
LMSYS Org
@lmsysorg
Followers
7K
Following
768
Media
84
Statuses
482
Large Model Systems Organization: Join our Slack: https://t.co/mSPNyKTLTS We developed SGLang https://t.co/jEqIJcGwGA, Chatbot Arena (now @lmarena_ai), and Vicuna!
US
Joined August 2024
🚀 Breaking: SGLang provides the first open-source implementation to serve @deepseek_ai V3/R1 models with large-scale expert parallelism and prefill-decode disaggregation on 96 GPUs. It nearly matches the throughput reported by the official DeepSeek blog, achieving 52.3K input

10
83
393
🚀We are thrilled to announce that SGLang now supports OpenAI's latest open-weight model 'gpt-oss-120b', on both Hopper and Blackwell GPUs. Thanks to the collaborative efforts from @Eigen_AI_Labs , @nvidia , SGLang @lmsysorg and the OSS community!. SGLang support landed within 4


3
9
31


RT @NVIDIAAIDev: We are excited to share the results of our collaboration with SGLang. 🎉. Together, we optimized DeepSeek R1 inference for….
0
9
0
🔥 SGLang x AMD SF Meetup — Aug 22 🔥.We're teaming up with @AMD for a special AI Infra Meetup at SF. Here's what to expect:.1. An instructor-led GPU workshop to get hands-on with LLM infra on AMD GPUs.2. Talks by AMD, xAI, and the SGLang team on open-source roadmap, MoE
2
14
51

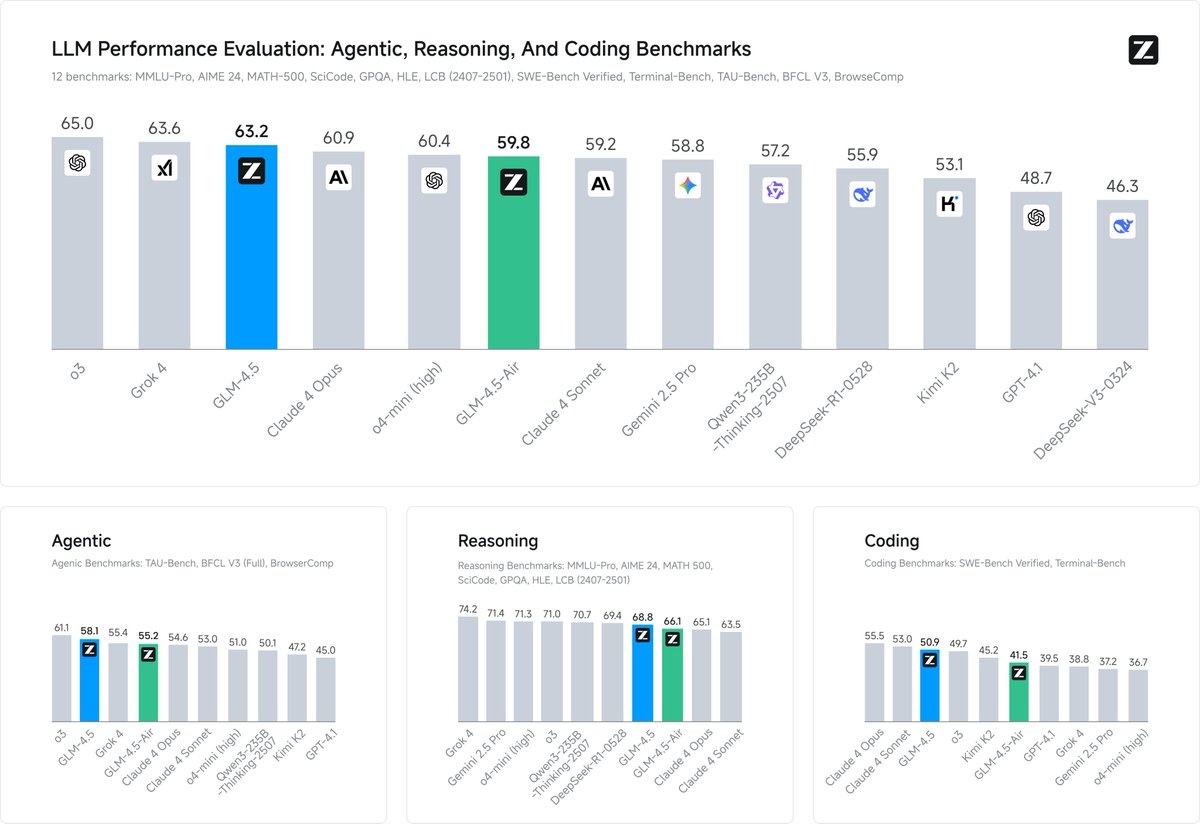
🚨GLM-4.5 is here — now fully supported on SGLang!. Unified reasoning, coding, and agentic capabilities with 128k context. Competitive with Claude 4, ahead of Kimi K2, and top-tier on MATH500, SWE-bench, and more. Deploy with a single command: .python3 -m sglang.launch_server.

