

Winnie Xu
@winniethexu
Followers
2,187
Following
461
Media
21
Statuses
319
Cookin' up LLM alignment at scale. Raised by @MetaAI @StanfordAILab @GoogleDeepmind . BS in CS/Math @UofT .
bay area 🇺🇸 (/ 🇨🇦)
Joined May 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Canucks
• 69634 Tweets
#GodMorningTuesday
• 63100 Tweets
राजीव गांधी
• 53099 Tweets
#呪術廻戦
• 50500 Tweets
定額減税
• 37210 Tweets
Oilers
• 36310 Tweets
オールスター
• 36008 Tweets
給与明細
• 32404 Tweets
招待コード
• 29337 Tweets
梅雨入り
• 27742 Tweets
梅津さん
• 25076 Tweets
梅津秀行さん
• 21868 Tweets
手紙110円
• 19530 Tweets
ZAGATKANDIAZ GalauerPRINCE
• 18472 Tweets
BikinBAPER LevelMAKSIMAL
• 17857 Tweets
間質性肺炎
• 17299 Tweets
ザレイズ
• 13954 Tweets
आधुनिक भारत
• 13241 Tweets
Samsung A55
• 11063 Tweets
I HAVE MY EVIDENCE
• 10653 Tweets



















Pinned Tweet

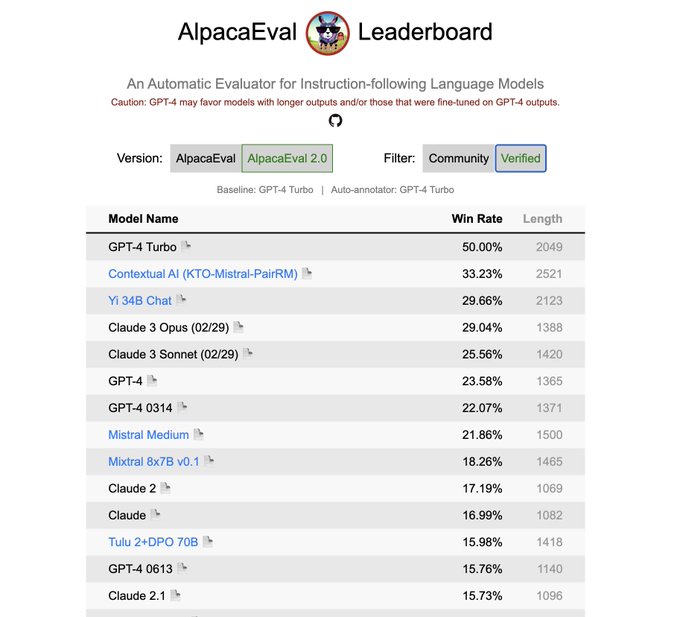
Excited to share a new model with
@ContextualAI
that tops the AlpacaEval 2.0 leaderboard!
How did we manage to rank higher than models like GPT4, Claude 3 and Mistral Medium? Enter iterative alignment… 🧵
11
35
203
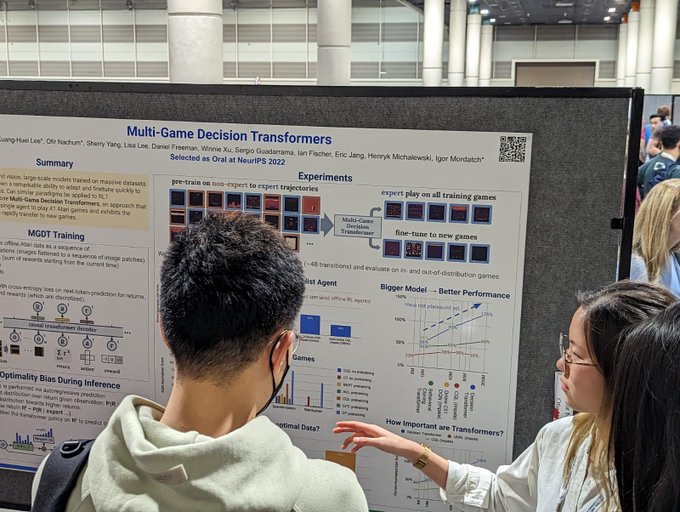
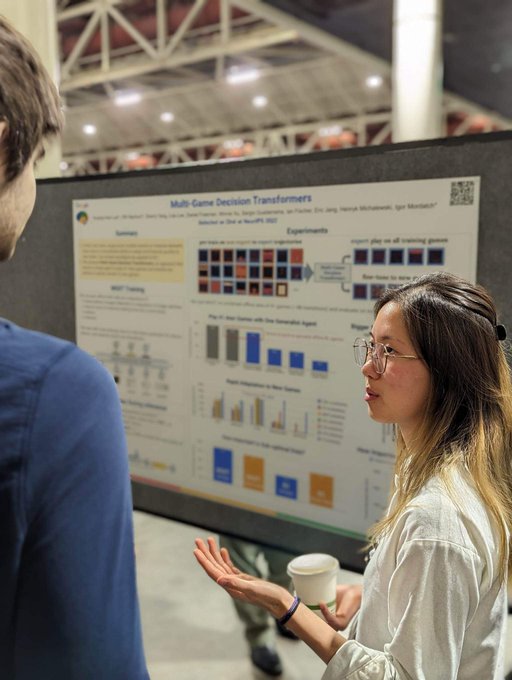
If you're interested in training generalist agents check out my blog post for our work on Multi Game Decision Transformers!

