Ultra. 4-bit quantized model in the 🤗 MLX Community: h/t @Prince_Canuma for MLX version and v2ray for HF version
14
58
383
SD3 runs locally with MLX thanks to the incredible work from @argmaxinc . Super easy setup, docs here: Takes < 30 seconds to generate an image on my M1 Max:

DiffusionKit now supports Stable Diffusion 3 Medium.MLX Python and Core ML Swift Inference work great for on-device inference on Mac!. MLX: Core ML: Mac App: @huggingface Diffusers App (Pending App Store review)
3
53
386

Real-time speech-to-speech translation while preserving your voice!. And, it runs on your laptop or iPhone in MLX / MLX Swift:


Meet Hibiki, our simultaneous speech-to-speech translation model, currently supporting 🇫🇷➡️🇬🇧. Hibiki produces spoken and text translations of the input speech in real-time, while preserving the speaker’s voice and optimally adapting its pace based on the semantic content of the
7
44
390
Llama 4 Scout 109B can actually run pretty fast on a 64GB M4 Max using a mixed 3/6 bit quant (4.0 bits-per-weight). Here it is generating 600+ tokens at 42 tok/sec on my laptop!
14
32
386
Mixtral-style mixture of experts now work with MLX LoRA (and QLoRA) example. Code + docs: . QLoRA training a 4-bit Mixtral-8x7B on an M2 Ultra:

8
49
368
PSA asitop is an incredibly useful tool if you are using MLX and want to observe RAM / CPU / GPU / power usage. pip install asitop

11
52
365
Collected some of the amazing projects people are building with MLX in one place: Looking at that list, it's hard believe MLX is just 2 months old.

8
65
365
RT if you want day-zero support for @OpenAI new open-weights model to run fast on your laptop with MLX.

TL;DR: we are excited to release a powerful new open-weight language model with reasoning in the coming months, and we want to talk to devs about how to make it maximally useful: we are excited to make this a very, very good model!. __. we are planning to.
12
101
375
Llama 3 models are in the 🤗 MLX Community thanks to @Prince_Canuma . Check them out: The 4-bit 8B model runs at > 104 toks-per-sec on an M2 Ultra.
13
32
367
4-bit quantized Code Llama models already in the 🤗 MLX Community!. {70, 13, 7}B models here: 1. pip install mlx-lm.2. python -m mlx_lm.generate --model mlx-community/CodeLlama-13b-Python-4bit --prompt "write a quick sort in C++". Thanks to.
11
47
356