
Cody Blakeney
@code_star
Followers
3,409
Following
860
Media
788
Statuses
11,878
Head of Data Research @MosaicML / @databricks | Formerly Visiting Researcher @ Facebook | Ph.D | #TXSTFOOTBALL fan |
Brooklyn, NY
Joined August 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#GranHermano
• 150919 Tweets
スタンプ
• 145431 Tweets
#JACKANDJOKERQ1
• 113234 Tweets
GPT-4o
• 112232 Tweets
#WWERaw
• 89269 Tweets
Luka
• 72679 Tweets
Dallas
• 47014 Tweets
Mavs
• 31538 Tweets
Diniz
• 27239 Tweets
Shai
• 25332 Tweets
Dort
• 21258 Tweets
Gunther
• 18873 Tweets
#NarcoCandidataClaudia60
• 17171 Tweets
スナック
• 14877 Tweets
スクエニ
• 14381 Tweets
Manny
• 13480 Tweets
Jey Uso
• 13147 Tweets
書類送検
• 12909 Tweets
Mavericks
• 11578 Tweets
Chet
• 10915 Tweets




















Pinned Tweet

It’s finally here 🎉🥳
In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯
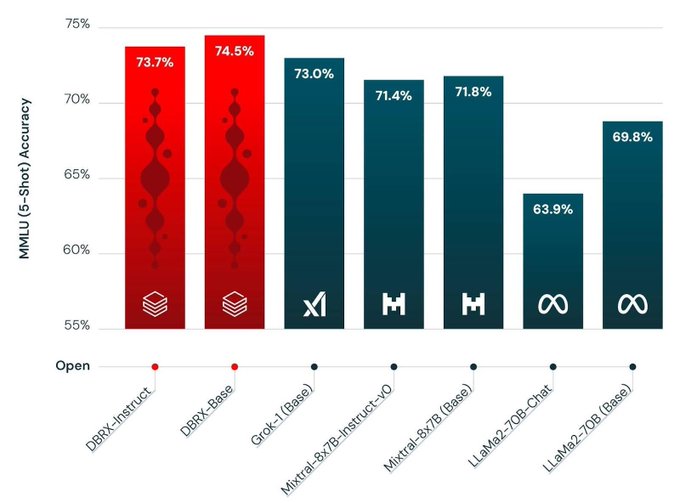
28
130
833
I decided to turn my error into an image with stable diffusion. That seems about right.

23
449
4K
I'm taking a graduate-level stats class for the first time. I now understand why all the stats people are mad at all the deep learning people.
63
169
3K
The next wave of startups seems to be PhD Students dropping out to build MLOps companies because they got good at training models and that turned out to be more valuable than their actual research
27
156
2K
People I work with have called me a “boomer” because I used tensorflow at the beginning of my PhD
47
25
889
Everyday an AI researcher runs a hyper parameter sweep and half or more of the runs essentially equate to lighting a pile of cash on fire.
14
27
462
Me at work for the past 2 weeks

It’s finally here 🎉🥳
In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯
28
130
833
2
13
391
@gdequeiroz
The best way I can articulate it is they care deeply about (or have worked hard at) proofs of things DL people just throw away. After several pages proving if you have an unbiased estimator of a parameter it's pretty annoying to see someone just doing a hyperparameter sweep.
6
5
349
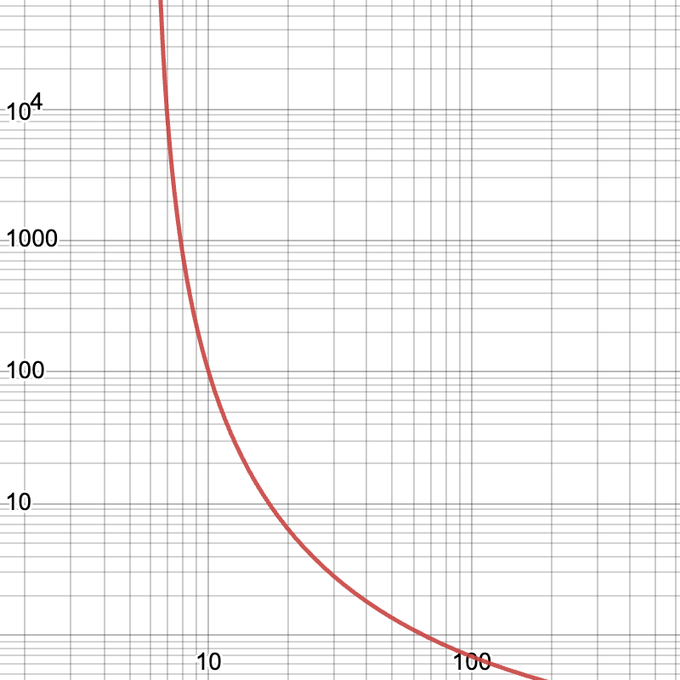
Ok, but hear me out. a 7B model with the same performance as a 67B model is worth 7837x as much.