Introducing the Multi-Game Decision Transformer: Learn how it trains an agent that can play 41 Atari games, can be quickly adapted to new games via fine-tuning, and significantly improves upon the few alternatives for training multi-game agents →
8
154
531
3
24
221
At Contextual AI, one of the biggest pain points for our customers doing LLM alignment is getting the preference data that current methods need.
Think about all the pain you’ve been through trying to collect + label training data — now imagine doing that at 100x the scale. 🧵 1/

5
22
136
Most of my time in undergrad was spent running research experiments instead of doing homework. I'd say it was pretty worth it 🤠
Grateful to have these goons still in my life!


Before Cohere For AI
@forai_ml
there was . In 2017, a group of students and a dropout responded to a slack message to do research together. ✨
Sometimes, embarking on a research idea can change your entire path in life.
3
7
94
1
4
76
The real NeurIPS party everyone should be talking about is the after after party at MSY

2
2
65
Excited to share this work on Multi-Game Decision Transformers (MGT)! For large-scale applications, traditional RL methods have struggled with effectively leveraging optimal policies learned from data of multiple modalities. MGT is one step towards achieving a generalist agent:

How can we effectively train generalist multi-environment agents? We trained a single Decision Transformer model to play many Atari games simultaneously and compared it to alternative approaches:
4
60
316
2
8
61
I think I spend more time staring at fake faces and getting them to look more real than I do staring at real faces.
3
2
62
"let's think step by step before we start a fire"

These are the people building the future of artificial intelligence and its impacts on humanity
7
7
122
1
3
58
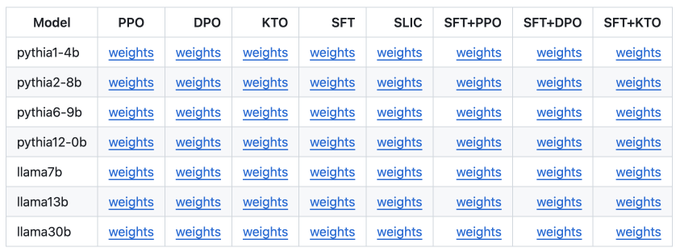
Not convinced? We’re releasing Archangel: the largest-ever suite of feedback-aligned LLMs: 56 models in total from 1B to 30B aligned with 8 different methods (including KTO!) on a combination of SHP, Open Assistant, and Anthropic HH.
Try
@huggingface
: 4/
1
6
43
Pleased to announce we've trained a 100000B parameter LLM!
JUST KIDDING (:
Check out the new version of our Goldiprox paper (active selection of high information datapoints with proxy models)! Maybe we can think more deeply about the problem of data efficiency at large scale...

Tired of waiting 💤 while your model trains? Try skipping points that are already learned, not learnable or not worth learning! Robustly reduces required training steps 🏎 by >10x ! to reach the same accuracy on big web-scraped data
📜ICML 2022 paper:

19
130
1K
0
4
40
Excited to share some co:ol news! Today
@CohereAI
is entering the scene with the most up-to-date, scalable, and responsible language models that help businesses + computers understand and leverage the rich information of our world
.... ....

