
Benjamin Lefaudeux
@BenTheEgg
Followers
1,189
Following
1,838
Media
238
Statuses
7,748
Crafting pixels w PhotoRoom after some time in sunny California and happy Copenhagen. Meta (xformers, FairScale, R&D), EyeTribe (acq) Mostly tweeting around AI
Anywhere by the sea
Joined August 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Messi
• 312968 Tweets
梅雨入り
• 134440 Tweets
#InternationalYogaDay
• 122402 Tweets
अंतर्राष्ट्रीय योग
• 86773 Tweets
lorde
• 81566 Tweets
WANGYIBO LOEWE GBA
• 67956 Tweets
gracie
• 46321 Tweets
Kehlani
• 35547 Tweets
ECHR
• 33169 Tweets
Brandy
• 31712 Tweets
ブラックジャック
• 30388 Tweets
キンキーブーツ
• 28890 Tweets
ドクターキリコ
• 26881 Tweets
FREEZE IS FOREVER
• 26251 Tweets
#StopCopyingTXT
• 25163 Tweets
FILLED BLANK WITH LOVE
• 20601 Tweets
#يوم_الجمعه
• 20362 Tweets
土砂降り
• 18922 Tweets
Hayırlı Cumalar
• 18744 Tweets
MakinKESINI MakinJELAS
• 15392 Tweets
हाई कोर्ट
• 13333 Tweets
デーゲンブレヒャー
• 12695 Tweets
原作改変
• 12561 Tweets
#LUXTWICE2024
• 11872 Tweets


















@hiphopscypher
@VeritasBP
@adamcbest
@howardfineman
Look at the stats and get back here. I’ll help you: Japan homicide rate is 0.02 per 100k per year. US is a thousand times that. What you *think* you know is insignificant when faced with these stats.
2
1
232
Attention sinks: great read, and pretty close out of principle to
@TimDarcet
's ViT registers

1
22
154
Reading the paper, and as a transformers part nerd (xformers 😘), this feels pretty compelling. One of the first "serious" algorithms I came across was of course Kalman, which has a solid mathematical grounding, good touchstone here (and S4 in general)

Transformers power most advances in LLMs, but its core attention layer can’t scale to long context.
With
@_albertgu
, we’re releasing Mamba, an SSM architecture that matches/beats Transformers in language modeling, yet with linear scaling and 5x higher inference throughput.
1/


42
343
2K
1
7
131
Happy to see this one out :) I’m one of the authors, I hope this helps research in the field

xFormers: Hackable and optimized Transformers building blocks, supporting a composable construction
github:

0
45
279
0
11
108
Finally reading Ring Attention (), doesn't look like there's a performant open source implementation in pytorch out there, but feels like something where
@d_haziza
and crew would shine...
Great paper, in Google's garden given TPU strong interconn, Gemini ?

5
11
83
Just finished a first read of Dino v2, feels really significant I read a fair bit of papers, first one for a while which felt so insightful despite not being about a new arch per say 1/N
3
11
79
This is really big I think. OpenAI Triton is now compatible with nvidia TRT & AMD Rocm (on top of the original use case with nvidia & python). New linga franca for GPU kernels, well deserved kudos to Philippe Tillet

One ongoing story I'm really excited about is the Triton compiler, which AMD has been investing a lot into. The end result: you can write 1 Triton kernel, and run it at high perf on NVIDIA or AMD GPUs!
Here's the current (fwd) perf of a Triton FA-2 kernel on A100 vs. MI250:

2
7
47
1
8
75
Not completely new by now, but “Direct Preference Optimization” (Rafailov et al) is a landmark in tuning models towards preferred distribution at génération time I believe. Not obvious to me in the beginning so mini thread

1
15
68
Hey Twitter, RT appreciated. Let's say we (PhotoRoom) opensource a new text-to-image model, would there be any research labs interested ? I would "just" need mark of interests, nothing binding or costly. DM open
10
26
68
@hiphopscypher
@VeritasBP
@adamcbest
@howardfineman
Check out this article when you get the chance. Sometimes saying “I don’t know, let’s look at the numbers” is the most reasonable way out.
1
0
57
Another great recent publication that went under many radars I think is SigmaReparam (reparam linear layers with spectral normalization, getting rid of LN and training tricks). Tested over many fields, simplifying, feels sensible, impressive results

