

Alexis Conneau
@alex_conneau
Followers
26,271
Following
143
Media
31
Statuses
341
Audio AGI Research Lead @OpenAI
San Francisco
Joined September 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Chiefs
• 79040 Tweets
Amad
• 74955 Tweets
#虎に翼
• 59363 Tweets
Ubisoft
• 55940 Tweets
Yasuke
• 54157 Tweets
Antony
• 50623 Tweets
#PLdaGLOBONÃ0
• 35669 Tweets
Eagles
• 33342 Tweets
ジェシー
• 32749 Tweets
Romney
• 29583 Tweets
#ラヴィット
• 28835 Tweets
Cádiz
• 28224 Tweets
Chargers
• 24067 Tweets
Nitro
• 23982 Tweets
Steelers
• 23957 Tweets
Reece James
• 22853 Tweets
Amrabat
• 21938 Tweets
Celta
• 20759 Tweets
Ravens
• 20230 Tweets
Browns
• 19940 Tweets
Cowboys
• 19068 Tweets
Raiders
• 16194 Tweets
Texans
• 15138 Tweets
Bengals
• 14338 Tweets
$BRETT
• 13229 Tweets
Rams
• 11550 Tweets
#AEWDynamite
• 11471 Tweets




















Pinned Tweet

@OpenAI
#GPT4o
#Audio
Extremely excited to share the results of what I've been working on for 2 years
GPT models now natively understand audio: you can talk to the Transformer itself!
The feeling is hard to describe so I can't wait for people to speak to it
#HearTheAGI
🧵1/N

Introducing GPT-4o, our new model which can reason across text, audio, and video in real time.
It's extremely versatile, fun to play with, and is a step towards a much more natural form of human-computer interaction (and even human-computer-computer interaction):
888
5K
23K
35
53
458
Just released our new XLM/mBERT pytorch model in 100 languages. Significantly outperforms the TensorFlow mBERT OSS model while trained on the same Wikipedia data.
@GuillaumeLample
@Thom_Wolf
@PyTorch

2
196
676
DATASET RELEASE: "CC100", the CommonCrawl dataset of 2.5TB of clean unsupervised text from 100 languages (used to train XLM-R) is now publicly available.
You can find below the
Data:
Script:
By
@VishravC
et al.
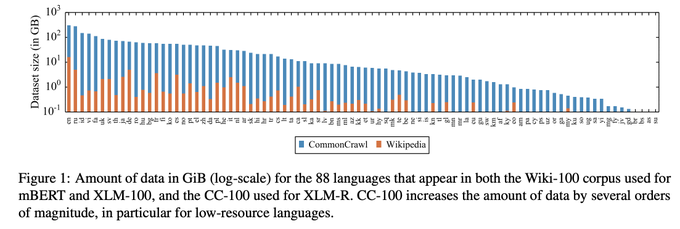
2
184
682
👨🔬Life update: Happy to share that I recently joined
@GoogleAI
Language as a research scientist 👨🏫
I will continue my research on building neural networks that can learn with little to no supervision
14
2
540
Happy to share our latest paper: "Self-training Improves Pretraining for Natural Language Understanding"
We show that self-training is complementary to strong unsupervised pretraining (RoBERTa) on a variety of tasks.
Paper:
Code:
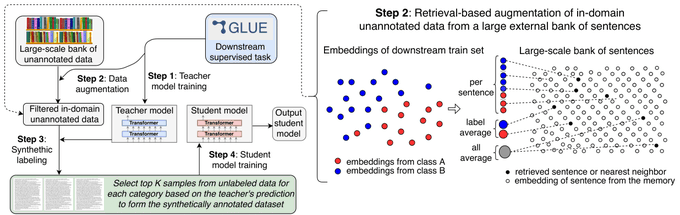
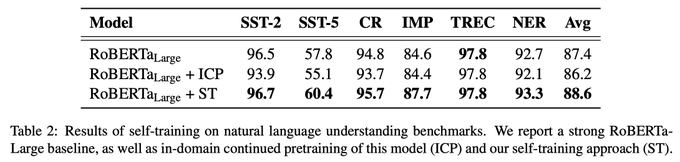
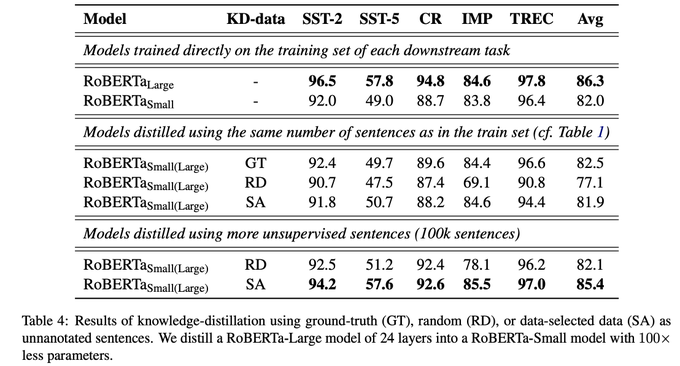
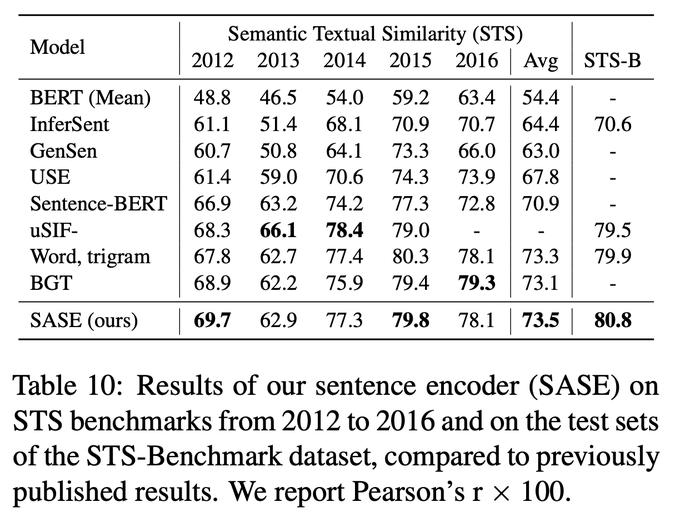
3
106
503
New work: "Unsupervised speech recognition"
TL;DR: it's possible for a neural network to transcribe speech into text with very strong performance, without being given any labeled data.
Paper:
Blog:
Code:

Today we are announcing our work on building speech recognition models without any labeled data! wav2vec-U rivals some of the best supervised systems from only two years ago.
Paper:
Blog:
Code:
15
314
1K
3
96
468
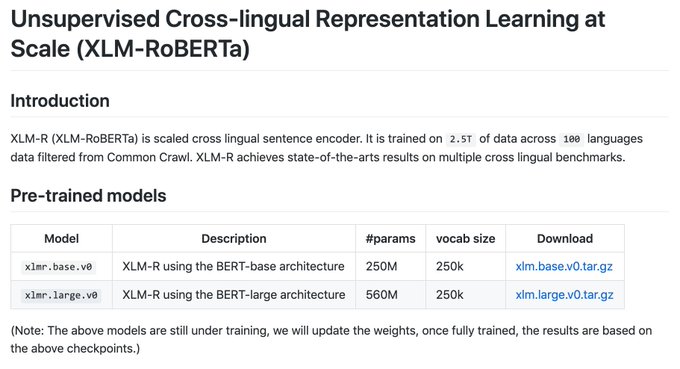
Our new paper: Unsupervised Cross-lingual Representation Learning at Scale
We release XLM-R, a Transformer MLM trained in 100 langs on 2.5 TB of text data.
Double digit gains on XLU benchmarks + strong per-language performance (~XLNet on GLUE). [1/6]

5
143
404
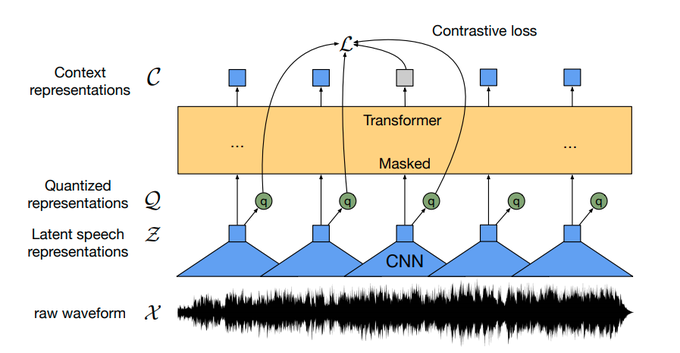
[XLSR-53: Multilingual Self-Supervised Speech Transformer]
We're happy to release XLSR-53: a wav2vec 2.0 model pre-trained on 56k hours of speech in 53 languages from MLS, CommonVoice and BABEL datasets!
Model:
Updated paper:
1/N

9
75
338
Career update: A month ago, I re-joined FAIR at
@MetaAI
as a research scientist.
I am continuing my work on self-supervised learning for Language.
12
6
322
This video clip should appear at the beginning of any AI movie in the classic flashbacks

A demo from 1993 of 32-year-old Yann LeCun showing off the world's first convolutional network for text recognition.
#tbt
#ML
#neuralnetworks
#CNNs
#MachineLearning
64
2K
8K
0
40
258
Our paper "Self-training improves pretraining for natural language understanding" has been accepted to NAACL 2021!
Paper:
Code:
3
42
253

Unsupervised Cross-lingual Representation Learning for Speech Recognition:
Our self-supervised learning approach learns cross-lingual speech representations by pretraining a single model from the raw waveform in multiple languages.
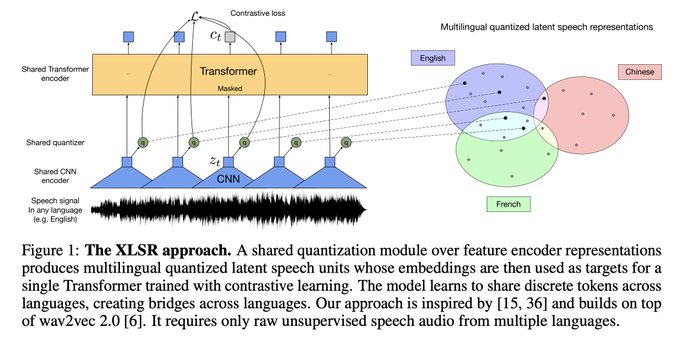
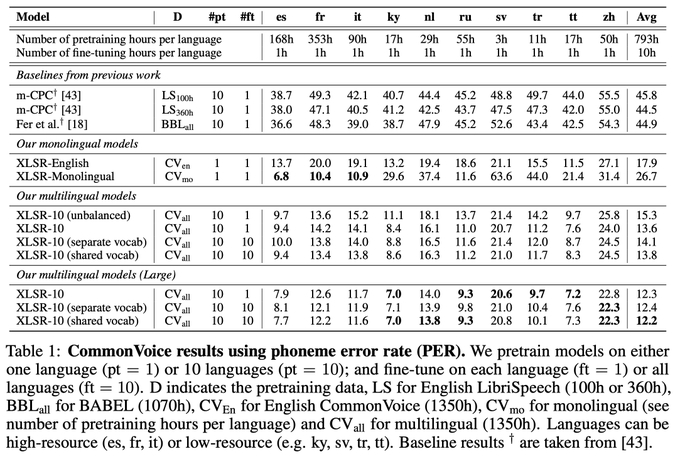
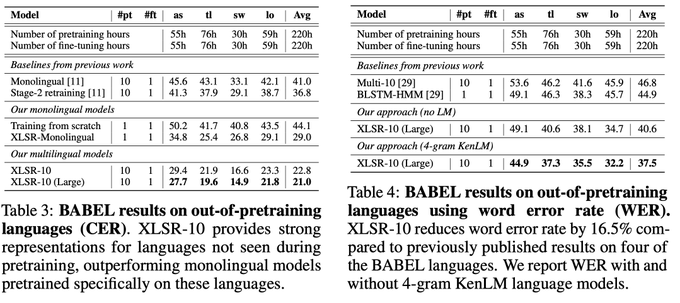
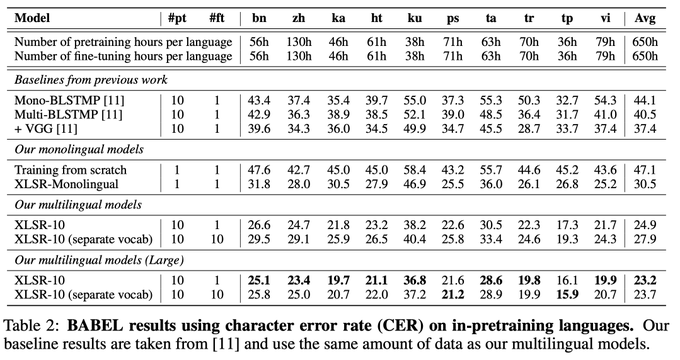
1
46
195
Would be cool to be able to say "
#ChatGPT
sucks" ... "it can't answer my <insert_weirdest_question>", and sound clever 🤓
But let's be honest, it has almost no flaws. It can answer most questions so well. Even tricking it is hard
Plus, the path for improvement is very clear
11
7
188
⚙️Release: CCNet is our new tool for extracting high-quality and large-scale monolingual corpora from CommonCraw in more than a hundred languages.
Paper:
Tool:
By G. Wenzek, M-A Lachaux,
@EXGRV
,
@armandjoulin
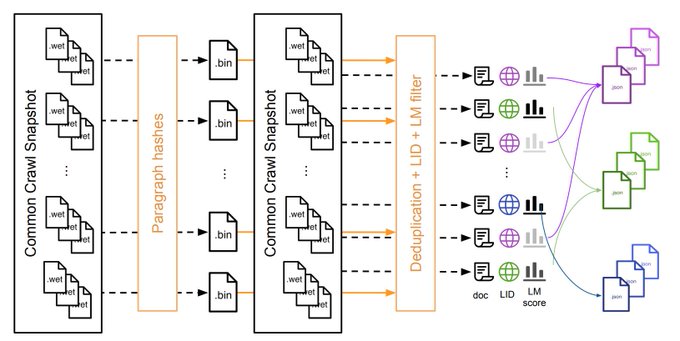
0
57
162
📢 New study: 'Larger-Scale Transformers for Multilingual Masked Language Modeling' 🚨
We study and release two larger-scale XLM-R models:
- XLM-R XL (3.5B params)
- XLM-R XXL (10.7B params)
Models and code will be publicly available soon
1/5