On small overtrained models 💪
To reach the loss of a 67B model,
- A 33B model needs 2.3x compute 🚀
- A 13B model needs 25x compute 🤔
- A 7B model needs 7837x compute 🤡
- A 3B model can't match the 67B. Ever. 🪦
With love, from Chinchilla scaling laws.
35
52
488
15
14
226
I'm pretty sure the reason LLMs are not "funny" is that it specifically goes against their programming. Good jokes typically subvert our expectations. Which is the opposite of what autoregressively maximizing the highest likelihood next token is designed for.
36
14
214



@maxisawesome538
@TylerAlterman
Alpha meme -> zoomer news (duet) -> boomer news (actual news) -> millennial news (twitter)
2
5
192
I strongly believe that understanding how pruning/distillation works is the key to understanding how all neural networks work in general. I'm far less interested in "how many weights can we remove?" and more interested in "why heck can we remove them in the first place?!"
8
22
188
You asked for it and we listened! Today we are proud to announce the release of open-source MPT-30B. Same great architecture 1T tokens and now with 8k (and beyond) context! Try it now on our hugging face space.
8
33
183
SF is probably the only place on the planet you can be at a bar talking about tokenizers, and hear further down the bar someone else also talking about tokenizers.
Some people love this, some people loathe this.
15
5
176
That’s not entirely true. We released an open source 30B model, described in great detail the data used to train it, and the framework to train it.
Just add GPUs.
Of course if you pay us, we make dealing with the infra much easier 😉

I think people underestimate how hard it is to train a large model like GPT-3 and up.
Lots of challenges arise when reaching billions parameters, let alone 10B+ params (data management, training stability, parallelism...).
Only a few have succeeded so far and the recipe is not…
7
31
310
7
10
166
MPT-7B is back and better than ever!
8K context length: 😍
500B additional tokens: 🔥
Open Source: ✅

2
24
161


Google researchers have better twitters than Facebook Researchers. You can't convince otherwise. Do they get more free time? 🧐
3
5
138
One of my favorite genre of tweets is public radio hosts clapping back at people who asked them to do/not do exactly what they already did/didn’t

Thanks. This is such a great suggestion! In fact, the story DID read excerpts of the Declaration and then DID hear from “a diverse set” of Americans who relied on it through history. Too bad you didn’t listen! “Missed opportunity.” But it’s not too late:
9
12
295
5
7
123
You know machine learning isn’t even my job
And it is NOT LLMs which is a common misconception
Actually my job … is just … GPU

