
Soumith Chintala
@soumithchintala
Followers
186,905
Following
887
Media
180
Statuses
3,474
Cofounded and lead @PyTorch at Meta. Also dabble in robotics at NYU. AI is delicious when it is accessible and open-source.
New York City
Joined September 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Madonna
• 1268931 Tweets
어린이날
• 416277 Tweets
こどもの日
• 373383 Tweets
Canelo
• 246361 Tweets
NHKマイル
• 124164 Tweets
子供の日
• 105765 Tweets
#マリカにじさんじ杯
• 80951 Tweets
鯉のぼり
• 80523 Tweets
GW最終日
• 51529 Tweets
#ไขข้อขึ้นใจไปกับนุนิว
• 48864 Tweets
TOP10Worldwide MOONLIGHTiTunes
• 46457 Tweets
ジャンタルマンタル
• 42425 Tweets
アスコリピチェーノ
• 38597 Tweets
予選突破
• 29956 Tweets
マリカ杯
• 29096 Tweets
誕生日記念
• 27552 Tweets
#ユーフォ3期
• 27120 Tweets
ルメール
• 22837 Tweets
ボンドガール
• 21818 Tweets
Happy Easter
• 21683 Tweets
Patrick Drinks Milk
• 21069 Tweets
アフター
• 21035 Tweets
JR京都駅
• 19246 Tweets
महाराणा प्रताप
• 16847 Tweets
ロジリオン
• 16438 Tweets
Χριστος Ανεστη
• 14853 Tweets
Braverman
• 13082 Tweets
シェリン
• 12148 Tweets
予選通過
• 11322 Tweets
不審物発見
• 11087 Tweets
Wofai
• 10295 Tweets





















No More GIL!
the Python team has officially accepted the proposal.
Congrats
@colesbury
on his multi-year brilliant effort to remove the GIL, and a heartfelt thanks to the Python Steering Council and Core team for a thoughtful plan to make this a reality.

70
1K
5K
apparently Google laid off their entire Python Foundations team, WTF!
(
@SkyLi0n
who is one of the pybind11 maintainers just informed me, asking what ways they can re-fund pybind11)
The team seems to have done substantial work that seems critical for Google internally as well.…

123
563
4K
If you have questions about why Meta open-sources its AI, here's a clear answer in Meta's earnings call today from
@finkd

72
417
3K
It’s been 5 years since we launched
@pytorch
. It’s much bigger than we expected -- usage, contributors, funding. We’re blessed with success, but not perfect. A thread (mirrored at ) about some of the interesting decisions and pivots we’ve had to make 👇
26
279
2K
This is a new Microsoft.
- WSL CUDA/GPU Support
- native `winget` package manager
- VSCode, Edge, buying Github
They are listening. They are admitting failure. They are marching on.
Considering the size and age of the company, that's really impressive.
35
256
2K
i might have heard the same 😃 -- I guess info like this is passed around but no one wants to say it out loud.
GPT-4: 8 x 220B experts trained with different data/task distributions and 16-iter inference.
Glad that Geohot said it out loud.
Though, at this point, GPT-4 is…

Unexpected description of GPT4 architecture from geohotz in a recent interview he gave. At least it’s plausible.

14
92
544
57
387
2K
Can finally talk some GPU numbers publicly 🙃
By the end of the year, Meta will have 600k H100-equivalent GPUs.
Feel free to guess what's already deployed and being used 😉!

86
190
2K
anyone else feel burned out by a new AI breakthrough every week? 🤯
Trying to keep up but it goes by so fast
most of it is not easily or locally reproducible which adds to the stress 😂😂😂
61
102
2K
The first full paper on
@pytorch
after 3 years of development.
It describes our goals, design principles, technical details uptil v0.4
Catch the poster at
#NeurIPS2019
Authored by
@apaszke
,
@colesbury
et. al.