2
3
39
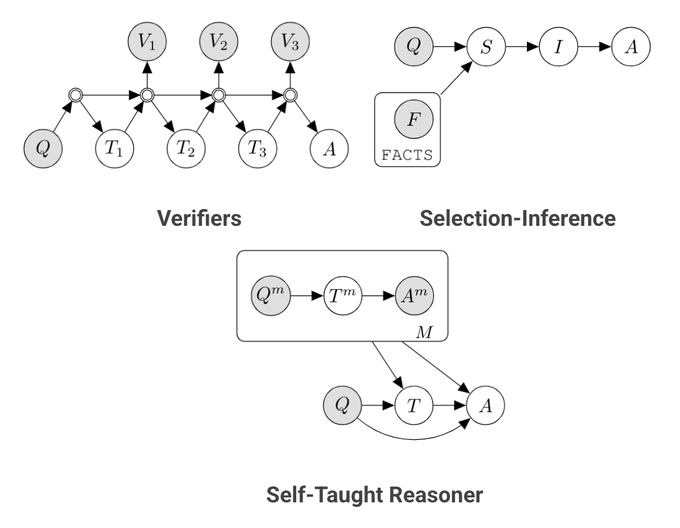
Check out this fun project we did towards augmenting the reasoning capabilities of LLMs through a probabilistic lens. More to come!

Happy to release our work on Language Model Cascades. Read on to learn how we can unify existing methods for interacting models (scratchpad/chain of thought, verifiers, tool-use, …) in the language of probabilistic programming.
paper:
3
99
669
0
0
39
Super excited to be mentoring up 'n coming young researchers, and collaborating with those from before! This was how I got to learn about research back when I had zero ML experience and couldn't get into any labs at my university... Let's continue the legacy 💪

The original couldn't have succeeded without the hard work of many many others including
@winniethexu
@divyam3897
@sid_srk
@acyr_l
@amrmkayid
@nitarshan
@ImanisMind
and many more.
4
6
31
0
1
39
How can we make information retrieval optimal in settings where factuality is equally important as good generation?
Excited to share the latest from
@ContextualAI
! RAG2.0 jointly optimizes the key components of typical RAG systems reaching SOTA on many key benchmarks. Read more:

Our first set of RAG 2.0 models, Contextual Language Models (CLMs), significantly improve performance over current systems across axes critical for enterprise work: open-domain question answering, faithfulness, and freshness.

1
2
26
0
3
32
Best people 🤙


0
2
31
We'll be presenting multi-game decision transformers this morning 11am Hall J
#107
. Come talk to us about generalist agents and sequence modeling!
If you're interested in training generalist agents check out my blog post for our work on Multi Game Decision Transformers!
3
24
221
2
1
29
We'll be giving the spiel on NFTs () today, Wednesday Dec 13 in Hall B1
#434
. Come by and say hi!


I'll be presenting this work at NeurIPS next week, as well as NFTs (not that kind--). DM me if you're around and want to chat.
0
8
57
1
2
21
Here's something your diffusion model can't do... (yet)
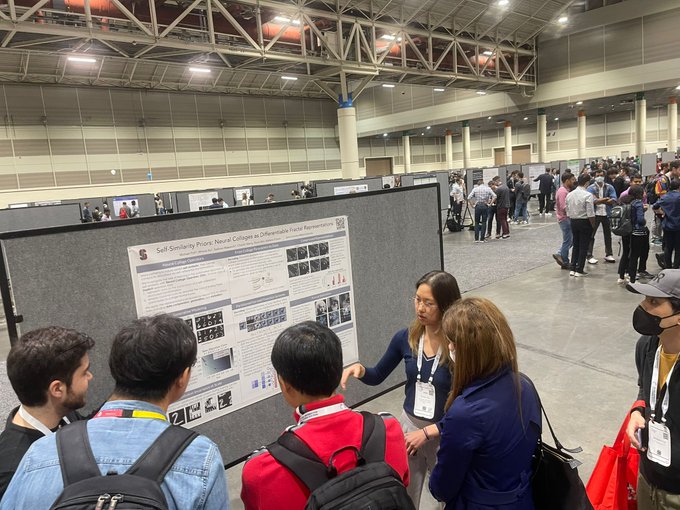
Pleased to share our work on Neural Collage Operators!
paper:
blog:
colab:
widget:


Let us embark on a fractal journey about dynamical systems and neural implicit representations... 1/
1
19
123
2
3
20
It's out!