2
17
55
This is utterly absurd. The planet is burning and we’re focusing on irrelevant and made up problems (crypto a few years ago, now extinction from AI..).
@EU_Commission
seems really poorly informed here, scientific reasoning and asking experts should be a priority

Mitigating the risk of extinction from AI should be a global priority.
And Europe should lead the way, building a new global AI framework built on three pillars: guardrails, governance and guiding innovation ↓

432
483
2K
2
8
53
With a little bit of experience, there’s no way these numbers are true, even if they were measured once. Playing this game you should take best implementation from team Jax vs. best from team PyTorch. 4x difference on SAM makes no sense (same for “it’s XLA” explanation
@fchollet
)
4
1
48
Attention really is the tree that keeps giving.. cuDNN9 coming out with nice perf claims + extra flexibility, not triton like but close. Nice for vision, where attention is more easily an issue than LLMs



1
12
47
@GergelyOrosz
I don’t think somebody can call him/herself “hands on” in software if they don’t code, really ?
4
0
45
Multi token prediction that works, really nice paper which I think will be foundational (1/N)
2
7
43
@geraintjohn_
We don’t know each other, but now you know that a stranger keeps you in his thoughts. Hold tight and get better ❤️🩹
0
0
41
We worked a lot on that, and it’s just the beginning

We are THRILLED to announce a major milestone today: our Series B, raising $43M with Balderton and Aglae
We also announce 6 new GenAI features in Photoroom. More importantly, these features are powered by Photoroom's foundation model, the best model for commerce photography.📸✨
62
61
489
5
2
41
A look back on 2023-early 2024 for the ML team
@photoroom_app
, sharing some insights from our diffusion journey

6
13
40
@barf_stepson
@ctatplay
But why don't you US people vote that insanity out ? You're aware that other comparable countries (ahem, Europe for instance) let you learn without digging your debt grave, right ?
17
2
34
Writing a blog post on our (Photoroom) family of diffusion models, from training to features in the app. Anything specific you would be interested in ? Won’t be able to spill all the beans but I can try
8
0
33
Finally took the time to play around with HF Candle, it’s really cool, impressive completeness already and a fresh take. Mini thread

2
3
31
Python is atrocious for parallel work, ProcessPool will never cut it because you're stuck in pickling oblivion and the code becomes an unstable spaghetti plate, Asyncio is overrated for anything which is not simple IO, answer is GIL-less project from Sam Gross.

Question 1: Tell me something which is true that almost nobody agrees with you on?
Why does Thiel ask this?
11
62
798
3
0
31
Having a look at datatrove () from
@huggingface
, nice to see this out. There’s also Fondant, but other than that not much in the open for what’s a key building block for modern ML: data pre-processing.

3
7
29
Interesting new deepseek model, still a Transformer but lots of tweaks and seems very competitive vs. llama3 70b. "Latent attention" is one new element in a string of compressed KVs proposals, also happens in vision

3
1
29
One day of training, from scratch (!), on a "big enough" cluster. This was actually a debug run 😅 What a time we live in... Which one is the real one ?

8
0
27
MobileCLIP is a really cool paper from Apple folks,
SOTA on a latency/accuracy basis (Parero sota if you will)
Couple of key axes to get there (ongoing read)
- model arch. Undervisited these days, shame given NextViT or MaxViT
- data
- training

2
3
28
A bit short on ML news at
@photoroom_app
recently (well, quiet for a month) because we're cooking something big, but this we just released: colored shadows, the model understands transparency ! This comes from the app in 5 seconds


2
1
26
I'm still not over Dino v2.. Abstractions have been a staple of LLMs, but they are all over the training set, already baked in (a car and a bus are a vehicle). Dino v2 shows some being captured by the model but it did not get them from a data leak, should be a bigger deal IMO