14
432
2K
PyTorch co-author Sam Gross (
@colesbury
) has been working on removing the GIL from Python.
Like...we can start using threads again instead of multiprocessing hacks!
This was a multi-year project by Sam.
Great article summarizing it:
13
321
2K
Here's details on Meta's 24k H100 Cluster Pods that we use for Llama3 training.
* Network: two versions RoCEv2 or Infiniband.
* Llama3 trains on RoCEv2
* Storage: NFS/FUSE based on Tectonic/Hammerspace
* Stock PyTorch: no real modifications that aren't upstreamed
* NCCL with…
91
198
1K
PyTorch's design origins, its connection to Lua, its intertwined deep connection to JAX, its symbiotic connection to Chainer
The groundwork for PyTorch originally started in early 2016, online, among a band of Torch7's contributors.
Torch7 (~2010-2017)
These days, we also…
43
279
1K
Based on all the user-request videos that
@sama
's been posting, it looks like sora is powered by a Game Engine, and generates artifacts and parameters for the Game Engine. 🤔

here is sora, our video generation model:
today we are starting red-teaming and offering access to a limited number of creators.
@_tim_brooks
@billpeeb
@model_mechanic
are really incredible; amazing work by them and the team.
remarkable moment.
2K
4K
26K
76
79
1K
Deep Learning is not yet enough to be the singular solution to most real-world automation. You need significant prior-injection, post-processing and other engineering in addition.
Hence, companies selling DL models as an API have slowly turned into consulting shops.
26
186
1K
this weekend has been very sad.
My friends at
@OpenAI
swore that it had become a magical place, with the talent density, velocity, research focus and (yet) a product fit that is really generational.
For such a place to breakdown in the cringiest way possible is doubly sad.
34
61
1K
* In 2016, I thought OpenAI was just shady, with highly unrealistic statements
* In 2020, I thought OpenAI was doing awesome work, but a bit too hypey, and the AGI bonds were weird
* In 2022, I fully changed my opinion and I think OpenAI is just phenomenal for changing the world.…
i loved my time at openai. it was transformative for me personally, and hopefully the world a little bit. most of all i loved working with such talented people.
will have more to say about what’s next later.
🫡
7K
10K
96K
17
76
1K
Maybe I can finally use matplotlib now without spending half a day googling the exact syntax and options!

24
119
1K
LLaMa-2 from
@MetaAI
is here!
Open weights, free for research and commercial use. Pre-trained on 2T tokens.
Fine-tuned too (unlike v1).
🔥🔥🔥
Lets gooo....
The paper lists the amazing authors who worked to make this happen night and day. Be sure to thank…

31
186
1K
Pretty excited about NVIDIA's Jetson Nano. 5W, $99 and a 128-core Maxwell sounds pretty great. This year is so good for embedded deep learning!
19
286
1K
Meta announces 2nd-gen inference chip MTIAv2.
* 708TF/s Int8 / 353TF/s BF16
* 256MB SRAM, 128GB memory
* 90W TDP. 24 chips per node, 3 nodes per rack.
* standard PyTorch stack (Dynamo, Inductor, Triton) for flexibility
Fabbed on TSMC's 5nm process, its fully programmable via the…
23
145
1K
NIPS Conference Registrations 2002 thru 2019.
[2018] War erupts for tickets
[2019] AI researchers discover time travel
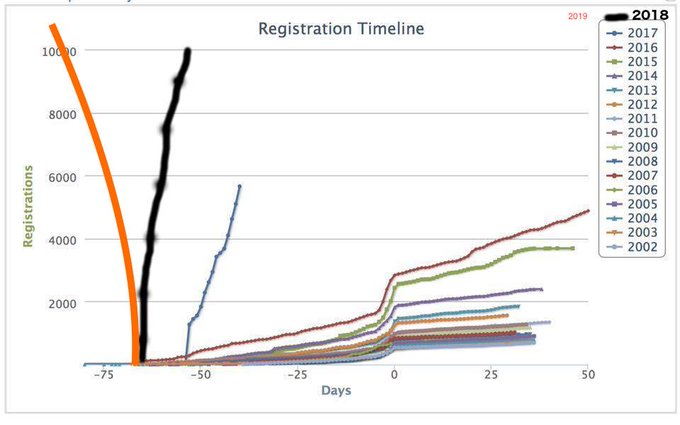
20
393
1K
Tensor Comprehensions: einstein-notation like language transpiles to CUDA, and autotuned via evolutionary search to maximize perf.
Know nothing about GPU programming? Still write high-performance deep learning.
@PyTorch
integration coming in <3 weeks.
13
431
1K
2013 me would not have had that loud GPU desktop from craigslist if Colab was around.
Colab Pro at $9.99 / month to get prioritized 24-hour stints of fast GPUs is a steal.
It is a product designed for individuals: login, create, go.
Thanks Google :)
14
93
1K
I'm fairly puzzled by $NVDA skyrocketing.
GenAI inference and fine-tuning will significantly outweigh GenAI training in overall compute.
When it comes to inference and fine-tuning, NVIDIA's advantage in software won't hold much significance. They will inevitably have to face…
78
140
1K
CodeLlama -- a version of Llama2 that was fine-tuned for code tasks is live now. Available in 7B, 13B and 34B.

