
Robert Dadashi
@robdadashi
Followers
1,793
Following
428
Media
8
Statuses
170
reinforcement learning research @GoogleDeepMind , Gemma post-training lead
Paris, France
Joined September 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#Alikocistifa
• 255316 Tweets
BIENVENUE À PARIS APO
• 160788 Tweets
連休最終日
• 101128 Tweets
The Next Prince Q5
• 78217 Tweets
立憲民主党
• 55124 Tweets
더보이즈
• 47427 Tweets
野田佳彦
• 37938 Tweets
イチロー
• 34206 Tweets
#polis
• 31970 Tweets
Şeyda Yılmaz
• 30240 Tweets
野田新代表
• 18511 Tweets
グリフィン
• 18471 Tweets
野田さん
• 16391 Tweets
松井秀喜
• 14798 Tweets
坂本勇人
• 13987 Tweets
政権交代
• 13601 Tweets
KALAKAL LIVE ON ROADSHOW
• 13425 Tweets
どらほー
• 11807 Tweets
Last Seen Profiles




















Pinned Tweet

I am so proud to announce that:
- Gemma 2 27B IT tops all open weights models on Chatbot Arena, with a pinch of optimism in the face of uncertainty :)
- Gemma 2 9B IT sets a new frontier for models of similar size.
1/n

4
24
126
I am very happy to announce that Gemma 1.1 Instruct 2B and “7B” are out! Here are a few details about the new models:
1/11
13
70
375
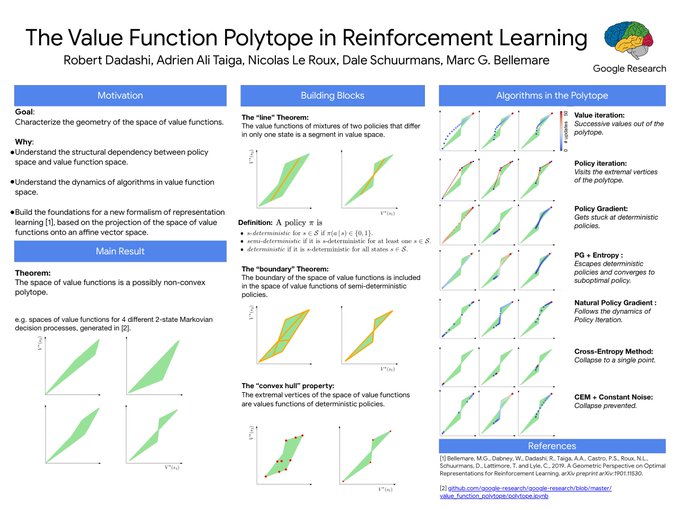
Just released a notebook to generate the figures in "The Value Function Polytope in RL": . It's fun to play with !
0
28
101
Very proud of our latest work: AQuaDem - Action Quantization from Demonstrations. The idea is simple:
1- Learn a state-conditioned quantization of a continuous action space from human demonstrations
2- Learn a controller in the induced MDP with a discrete action method, e.g DQN
2
21
82
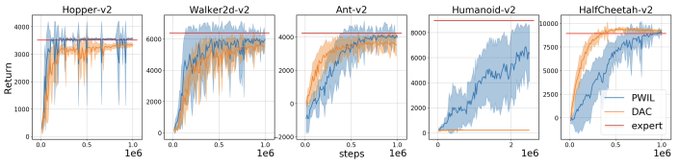
New paper out: PWIL ! A simple imitation learning method, which reinforces a reward signal based on a distance to expert demonstrations. Makes Humanoid walk with a single demonstration (below). 1/
3
10
83
We have just released the code for our latest paper on Imitation Learning: PWIL (). It’s simple and concise and yet performs strongly with MuJoCo environments. The code builds on
@deepmind
’s Acme (which is great !)
2
13
71
During my
@GoogleAI
residency I have been fortunate to work with my research mentor
@marcgbellemare
and other great collaborators on projects that I am weirdly excited about. This led to 2 papers accepted at ICML: (1/2)
2
4
67
I am so proud to see Gemma released today! I have had a fantastic time working on post-training and RLHF with an amazing team. Cannot wait to see what the community builds with these models!