1
0
25
@Broun_Dragon
@SmallHandsDon
@RALee85
@AbraxasSpa
Not all leaders steal the country wealth, whataboutism only goes so far.. Putin is billionaire in goods after “leading” an impoverished country. Can you think of another western leader with comparable stealing skills ? So no, not just like any pilot in any country
1
0
23
In the middle of an AI storm in SF, the Paris AI scene is vibrant and getting things done !
We're still recruiting in the ML team at PhotoRoom, Senior Applied Scientist and Data Scientist (with a big DL flavor). Know somebody interested ?
1
5
24
Gaudi3 out, looks like a much beefier version of Gaudi2 + emphasis on interconnect, a bit like TPUs. Quoted numbers are fp8 which is non trivial at the moment, but supposedly pytorch compatible (native pytorch ops or intermediate like ONNX ?)

2
4
23
@kikithehamster
@barf_stepson
@ctatplay
That's just sad.. I understand that everything is not that simple, but frankly the inability of the US society to position itself on some subjects which are in much better shape in other OECD countries (school, healthcare, police violence, guns..) is baffling.
1
1
22
Moving our data processing to Ray, pretty cool framework to orchestrate workloads, it's nice that it removes a lot of the Python quirks (esp. their Actor abstraction).
Not a deal breaker but looks like serialization takes a lot of CPU though, CUDA tensors. Any tips ?

2
1
22
@Suhail
@ID_AA_Carmack
Did you check out
? It’s widely used these days with webui and low memory dreambooth or textual inversion

1
0
22
Some of the examples in the blog post are early engineering demos, updating them today. Here's a more recent "erase" example which I think is nuts. Soon in your pocket, kudos to
@mearcoforte

A look back on 2023-early 2024 for the ML team
@photoroom_app
, sharing some insights from our diffusion journey
6
13
40
3
2
21
New model incoming, doing much better in situations which were tricky, lots of contrast for instance. Easier to prompt also, which was an issue (looks like we're not the only ones, SD3..).
Other examples in the thread




2
2
21
Did you know that superresolution is a surprisingly interesting topic ? Like, the frequencies you need to add (hallucinate) are super context-dependent, you don't want to superresolve bokeh. Super proud of the ML team at
@photoroom_app
(pic credits: )


3
3
21
How
@photoroom_app
speeds up
#stablediffusion
using xformers, explained:
Attention still matters.. Matthieu also contributed a PR to
@huggingface
, eventually this should become largely available
1
2
20
Really cool results, even the "broken" part is fascinating, super smart solution ! Interesting parallel with some discussions on autoregressive LLMs being doomed without scratchpads

Vision transformers need registers!
Or at least, it seems they 𝘸𝘢𝘯𝘵 some…
ViTs have artifacts in attention maps. It’s due to the model using these patches as “registers”.
Just add new tokens (“[reg]”):
- no artifacts
- interpretable attention maps 🦖
- improved performances!
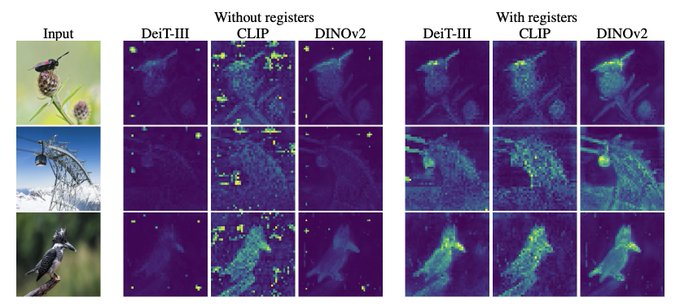
43
327
2K
1
1
20
GPU poor or GPU rich, always a matter of perspectives..
- one H100 node down,
- 1 used right now (<- GPU poor)
- 29 nodes to go (<- GPU $$$)
Updating this tweet when I get the full 30 nodes back up :) Sharing a recent learning of mine: interconnect is _still_ key to perf

4
0
19
Training a diffusion model, learning
#42
: stay calm and carry on. Incoming soon on
@photoroom_app
, our model, data and training stacks :)

1
1
19
@francoisfleuret
You would risk overshooting ? Undershooting is not as bad, it could take you more steps but you’ll get there. Overshoot and you may never get there.