17
210
962
Seems to solidly compete with GPT-4 on benchmarks.
Google has existing customers and surfaces to start the feedback loop, without worrying about adoption.
And Google will use TPUs for inference, so doesn't have to pay NVIDIA their 70% margins (like
@OpenAI
and
@Microsoft
has to…

We’re excited to announce 𝗚𝗲𝗺𝗶𝗻𝗶:
@Google
’s largest and most capable AI model.
Built to be natively multimodal, it can understand and operate across text, code, audio, image and video - and achieves state-of-the-art performance across many tasks. 🧵
174
2K
6K
18
83
958
googled for an error message in pytorch, read my own answer from a year ago. full circle! Then dug around some stats. There are 34,300 posts on the PyTorch forums, viewed 7.6 million times. I wrote 1800 of them. So cool :D
13
57
917
Rethinking floating point for deep learning - Jeff Johnson at FAIR
- proposes non-linear floating point math -- more energy efficient, accurate
- no retraining or quantization before deployment
- Verilog, C++, PyTorch implementations available
1
269
869
People getting mad about
@OpenAI
not releasing GPT4's research details....
the only tangible way to get back is to surpass GPT-4's results and release the details of how it was done.
literally any other kind of criticism is a mere expression of anger and a big distraction.
71
68
839
10 crazy years -- pytorch, detectron, segment-anything, llama, faiss, wav2vec, biggraph, fasttext, the Cake below the cherry, and so much more.
Can't say we didn't change AI and to an extent the world.

10 years of FAIR.
10 years of advancing the state of the art in AI through open research.
We're celebrating the 10th anniversary of Meta's Fundamental AI Research team and continuing that legacy by sharing our work on three exciting new research projects today.
Details below 🧵
28
157
794
23
60
833
Debates on PyTorch vs TensorFlow were fun in 2017.
There was healthy competition to innovate, and philosophical differences like Theano vs Torch, Emacs vs vim, or android vs iOS.
Now both products look exactly the same, the debates are nonsense and boring. Please stop.
19
105
819
Linux kernel push confirms, Intel to add dedicated neural network hardware ops into their future processors
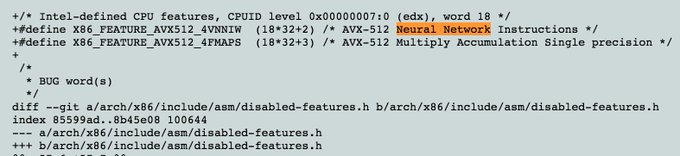
9
786
795
reading "AI News" (previously Smol Talk) is probably the highest-leverage 45 mins I spend everyday on catching up with what's going on in AI.
So much alpha, organized hierarchically; an exceptionally well curated (and summarized) daily newslettter.
Probably only suited for…
14
70
796
Perplexity has become my most used AI app by the end of 2023. I use it for fact-seeking questions -- including recent news / facts, summarizing opinions and recommendations on products and much more.
ChatGPT + Browsing can do similar stuff, but its like 100x slower, and is often…

We are happy to announce that we've raised $73.6 million in Series B funding led by IVP with participation from NVIDIA, NEA, Bessemer, Elad Gil, Jeff Bezos, Nat Friedman, Databricks, Tobi Lutke, Guillermo Rauch, Naval Ravikant, Balaji Srinivasan.
145
319
3K
17
56
786
Getting
@satyanadella
to talk about PyTorch...✅
.
.
(Satya and I went to the same high school, Hyderabad Public School)

13
46
775
cancel meetings on your calendar until it sparks joy!
14
132
765
PyTorch M1 GPU support (still in alpha) already being put to good use:

15
115
767
We just released AITemplate -- a high-performance Inference Engine -- similar to TensorRT but open-source.
It is really fast!
On StableDiffusion, it is 2.5x faster than the XLA based version released last week.
Get faster, more flexible inference on GPUs using our newly open-sourced AITemplate, a revolutionary new inference engine that delivers up to 12X performance improvements on NVIDIA GPUs & 4X on AMD GPUs compared to eager-mode within Pytorch.
Learn more:
10
152
754
19
116
730
In 270 days, the Department of Commerce will determine whether they will allow open-weights or not.
if you support open model weights and want something actionable to do, then figure out how to lobby your opinion to them.

