
Alexandre Défossez
@honualx
Followers
3,888
Following
490
Media
57
Statuses
595
Founding researcher @kyutai_labs , with strong interests in stochastic optimization, audio generative models, and AI for science.
Paris, France
Joined March 2019
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
ALL EYES ON RAFAH
• 796778 Tweets
De Niro
• 387631 Tweets
Palestino
• 103996 Tweets
Fernando
• 92116 Tweets
#WWENXT
• 56714 Tweets
Thomsen
• 54044 Tweets
#خادم_الحرمين_الشريفين
• 50758 Tweets
Millonarios
• 38365 Tweets
Lali
• 37777 Tweets
Lali
• 37777 Tweets
Coronado
• 36152 Tweets
Lala
• 35490 Tweets
Renê
• 34261 Tweets
DAME MIL FURIAS
• 34159 Tweets
Paulinho
• 33737 Tweets
Peñarol
• 30256 Tweets
$BOOST
• 26582 Tweets
Wesley
• 18251 Tweets
Sudamericana
• 16133 Tweets
Josh Gibson
• 14829 Tweets
Jordynne Grace
• 13047 Tweets
#PumpRules
• 11494 Tweets





















I'm happy to release the v3 of Demucs for Music Source Separation, with hybrid domain prediction, compressed residual branches and much more. Checkout the code:
Here is a demo for you
@jaimealtozano
, I'm sure you'll enjoy the improvements!
14
112
604
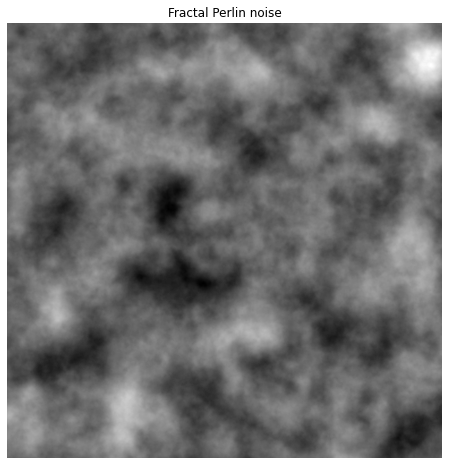
I recently discovered Perlin noise, a stochastic texture generation algorithm used to make realistic fire, smoke, clouds etc. It was developed by Ken Perlin for the CGI of Disney movie Tron in 1982 🤖 (1/N)
8
56
473
We have released our platform for source separation in music. We adapt Conv-Tasnet and introduce the Demucs architecture, leading to two state-of-the-art models surpassing all previously known methods such as Wave-U-Net, Open-Unmix or Spleeter.

13
143
472
We release stereo models for all MusicGen variants (+ a new large melody both mono and stereo): 6 new models available on HuggingFace (thanks
@reach_vb
). We show how a simple fine tuning procedure with codebook interleaving takes us from boring mono to immersive stereo🎧👇
17
83
410

With
@jadecopet
,
@syhw
and
@adiyossLC
, we are releasing EnCodec, a state-of-the-art neural audio codec supporting both 24 kHz mono audio and 48 kHz stereo, with bandwidth ranging from 1.5 kbps to 24 kbps 🗜️🎤🤖
8
76
246
Really excited to be part of the founding team of
@kyutai_labs
: at the heart of our mission is doing open source and open science in AI🔬📖. Thanks so much to our founding donators for making this happen 🇪🇺 I’m thrilled to get to work with such a talented team and grow the lab 😊


Announcing Kyutai: a non-profit AI lab dedicated to open science. Thanks to Xavier Niel (
@GroupeIliad
), Rodolphe Saadé (
@cmacgm
) and Eric Schmidt (
@SchmidtFutures
), we are starting with almost 300M€ of philanthropic support. Meet the team ⬇️

18
164
757
13
6
212
Today we release MusicGen, a text-to-music auto-regressive model built on EnCodec. It also supports optional melody conditioning based on chroma-gram extraction! It requires only 50 autoregressive steps per second of audio. Really fun to remix known tune in all genre 👇 + 🧵

We present MusicGen: A simple and controllable music generation model. MusicGen can be prompted by both text and melody.
We release code (MIT) and models (CC-BY NC) for open research, reproducibility, and for the music community:
36
424
2K
5
44
194
As a PhD student and RS, FAIR was a magical place to be in:
- incredible mentoring in all fields of AI🧑🏫
- access to resources and having my own research agenda 🧭
- free and encouraged to publish and open source 📖
For a lot of us there it was a transformative experience 🧑🏻🚀

4
7
180
We are releasing the code for our Interspeech paper "Real Time Enhancement in the Waveform Domain" with
@syhw
and
@adiyossLC
. Watch our live demo . Want to try it? Checkout our repo (1/2)

7
52
175
Official MusicGen now also supports extended generation (different implem, same idea). Go to our colab to test it. And keep an eye on
@camenduru
for more cool stuff!
Of course, I tested it with an Interstellar deep remix as lo-fi with organic samples :)

Good news 🥳 Now we can generate more than 30s, Thanks to rkfg ❤ and Oncorporation ❤
Please try it 🐣
🦆 🖼 stable diffusion model Freedom Redmond by
@artificialguybr
10
70
231
6
33
173
I'm releasing `julius`, a package for fast and differentiable resampling of 1D signals in PyTorch.
It uses the same algorithm as resampy but optimized for the case where the ratio of the old and new sample rate is a simple irreducible fraction.