1
1
19
Makes no sense to me, focused on anecdata. Scientific progress doesn’t work like this, when comparing training & architectures what merit is there to which data center the model was trained on ? Aim is repro or improve, past is useless. Even
@JeffDean
gets this backwards it seems

I got really excited that the LLaMA paper calculates and reports their carbon footprint! 🦙🌬️🌎
But upon looking at the paper itself, it has this table, which completely misconstrues the emissions of OPT and BLOOM, while not actually reporting LLaMA's own.
How? A thread 🧵
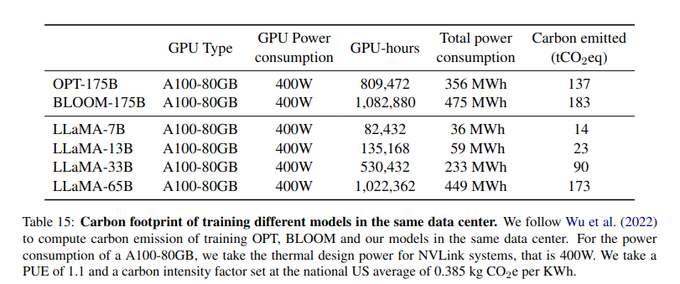
14
66
312
2
1
18
We’re hiring a senior ML engineer in the ML team, remote in Europe is good, and we’re covering many cutting edge topics !
PhotoRoom is hiring for many positions if you’re looking for a lean and fast growing company
You’ll have a big impact for hundreds of million of entrepreneurs in the world🔥
9
16
124
3
8
18
Classification is not a modern computer vision task, I wish people stopped using it for broad architecture prescriptions. Where is MLPMixer again ? “Optimal ViT shape” paper ? Right

ConvNets Match Vision Transformers at Scale
abs:
This paper from Google DeepMind pretrains a variety of NFNet models on the JFT-4B at various scales and obtain performance on ImageNet similar to ViTs.
> Our work reinforces the bitter lesson. The most

13
92
562
2
1
16
@Eastern_Border
He literally says (typical Macron) "neither follow the most warmongering ones, nor abandon the eastern countries so that they have to act alone", it's convoluted but it's actually supportive of Eastern Europe.
7
0
16
“Sparse to soft MoE” (Puigcerver and Riquelme, ) feels like a complete game changer, super surprised very few people talk about it
0
1
17
Great thread and insights, some mirror vision indeed and lots I didn’t know. Caveat is that this doesn’t improve on BERT, seems trivial but to keep in mind. Would be nice to see this with GPT and compare the keepers, looks like
@karpathy
is on that these days

How good of a BERT can one get in ONE DAY on ONE GPU?
With all the recent studies about scaling compute up, this paper takes a refreshing turn and does a deep dive into scaling down compute.
It's well written, stock full of insights. Here is my summary and my opinions.
🧶 1/N

47
636
3K
2
1
17

Something everyone should know, but with an eye on historical perspectives I think. Historically attention is IO bound even more than flops bound, so the incentive was big for LLM practitioners to pile up on model dim. Flash relaxed that.. and openAI moved to 32k context

this chart shows how the FLOPS in a GPT are allocated as the model scales
this model has a fixed context length of 2048 tokens, but the model dim increases by 16x from the smallest to the biggest

1
15
106
1
2
16
Anyone in my torch TL: if you have a "classic" (explicit softmax(QKt)V) implementation of attention in your codebase, it's _really_ worth it moving to torch SDPA (or xformers' or FlashAttention). It's typically only a few lines, more reliable, faster & way less ram
2
0
17
I personally love
@giffmana
very open takes / opinions + shared recipes and little tricks, not seen that often. Beyond this "style", the track record is very impressive
Here's what our (sub)team in Zürich has done for OSS vision over the past 5y, besides inventing ViT:
1) Make i21k a thing
Release:
2) best CLIP (siglip) by a large margin
3) best i1k ResNet50 ever
4) best pre-trained ResNets
5) >55k ViTs
6) Most efficient JAX/TPU CV code
deets👇
11
56
555
1
0
16
Illustration for a colleague, the pytorch way to sample data. Never as good as
@francoisfleuret
little book, and a little quick and dirty