35
171
717
Llama3 8B and 70B are out, with pretty exciting results!
* The ~400B is still training but results already look promising.
* Meta's own Chat interface is also live at
* TorchTune integration is shortly going live:


It’s here! Meet Llama 3, our latest generation of models that is setting a new standard for state-of-the art performance and efficiency for openly available LLMs.
Key highlights
• 8B and 70B parameter openly available pre-trained and fine-tuned models.
• Trained on more…
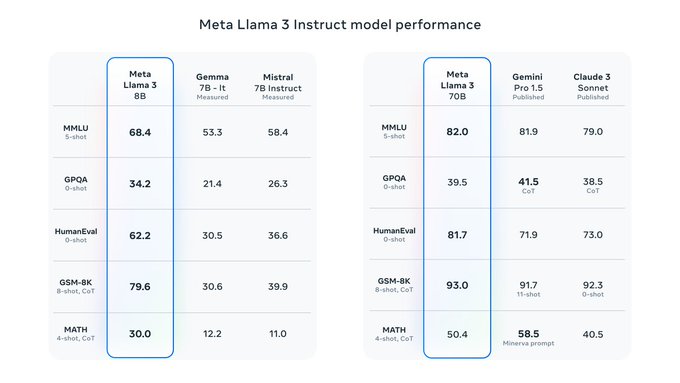
35
208
999
15
95
715
to my researcher friends (at
@openai
and those who watched this saga unfold) -- if you want to focus on doing solid *open* and published research, have access to lots of hardware -- there are a few options: Meta, Mistral, etc.
don't let your work get lost in corporate sagas!…
22
54
691
Llama3-70B has settled at
#5
. With 405B still to come next...
I remember when GPT-4 released in March 2023, it looked like it was nearly-impossible to get to the same performance.
Since then, I've seen
@Ahmad_Al_Dahle
and the rest of the GenAI org in a chaotic rise to focus,…

Exciting update -- Llama-3 full result is out, now reaching top-5 on the Arena leaderboard🔥
We've got stable enough CIs with over 12K votes. No question now Llama-3 70B is the new king of open model. Its powerful 8B variant has also surpassed many larger-size models. What an…

30
165
1K
17
48
681
ML Code Completeness Checklist: consistent and structured information in the README makes your code more popular and usable.
Sensible advice, backed by data.
Proposed by
@paperswithcode
and now part of the NeurIPS Code Submission process.
Read more:

6
152
653
use gradient magnitude as a signal for gradient importance.
Sort your gradients, find a threshold, clip your gradients, exchange sparse gradients, win.

10
236
642
I find it really cool that today, you can:
- go to
- select NVIDIA's open-source WaveGlow model
- open it in Google Colab
- run the model and listen to it synthesize speech
You can take that as a starting point and do further research.

4
129
641
Super excited to welcome the PFN team to the
@PyTorch
community. With Chainer, CuPy, Optuna, MNCore, their innovations need no introduction. The community is going to get even more fun! :)

[News] Preferred Networks (PFN) migrates its DL platform from Chainer to PyTorch. Chainer moves to maintenance support.
PFN jointly works with Facebook and the OSS community to develop PyTorch.
For more information, please look at the news release:
2
217
426
6
142
642
Small perks of joining the Linux Foundation!
We spoke about ML Accelerators and Linux driver-land issues :D

Two creators of passion projects that transformed the landscape of how we code today — Linus Torvalds and
@soumithchintala
meet for the first time, sharing a smile and a love for the open source community.
#PyTorchFoundation

18
68
685
1
40
636
Big announcement: PyTorch Foundation!
PyTorch has large core investments from many companies. So, we're creating a neutral foundation for securing assets and interests.
Technical Governance is separate & secure in a Maintainer model.
Here's more context:

7
108
644
Everyone's been waiting for it!
Thanks to Apple, working in closing collaboration with the core team for making this happen!
We’re excited to announce support for GPU-accelerated PyTorch training on Mac! Now you can take advantage of Apple silicon GPUs to perform ML workflows like prototyping and fine-tuning. Learn more:
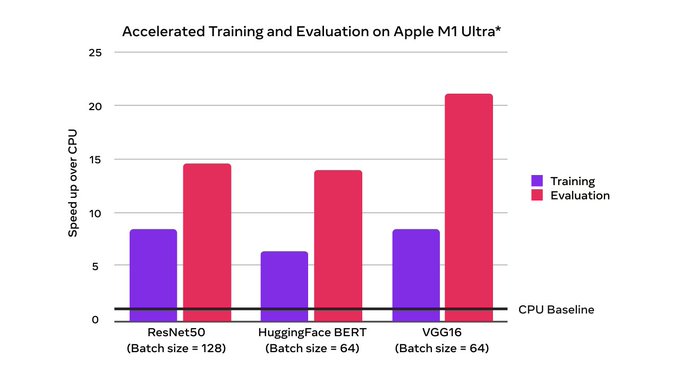
79
710
3K
7
47
630
- Take FasterRCNN
- Remove clunky NMS, Proposals, ROIAlign, Refinement and their gazillion hyperparameters
- Replace with Transformer
- Win!
Simplifies code and improves performance.
Nice work from
@fvsmassa
(torchvision maintainer) and his collaborators at FAIR.
We are releasing Detection Transformers (DETR), an important new approach to object detection and panoptic segmentation. It’s the first object detection framework to successfully integrate Transformers as a central building block in the detection pipeline.
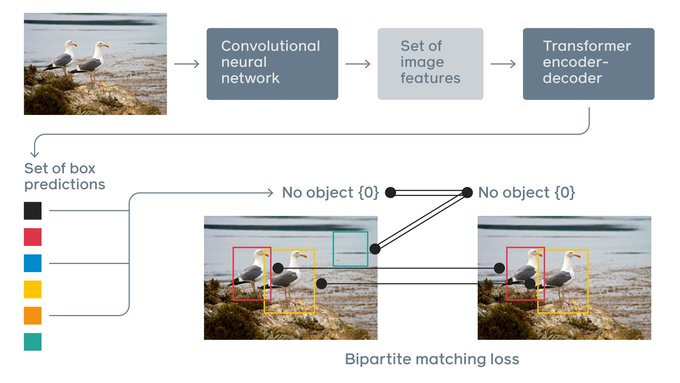
12
501
2K
5
104
630
The race has publicly begun!
- GPT still blows everyone else out of the water wrt coding abilities, with Claude coming a close second.
- Bard can't do coding yet (according to their FAQ)
- LLaMa / Alpaca, etc. is having a huge community-driven moment
28
53
632
Open LLMs need to get organized and co-ordinated about sharing human feedback. It's the weakest link with Open LLMs right now. They don't have 100m+ people giving feedback like in the case of OpenAI/Anthropic/Bard.
They can always progress with a Terms-of-Service arbitrage, but…

The pace of open-source LLM innovation and research is breath-taking
I suspect that open-source will soon become unbeatable for anyone except maybe OpenAI
Here's why
- Open-source community is way bigger than any specific company
- Safety lobotomy and fear of bad press will…
107
281
2K
27
82
626
"Everybody Dance Now" from Caroline Chan, Alyosha Efros and team transfers dance moves from one subject to another
The only way I'll ever dance well. Amazing work!!!
5
202
619
Dont miss out on internships. Get as many under your belt as you can before joining full-time!
I always wish I could go intern at Deepmind, Brain or NVIDIA for the summer just to know more about what it's like to work there, but it's no longer possible to do a 3-month stint.
21
71
608
Had a practical search today that Google totally failed to answer, failed too, but ChatGPT gave an answer that sounds plausible.
Now, the conundrum is that I don't know whether ChatGPT made stuff up or gave an accurate answer haha.

49
36
570
Cloud TPUs are out, we'll start sketching out
@PyTorch
integration. The cost is $6.50 per TPU-hour right now. Hopefully when they get affordable, we will be ready with PyTorch support :)
Thanks
@googleresearch
who have been very open to the conversation of
@PyTorch
integration.
4
115
562
NVIDIA releases an open-source Deep Learning Inference chip design (based on Xavier), with full verilog source:

6
304
555
No, GPT-3 wasn't trained in 11 minutes.
The GPT-3 architecture was trained on the C4 dataset to 2.69 log-probability in 11 minutes on 3584 H100 GPUs.
Don't focus on the "11 minutes" -- because it's like saying "ResNet-50 was trained in 5 seconds on MNIST to 80% accuracy"
18
47
553
This is not a research paper, this is a real-world product. Wow!
Been following
@runwayml
from their early days (and visited their offices last year). Great set of people, strong creative and product sense. Watch out for them.