Introducing TF-Coder 🖥
A program synthesis tool that helps you write tensor manipulations in TensorFlow. Simply provide an input/output example of the desired behavior, and leave the rest to TF-Coder!
Learn more →
Try it out →

14
311
1K
0
1
18
@dmdohan
@hmichalewski
@jaschasd
@sirbayes
@alewkowycz
@jacobaustin132
@Bieber
@Yuhu_ai_
@RandomlyWalking
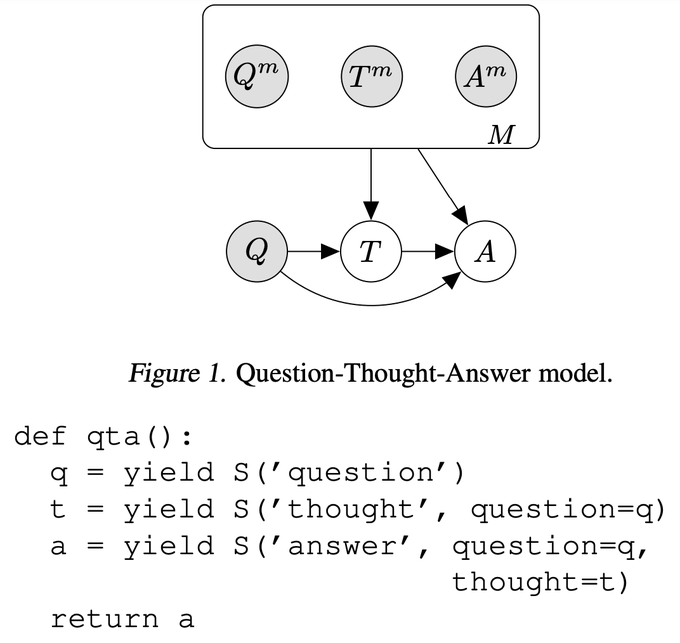
Since GPT3, we've seen many techniques for composing and prompting models. We view these composite systems as probabilistic (graphical) models. Some have control flow such as loops, requiring ideas from probabilistic programming languages (PPLs).
1
1
17
We will be presenting our poster (
#431
) this morning!
Come chat with myself and
@MichaelPoli6
about generative models, compression, and implicit representations!
Here's something your diffusion model can't do... (yet)
Pleased to share our work on Neural Collage Operators!
paper:
blog:
colab:
widget:
2
3
20
1
3
17
When I asked my language model for math advice, I guess I got some pretty pragmatic gardening tips: "one plus two is the right amount of organic fertilizer that will support your plants."
0
0
17
@ContextualAI
Starting with Mistral 7b Instruct as the base, we progressively aligned with 3 rounds of Kahneman-Tversky Optimization (KTO) on 3 disjoint partitions of the PairRM DPO dataset that utilized prompts only from UltraFeedback without external LLMs. 2/
3
0
16
Can confirm that Isaac Gym is pretty powerful, check it out!
(Look out for an Omniverse Gym release in the future... 😉)