1
26
144
We do not have a demo booth at
#NeurIPS2023
but the MusicGen demo is always online 💻 and all code is open source 📖, with
@jadecopet
and
@FelixKreuk
🎶🥁

2
29
123
Our work on decoding is now published in Nature Machine Intelligence! We release the code to reproduce our results (and improve on them) based on public datasets (175 subjects, 160+ hours of brain recordings, EEG and MEG) 🧠🔬🖥️


`Decoding speech perception from non-invasive brain recordings`,
led by the one an only
@honualx
is just out in the latest issue of Nature Machine Intelligence:
- open-access paper:
- full training code:
5
115
458
7
34
133
MusicGen is definitely good at EDM (chroma conditioning from Interstellar used + some EDM description). Sadly the Interstellar theme doesn't really make it through the Chroma transform...
11
21
110
@adiyossLC
@syhw
and I are happy to present our work: Differentiable Model Compression with Pseudo Quantization Noise 🗜️💾🤖 Our method, DiffQ, uses additive noise as a proxy for quantization, giving differentiability with no Straight Through Estimator👇
3
24
102
Wondering how Adam and Adagrad work for non convex optimization? Go read our paper with L. Bottou,
@BachFrancis
and N. Usunier with a 2 pages proof covering both and one message: Adam is to Adagrad like constant step size SGD to decaying step size SGD .
1
22
101
If you are interested in language modeling for audio 🔊/ music generation 🎶, remember that Encodec provides high quality discrete tokens that can be decoded to audio similar to Soundstream !
Both AudioGen and VALL-E built on it 😉
3
15
97
Looking forward to discuss open research at
@kyutai_labs
. If you want to work on large scale multimodal LLMs, come and talk to us, this is what we look like 👇☕️


Look for my
@kyutai_labs
colleagues at
#NeurIPS2023
if you want to learn more about our mission. We are recruiting permanent staff, post-docs and interns!
0
3
39
3
8
93
EnCodec, is now on 🤗 Transformers!Think of it as a low level latent space 🔮 inversible to audio 🔊 It also provides a discrete space for Language Models as used in our MusicGen model.
2
9
93
As I am writing my PhD thesis and glueing papers together, I needed to merge bibtex files, remove duplicates and rewrite the tex files to reflect these changes. In case this would be helpful to anyone, here is the code to automate this:

3
17
89
Really excited about this release! We provide all the tools you need to start training your own audio models or just play with the ones we provide🤖🎸🔊And amazing work by
@jadecopet
for the final sprint 🤾♀️🚀


Today we open source the training code for our audio generation and compression research in AudioCraft and share new models.
With this release, we aim at giving people the full recipe to play with our models and develop their own models!
4
26
146
5
9
84
Demucs is now available under the MIT license. I hope this can lead to new applications for this research 🥁🪕🎹🎤🌊
PS: I also released 8bit quantized models, for faster download 🗜️💾
2
24
81
Watermarking is an increasingly important component of gen' AI, ensuring a safe and detectable usage. With
@RobinSanroman
,
@pierrefdz
,
@hadyelsahar
et al., we release AudioSeal, a faster, less audible, and more reliable watermarking for audio.
🧵🔽 1/6


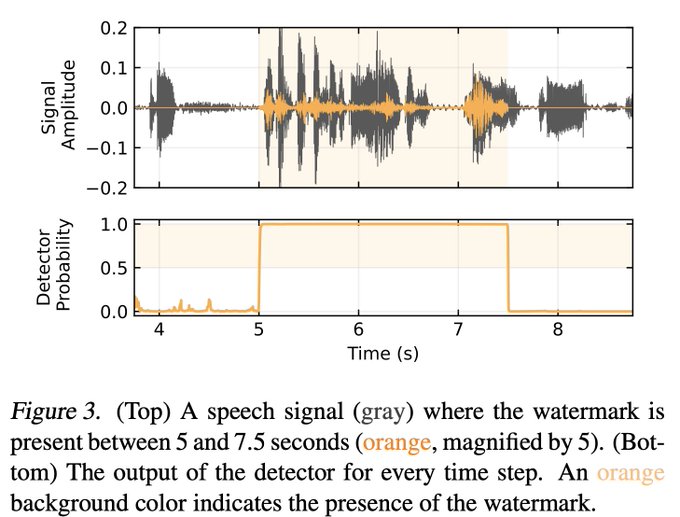
AudioSeal generates a watermark that hides in the signal. The detector is then able to flag watermarked parts of the audio with sample level precision.
2/n
1
2
10
3
11
81
I’m in at Neurips, 3 posters with my former team:
Simple and Controllable Music Generation, 10:45am Thu.
#603
From Discrete Tokens to HiFI Audio using MultiBand Diffusion, 5pm Wed.
#604
Textually Pretrained Speech Language Models
#543
same time.
Let’s talk about
@kyutai_labs
too!
2
3
79
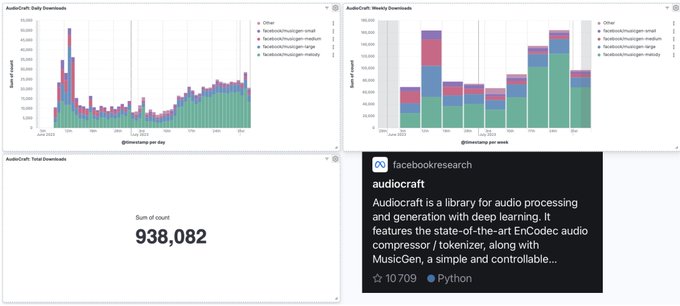
@sanchitgandhi99
is letting me know that we are about to cross the 1 million downloads for MusicGen! And AudioCraft has just crossed 10k⭐️ Really excited and touched to see such a fast adoption by the community ⚡️
@jadecopet
@FelixKreuk
@adiyossLC
@syhw
🙌
2
10
72
MusicGen is now supported in the 🤗Transformers library! Thanks a lot Sanchit for the integration. Next step: training / fine-tuning 🎯

MusicGen is state-of-the-art model for music generation by Meta AI 🎶
Now available on the main branch of 🤗 Transformers!
Check out the Colab here to get started:
4
58
218
1
9
68
Lucky to have
@huggingface
making everything easy and fast 😍 thanks
@reach_vb
and
@sanchitgandhi99
for your support!