2
16
117
@AlbalakAlon
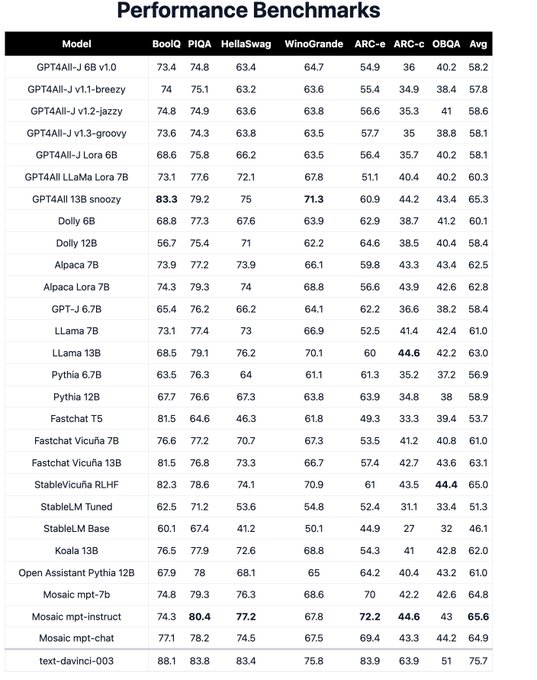
Yes! We trained a *new* MPT7B. Exact same arch and code. We were able to hit the same quality with half the number of tokens / training. Its not quite 2x reduction in training (larger tokenizer), but pretty dang close. We evaluated it on our newest version of guantlet.
6
11
118
Not only is it’s a great general purpose LLM, beating LLama2 70B and Mixtral, but it’s an outstanding code model rivaling or beating the best open weight code models!
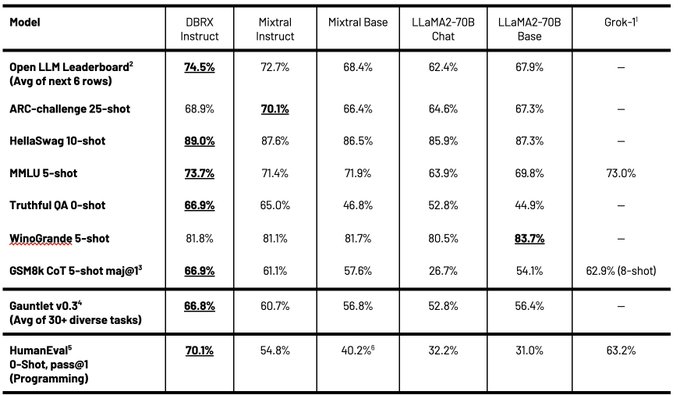
1
9
96
“What do you mean you didn’t sweep the learning rate????!!”

8
3
93
I still think the best use of chatGPT is just generating a template you can correct. Personally, editing requires a lot less mental strain than staring at a blank page.
5
5
88

@bartbing71
This isn’t the right take away but I hate the hassle the most when I catch cheating. Like … can you cheat better so I can enjoy my evening?
0
0
74
I'm absolutely floored by all the community-driven projects around MPT-7B 🤯. Are you using it for something? Tell us (
@MosaicML
), we would love to hear it!
3
5
70
I don’t have a SoundCloud but if you want to checkout the MLOps company I work for my boss (who hasn’t officially quit his PhD) would be very grateful
We are trying to change the math on efficient training. Want to train imagenet in 27 min? Find out how

1
2
70
@kairyssdal
how much do I need to donate to APM or Marketplace to have start the show off on a Wednesday saying "In Los Angeles, I am Kai Ryssdal it is Wednesday, my dudes!"
3
0
68
MosaicML ends, MosaicML Shippuden begins. Rest assured that the power creep is just getting started.

4
2
65
In light of recent releases, how do we feel about 8Bs with the same performance as 70Bs?
Ok, but hear me out. a 7B model with the same performance as a 67B model is worth 7837x as much.
15
14
226
9
4
67
If it turns out Mistral’s new MoE is just 8 copies of its 7B trained “Branch, Train, Merge” style and compiled into an MoE. I suggest we call it “Mixture of Bastards” MoB.
6
1
65
This price to train a 13B feels off. It only cost us ~$200k to train MPT-7B 🤔

I feel like a lot of the ideas about how to use AI are not in sync with the current cost realities. 1 MB per token! (from: )

0
5
24
8
8
62
Give the model a try yourself in our hugging face space 🤗

3
6
63
Is anyone out here still using step/exponential decay instead of cosine annealing or linear decay for learning rate schedulers?
3
5
60
Fun deep learning tip. Make your global batch size divisible by lots of numbers. 960 is way better then 1024. Then you can train on far more combinations of gpus if you want to soak up more capacity. 64, 80, 124, 120, 240, 480 so many options.
6
0
61
Oh no .. sudden drops in loss. This ResNet needs to be shut down ... just in case.