1
38
160
1/4 XLM: Cross-lingual language model pretraining. We extend BERT to the cross-lingual setting. New state of the art on XNLI, unsupervised machine translation and supervised machine translation.
Joint work with
@GuillaumeLample
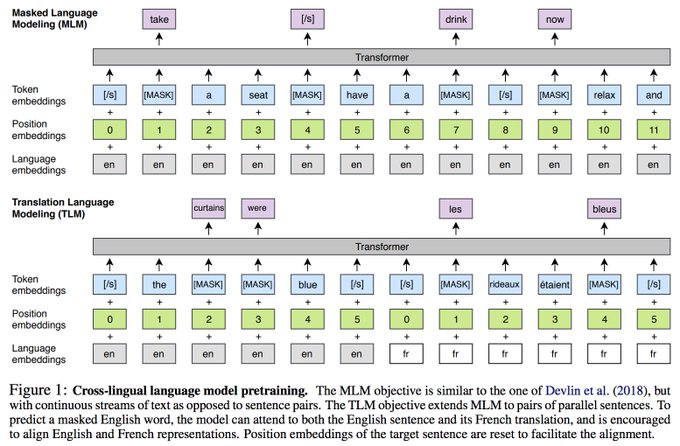
6
64
151
[🚨XLS-R🚨] We're releasing XLS-R (XLM-R for Speech) a multilingual SSL model in 128 languages, with great results:
Speech Translation: +7.4 BLEU on XX->En CoVoST-2
Speech Recognition: 14-34% WER reduction on BABEL, MLS, VoxPopuli and CommonVoice
Paper:
2
16
153
Two papers accepted this year at
#ACL2020
:)
The first one on Unsupervised Cross-lingual Representation Learning at Scale (XLM-R) is a new SOTA on XLU benchmarks; and shows that multilinguality doesn't imply losing monolingual performance. (1/3)
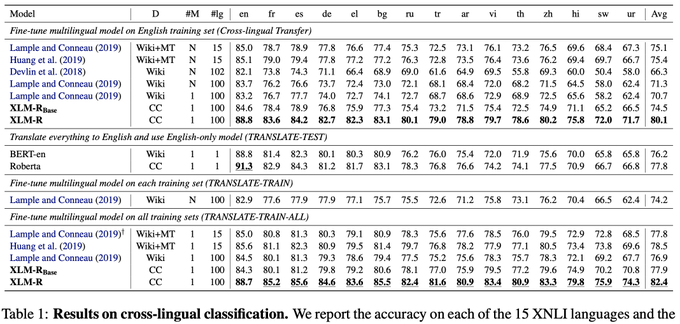
1
27
148
Happy to share our work "Large-Scale Self- and Semi-Supervised Learning for Speech Translation"
New state of the art (+2.6 BLEU on average) on CoVoST-V2 with a simple approach, lot of unannotated data and less supervision
Paper:
Models coming soon
1
33
141
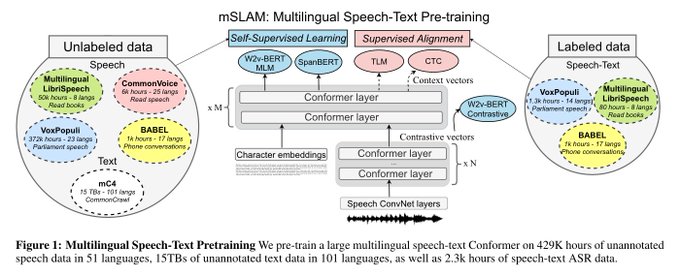
📢 mSLAM: Massively multilingual joint pre-training for speech and text 📢
Imagine if we could unify speech and text understanding within a single model + handle all languages?
This is the direction we're taking with mSLAM (~=XLM-R+XLS-R?)
New SOTAs on AST(+2.7BLEU) and ASR...
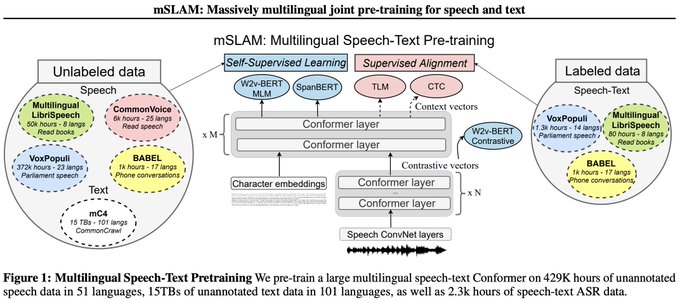