Isaac Gym -
@NVIDIAAI
physics simulation environment for reinforcement learning research (preview Release)
- End-to-End GPU accelerated
- Isaac Gym tensor-based APIs fo massively parallel sim
Also get in touch for potential internships to flex in Gym!
8
44
243
0
1
16
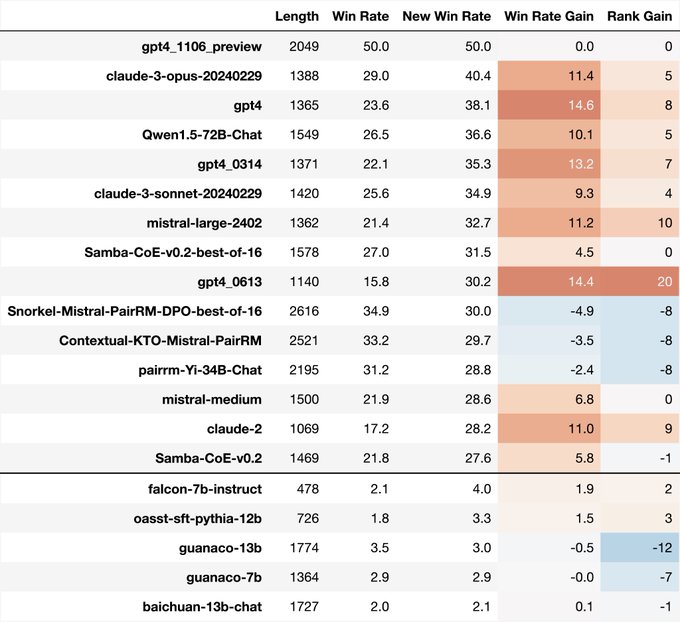
Awesome work on the update Yann, learned a lot from following the discussion on length biases, I’ll keep on cooking 😀

Closed models, often more concise, got a boost on LC AE. But open models are still looking strong:
-
@Alibaba_Qwen
72B-chat
@JustinLin610
@huybery
-
@SnorkelAI
’s Mistral PairRM
@HoangTranDV
-
@ContextualAI
’s Mistral KTO
@winniethexu
-
@allen_ai
’s Yi-34B PairRM
@billyuchenlin
...
1
4
16
2
0
15
When I first learned about neural nets back when I was a hardcore genetics student I had interpreted them as mathematics turned to biology - yes, not the other way around. Apparently now a science sellout (according to my med friends), maybe there's more to my theory after all!

More exciting
@Nature
news today: an example of how AI and neuroscience continue to propel each other forward. (1/2)

5
119
359
1
0
15
No words will ever do justice to how much I have learned and grown as a researcher and person these past few months. May the fourth forever be with this kind & brilliant team ❤️

1
3
14
Code is like a box of chocolates, ya never know whatcha gonna git:
1
0
13
Honored and humbled to be able to learn from and do great research with my amazing team of mentors and co-authors, especially
@kuanghueilee
and
@IMordatch
(:
0
0
13
@Massastrello
@MichaelPoli6
Many patterns in nature exhibit self–similarity, meaning they can be efficiently described via self–referential transformations. We propose to represent data as the parameters of a contractive, iterative map defined on partitions of the data space. This is a Collage Operator. 3/
1
0
13
@huggingface
Check out our blog and how you can use KTO here:
For further details, see our technical report
Privileged to have worked with
@ethayarajh
,
@jurfasky
(
@stanfordnlp
),
@douwekiela
6/

1
0
11
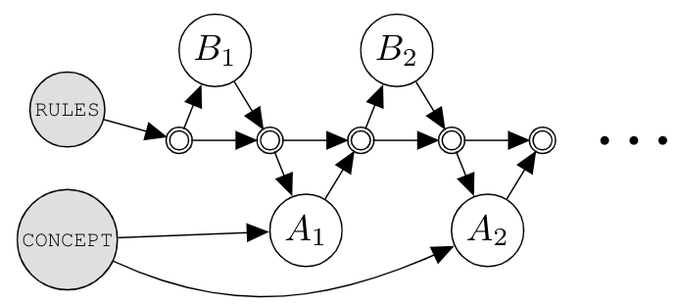
@dmdohan
@hmichalewski
@jaschasd
@sirbayes
@alewkowycz
@jacobaustin132
@Bieber
@Yuhu_ai_
@RandomlyWalking
We can also specify multiagent systems. Suppose we want to model Alice and Bob playing a guessing game of 20 questions (see paper for details). Using a Cascade, we can clearly represent the hidden knowledge each of them has.
1
1
11
@dmdohan
@hmichalewski
@jaschasd
@sirbayes
@alewkowycz
@jacobaustin132
@Bieber
@Yuhu_ai_
@RandomlyWalking
Where do we go from here? Cascades enable us to run inference on complex compositions of models. We want to be able to finetune end-to-end and amortize inference to make it more efficient. We aim to do probabilistic program induction to search for the best Cascade for a task.
1
2
11
@ContextualAI
It is becoming increasingly valuable in the enterprise setting to have high quality models that can leverage specialized data. With methods like KTO, base models can be easily fine-tuned and aligned without the need for human-annotated preference datasets. 3/
1
0
10
"You have to love <dancing> to stick to it. It gives you nothing back, no manuscripts to store away, no paintings to show on walls and maybe hang in museums, no poems to be printed and sold, nothing but that single fleeting moment when you feel alive." - Merce Cunningham
0
0
10
Woohoo!