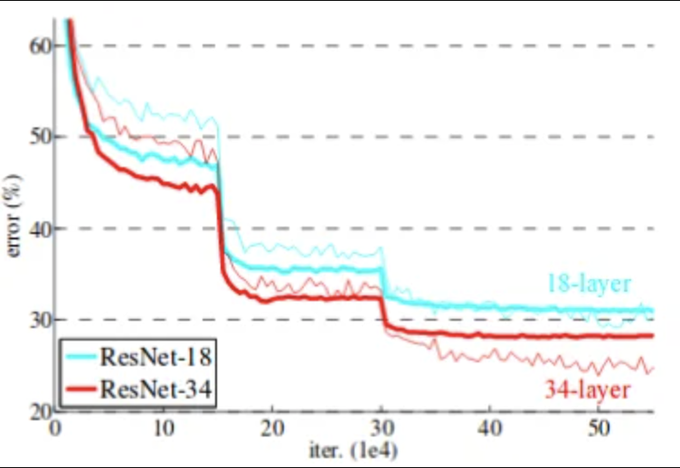
2
2
60
@chrisalbon
Docker is the solution. Fuck it, just send the whole OS and all the packages. I don't trust anyone.
5
2
61

I have to thank my amazing team (the
@DbrxMosaicAI
Data team
@mansiege
@_BrettLarsen
@ZackAnkner
Sean Owen and Tessa Barton) for their outstanding work. We have try made a generational improvement in our data. Token for token our data is twice as good as MPT7B was.
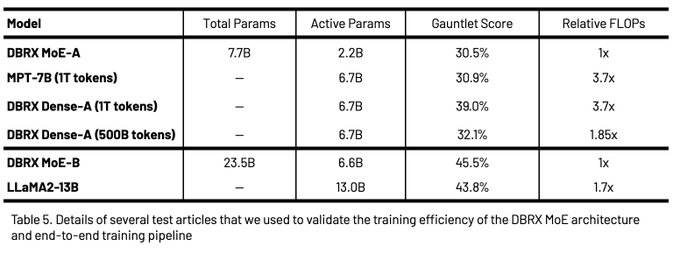
2
4
58
People writing DL papers with "Towards" in the title. Like bro where you headed?
7
7
57
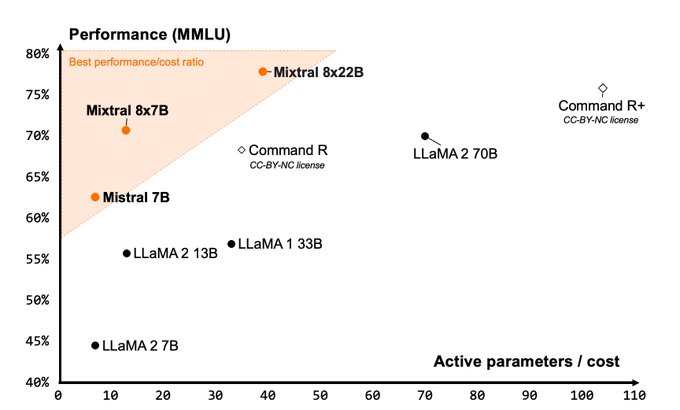
Feels like there is a model missing from this triangle. 🤔

Incredible performance and efficiency, all Apache 2.0 open, from the amazing
@MistralAI
team!!!
I’m most excited for the SOTA OSS function calling, code and math reasoning capabilities!!
Cc
@GuillaumeLample
@tlacroix6
@dchaplot
@mjmj1oo
@sophiamyang
3
4
71
4
0
57
People have been talking on twitter about how few people can train XXbillion param LLMs, but I wonder how many people know the dark arts of building great tokenizers.
9
0
53

wow! you got into that *fast*. Yup that all looks right!
Took a look at
@databricks
's new open source 132 billion model called DBRX!
1) Merged attention QKV clamped betw (-8, 8)
2) Not RMS Layernorm - now has mean removal unlike Llama
3) 4 active experts / 16. Mixtral 2/8 experts.
4)
@OpenAI
's TikToken tokenizer 100K. Llama splits…