New paper: "mSLAM: Massively Multilingual Joint Pre-training for Speech and Text"
mSLAM is our new 2B-param speech-text model in 100+ languages, pre-trained on 430k hours of speech and 10+TiB of text.
SOTA on AST(+2.7 BLEU)/ASR, strong on XLU
🧵
2
46
244
6
24
130
I'm really happy about having our XLS-R models on HF
These are the best models we have. Now, with a few lines of code, you can fine-tune it on speech tasks with good performance, in 128+ languages
I find it very cool that we can make such models public
4
26
126
Out of the 4 most downloaded models on
@huggingface
, one is XLM-R and one is XLS-R
made it possible. HuggingFace is an incredible partner to both researchers & practitioners
No wonder
@ClementDelangue
can organize AI parties with 5,000 people in a week
0
15
117
🎉 We had 3 papers accepted at
#Interspeech2022
+ 1 new paper 🎉
1) XLS-R: SSL for Speech
2) XTREME-S: Benchmark for Speech SSL
3) FLEURS: 100-way parallel speech data based on FLoRes MT data + Speech "bitext" mining
4) SSL for Speech2speech translation
<Thread>
2
12
121
Our FLEURS paper won the best paper award at SLT 2022!
@ieee_slt
SLT:
arXiv:
Thanks to the organizers! Grateful for the collaboration with many great colleagues 🙂
6
19
116
Speech and text technologies have converged in:
1) Architecture: Transformer-based models
2) Pre-training: De-masking for both modalities
3) Fine-tuning: Seq2seq with attention
And .. self-supervised speech representations are naturally close to text (modulo a Linear mapping)
1
7
106
Glad to announce that our paper on Cross-lingual Language Model Pretraining has been accepted as a spotlight presentation at
@NeurIPSConf
.
Code:
Paper:
3
14
101

It's not surprising
@OpenAI
focused on mining supervised data, it's the right thing to do and it's been so under-explored in Speech
Think about how MT is done: pretty much only bitext mining. Check out LASER for speech (Meta) or FLEURS (Google); more work needs to be done there
3
4
96
Check out the open-source code for SOTA Unsupervised Machine Translation at . Gives 28 BLEU on WMT English-French without a single parallel sentence!


2/2 papers accepted at
@emnlp2018
! One is our paper on Unsupervised MT: for which we also open-sourced the code:
Other one will come soon :)
@alex_conneau
@LudovicDenoyer
1
39
175
0
18
81
We are releasing the checkpoints of XLSR-53 fine-tuned on each language of the MLS dataset
Thanks to
@PatrickPlaten
and
@huggingface
we can now easily understand and look at the common mistakes made by these models. So far, at least the French model seems to work decently :)
1
8
74
GPT-4 coding capabilities are incredibly helpful
I can't see a situation where using it doesn't lead to a big boost in productivity if you work in Engineering
4
2
67
Two papers accepted at Interspeech 2021 :)
- Unsupervised Cross-lingual Representation Learning for Speech Recognition (the XLSR paper)
- Large-Scale Self- and Semi-Supervised Learning for Speech Translation

0
8
72
🚨[🗣️🔊💻💬]🚨 Excited to share our new benchmark "XTREME-S" to accelerate speech technologies for all
XTREME-S evaluates recognition, translation, classification and retrieval in 100+ languages.
Paper:
Code:

2
17
64
Great event incoming to build ASR systems in many languages using
@huggingface
. Will involve the new XLS-R models, as well as many tricks (fine-tuning, self-training, LM-decoding).
Jan 24th to Feb 7th

🎙️Speech community event incoming! 📨
The Robust Speech Challenge will be held from January 24th to February 7th in collaboration with
@OVHcloud
🔥
Come and join us to build robust speech recognition systems in 70+ languages🤗🌍
To participate:
6
58
192
0
6
65
Very cool work by
@PatrickPlaten
@Thom_Wolf
and the
@huggingface
team integrating wav2vec 2.0 into HuggingFace.
The amazing Transformers library is now also a speech recognition library!
🚨Transformers is expanding to Speech!🚨
🤗Transformers v4.3.0 is out and we are excited to welcome
@facebookai
's Wav2Vec2 as the first Automatic Speech Recognition model to our library!
👉Now, you can transcribe your audio files directly on the hub:
17
317
1K
0
10
63
The "Jigsaw Multilingual Toxic Comment Classification"
@kaggle
competition from Jigsaw/
@GoogleAI
is now over.
Happy to see winning solutions using XLM-R as their main model
Thanks to
@huggingface
for making the model very easy to use for participants
0
14
63
We just released the XLM-R XL (3.5 Billion parameters) and the XLM-R XXL (10.7B Billion parameters) models.
Link:
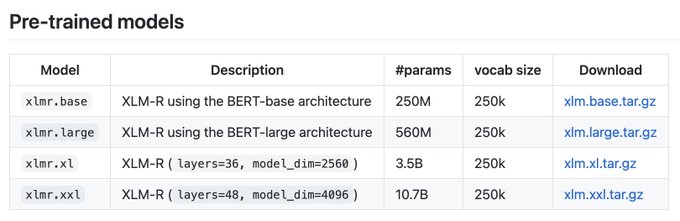
📢 New study: 'Larger-Scale Transformers for Multilingual Masked Language Modeling' 🚨
We study and release two larger-scale XLM-R models:
- XLM-R XL (3.5B params)
- XLM-R XXL (10.7B params)
Models and code will be publicly available soon
1/5
1
38
160
1
8
61
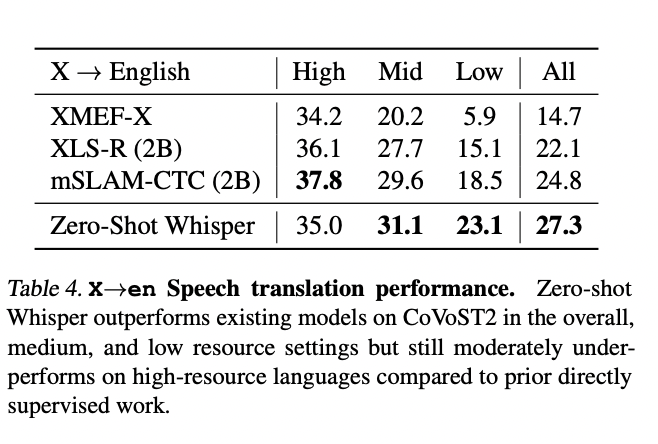
Evolution of average XX->En CoVoST-2 speech translation performance (BLEU) in one year:
Li et al. (2021): 14.7 BLEU
XLS-R (2021): 22.1 BLEU
mSLAM (2022): 24.8 BLEU
+10.1 BLEU in one year, driven by improvements in few-shot understanding from self-supervised learning
2
5
54
I cannot believe this is real
Big congrats to the magicians who made Sora:
@_tim_brooks
&
@billpeeb
,
@model_mechanic
and team

Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
Prompt: “Beautiful, snowy
10K
33K
141K
3
2
45
[Whisper] On speech translation, Whisper outperforms the CoVoST-2 SOTA (which was XLS-R then mSLAM) by 2.5 average BLEU, but 4.6 BLEU on low-resource - on which mSLAM was particularly good.
It's a big improvement for speech translation.
2
2
46
Research on retrieval-augmented LLMs is nicely complementary to research on dense models like GPT-3 or PaLM.

Very excited to introduce Atlas, a new retrieval augmented language model which is competitive with larger models on few-shot tasks such as question answering or fact checking.
Work lead by
@gizacard
and
@PSH_Lewis
.
Paper:
2
11
74
2
3
43
Join the live stream of
@OpenAI
DevDay on Monday 10am!
Some great new stuff to be announced there
We’re live streaming the OpenAI DevDay keynote on Monday at 10AM PST.
Tune in!
239
826
4K
3
3
42
Play with our XLM-R and XLM-R_Base with
@Pytorch
hub: . Available on FairSeq, Pytext and XLM. Soon on
@HuggingFace
Transformer repo and
@TensorFlow
hub. [5/6]
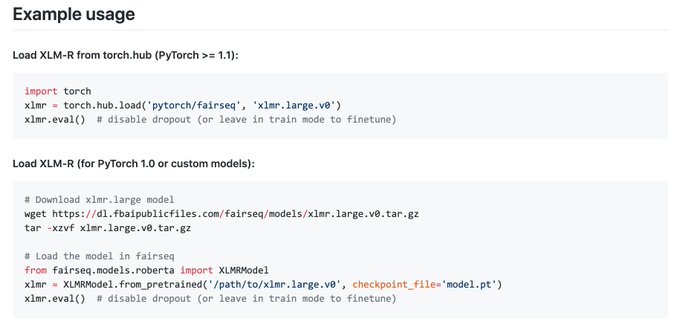
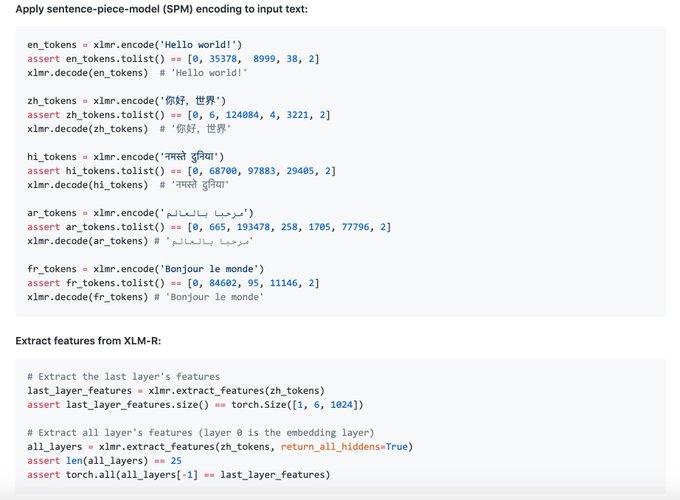
4
12
42
I spent a great year at
@GoogleAI
, working on multimodal self-supervised learning, for speech and text.
Thanks to all my amazing colleagues there for the ride.
1
0
39
We're working hard to provide the community with high-quality
#CommonCrawl
corpora to enable representation learning for low-resource languages. The reign of Wikipedia corpora is over =). The CC100 corpus of XLM-R will be released soon at
#LREC2020
. (3/3)
1
3
39
I have rarely been as excited as I am today about deep learning research in general.
Very glad to be working in this field, at this point in time.
1
0
39
We have some exciting piece of research to share tomorrow, on a new method to do speech recognition without any supervision.
One of the most exciting research projects I have had the chance to work on. With my Facebook colleagues Alexei Baevski, Michael Auli and Wei-Ning Hsu.
3
0
24
2
1
37
Most folks who pretend to be skeptical about this kind of technology had no idea that this was going to happen so fast or even during our lifetime, and we all know it
This is almost unbelievable. And it's only 2022.
1
0
37
Self-supervised pretraining for speech enables automatic speech recognition with only *10 minutes* 🕐 of transcribed speech data. Works very well cross-lingually too.
Wav2vec 2.0:
XLSR:
By
@ZloiAlexei
and colleagues from Facebook

Facebook AI is releasing code and models for wav2vec 2.0, a self-supervised algorithm that enables automatic speech recognition models with just 10 minutes of transcribed speech data.
5
189
683
0
4
34
Congrats, Google DeepMind folks!