Introducing Gemma: a family of lightweight, state-of-the-art open models for developers and researchers to build with AI. 🌐
We’re also releasing tools to support innovation and collaboration - as well as to guide responsible use.
Get started now. →

133
530
2K
3
9
57
The training data was pretty much the same as v1.0, but we switched the RL algorithm to something new. I hope that we will be able to disclose more about this in the future :).
6/11
1
4
57
I will talk about the *mysterious* polytopes in reinforcement learning at
#ICML2019
, Tuesday June 11th at 5:15pm in room 104 and at 6:30 at poster 119.
1
6
50
Very proud to contribute to making RL agents more accessible and reproducible!
Acme, a framework for distributed RL research, has been updated to be cleaner, more modular, and to support more agents - including offline & imitation. Try it yourself!
GitHub:
Quickstart:
V2 Paper: 1/

8
106
493
0
8
50
Similarly to v1.0, we enforced verbosity penalty on the models at training time even though it means worse performance on benchmarks. If you still feel like Gemma models are too chatty, prompting with a target word count can help.
7/11
2
1
37
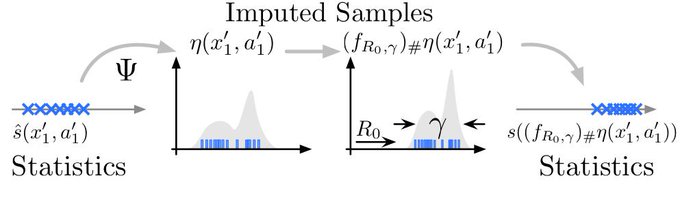
Proud to be part of this project tackling how we should think of statistics propagation & derive new algorithms in the context of distributional reinforcement learning

Mark Rowland's distributional RL paper on samples and statistics (& potential mismatch) is out -- big step towards understanding the method w/
@wwdabney
@RobertDadashi
S. Kumar R. Munos
0
23
80
0
3
34
Finally, make sure to correctly prompt the models following the Gemma IT chat template: f“<start_of_turn>\n{prompt}<end_of_turn>\n<start_of_turn>model\n”. If you notice abnormalities, or if you want specific capabilities improved in future versions, please DM me :)
10/11
2
1
35
This was done with my great collaborators:
@piergsessa
,
@suryabhupa
,
@leonardhussenot
,
@johanferret
,
@olivierbachem
and of course the Gemma team.
11/11
2
1
35
On the geometric characterization of discrete Markov decision processes:
On a new framework for distributional RL, that distinguishes «samples» from «statistics»:
0
3
33
Gemma 1.1 is making a big jump on the Arena leaderboard!


1
4
30
The new models are better across the board (e.g. quality, instruction following, factuality, coding, reasoning) while maintaining the same standards of safety. The gains are larger for “7B” than 2B.
3/11
3
1
31
Please be aware that lower resolution versions of the models (anything below bf16) have noticeable drops in quality.
9/11
2
2
30
In the same vein, Gemma models have a tendency to output itemized lists. If you don’t like bullet points, ask the model to “write paragraphs” in your prompt.
8/11
1
1
29
We mitigated the overuse of “Sure,” at the start of the model answers.
5/11
1
1
26
This update addresses some of the feedback from the community. We will continue to do so in the future :)
2/11
1
0
25
We fixed a multi-turn bug (v1.0 models sometimes refuse to answer when the user changes topic in the middle of the conversation).
4/11
1
1
24
New paper to appear at
#ICML2021
: Offline Reinforcement Learning with Pseudometric Learning (PLOff)
PLOff first learns a metric in the spirit of bisimulations using offline transitions, and uses it to derive a bonus preventing OOD action extrapolation
1/n

1
7
18
Exhaustive exploration makes sense when we have no prior about an environment (which most novelty based exploration bonuses assume). In this work, we use demonstrations to derive an exploration bonus, and show that we can extract the priors of the demonstrator.

Human behavior is driven by many intrinsic motivations: fun, fear, curiosity, competition, resource constraints...
Instead of pushing RL agents to carry out an exhaustive exploration by modeling curiosity, can we implicitly extract all intrinsic motivations from demonstrations?

1
8
25
1
3
18
It has been an absolute blast to lead this effort with my wonderful contributors:
@suryabhupa
,
@piergsessa
,
@leonardhussenot
,
@bshahr
,
@sabelaraga
,
@OlivierBachem
,
@johanferret
,
@alexandrerame
,
@mw_hoffman
,
@abefriesen
,
@charlinelelan
, Sertan, Piotr, Nikola, Danila,
10/n
1
2
18
It was great to collaborate with the RecurrentGemma team on post-training (with again, a colossal effort from
@piergsessa
)! I am so excited to see the applications that RecurrentGemma opens :)