2
0
14
It’s also a key part of the soon to be released PhotoRoom model (not vanilla DiT but heavily related). I really think gatekeeping reviews are too noisy, something like arxiv + open reviews/ test of time feels better to my eyes

The Diffusion Transformer paper, by my former-FAIR-and-current-NYU colleague
@sainingxie
and former-Berkeley-student-and-current-OpenAI engineer William Peebles, was rejected from CVR2023 for "lack of novelty", accepted at ICCV2023, and apparently forms the basis for Sora.
47
417
3K
1
0
15
How is the photoroom backend fast and scalable, with billions of diffusion based images generated a year -and growing- ? Re-posting slides from
@MatthieuToulem1
and
@EliotAndres
from latest GTC, for visibility.
0
4
15
All decent training gets 40 to 50% MFU, there’s no 4x hiding in there, these numbers mean that PyTorch was at <15% meaning that there were correct but very slow ops that any engineer would fix. 15% speed ups are possible, not 400% unless your baseline is broken
1
0
14
Remember a thread two months ago on how to sell your sneakers () ? Remember this thread from
@matthieurouif
? (). Well, we have new Magic Studio incoming in
@photoroom_app
, now real time. Learning by doing, we're ML artisans :)


PhotoRoom raised $19 million for its AI photo studio, which is already powering millions of resellers and small businesses.
Today, we are launching a new generative AI feature, magic studio, to create stunning marketing images from any product photo
A thread 🧵
158
896
8K
3
4
14
@gcvrsa
@silentsara
@brent_bellamy
Honey, check out rear facing car seats, these are by far the safest until age 4 (and are indeed hard to fit in a smallish car even if that doesn't justify crazy American pick ups)
1
0
13
Interesting results, which completely match residual path assumptions if you think about it. Each new layer adds residual information, so simple concepts are nailed early, complex ones late

Diffusion Lens is a pretty neat new paper, you can see a text-to-image encoder's representation of a giraffe getting less and less abstract with every layer 🦒

5
55
493
2
1
14
Cooking.. No stable diffusion fine tune, no LoRA yet, just a base model training. One of the first 512+ samples, promising

1
0
14
To the surprise of nobody in the field, but much easier said than done. Congrats
@pommedeterre33
et al. for the Kernl, it was a motivation for xformers at the time and I'm glad that a complete faster Transformer, torch compatible, happened in the open !

12X faster transformer model, possible?
Yes, with
@OpenAI
Triton kernels!
We release Kernl, a lib to speedup inference of transformer models. It's very fast (sometimes SOTA), 1 LoC to use, and hackable to match most transformer architectures.
🧵

7
108
574
0
1
12
Dear TL, we're recruiting at
@photoroom_app
and more specifically in the ML team, if you're interested in wrangling data at scale (100M+), multi modalities, custom labelling models & data science challenges: DM and talent
@photoroom
.com !
Job desc here
0
3
12
Nothing to do with me, but Llama and Dino v2 are two great SOTA papers from FAIR, anchored in different fields, both using specialized parts from xformers (that I didn’t contribute to, again not about me). Optimizing above the torch ops was a key vision, confirmed IMO
0
1
13
I've a huge respect for
@OpenAI
, but this is an incredibly pretentious, self centered and historically wrong take. Swap AGI for RNA vaccines, Crispr , X-rays, relativity theory, antibiotics, .. None of them were any better kept under wraps, and nobody can be trusted with these.
3
0
12
Speeding up multimodal ML: we're rolling out a much faster scene suggestion
@photoroom_app
, which is content aware, editable to your taste, and now almost instant fast. The two top scenes are effectively infinitely fine grained recommendations for this content.
1
2
12
Reacting a bit late, but my take on this (the open part). I've been a follower of SemiAnalysis and
@dylan
for a while, generally impressed. Disagreeing this time.
I think this is based on two premises, largely debatable
1 - winner takes all
2 - bigger is better