The Gemini era is here. Thrilled to launch Gemini 1.0, our most capable & general AI model. Built to be natively multimodal, it can understand many types of info. Efficient & flexible, it comes in 3 sizes each best-in-class & optimized for different uses

377
2K
12K
3
0
30
We have a new paper: "Scaling laws for generative mixed-modal LMs"
Check it out!
Although I have contributed only a little I am proud to be on that work with this set of amazing colleagues

I'm excited to present: Scaling Laws for Generative Mixed-Modal Language Models. In this paper we explore the scaling properties of mixed-modal generative models, discovering new scaling laws that unify the contributions of individual modalities and the interactions between them.
10
76
313
1
2
32
In the second we show that monolingual BERT representations are similar across languages, same as word2vec spaces. This explains in part the natural emergence of multilinguality in bottleneck architectures like mBERT/XLM. (2/3)
1
3
30
These "phase transitions" in LLMs are quite incredible

Presenting our survey on emergent abilities in LLMs!
What's it about? Certain downstream language tasks exhibit an interesting behavior: eval curves are flat/random up to a certain model scale, until -- poof -- things start to work.
1/7
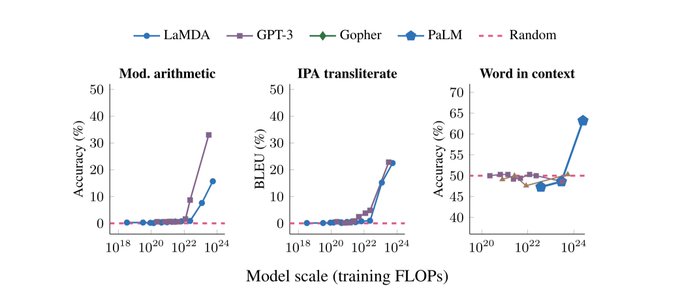
21
113
585
1
1
28
Wow!
@huggingface

Data is all we need! 👑 Not only since Llama 3 have we known that data is all we need. Excited to share 🍷 FineWeb, a 15T token open-source dataset! Fineweb is a deduplicated English web dataset derived from CommonCrawl created at
@huggingface
! 🌐
TL;DR:
🌐 15T tokens of cleaned
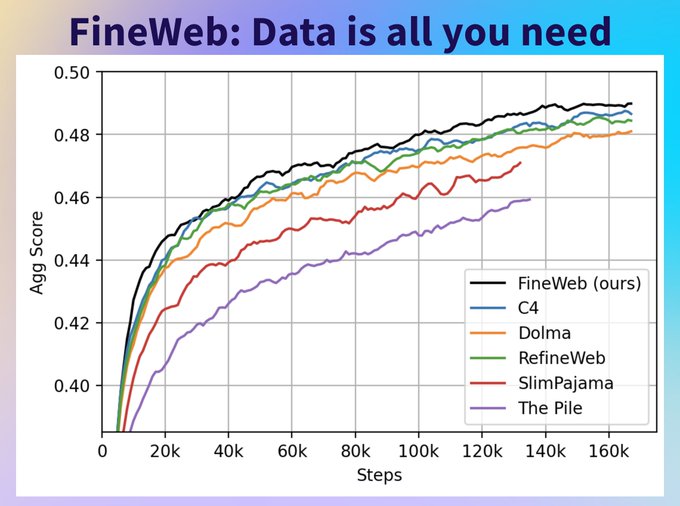
14
87
395
0
5
30
Does this make AI research incredibly boring or all the more exciting?
4
0
27
How many more AI challenges are already solved with current technology without us realizing it yet?
Just a matter of collecting the relevant data; figuring out Legal issues; getting 10x more compute; adding a slight modification to the loss function of a large Transformer?
1
0
25

Congrats to the
@AIatMeta
team working hard for that cool release!
Congrats too to the former FAIRies who initiated the Llama train, wherever they are now!
Introducing Meta Llama 3: the most capable openly available LLM to date.
Today we’re releasing 8B & 70B models that deliver on new capabilities such as improved reasoning and set a new state-of-the-art for models of their sizes.
Today's release includes the first two Llama 3
253
1K
6K
1
0
25
@colinraffel
Thanks!
In the github we release four 100M/1B-sentences FAISS indexes () that fit on a single GPU (16/32GB mem) for simplicity. Embeddings are quite compressed but these still work quite well for similarity search. I'll add the github link to arxiv! :)
1
4
20
Really impressive and fun. Conversations are sometimes quite impressive. Also the Demo is well designed and easy to use.
Check it out here:
Help improve conversational AI safety for everyone by trying out the new BlenderBot3 demo and providing feedback:
(It’s only available in the U.S. for now but we hope to expand access in the future.)
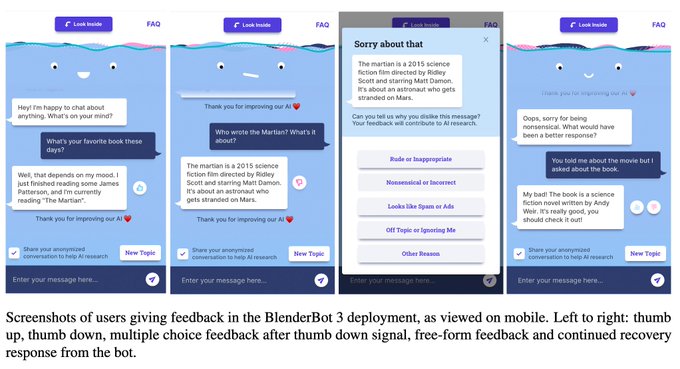
13
43
184
0
0
18
"It’s easy to think of the ability to talk to your phone as just a matter of convenience — a way of getting information while you’re driving or cooking. But for many new internet users, voice isn’t just helpful — it’s critical."

0
4
18
@pmddomingos
@sama
@ilyasut
AlexNet / Seq2seq / GPTs (i.e. LLMs) / Rebirth of self-supervised learning (GPT-1/Sentiment-neuron). Among other things
0
0
16
FLEURS: Few-shot Learning Evaluation of Universal Representations of Speech
(not at Interspeech, just a new paper)
Paper here:
Dataset here:
1
2
17
🧐 I'm looking for a text dataset called "ATC 120k", often used to train a language model in Amharic for speech recognition. Please let me know if you know where to find it! 🙏
5
5
16
Really great trying it for generation
But a lot of downstream results reported for BLOOM & OPT () are basically close to random (e.g. SST, MNLI)
Does it make sense to report those scores? "Few-shot" doesn't mean you *don't* have to provide good results.