Generate melodies with MusicGen & Transformers, but faster! ⚡️
import torch
from transformers import pipeline
pipe = pipeline("text-to-audio", "facebook/musicgen-small", torch_dtype=torch.float16)
pipe("upbeat lo-fi music")
That's it! 🤗
12
85
399
3
21
62
I want to build a small dataset of music descriptions (~40) matching how people use generative models in real life ⌨️🔊 If you want to participate, please comment below with your description amd the prefix "My description released under CC NC BY 4.0: ", thanks for the reposts 🙏
38
8
63
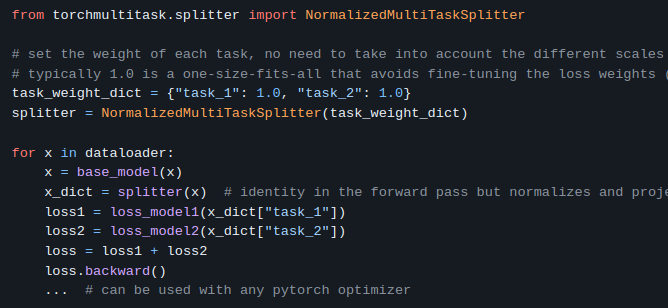
The multi task gradient balancing operator we introduced for training EnCodec is picking up steam 🚂⚖️
Think of it as having 1 Adam per loss term, except with no runtime or memory extra cost. No more lambda_1=0.001 and lambda_2=250 🤨🧘

I released today my mini-torch toolkit for multitask learning.
The most useful code-bit is minimal re-implementation of
@honualx
solution to auto-scale losses with very different scaling.
Happy to chat if someone's interested.
1
1
48
0
8
60
Glad to present our work with
@JeanRemiKing
,
@c_caucheteux
on non-invasive brain decoding🧠
1⃣ A contrastive loss is great for hard problems like decoding.
2⃣ It allows to leverage pre-trained Wav2Vec representations.
3⃣ We reach 44% top-1 acc. on MEG data on unseen sentences.
2
9
62
Demucs v4 is now on PyPI with HTDemucs now the default model. Use `-n mdx_extra_q` if you need he old one back, as for some tracks it might still be best. Also added an experimental 6 sources model `htdemucs_6s` with piano and guitar, although I observe some bleeding + artifacts.
3
11
60
Using a post-processing network with GANs help remove source separation artefacts. Maybe a sign that we should put less emphasis on the reconstruction SDR!

Music Separation Enhancement with Generative Modeling
abs:
project page:

0
30
189
1
6
57
The dignity of audio scientists finally restored after a short time with a vision based SOTA in music gen 🥲 Great work released by Google Brain with
@neilzegh
@antoine_caillon
@jesseengel
among others.

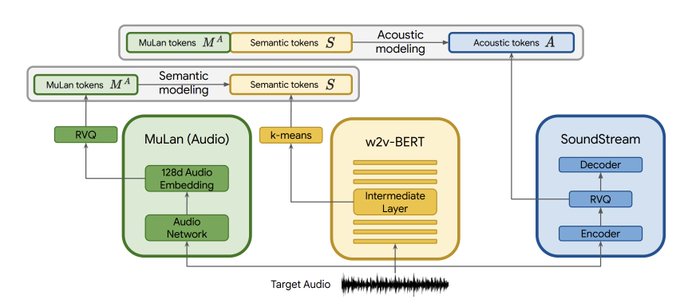
really well done, from SoundStream and AudioLM through MuLan to MusicLM 👏👏
the overall structure of MusicLM
= MuLan + AudioLM
= MuLan + w2v-BERT + SoundStream
2
21
253
2
9
55
Another day, another project. Seewav is a python tool to generate videos from audio files. It's not perfect yet, but it is already quite useful for slideshows and demos.
pip install -U seewav
seewav myaudio_file.mp3 # -> write to out.mp4
0
7
55
If you want to learn more about Demucs and source separation for music, this is for you 🌊🥁🪕🎹🎤
2
19
55
Demucs ranked 1st when trained on Musdb only (track A) and 2nd when trained with custom data (track B). Its SDR is nearly 1.5 dB better than before the competition. More info, code and paper coming up! A huge thank to
@musdemix
for the organization 🙏