🥳Thrilled to share Imagen Video: our new text-to-video diffusion model generating 1280x768 24fps HD videos!
#ImagenVideo
Website:
10
66
408
0
0
9
cc folks who might be interested:
@ericmitchellai
@chelseabfinn
@sleepinyourhat
@srush_nlp
@natolambert
@OriolVinyalsML
@johnschulman2
@_lewtun
@ancadianadragan
@lvwerra
@norabelrose
@alexgraveley
@tomekkorbak
1
0
8
indeed, i don't think i'll ever forgot how to derive an elbo

And... the first-ever ICLR test-of-time award goes to "Auto-Encoding Variational Bayes" by Kingma & Welling.
Runner-up: "Intriguing properties of neural networks", Szegedy et al.
The awards will be presented at 2:15pm tomorrow; there will be retrospective talks. Please attend!
5
60
635
0
0
9
sometimes the fake faces give me a lot of attitude too if I stare for too long:

0
0
9
Also check out
@ethayarajh
thread to learn more about the theory backing HALOs!

📢The problem in model alignment no one talks about — the need for preference data, which costs $$$ and time!
Enter Kahneman-Tversky Optimization (KTO), which matches or exceeds DPO without paired preferences.
And with it, the largest-ever suite of feedback-aligned LLMs. 🧵

19
130
698
0
2
8
How to be a woke academic: agglomerate "de facto" "ipso facto" "desiderata" and other latin superlatives into one sentence.
0
0
8
Check out our NeurIPS 2022 workshop! :)
Join us for the second edition of the
#NeurIPS2022
workshop "The Symbiosis of Deep Learning and Differential Equations"🌀
We're looking for your AI <> DE ideas: neural diff. eqs., neural operators, diffusion models and novel applications!
website:

1
13
33
0
0
8
Bits are all you need 😁

So it looks we can stick with the basic MLE/ELBO objectives (=compression!), as long as we combine it with the right kind of data augmentation.
Also, diffusion models have an interpretation as VAEs, so we can now again claim that VAEs are SOTA image generation models... 😅✌️
0
6
70
0
0
8
@Massastrello
@MichaelPoli6
In generative applications, a nice property of representing data implicitly as collage parameters is that they are resolution agnostic. This means that each unique, corresponding data sample can be decoded at any desired resolution (resources allowing) w/o the need to re-train 5/

1
0
8
@ContextualAI
Special thanks to
@ethayarajh
,
@shikibmehri
,
@yanndubs
,
@ContextualAI
for invaluable support and discussions 🫶
Also to
@MistralAI
and
@SnorkelAI
for the OS contributions that made all this possible!
Our model can be found on
@huggingface
hub here: 6/

1
0
8
@ContextualAI
I’m excited about a few more potential ways to incorporate intermediate and continuous signals into our alignment objectives, moving even further past binary preferences. Look out for more cool stuff coming soon! 😉 5/
1
0
8
@ContextualAI
The alignment protocol is KEY to achieving good results. We can see that tuning smaller base LLMs can be made more effective with richer signals such as rewards, curricula, or rankings. Methods like KTO allow us to incrementally improve with more nuanced data and more rounds. 4/
1
0
8
We've reached super human generation capabilities, these are some crazy samples!