25
174
1K
2
1
53

At me next time 😅


4
1
52
IYKYK 😉

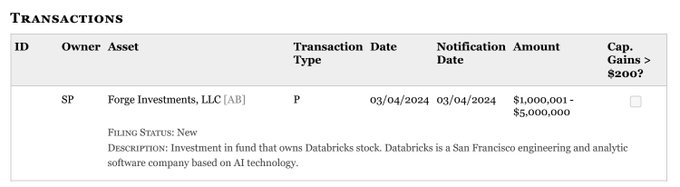
BREAKING 🚨:
Nancy Pelosi just bought $5M of the AI company Databricks
Unfortunately, Databricks is a privately held company and not available to be bought by the public
Sorry people, you don’t have access to this one.
294
2K
15K
3
1
50
Today is the first day of my big boy job. I'm excited to finally be full-time at
@MosaicML
! 🥳 (now excuse me while I go flood our cluster with new experiments)
7
2
48

I've made it y'all

Felt cute. Did some petabyte scale preprocessing. Might delete later.
4
1
41
4
0
48


Trained a model for a full week
But the results were total shit
Machine Learning is so much fun
Fuck my life, what have I done?
17
4
181
2
1
47
Python should be more like Zuck and give me threads.

Much of modern ML engineering is making Python not be your bottleneck.
98
138
2K
4
3
46
@ItsMePCandi
@caradaze
Just a guess. Spots are a zero sum game. Once too many tourists find out it’s harder for locals to go. 🤷♂️
2
0
43

@johnwil80428495
@UniversityStar
Well alot of us love people that are old or have compromised immune systems. If we do the right things we can save lives.
0
0
43
*correction, not open weights. It’s a commercial friendly licensed model. You’ll have to forgive me I was up late 😅 feel free to download it and try it yourself.

3
3
43
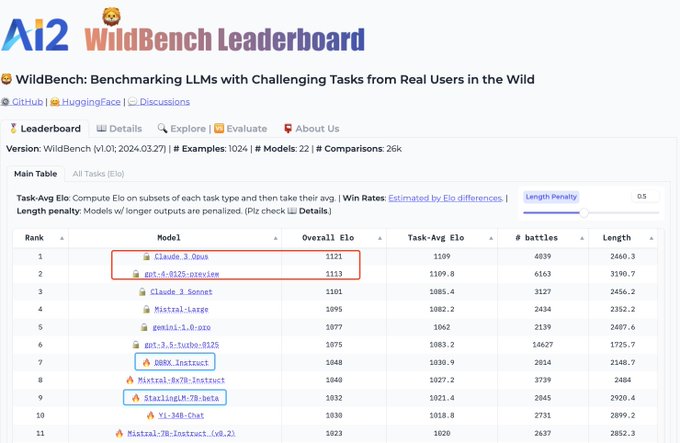
DBRX is the best open model on AI2 WildBench! 😀

🆕 Check out the recent update of 𝕎𝕚𝕝𝕕𝔹𝕖𝕟𝕔𝕙! We have included a few more models including DBRX-Instruct
@databricks
and StarlingLM-beta (7B)
@NexusflowX
which are both super powerful! DBRX-Instruct is indeed the best open LLM; Starling-LM 7B outperforms a lot of even…
3
32
127
3
5
42
@Tim_Dettmers
Truly the shame should go further up the author list.
That being said I think like 30-50% of deep learning papers of the last decade wouldn’t have been published if they had properly tuned baselines.
0
0
42
Felt cute. Did some petabyte scale preprocessing. Might delete later.
4
1
41


It’s coming back! The
@jefrankle
lost a bet with the unbelievably talented
@mansiege
and has been subjected to being rad. What an unfortunate turn of events.