The final leaderboards are live!
Take a look at
0
11
31
5
14
54
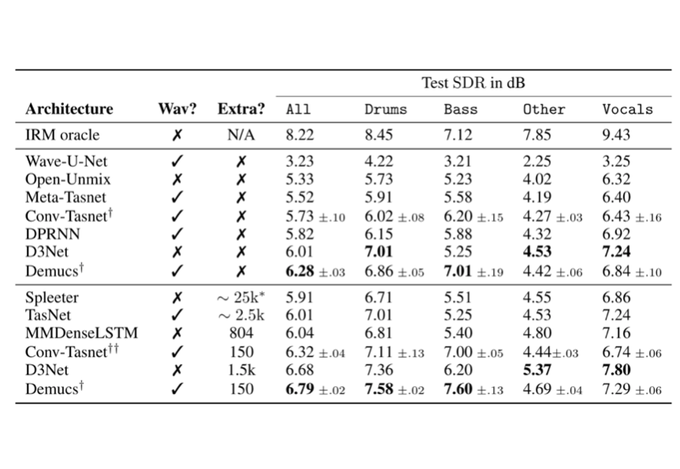
Is Demucs for music source separation out-fashioned already? With new data aug., on-the-fly resampling, and quantization, Demucs is 150MB, reaches 6.3 SDR (5.6 before) when trained on MusDB, and surpasses the IRM for bass by 0.5 dB with 150 extra songs.👇
1
16
52
Huge thanks to
@_akhaliq
,
@julien_c
and the team at
@huggingface
for providing extensive support for the demo 🤗
Meta just released MusicGen, a simple and controllable model for music generation
MusicGen is a single stage auto-regressive Transformer model trained over a 32kHz EnCodec tokenizer with 4 codebooks sampled at 50 Hz. Unlike existing methods like MusicLM, MusicGen doesn't not
46
429
2K
1
3
51
My favorite MusicGen remix from one of Bach's fugue, combined with the prompt "a light and cheerly EDM track, with syncopated drums, aery pads, and strong emotions". Make your own on HF or Google Colab (links in the repo ).
0
9
47
Happy to share our work on MEG brain activity prediction. This opens up exciting opportunities for deep learning based modeling of brain signals 🧠 🤖 📈
Deep learning improves the analysis of time-resolved brain signals by ... 3️⃣ folds!
Check out our latest paper by
@lomarchehab
*,
@honualx
*,
@loiseau_jc
, and
@agramfort
:
Below is the summary thread 👇
7
70
216
1
10
45
Demucs can now enhance your speech in real time, in the
waveform domain 🌊🗣️🎉➰📞👵. We study many tricks and their impact on perceptual quality and intelligibility: spectrogram losses, reverb aug., dry/wet balance. With
@syhw
and
@adiyossLC
.

5
15
45
I will be presenting our work on Transformers for Music Source Separation tomorrow, 6th of May, at ICASSP, during MLSP-P5 poster session on Source Separation, ICA and Sparsity, in the Garden P6 area from 2pm to 3:30pm. Hope to see you there!

3
1
44
Demucs has reached 3k stars on Github 😊 Hopefully by the end of the year we should have new models released with more instruments 🎸 🎹
0
1
46
Thanks so much for making this journey happen
@RodolpheSaade
,
@ericschmidt
,
@Xavier75
. Excited to ship AI in the whole French and European ecosystem with you 🇪🇺🤖⚓️

Thrilled to announce the launch of Kyutai with
@Xavier75
&
@ericschmidt
, the 1st European AI research lab. Researchers & entrepreneurs will have all the resources they need to shape our future. Excited to delve into use cases for transport & logistics. Join us in the AI journey !



11
45
220
0
0
43
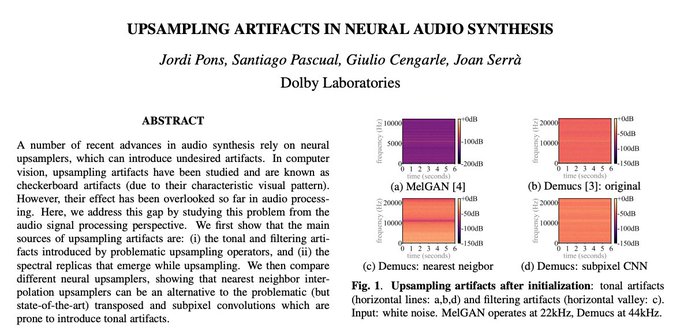
Very nice discussion on the artifacts of transposed convolutions for audio processing. I think that training mostly erase the initial artifacts, and the speed gain makes it a no brainer. Pons et al. suggest minor changes to remove those from the start!

Our last paper is out!
"Upsampling artifacts in neural audio synthesis"
arXiv:
Work with
@santty128
, Giulio Cengarle and
@serrjoa
.
3
34
193
2
9
42
I know its not the most fun in ML at the moment, but I finally made a Colab for easily playing with our Demucs based speech denoising model:

3
6
39
We are looking to release the training code and more during the summer
@danlyth
. This will go far beyond just compression ⚙️🔊

2
2
39
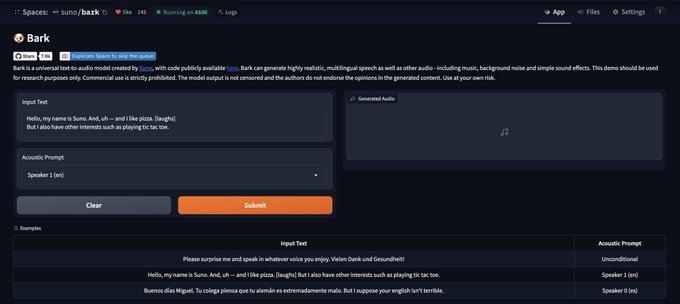
Bark is an awesome text to audio model by Suno AI. It combines two great papers on audio modeling: AudioLM by Google and Valle by Microsoft, and uses our open source EnCodec model as audio tokens. A sign that open research and open source are essentiel for our field.
🐶 Bark
Bark is a transformer-based text-to-audio model created by Suno. Bark can generate highly realistic, multilingual speech as well as other audio - including music, background noise and simple sound effects. The model can also produce nonverbal communications like
29
200
976
0
6
38
I've just released two Hybrid Demucs baselines for the SDX23 music demixing challenge, featuring learning with corrupted labels or bleeding. To get started, head over to
cc
@sounddemix
@moises_ai
@aicrowdHQ

0
6
36
@deepwhitman
@techatfacebook
Spleeter is a spectrogram based method, while Demucs works directly on the waveform. While waveform methods used to lag behind in terms of quality, Demucs was one of the first to outperform spectrogram methods.
2
1
35
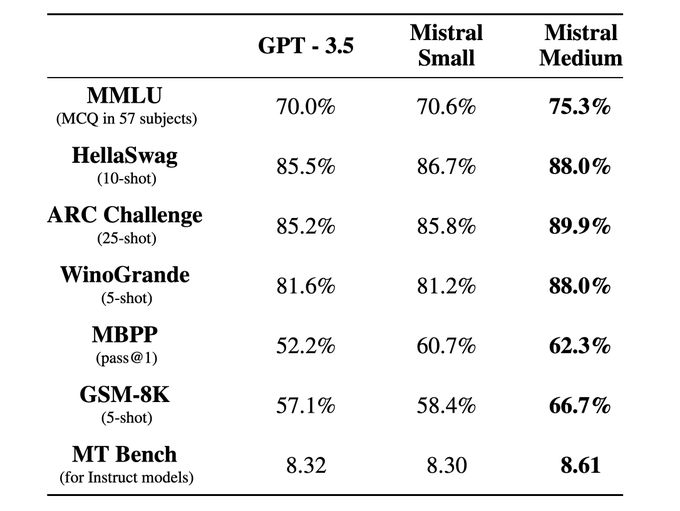
Really impressive performance from the latest Mistral model. Congrats to the whole team, and let’s that be some inspiration for the open source research in Paris.