BLOOM is here. The largest open-access multilingual language model ever. Read more about it or get it at

29
815
3K
2
1
16
We show that multilingual models can outperform monolingual BERTs by leveraging training sets in multiple languages at fine-tuning time.
Our work generally demonstrates the possibility of having one model for all languages while not giving up on per-language performance. [3/6]
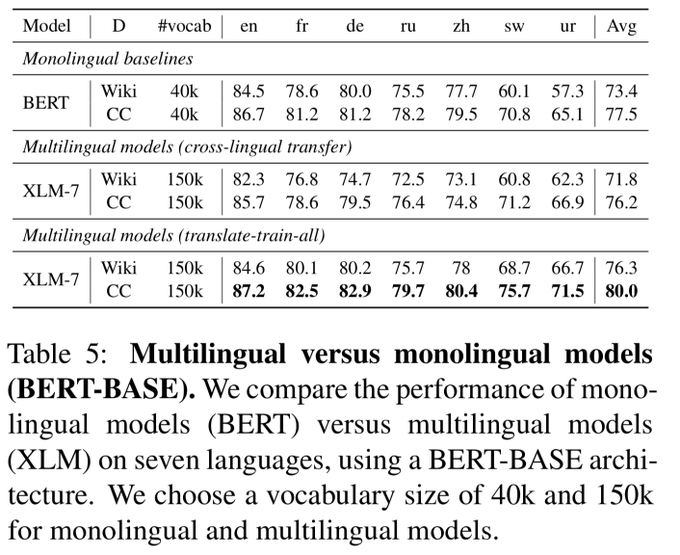
2
1
16

A great note that describes in more details how XLM is used at FB to recognize hate-speech effectively, in many languages
We’re sharing new details on our AI tools to help us detect and deal with hate speech on our platforms.
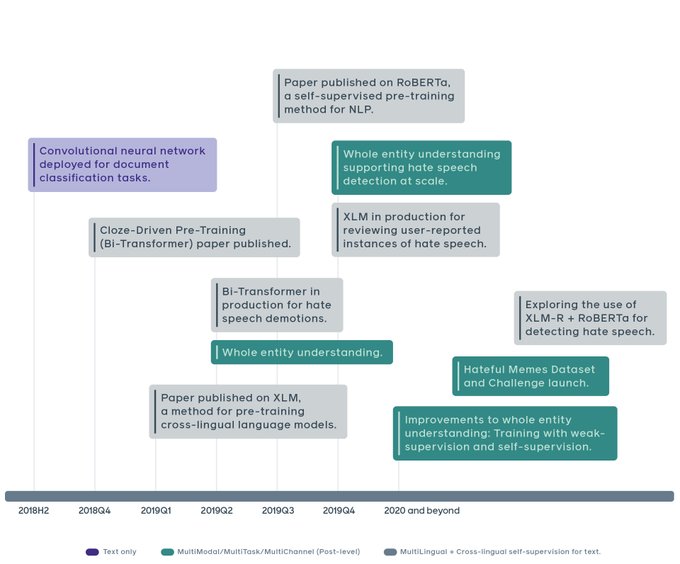
28
56
192
0
1
15
What a legend

0
0
13
@ParcolletT
Knowledge distillation (+ quantization) of large fine-tuned models to smaller models works quite well though. Big companies use that as they also need very small models for prod. What do you think about this approach?
1
0
13
XTREME-S: Evaluating Cross-lingual Speech Representations
Paper here:
Code/data can be found here:
1
3
13
Nice article from
@FortuneMagazine
that mentions our work on hate speech:
"[Facebook] says the new techniques [XLM(-R)] were a big reason it was able [..] to increase by 70% the amount of harmful content it automatically blocked from being posted."

1
1
12
Amazing work that takes one more significant step towards the unification of neural nets for all modalities
Now open-sourced and available on
@huggingface
0
1
12
XLSR-53 languages include:
Arabic Assamese Basque Bengali Breton Cantonese Cebuano Chinese Chuvash Dhivehi Dutch English Esperanto Estonian French Georgian German Haitian Hakh-Chin Indonesian Interlingua Irish Italian Japanese Kabyle Kazakh Kinyarwanda Kurmanji ...
5/N
1
0
12
We present a comprehensive analysis of the capacity and limits of unsupervised multilingual masked language modeling at scale.
In particular, we study the high-res/low-res and transfer/interference trade-offs, and expose what we like to call "the curse of multilinguality". [2/6]
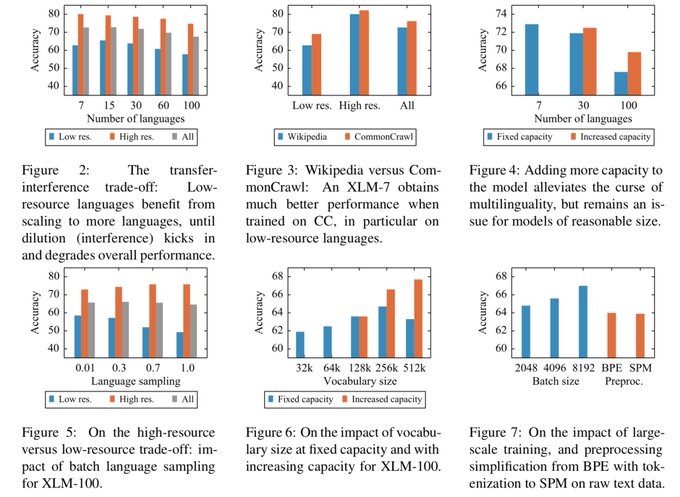
1
5
11
SSL for ASR with wav2vec 2.0 has shown incredible results with only 10 minutes ⏰ of English annotated data.
Our goal with XLSR-53 is to enable few-shot learning for languages that are actually low-resource, leveraging unsupervised data from higher-resource languages.
2/N
2
0
11
The CoVoST-2 benchmark is far from being solved. XMEF-X was the state of the art in Oct 2020. That's a +12.6 average BLEU improvement in 2 years.
Speech translation is such a great machine learning topic; as it mixes multi-task, multi-modal and self-supervised learning.
0
0
11
XLM-R especially outperforms mBERT and XLM-100 on low-resource languages, for which CommonCrawl data (see
#CCNet
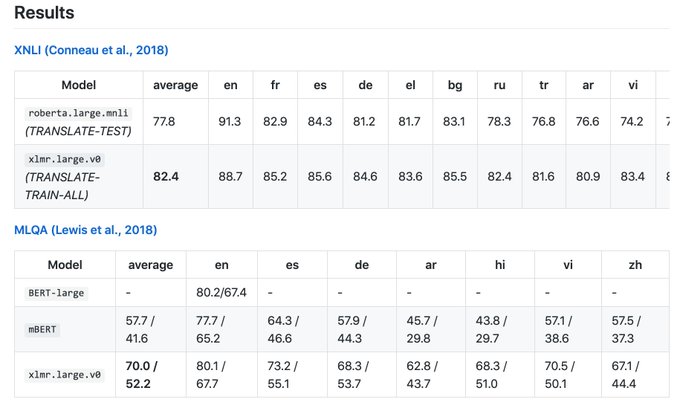
) enables representation learning: +13.7% and +9.3% for Urdu, +21.6% and +13.8% accuracy for Swahili on XNLI. [4/6]