0
0
7
Why? KTO only needs to know if an output is desirable or undesirable — not which of two outputs is better.
If you have a customer interaction that turned into a sale, that can turn into a datapoint for KTO. This is not the case for traditional preference optimization methods. 3/
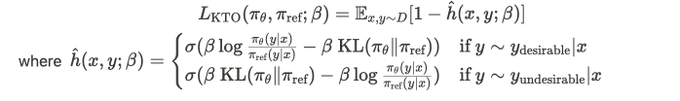
1
1
7
Sometimes life gives you lemons so you compress em anyways :) new paper with the dream team ❤️

Revisiting Associative Compression: I Can't Believe It's Not Better
By
@winniethexu
, myself,
@yanndubs
, and
@karen_ullrich
1
0
2
0
0
7
Now we can do LLM alignment without all that hassle, all because of a new method for aligning LLMs called KTO. It’s as good as state-of-the-art methods like DPO while not needing pairs of preference data.
This makes it much much easier to use in the real world. 2/
1
1
7
and cultured we are

2
0
7
Gotta love my Mac 😁
⚡️ Accelerating TensorFlow 2 performance on Mac
@Apple
’s new Mac-optimized TensorFlow 2.4 fork lets you speed up training on Macs, resulting in up to 7x faster performance on platforms with the new M1 chip!
Learn how ↓
27
432
2K
0
1
7

@Teknium1
@ContextualAI
yea basically 😅 all just dataloader changes and then alignment with KTO. i’m working on another version that leverages richer signals next, let’s see
1
0
6

Our simple API allows users to effortlessly experiment with and/or deploy large language models. You can apply for access on our site!
0
0
6
@chhaviyadav_
@NeurIPSConf
In order to not reschedule my exams last year, I had brought my suitcase to the exam center and booked it to the airport right after!
0
0
6

with undying conviction, I've completed my security compliance training.
0
0
6
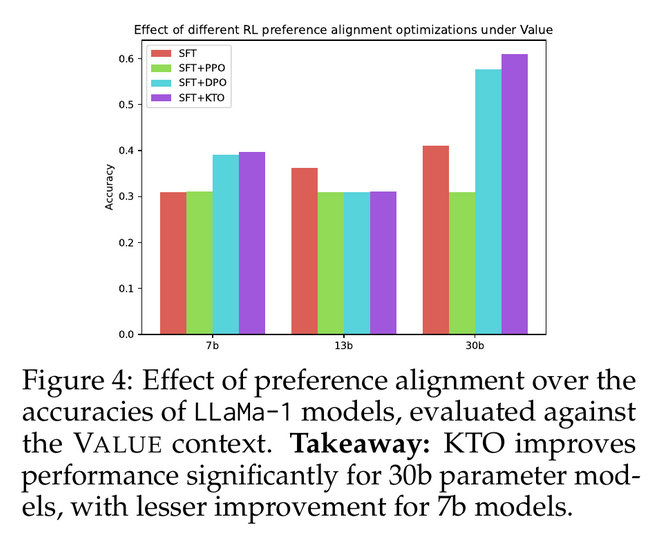
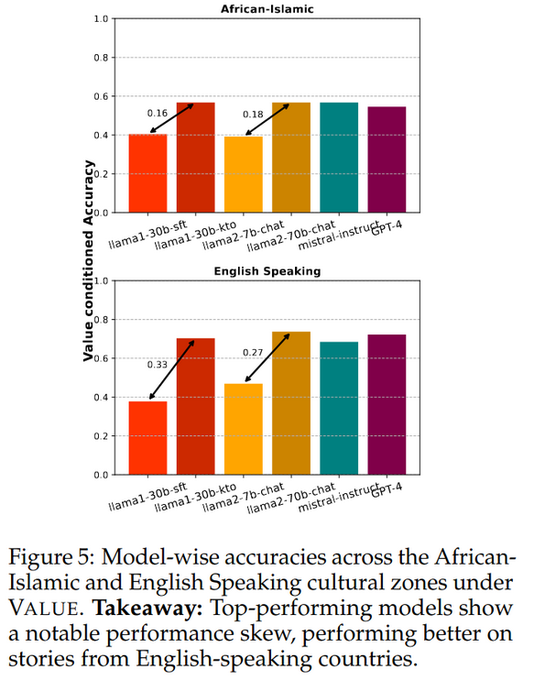
really neat study on alignment methods and cultural values!