More details about Mixtral can be found at
We are also very happy to announce "La plateforme" our early developer platform (in beta & limited access), to access our models through our API: (7/n)
5
12
222
0
1
31

What’s better than the hottest LLM? The hottest LLM running in Rust 😍

The new Mixtral 8x7b MoE model from
@MistralAI
is now available in candle - including support for quantized models. These can be run locally on a laptop with 32GB of memory, all this powered by
#rust
and
#opensource
!
7
62
434
0
2
30
Thanks
@gordic_aleksa
for the in depth coverage of Encodec, with paper and code! A good watch if your have some knowledge in deep learning and want to learn more on what is going on under the hood.

I cover
@MetaAI
's "High Fidelity Neural Audio Compression" paper and code.
With only 6 kbps bandwidth they already get the same audio quality (as measured by the subjective MUSHRA metric) as mp3 at 64 kbps!
YT:
@honualx
@jadecopet
@syhw
@adiyossLC
1/

2
18
116
1
3
29
Really excited to see a standard benchmark for going beyond 4 stems source separation! Thanks a lot
@moises_ai
for the release.
``Moisesdb: A dataset for source separation beyond 4-stems. (arXiv:2307.15913v1 []),'' Igor Pereira, Felipe Araújo, Filip Korzeniowski, Richard Vogl,
1
23
46
1
1
28
A new generative model for music generation 🎶based on the MaskedGIT approach: fast generation and ability to do in painting 🖼️
@hugggof
shows how you can generate infinite variations by keeping only one step out of P from the prompt.

You can now try VampNet on
@huggingface
spaces! Thanks
@_akhaliq
for helping getting it on spaces, and
@pseetharaman
@ritheshkumar_
and Bryan Pardo for making this dope project happen!
try it:
show me your coolest/weirdest VampNet loops! :)
3
6
24
0
4
28
Perlin noise can be extended to 3D or 4D. For higher dimensions, Perlin recommends using Simplex noise, but I didn't go that far.
Source:
PyTorch notebook:
1
0
25
First, if you just want to play with it 💻🎶
Demo:
Repo:
Samples:
Demo in Colab:
Updated paper (@ Neurips 23 🥳):
Now keep on reading for the details 🤓

1
4
27
This a central part of our mission
@kyutai_labs
along with developing the next generation of deep learning modeling techniques. All the inspiring discussions we had at the
@huggingface
open source party yesterday show that this dynamics is only getting started 💫
1
0
26
Try it now with `pip install -U julius`, and find more information on the repository:
2
1
26
@RobinSanroman
will present our work on diffusion vocoders at 5pm, poster
#604
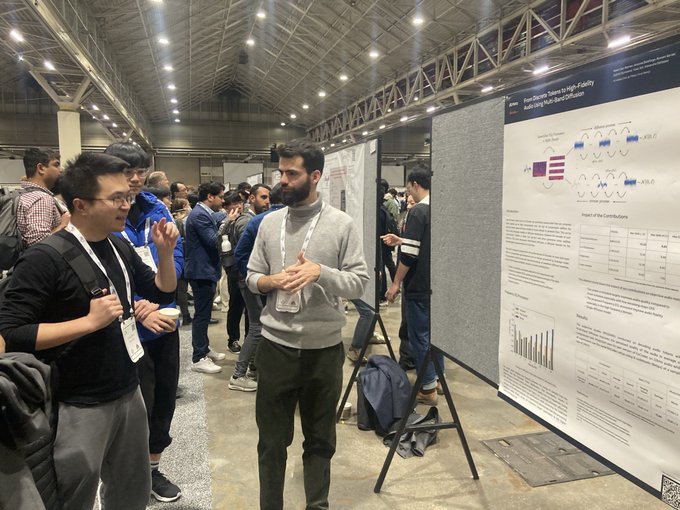
: "From discrete tokens to High-Fidelity audio using multi-band diffusion". 😶🌫️💻🔊
We use a diffusion U-Net conditioned on EnCodec tokens to replace the original adversarial decoder.
🧵 1/6
3
6
25
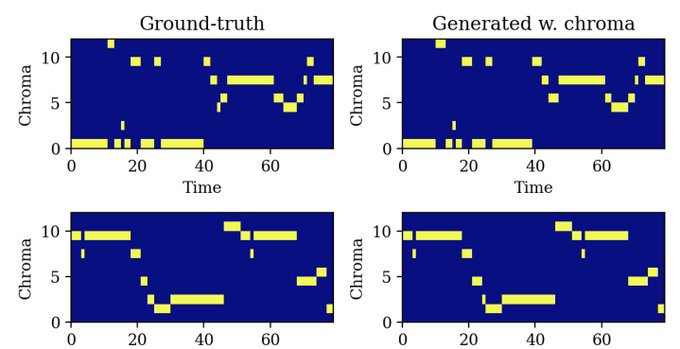
Then, we introduce some optional chromagram based conditioning. This can be computed for any track, and gives a rough idea of the tune of a track, thus allowing easy and controllable "remixing" of any song you like.
Play with it on our HuggingFace demo 🤗:
0
1
23
I know some of you noticed the “ht” branch on the Demucs repo a few weeks ago.
@simonrouard
great work is finally out, showing that multi domain Transformers perform great on music source separation when using an extended dataset.
0
3
22
I'll be presenting this work at the
@ismir2021
MDX workshop on Friday at 12:50 UTC. Other winning teams from the contest will be presenting as well, including
@WOOSUNGCHOI3
and
@LiuHaohe
.
A huge thank to the workshop organizers
@faroit
,
@AntoineLiutkus
.
1
4
21
Great upsampling model for all audio modalities by
@LiuHaohe
based on the AudioLDM design 👏↗️🔊
First extends the mel-spectrogram with latent diffusion then generates a waveform with HIFIGan.
Maybe diffusion for the last stage could be nice too (but slow) 🤔