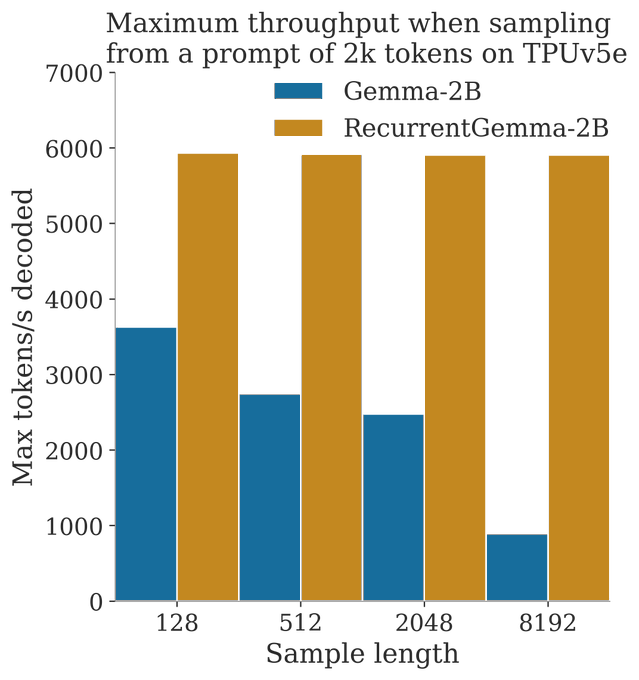
Announcing RecurrentGemma!
- A 2B model with open weights based on Griffin
- Replaces transformer with mix of gated linear recurrences and local attention
- Competitive with Gemma-2B on downstream evals
- Higher throughput when sampling long sequences
9
68
278
0
1
13
I recommend reading this, thanks
@natolambert
! Here are a few additional thoughts:

A brief summary on what REINFORCE is in terms of RLHF and history of RL.
The algorithm known as REINFORCE is really just the vanilla policy gradient approach. The name comes from Williams 1992, "Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement
3
16
121
1
1
12

Gemma 2 models are much better on all capabilities (coding, math, reasoning, if, safety) than the 1.1 version, but the most striking improvement is in the multi-turn setting. You can look at evals in the technical report, but the most convincing eval is… vibe checking.
5/n
1
0
11
Unsurprisingly, we added more data in all capabilities. In particular we added the LMSYS-Chat-1M dataset ( of course we stripped all model turns :) ).
3/n
2
0
12
We used a similar algorithmic recipe as Gemma 1.1, although it’s worth noting we used more teacher supervision (using a larger model) and performed model merging.
4/n
1
1
11
We have a project website where we detail the influence of all the hyperparameters considered (for the baselines and the introduced methods) and where we provide videos of *all* resulting agents.
Paper:
Website:
n/n

0
0
6
Besides basing these models on top of the new Gemma 2 pre-trained models, there was some adjustment in our post-training recipe.
2/n
1
0
9
Although I received a "Visual Intimidation Award" for most equations (thanks
@MILAMontreal
), there will be no equation in my talk.
2
0
7
Also, if you are interested in representation learning in RL, I would love to chat with you!
0
0
7
If you run these models with precision below bf16, you might see quality deterioration.
9/n
1
0
8
I guess I know my next research project

Ever wanted to play FIFA but still be able to call it "doing research work" ?
You're welcome.
0
6
41
1
0
6
As an interesting side effect, on prompts that require numerical computation, the model might respond with a response skeleton and ask the user if they want the numerical computations. This is an example of behavior that hurts performance on standard benchmarks.
6/n
1
0
8
Congrats
@aalitaiga
!
Congrats to my PhD student
@aalitaiga
for winning Best Paper Award at the Exploration in RL Workshop at ICML19, "Benchmarking Bonus-Based Exploration Methods on the Arcade Learning Environment"! Talk today, 11:30, Hall A.
#ICML2019
#ERL19
@AaronCourville
@cholodovskis
@LiamFedus
4
15
124
0
0
6
As in Gemma 1.1, the model tends to output lots of bullet points. This can be mitigated by prompting the model to output paragraphs instead.
7/n
1
0
8
We recover near-optimal expert behaviour on all tasks considered. Joint work with my great collaborators:
@leonardhussenot
, Matthieu Geist and Olivier Pietquin ! 6/
0
0
5
Once again, we made the conscious decision to limit the verbosity of the models at the cost of penalization on side by side evaluations. If you think that the models are still too verbose, prompt them with a target word count.
8/n
1
0
7
The quantization step can be thought of as a Behavioral Cloning with multiple actions as outputs (thus capturing the multimodality of the demonstrator’s behavior), while the second step is meant to select the “right mode” by interacting with the environment.
3/n
1
0
5
We only considered human demos and designed new algorithms for various setups: RL + demos, Imitation and RL + play data, that outperform SOTA continuous methods (in sample efficiency and performance). Plus, our algorithms result in agents that behave similarly to the human.
2/n
1
0
4
@EugeneVinitsky
In some way you can think of a reward model learned from preferences as a discriminator (and so RLHF really means IL). The SFT phase is what a lot of IL methods do in practice: start from the BC policy
1
2
4
2/n I do believe that on the algorithmic end (which is probably far less crucial than data quality), what really matters is to use an online method. I am pretty sure we will see an emergence of new RL methods for language but I bet they will all require sampling from the policy.
1
0
4
The second reason is that the quantization is based on the actions taken by the demonstrator. This makes it possible to capture the prior knowledge of the demonstrator, and limit the possible actions to demonstrator-like actions. Arguably, this also facilitates exploration.
5/n
1
0
4
Analytics have changed the game in basketball or baseball. Very excited to see the impact they will have on football.