Introducing Inpainting!
Easily remove any object from a video with a few brush strokes. In real-time. Like magic 🪄
Get started for free:
33
262
2K
6
59
555
very excited about the
@GoogleAI
office in Bangalore!

At
#GoogleForIndia
today, we announced Google Research India - a new AI research team in Bangalore that will focus on advancing computer science & applying AI research to solve big problems in healthcare, agriculture, education, and more.
#GoogleAI
263
2K
9K
4
38
545
Here's
@MosaicML
showcasing their results with
@PyTorch
2.0 + AMD for LLM Training.
They made "Zero Code Changes" to run on AMD.
MI250 is already trending well, and IMO MI300X will be very competitive.

Introducing training LLMs with AMD hardware!
MosaicML + PyTorch 2.0 + ROCm 5.4+ = LLM training out of the box with zero code changes.
With MosaicML, the ML community has additional hardware + software options to choose from.
Read more:
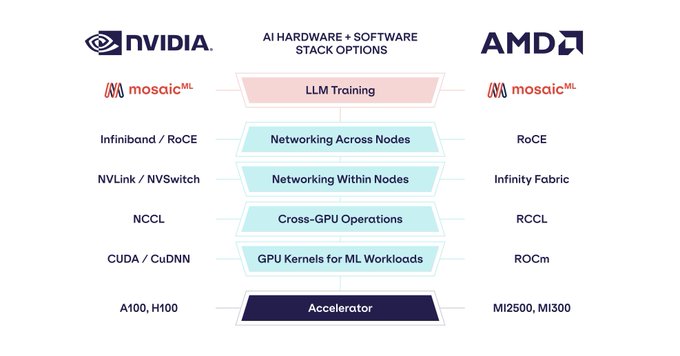
9
149
685
16
77
543
AI is just matrix multiplications.
Brains are just biochemical interactions.
Must be simple.
28
51
535
FAIR releases faiss. Many uses: text2image by searching through 1B or 100B images? RL Agent with VERY LARGE memory?

5
248
515
We're launching a FAIR Residency Program: a 1yr fixed-term research training program where you will work closely with researchers at FAIR. Deadline for applications is January 26, 2018. Do apply :)
11
169
514
Twitter, if you're listening --
1. get rid of the crypto bots
2. a feed that does some kind of Tweet TF-IDF. If someone tweets once a month, I want to see that as visibly as someone who tweets 10 times a day.
3. a feed API, so that we can build custom feeds again
18
30
509
Congrats to the DenseNets authors for winning the CVPR best paper award. Elegant work, well deserved!

1
182
501
Two exciting news from our robotics research today. 1/
DIGIT: a vision-based touch-sensor
Projects light into a gel in the "finger-tip".
A camera + model rapidly estimates the changes in image to compute localized pressure
Announcement that it is commercially available now!
Today, as part of a larger tactile-sensing ecosystem, we’re announcing two major advances: DIGIT, a commercially available touch-sensing hardware produced in partnership with GelSight, and ReSkin, a replaceable, low-cost tactile skin. Read more about our work in touch sensing:
17
84
612
12
88
497
The speech team @ FAIR released wav2letter++:
- a fully convolutional speech recognition system
- a C++ ML library on top of ArrayFire
They recognized very early that C++ was their best option and dived in much before PyTorch C++ API existed.
See:

9
113
501
Over the past year, I've been doing robotics at FAIR. It's been lots of fun.
My personal research goal is to build home robots: cooking, cleaning, etc.
(1/x)
11
22
490
Currently, we overfit to exploring AI techniques that work well on NVIDIA GPUs.
With the AI Accelerator sanctions on China -- one interesting result might be that China forks silicon and explores a different idea-space in AI techniques than the rest of the world.
23
44
476
this take is so bad, it's hard to comprehend where to start taking it apart!
For one, it starts with academic peer-review pathology: "paper too simple, so cant be innovative -- reject".
It equates "fundamental innovations" to "architectural innovations" which is like ughhh...