0
0
21
Love this ! Using MusicGen for quick prototyping and enriching actual production is a great use. Most of the skill and magic still comes from the producers 💫

by
@NimOne510
@BigDaddyCh0p
We're just at the beginning, we had lil' data
But A.I. ain't replacing artists anytime
A.I. ain't those guys creativity I tell ya
They even turn A.I. brain farts into arts
h/t
@Thom_Wolf
for the link
2
5
28
0
0
19
Impressive jump in SDR on the MusDB HQ dataset (+0.6dB, and an extra 0.7dB with unsupervised data) using multiple DualPathRNN on frequency bands.
``Music Source Separation with Band-split RNN. (arXiv:2209.15174v1 []),'' Yi Luo, Jianwei Yu,
0
1
18
0
0
18
The key idea is to sample a random vector field over a coarse grid, and compute its integral over a finer grid of pixels. Perlin provided an efficient algorithm, where the value at each pixel is computed from a specific interpolation of dot products with the 4 nearby vectors.
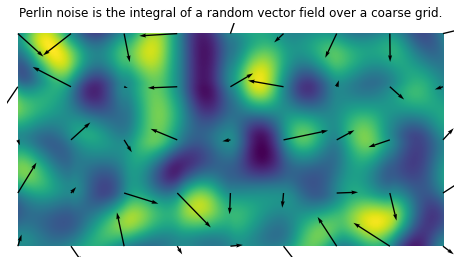
1
1
17
𝜋 in 1 tweet (up to 1e-12 error):
q,p,g,pi = 1,0,1e-5,0
while 1:
nq = q + g*p
np = p - g*nq
if (pi > 0)*(np*p <= 0):
g /= 10
if g:
continue
else:
break
q,p = nq,np
pi += g
import math
print(abs(pi - math.pi))
1
2
17
In order to achieve a smoke like structure, one can sum Perlin noises with different grid sizes, adding finer and finer details, and giving the texture a fractal structure.

2
0
16
Neat approach to training free multimodal labeling from pretrained unimodal models and small dset of paired text images. Given a new image I, compute its cos sim. with all I_k in the dset -> C_I. do the same for a new text T with all T_k -> C_T. Now you can dot prod C_I and C_T.

Next we compute new representations made of cosine similarities. We call them relative representations (rel-reps)
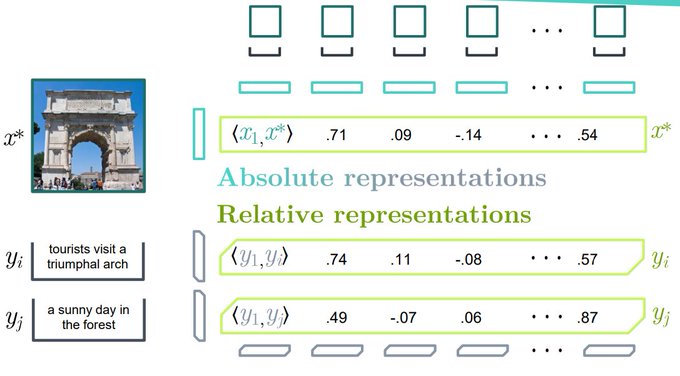
1
0
10
0
1
16
@pozzoli_lucas
@musdemix
I will release the code and models for the
@musdemix
workshop at ISMIR on the 12th of November. The workshop will be a cool place to learn about the technology if you are curious.
2
1
16
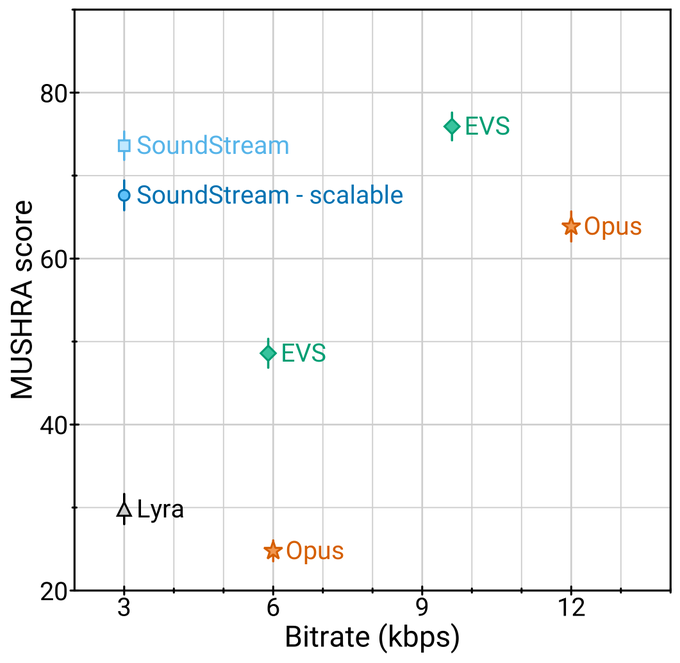
Who needs 5G when you can compress audio with Soundstream? 😍 next one is Videostream?
Check Soundstream, our neural audio codec:
* outperforms Opus & EVS on speech & music w/ up to 4x fewer bits
* scalable: 1 model for all bitrates
* runs real-time on 1 smartphone CPU
* controllable denoising
Paper:
Samples 🔊 :
1/5
7
13
89
0
1
15
Finally we provide an easy to use and generic API to apply our method to any architecture.
Check the repo and paper for more:
(5/5)

1
1
14
Waveform based self supervised representation like Wav2vec are rich, explaining both low level processing in the auditory cortex, and semantic processing from the prefrontal cortex. Congrats
@c_caucheteux
et al.