Introducing GLM-4.5 and GLM-4.5 Air: new flagship models designed to unify frontier reasoning, coding, and agentic capabilities. GLM-4.5: 355B total / 32B active parameters.GLM-4.5-Air: 106B total / 12B active parameters. API Pricing (per 1M tokens):.GLM-4.5: $0.6 Input / $2.2
3
15
87
SGLang Day 0 now supports Step 3 — come give it a try! 🚀.

🚀 Announcing Step 3: Our latest open-source multimodal reasoning model is here! Get ready for a stronger, faster, & more cost-effective VLM!.🔵 321B parameters (38B active), optimized for top-tier performance & cost-effective decoding. 🔵 Revolutionary Multi-Matrix.
2
5
19
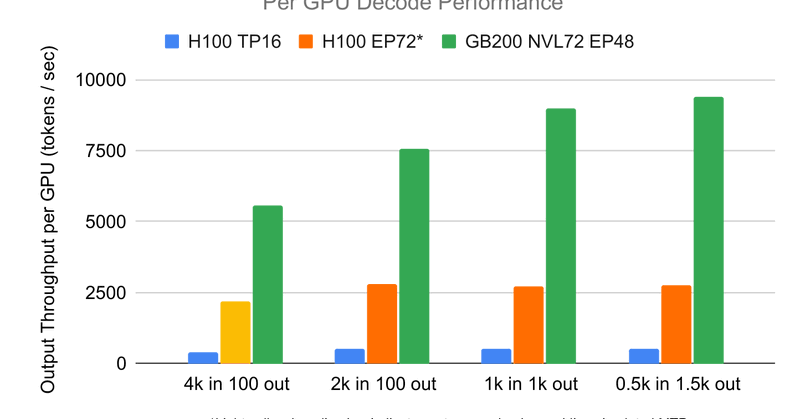
🔗Blog: ⏬ Container: Download it with one line:.docker pull lmsysorg/sglang:v0.4.9.post6-cu128-gb200.
lmsys.org
The GB200 NVL72 is the world's most advanced hardware for AI training and inference. In this blog post, we're excited to share early results from running ...
0
4
22
🚨Big News! We collaborated with @nvidia to release a DeepSeek R1 inference container optimized for large scale deployment on GB200 NVL72, the world’s most advanced data center–scale accelerated computing platform. This docker container runs a single copy of the model across 56

3
25
214
GLM-4.5 and GLM-4.5 Air are supported from day one by the team. Give them a try!

Introducing GLM-4.5 and GLM-4.5 Air: new flagship models designed to unify frontier reasoning, coding, and agentic capabilities. GLM-4.5: 355B total / 32B active parameters.GLM-4.5-Air: 106B total / 12B active parameters. API Pricing (per 1M tokens):.GLM-4.5: $0.6 Input / $2.2
3
11
104
RT @VoltagePark: Training draft LLMs? This changes everything. @lmsysorg just open-sourced SpecForge:. ⚙️ Built for MoE models.⚡ Instant i….

lmsys.org
Speculative decoding is a powerful technique for accelerating Large Language Model (LLM) inference. In this blog post, we are excited to announce the open...
0
3
0
RT @VoltagePark: Training draft LLMs? This changes everything. Congratulations to @lmsysorg on the open-sourcing of SpecForge. Their train….
0
4
0