1) ChatGPT is super cool and fun but it's important to recall OpenAI made basically zero fundamental innovations. Actually the basic innovation behind the GPT software was made at Google Brain in Mountain View
133
421
3K
13
23
461
I've always wondered how to optimally read math-heavy papers. This seems like good advice:
5
157
453
Object Detection systems (commercial and academic) are trained on biased data
This disproportionally affects accuracy in lower-income households and continents like Africa & Asia.
Work by my colleagues at FAIR using the Dollar Street dataset from GapMinder

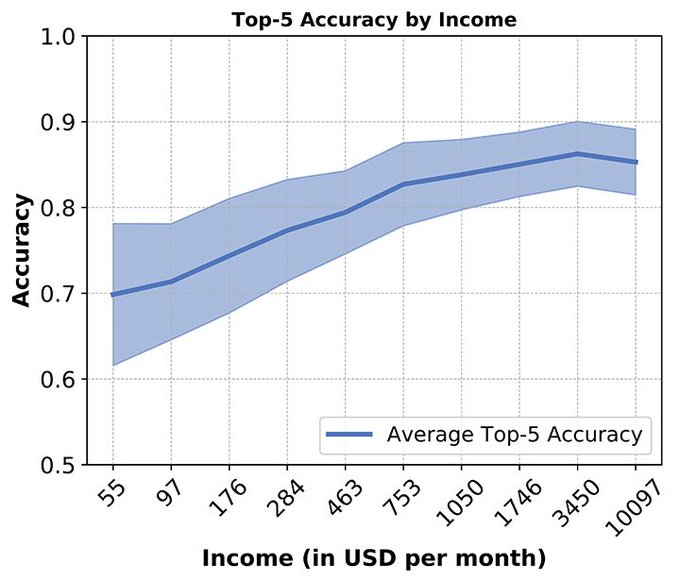
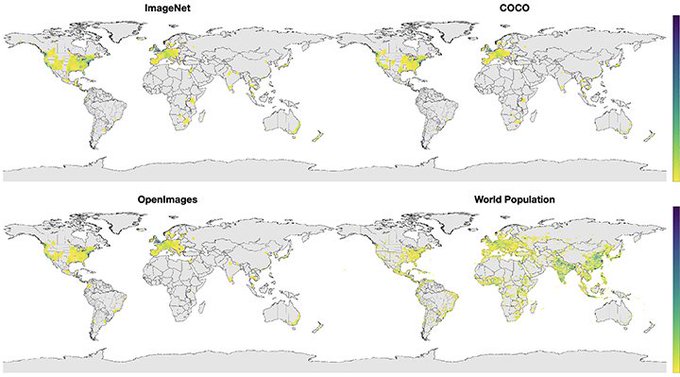
8
147
452
.
@OpenAI
showed an cool code generation demo at
#MSBuild2020
of a big language model trained on lots of github repositories
The demo does some non-trivial codegen specific to the context.
Eagerly waiting for more details!
Video: starting at 28:45
5
155
447
so excited to introduce
@PyTorch
2.0, a year in the works.
Still early, be gentle :)
We just introduced PyTorch 2.0 at the
#PyTorchConference
, introducing torch.compile!
Available in the nightlies today, stable release Early March 2023.
Read the full post:
🧵below!
1/5
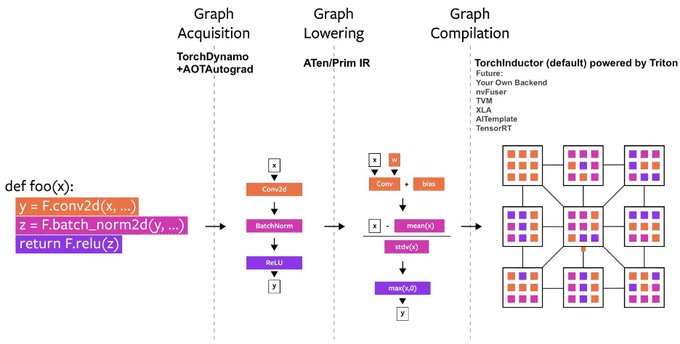
23
524
2K
8
50
443
thanks to
@JeffDean
and
@SingularMattrix
for their great leadership today; and
@fchollet
@dwarak
and many others at
@GoogleDeepMind
for quickly charting a good and aligned path forward together.
We can go back focusing on the unlimited amounts of good work ahead of us.
(Jeff,…
16
25
446
it pains me to see a poorly constructed benchmark coming from a credible source. I hope
@anyscalecompute
fixes things, and also consults other stakeholders before publishing such benchmarks. If I didn't know Anyscale closely, i would have attributed bad faith.
Lets dive into…

📈We’re excited to introduce the LLMPerf leaderboard: the first public and open source leaderboard for benchmarking performance of various LLM inference providers in the market.
Our goal with this leaderboard is to equip users and developers with a clear understanding of the…

10
45
169
8
45
309
Pre-trained Word Embeddings for 90 languages trained using FastText, on Wikipedia. Even has my native Telugu!