Result 2: The hierarchy learnt by the algorithm maps onto the brain's: The auditory cortex is best aligned with the first layer of the transformer (blue), whereas the prefrontal cortex is best aligned with its deepest layers (red).
3/n

1
3
30
1
0
15
100h of all kind of sounds, human labeled and with clear licensing. That's exciting! 🤖

🔊Happy to announce FSD50K: the new open dataset of human-labeled sound events! Over 51k Freesound audio clips, totalling over 100h of audio manually labeled using 200 classes drawn from the AudioSet Ontology.
Paper:
Dataset:

5
85
263
1
5
14
Polyphonic midi transcription agnostic to the instrument. And light on top of that 🙂

Meet — a 🎹🎸🎻🪕🎺🎷🪗 🎤-to-MIDI converter that uses about 70 billion fewer parameters than those fancy neural networks.
#MachineLearning

1
40
129
0
0
15
Initializing an audio domain speech LM from a text LM gives a large perplexity boost! Latest work by
@MichaelHassid
et al.
Paper:

We also show that TWIST converges much faster. When using a 350M parameter LM, TWIST archives similar perplexity with only 1/4 of the training steps.
4/n
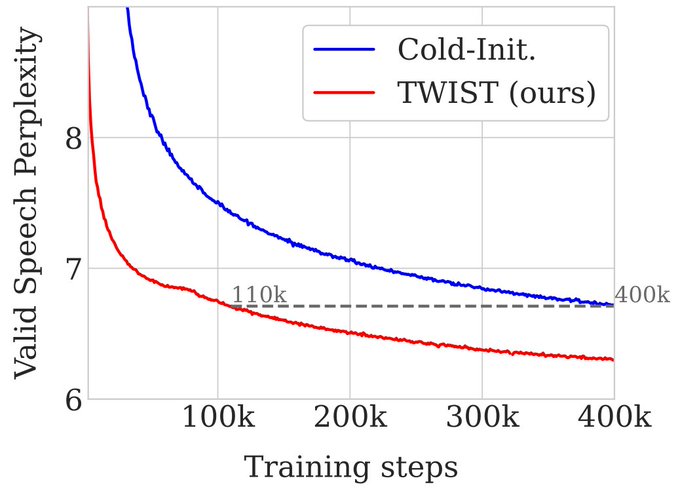
1
0
3
1
0
13
And on the other side,
@MichaelHassid
will tell you all about using warm start for your Speech LM at
#543
!

0
0
13
EnCodec is the first neural audio codec for hi-fi music, with strong ratings from human evaluators.

1
6
13
Now that’s some real non supervision 😻

New work: "Unsupervised speech recognition"
TL;DR: it's possible for a neural network to transcribe speech into text with very strong performance, without being given any labeled data.
Paper:
Blog:
Code:
3
96
467
0
2
14
Text guided generation for general audio 📜🤖🎧
We present “AudioGen: Textually Guided Audio Generation”!
AudioGen is an autoregressive transformer LM that synthesizes general audio conditioned on text (Text-to-Audio).
📖 Paper:
🎵 Samples:
💻 Code & models - soon!
(1/n)
96
966
5K
0
1
13
This repo is underrated, cross platform Lame MP3 encoder bindings in Python with binary distrib, as simple as `pip install lameenc`:

0
2
12
Impressive results for end-to-end classification from the raw waveform.
I will present LEAF, a learnable frontend for audio classification, at ICLR 2021.
* Learns filtering, pooling, compression, normalization
* Evaluated on 8 tasks, incl. speech, music, birds
* Outperforms mel-fbanks, SincNet, and others
* SOTA on AudioSet
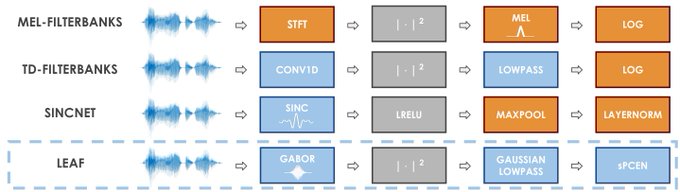
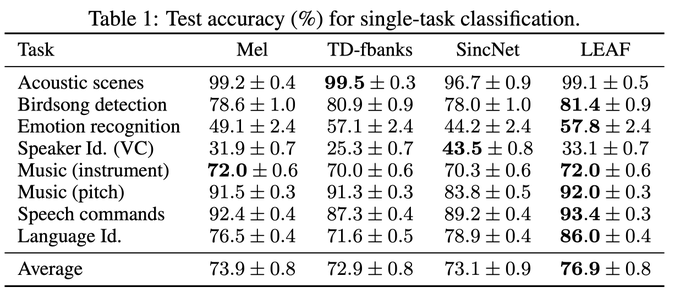
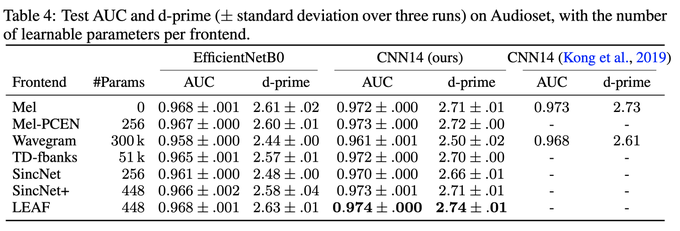
1
37
176
0
0
13
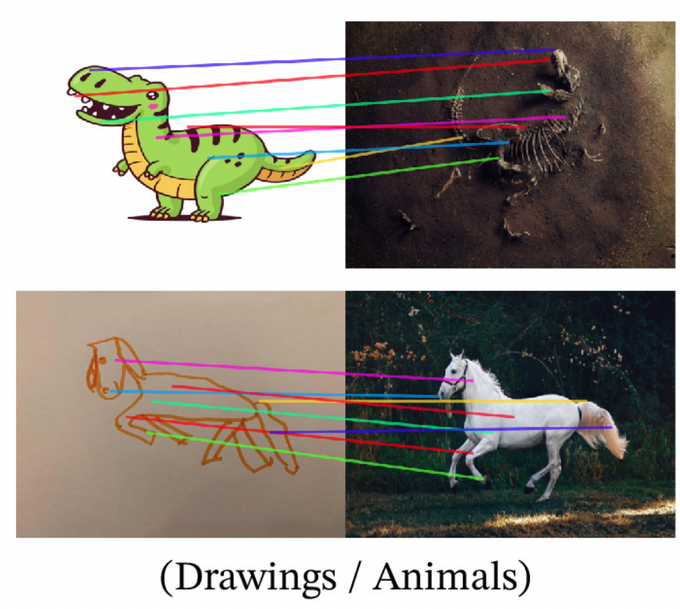
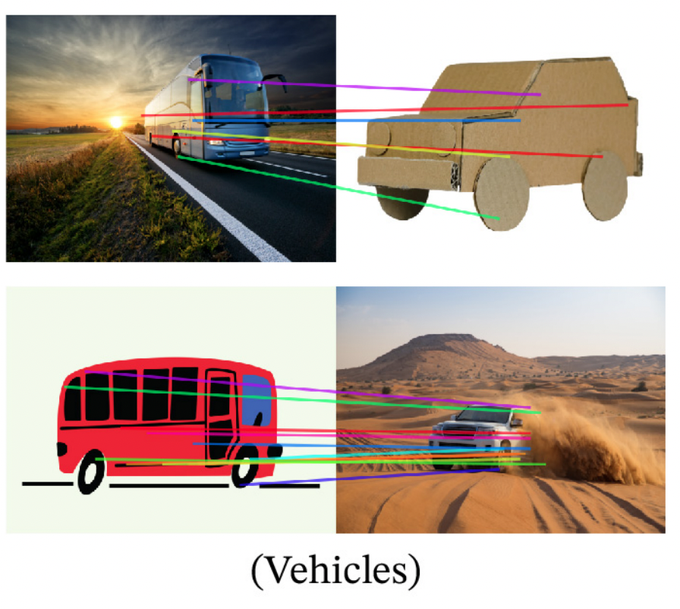
DinoV2 can do semantic key point matching for a wide range of objects, aka pose estimation, without being trained for that 😱
@TimDarcet
how reliable is that for downstream applications ?

6/ With these capabilities emerge new interesting properties. A very nice one is the ability to perform semantic keypoint matching between images simply by matching the closest features. This works across very different domains !

2
12
56
1
0
12
As we keep the same EnCodec, we remain compatible with our existing MultiBandDiffusion model. In fact all samples in the first video were generated using MBD as a decoder.
See which
@RobinSanroman
will present at Neurips 2023 too. One last sample:
1
1
12
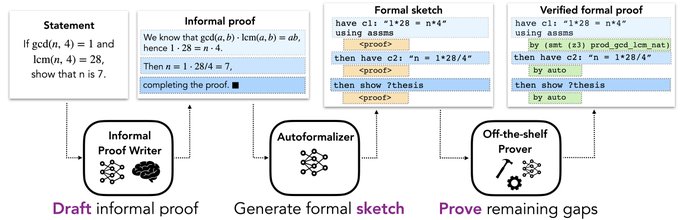
LLMs are nice but how can we trust them? For maths,
@AlbertQJiang
,
@GuillaumeLample
at al. show that they can work along formal provers to get the best of both world.

Large language models can write informal proofs, translate them into formal ones, and achieve SoTA performance in proving competition-level maths problems!
LM-generated informal proofs are sometimes more useful than the human ground truth 🤯
Preprint:
🧵
8
153
662
0
4
13
We performed subjective evaluation on music and speech, and EnCodec performs better than any existing solution.
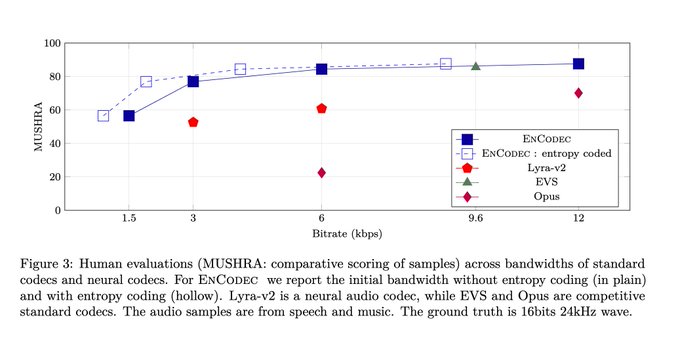
1
0
11
Having fun with waveform visualization and source separation 🥁🌊🙃
0
2
10
Thanks
@AudioStrip
for providing free and easy access to Demucs 😍

Demucs V3 is now available on . Offering much better separation, allowing you to sample your favorite songs easier. (Even 'Pac is excited).
4
4
16
1
0
10