Google Gemini Eats The World – Gemini Smashes GPT-4 By 5X
The GPU-Poors, MosaicML, Together, and Hugging face
Broken Open-Source
Compute Resources That Make Everyone Look GPU-Poor
Google Cloud TPU wins
37
123
808
2
1
12
@savvyRL
Word2vec was just about clustering, but here there seems to be a spatial component, new right ? Some cities are bound to be written together more often because of non-spatial logic, say a list of capitals for instance. A purely frequentist approach should get the loc wrong, no ?
1
0
12
We've been using Ruff for a while at Photoroom AI, moving to it for the formatting, pretty incredible tool, we're lucky to have it in the ecosystem (and Rust is the future for low latency tools, that's for sure).

Ruff v0.1.3 is out now with a bunch of improvements to the formatter.
2
6
96
1
1
12
@typewriteralley
There are existing counter examples to that, take Copenhagen for instance, the bikes and buses don't have to compete. The phrasing could have been "people on buses are often stuck in traffic because one-crewed cars take all the space". City planning education is rare :(
1
0
12
@finbarrtimbers
It’s hard to get food perf out of it, there are great kernels for this in xformers but you don’t typically get the speed that you could expect, for instance picking single coefficients doesn’t fit tensor cores. Blocksparse is much better if you want sparse
1
0
11
Of note: there’s an industry standard for inference called MLPerf. Fastest on nvidia GPU is TensorRT, across many models, go check it out.
Benchmarks are only meaningful best on best, there’s an order of magnitude perf span in between correct implementations.
With a little bit of experience, there’s no way these numbers are true, even if they were measured once. Playing this game you should take best implementation from team Jax vs. best from team PyTorch. 4x difference on SAM makes no sense (same for “it’s XLA” explanation
@fchollet
)
4
1
48
0
0
11
AMD dropping on results then jumping on AI partnership with MSFT.. interesting that MSFT is actually a credible partner here, given the workload via OpenAI and their triton-infused stack (nvidia for now but through an IR) 1/2

2
1
11
@Jonathan_Blow
Maybe that’s just an easy way to do layoffs, and people want to stuff their agenda in it ? “People want this not to be true, but it’s true” as the saying goes :)
1
0
10
Some tech news from the
@photoroom_app
team, it’s been a while:
- consistent renderings (in beta on the web already), your gen Ai pics look like they come from the same place, instead of being unrelated
1
1
11
I forgot in the above, but the details on engineering are just great also. Hero number: 2x as fast and 3x less memory as comparable SSL methods, when proper engineering is included. Pretty impactful, and good engineering compounds (reusable), good omen for FAIR 3/N
1
0
11
None of these pics are completely real, but there’s some reality-informed diffusion :) no outgrowing (I believe
@photoroom_app
is the only company nailing that), but we’re improving on some details. Crazy optim on the backend to get to these speeds (seconds) but more to come


1
2
10
Hopefully able to share a bit more in a couple of weeks, we tried to push the walls with this training. It's not a SD_something, another architecture that we believe in for PhotoRoom. Our own data stack, and a metric ton of work even before the diffusion training
2
0
8
To emphasize some key facts:
- we generate billions (with a b) of images a year for our users
- Photoroom is sustainable, this is not a VC money or ZIR plot
- foundational diffusion model, trained from scratch and powering a host of features
- third one we trained actually (:
1
0
10
It feels like a paper which covers the whole loop to start with: a lot of context around the SSL SOTA, picking the good ideas where they are, detailed explanations on the data pipeline, many insightful ablations, extensive results and plenty of take aways and surprises 2/N
1
0
10
Why are the CPUs so idle, I hear you say ?
Because we precompute everything we can, that's why. Removes most augmentation options, but that's not really a thing for diffusion. That's how we got these 10k img/s (training !) on 16 A100 nodes that I mentioned in the blog post
And.. we're back in business ! Possibly placebo, but I can feel the heat just looking at the screen

1
0
9
1
0
10
The Lenna of generative AI just got an upgrade... Still ~instant rendering, now need to ship this (after internal demo and convincing colleagues 😬). Not quite the final checkpoint

Moving up the resolution ladder (just a few thousand steps at this resolution).. hard to source the GPUs but getting there

1
0
5
2
1
9
@tunguz
We did that for xformers () in retrospect that was probably a mistake and a white paper on arxiv would have helped getting traction. Most people receptive fields are tuned to arxiv these days (+derived mailing lists, websites and RSS)

1
0
10
In a similar vein Mistral or Gemma numbers would have fair-er with things like GPT Fast baked in, after all the comparison includes all of Keras so surely that 1000loc are fair game ?