When generalized to higher-level value contexts and just country names, performance plummeted to 60% and below for the best models. Larger models improved with different training paradigms, but exhibited greater skew towards English/Western cultures. [6/n]
1
0
2
0
0
6
This paper is awesome! Great insights and lets us reason about these powerful models with a bit more clarity

Elucidating the Design Space of Diffusion-Based Generative Models
abs:
improve efficiency and quality obtainable with pre-trained score networks from previous work, including improving the FID of an existing ImageNet-64 model from 2.07 to near-SOTA 1.55

0
43
272
0
0
5
Check out our results comparing supervised DT against online/offline RL algorithms. I'm certainly looking forward to exploring more ways to combine this paradigm of supervised learning and sequence modeling to tackle more problems in control / unstructured envs
1
0
5
@lovetheusers
@dmdohan
@jekbradbury
@ylecun
you can compose complex probabilistic programs (over string random variables in our case) and then apply various existing inference algorithms by sampling via the cascade ppl
0
0
5
@huggingface
So if you’ve spent all your money on compute resources and don’t have any left over for annotating preferences, don’t fret. You can remove the critical P in DPO and still effectively custom align models 😈 5/
1
0
5
Brought to you by implicit representations and spatial recapitulations:
0
0
5

@huggingface
@ethayarajh
@stanfordnlp
@douwekiela
and ofc with the amazing support of many others at Contextual
@realgmittal
@neilhtennek
@w33lliam
@aps
@caseyfitz
@Muennighoff
7/7
1
0
4
Paper:
Website:

0
0
4
Oh and can't forget, check out our team playlist 😸
0
0
3

@SeungjaeJungML
@Teknium1
@ethayarajh
@douwekiela
@_lewtun
@krasul
@lvwerra
@BanghuaZ
@tomekkorbak
@archit_sharma97
@rm_rafailov
@ericmitchellai
nice work! yes we’ve also been looking into the log sigmoid and sigmoid. i have ran some experiments comparing this too, haven’t any clear conclusions just yet
1
0
3
Magnum opus 👌

I have a new paper on how to represent part-whole hierarchies in neural networks.
46
615
3K
0
0
3
Comparing length normalized performance is a good idea, and no evaluation is perfect. Looking forward to exploring ways of getting our LLMs to generate better shorter responses :)

That said, notice the difference in length between the different models - this leaderboard (like any other) does not tell the full story. We need better evaluations!
Amazing job by
@winniethexu
!
1
0
4
0
0
3
@Teknium1
@huggingface
Enjoyed seeing all the sweeps! I've found similar things with increasing beta to get better perf on mt bench. If comparing between methods, not sure if you can compare via beta as for some methods it's likely there's a corresponding beta that reaches the same loss
0
0
3
impressive results with KTO!

Delving into Orca-Math's training strategy: It hinges on a strategic iterative process!🧠🔄 We kicked off with supervised finetuning (SFT), followed by two rounds of KTO. This SFT-KTO-KTO sequence proved more effective than a straight SFT series and surpassed DPO too.
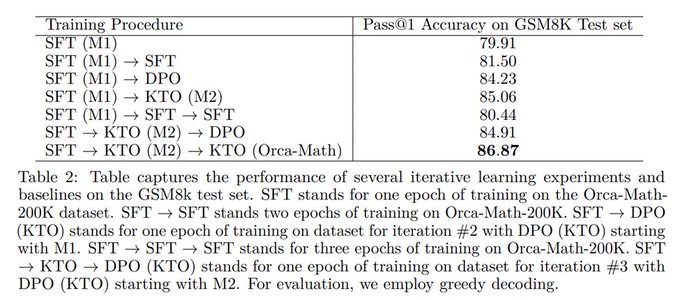
1
3
26
0
0
3
@ericssunLeon
@gblazex
@ContextualAI
The new length adjustment method uses a simple regression model to Trying to estimate the counterfactual "what would the win rate be if the length was X" where X=len(baseline). Still not a perfect metric and very simplified assumption over certain variables + a fixed relationship
0
0
3
can't wait to play with this tool :o

Happy to support our frens Abraham AI for those of you who were asking about inpainting and
#StableDiffusion
.
There is a *lot* to come.
Very excited and as we will release open source this will unleash a wave of innovation and creativity globally beyond what we seed.
12
33
259
0
0
3

@lzamparo
@aidangomezzz
@sorenmind
@oatml
@CohereAI
@JanMBrauner
@MrinankSharma
@mtrazzak
@BlackHC
@adrien_morisot
@seb_far
@yaringal
haha thanks, credit to hoffman ;)
0
0
3
Alex is amazing at making complex things easier to understand, highly recommend!
0
0
3