11
210
439
It's incredible to see how far
@pytorch
has come as a community, while preserving our core values of pushing for simplicity and innovation. (1/x)

2
55
427
Yesterday I read an 8-page paper. Breezed through it like a Netflix episode.
Clear, concise, and considerate of my time.
Somehow we've regressed to writing 30+ page epics (i'm guilty too).
16
7
435
PapersWithCode go brrrrrrr....

🎉 We've just crossed 5000 Datasets! 🎉
We now index and organize more than 5000 research datasets for machine learning. A huge thanks to the research community for their ongoing contributions.
Browse the full catalogue here:

15
489
2K
0
46
425
wow didn't know this was happening. this is huge!
scikit added support for pytorch and GPUs via array dispatch

New in
@scikit_learn
-- experimental support for building models on GPUs with
@PyTorch
-
@thomasjpfan
at
#SciPy2023

0
83
375
3
49
430
Wasserstein GANs pretty aptly summarized in this reddit comment:

3
185
428
Rodney Brooks explains that, according to early AI research, intelligence was "best characterized as the things that highly educated male scientists found challenging", such as chess, symbolic integration, proving mathematical theorems and solving complicated word algebra…
16
52
424
Congratulations Jeff and team!
In 2015 TensorFlow pushed framework engineering up a level and pushed everyone forward.
JAX seems to be doing the same in 2020, so thanks for continually funding great frameworks out of
@GoogleAI

When we released
@TensorFlow
as an open source project in Nov. 2015, we hoped external machine learning researchers & practicioners would find it as useful as we had internally at
@GoogleAI
. Very proud to see us hit 100M downloads!
2015 blog post:
16
149
956
2
20
413
the Cerebras chip is a technological marvel -- a real, working full-wafer chip with 18GB of register file!
It's probably one of the first chips where data "feed" will become the bottleneck, even for fairly modern networks. Congrats
@CerebrasSystems
!

10
110
411
gpt-fast now supports mixtral-8x7B, in addition to gpt/llama.
1000 lines of simple pytorch code blazing it out!

2
69
404
stuff that I worked on but can't talk about 😊

8
9
411
TF goes imperative with eager, pytorch getting static optimizations and production-ready with JIT and onnx. Worlds are slowly converging...
3
104
409
nothing short of mind-blowing!
holy shit, the future is getting crazy!
here is sora, our video generation model:
today we are starting red-teaming and offering access to a limited number of creators.
@_tim_brooks
@billpeeb
@model_mechanic
are really incredible; amazing work by them and the team.
remarkable moment.
2K
4K
26K
13
14
406
so many mainstreamers pumping AI now.
a good filter is to check if they were pumping crypto before lol.
10
37
403
@OpenAI
Join the folks in the business of pushing the limits of open-science:
@MetaAI
,
@Stanford
,
@StabilityAI
,
@huggingface
and others.
Help make this happen.
9
22
404
a birds-eye view into Facebook's datacenter infra
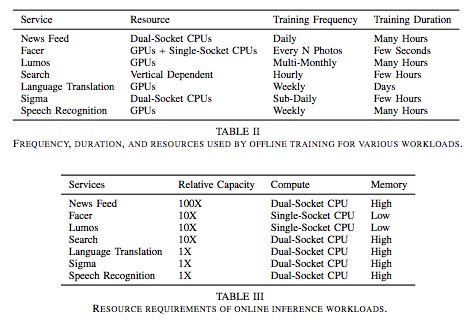
2
143
404
this Nature machine intelligence thing is fine exploitation of researchers. Please lets not make it a thing.
Its a decade when sci-hub has to exist hush-hush and Aaron Schwartz was legally ambushed because he downloaded a bunch of research. Let that sink in. Signed.

Several machine learning researchers have signed a statement regarding the upcoming launch of Nature Machine Intelligence. If you agree, I encourage you to sign this as well.
33
1K
2K
6
94
398
Spot-pricing on TPUs is getting good. We have prototyped TPU-PyTorch support (w. Google engineers), hammering coverage and performance now. Promising times....
Google Cloud TPUs now offer preemptible pricing at ~70% off the reserved instance pricing. This means, for example, that you can train a ResNet-50 model for ~$7.50 instead of $25, or a Transformer neural translation model for ~$13 instead of $41.
See:

4
184
558
5
85
402