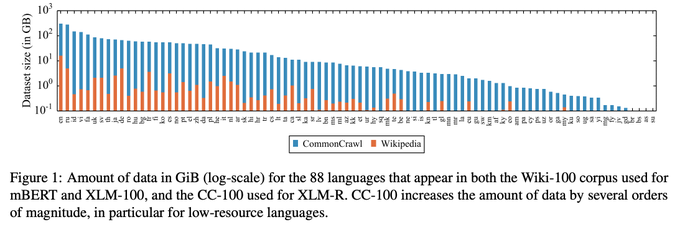
1
2
11
"Model downloads of XLS-R (300m,1B,2B) spiked at 3,000 downloads per day during event"
Thank you
@huggingface
@PatrickPlaten
🤗
Speech technology for everyone in all languages will become a reality, not just for research, but also for concrete products.
0
2
11
With recent strides in self-supervised learning for speech representation learning, you can expect to see more releases of strong pretrained unsupervised Transformer models for speech, similar to what is happening in NLP. So stay tuned!
7/N
1
1
11
... as well as: Kyrgyz Lao Latvian Mandarin Mongolian Pashto Persian Polish Portuguese Russian Sakha Slovenian Spanish Swahili Swedish Tagalog Tamil Tatar Tok Turkish Vietnamese Welsh and Zulu.
6/N
1
2
10
@ashkamath20
@seb_ruder
@NYUDataScience
I'm not sure about monolingual transfer performing as well as joint learning though. Results from perform around 70% on XNLI which is more than 5% average accuracy below the state of the art.
2
1
9
Leveraging unsupervised and weakly-supervised data to improve direct speech-to-speech translation
Paper here:
0
1
10
1
1
9
Our XLS-R models (100m, 300m, 1b, 2b parameters) are available in:
HuggingFace:
Fairseq:

2
1
8
In our updated paper we show that fine-tuned XLSR-53 models perform very well in a few-shot setting for many languages, high & low-resource.
In particular, our model outperforms previous work on several MLS and BABEL languages, for which we added more results and baselines.
3/N
1
0
8
XLS-R: Self-supervised Cross-lingual Speech Representation Learning at Scale
Paper here:
Models can be found here:
1
1
8
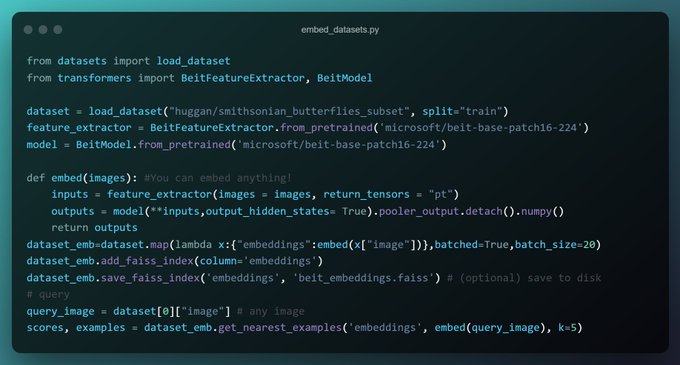
This is really awesome
Fast similarity search made simple with FAISS integration in
@huggingface
, for any embedding dataset

Underrated
@huggingface
datasets feature🧡
Adding an embedding faiss index to your dataset is this easy ⤵️
8
45
308
0
1
8
"Masked Autoencoders Are Scalable Vision Learners"
By Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, Ross Girshick
1
1
8
We leverage 436k hours of unannotated data
We show that we can obtain very good results on speech translation with a small amount of supervised data (only 1h-2h).
By scaling the capacity of our model, we show strong improvements on ASR, AST, and also classification (LangID).

1
1
8
This is the result of work done by many amazing folks across
@GoogleAI
,
@huggingface
, and
@MetaAI
.
Please consider using XTREME-S so that as a community, we can accelerate progress on speech technology for the benefit of all.
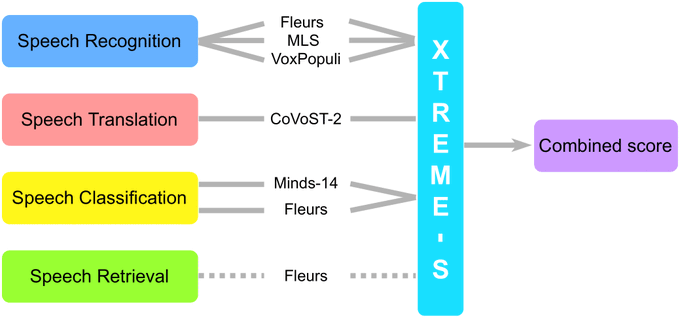
📊4 challenging speech tasks, 102 spoken languages: can one model solve them all? 🤯
Introducing
@GoogleAI
's XTREME-S🏂 - the first multilingual speech benchmark that is both diverse, fully accessible, and reproducible!
👉
1/9
2
80
260
0
3
7