0
0
10
Pretty interesting, and great to see numbers out not using Infiniband, it’s a big part of public clouds offering

Maximize training throughput using PyTorch FSDP 🔥
The PyTorch teams at IBM and Meta demonstrate the scalability of FSDP with a pre-training exemplar and share various techniques to achieve rapid training speeds.
Read more here:

2
36
271
1
0
9
Liberal depiction of the Mistral naming scheme: so French it’s becoming pretty funny. Joke aside I think they’re doing a great job a standing out
Vive La Plateforme and Le Chat !
(pic not real, from PhotoRoom own model)

0
1
9
Sneak peek, which one is real ?
@photoroom_app
and instant backgrounds, this is still instant but quality and model understanding is going through the roof. Hold on to your socks and stay tuned

3
2
9
Some practical questions in terms of AI image edition these days: go full ML or keep the physics/rendering angle ? It's not entirely obvious in many places, mini thread
4
0
9
@KerenAnnMusic
@lorde
Does "appartheid state" and "colonies" count, or do you have selective eyesight ? Nothing to do with Judaism. With your reasoning Mandela would have died in prison
0
2
8
@melficexd
@cHHillee
they've been GP-GPU for a while, and GP stands for General Purpose, but I guess that most people commenting don't know that either. TensorCores in nvidia chips have been targeted at AI for a long time
0
0
9
Out of my league again, but the parallel scan here feels like the crown jewel. Flash got us used to streaming all the time, kernel fusion is known quantity by now, but this being not bound by recurrence doesn't feel obvious ? Tri Dao strikes as usual



1
0
9
And.. we're back in business ! Possibly placebo, but I can feel the heat just looking at the screen
GPU poor or GPU rich, always a matter of perspectives..
- one H100 node down,
- 1 used right now (<- GPU poor)
- 29 nodes to go (<- GPU $$$)
Updating this tweet when I get the full 30 nodes back up :) Sharing a recent learning of mine: interconnect is _still_ key to perf
4
0
19
1
0
9
@rasbt
you can try out "metaformers" (ViTs with some patch embedding layers) on cifar in xformers, super simple script
Defaults bring you to 86% cifar10 (not a world record, I know) within 10 minutes on a laptop with a 6M parameters model (half of resnet18)
2
2
9
Cringe-y for me to watch, too slow in the beginning but getting a bit better over time, a presentation I made a couple of weeks back on how some of the
@photoroom_app
AI features work behind the scenes. Not too detailed but hypothetical questions welcome

1
1
7
A lot of intuition is shared here, which feels great. Definitely putting this selection mechanism to good use (jeez twitter is broken, and sorry for the typos above)

1
0
8
@ID_AA_Carmack
Initial release was not optimized at all, getting better these days (fusing layers with nvfuser or tensorRT for inference, better attention kernels from xformers and
@tri_dao
, ..). New major improvements may not be iso-weights from now on (to be able to use tinyNN for instance)
1
0
8
The DPO promise is to cut through this, as they put it “your LLM is already a reward model”. How that worked in practice I didn’t get it initially though

1
0
8
SSL method: I’m far from a specialist, felt like this reuses a lot of prior insights from this lab + other good ideas from the outside, in particular KoLeo (encourages a very regular feature spread) looks to be very significant (8% retrieval boost !) 5/N
2
0
8
@BlancheMinerva
@norabelrose
Are you sure you’re reading this right ? This just shows the updated algorithm goes higher in flops iso-hardware, and is not affected by sequence length too much, but this is not the attention throughput (else it would be in seq/s or similar).
1
0
7