.
@Polytechnique
&
@PSG_English
launch the “Sports Analytics Challenge”: an exclusive project that invites candidates worldwide to take part in the
#datascience
& sports performance
#challengexpsg
⚽️. Consult the challenge website for more information:

0
4
9
0
0
3
We compare PWIL with DAC, and show results for the original return of the task (not available in real settings) but also in terms of the Wasserstein distance between the agent and the expert. 5/
1
0
4
Check out our new paper: an extensive study of the experimental and design choices of GAIL-like methods !
Here is our new large-scale study on Adversarial Imitation Learning! 🤖
How to train your discriminator? How to regularize it? What direct RL agent to choose? How to optimize for training time? How does it behave with human data?
Check out the answers 🥳
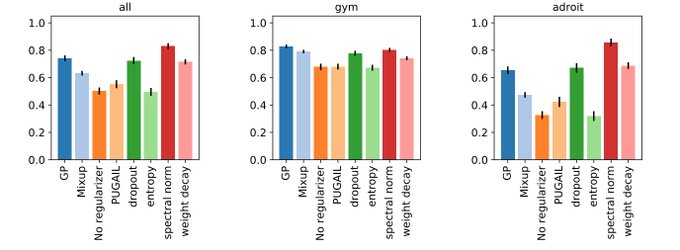
2
7
35
0
0
3
Contrary to adversarial IL methods, we bypass the minmax optimization problem and reinforce a non-stationary reward function that is not re-parameterized with interactions with the environment, and that relies on 2 hyperparameters. 4/
1
0
3
Why quantize in the first place? We argue that discrete action problems (with a reasonable number of actions) are more natural for VI-inspired methods, since the policy improvement step is immediate.
4/n
1
0
3
1/n TRPO vs PPO vs REINFORCE probably also matters less in the RLHF setting because we typically tend to use the BC policy as a regularizer (and start from it rather than tabula rasa).
1
0
3
3/n I am not a fan of DPO because it makes multi-objective harder.
1
0
3
@RorySmith
"There is no plan that contains Messi." Wrong, there is a one man plan named
@nglkante
.
0
0
3
This is joint work with my great collaborators
@shidilrzf
,
@leonardhussenot
, Nino Vieillard, Olivier Pietquin and Matthieu Geist.
n/n
0
0
2
@jishanshaikh41
I learned with David Silver's online lectures from his RL course at UCL. You can also check out the RL course from
@mlittmancs
and
@isbellHFh
on udacity.
0
0
2
Idea: at the start of the episode all expert state-action pairs are available. As the agent takes action a in state s, look for the closest expert state-action pair (s*, a*), pop it, and define a reward r = exp(- d(s, a, s*, a*) ). 2/
1
0
2
n/n Fwiw on Gemma, we did use a baseline with REINFORCE but I am not even sure this really matters because of the structure of the reward function in this setting (and as rightfully pointed out, the batch size).
0
0
2
Conceptually, PWIL defines a suboptimal transport between the agent state-action pairs and the expert state-action pairs. The approach relies on a distance in an MDP; in our case we use expert demonstrations to derive a distance. 3/
1
0
2
The intuition is to move away from the idea of estimating a parametric behavior policy, and replace it with a non-parametric bonus. This encourages the learning agent to remain close to the support of logged transitions, in terms of the learned metric.
2/n
1
0
2
0
0
1