Which head of research at an AI company has the craziest hair?
4
0
31
5
4
39
I think people some people (not necessarily Jesse) misunderstood why there is a lack of transparency. Meta isn’t afraid of transparency, or giving up secret sauce. Big players will not disclose their data until case law over copyright/fair use is better defined. That doesn’t mean…

This follows the trend of large organizations releasing models and promoting their capabilities, while not providing the information necessary to understand their behavior: the training data.
To be clear, this is expected, but also highlights the need for more transparency.
2
2
24
5
3
40
Words cannot express how excited I am about this.
@lilac_ai
is *the* best user experience I have found for exploring, cleaning, and understanding data for LLMs. I can’t wait to work with them to build the future of data!
Incredibly excited to announce that
@lilac_ai
is joining
@databricks
!
With Lilac in Databricks, data curation for LLMs will be elevated to the next level: Enterprise AI 🚀🚀
A huge huge to everyone who’s supported us on this journey ❤️
44
14
221
1
1
40

I can't believe it's finally happening. Tomorrow I don my wizard robes and become a Dr. Blakeney (again ... I'm still trying to figure out how that works). I'm gonna try and jump in the river if it isn't flooding. If y'all don't hear from me ... check the news.
2
0
20
9
1
38
Ok I just got around to taking the time to learn how to use
@weights_biases
. Wow what a game changer. I can't believe I put it off this long.
1
4
39
MI250s run out of the box with ZERO CODE CHANGES on llm-foundry 👀👀👀 huge shout out to
@abhi_venigalla
and
@vitaliychiley
for this one!

2
6
39
If you are hiring anything ML/NN related reach out to my boy. We were in the same PhD cohort. Half of my good ideas in my dissertation he helped me brainstorm. One of the best python programmers I know. Immigration laws in this country are bs and have him scrambling.

1
20
36
Me making memes all day to support the launch

It’s finally here 🎉🥳
In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯
28
130
833
0
5
37
@NaveenGRao
I feel like a python -> c/c++ translator would get you most of the way to what you want.
2
0
37
I cannot say enough how much I ❤️ love ❤️ our model gauntlet. Both for the speed at which it evaluates on its many tasks, and the thoughtfulness that went into organizing the tasks. It’s been a god send for us for selecting pre-training data and making modeling decisions.

How can the ML community measure LLM quality in a holistic and standardized manner?
The Mosaic Model Gauntlet encompasses 34 benchmarks, organized into 6 broad categories of competency, evaluated with our blazingly fast open-source ICL eval harness.
🧵👇
5
41
170
2
4
35

It’s hard for me for read the statements by OpenAI as anything other than a cynical advertisement for how powerful their products are, and to scare people off from throwing their hat in the ring.

"Sir, our AI system has detected an anomaly in the energy usage at your residence. The authorities will be over to inspect."

48
49
507
2
2
35
Kind of genius if this is what happened. Drop the big expensive model, let people analyze it and be amazed, then distill it to save costs.
*If* that is what occurred *and if* if has regressed this seems like a case where metrics didn’t capture the effects of compression.

Was GPT4 just lobotomized?
It responds to queries a lot faster but seems to perform a lot worse than just a few weeks ago (not following instructions properly, making very obvious coding mistakes etc)
Quite likely they replaced it with a distilled smaller model to save costs?
329
180
3K
5
1
34
Read all the details about how we built this model in our technical blog!

1
3
34
Oh and I’m pretty sure we are always hiring great PhD talent wanting to drop out and build the future of Efficient AI!
0
1
32
55 A100s!!!
55 H100s!!
55 INFERENCE DEPLOYMENTS!!
55 TACOS!!
55 COKES!!
100 TATER TOTS!!

what it feels like as an intern asking the researchers not to preempt all your training jobs
0
1
33
1
4
34

Fwiw I currently light piles of cash on fire for
@MosaicML
so that we can learn how to light smaller piles of cash on fire 🔥 (when we have to)
0
0
33