

Allan Zhou
@AllanZhou17
Followers
1,221
Following
470
Media
36
Statuses
200
AI PhD student @Stanford .
Menlo Park, CA, USA
Joined March 2022
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
ALL EYES ON RAFAH
• 796778 Tweets
De Niro
• 387631 Tweets
Palestino
• 103996 Tweets
Fernando
• 92116 Tweets
#WWENXT
• 56714 Tweets
Thomsen
• 54044 Tweets
#خادم_الحرمين_الشريفين
• 50758 Tweets
Millonarios
• 38365 Tweets
Lali
• 37777 Tweets
Lali
• 37777 Tweets
Coronado
• 36152 Tweets
Lala
• 35490 Tweets
Renê
• 34261 Tweets
DAME MIL FURIAS
• 34159 Tweets
Paulinho
• 33737 Tweets
Peñarol
• 30256 Tweets
$BOOST
• 26582 Tweets
Wesley
• 18251 Tweets
Sudamericana
• 16133 Tweets
Josh Gibson
• 14829 Tweets
Jordynne Grace
• 13047 Tweets
#PumpRules
• 11494 Tweets




















Pinned Tweet

🧵: How do you design a network that can optimize (edit, transform, ...) the weights of another neural network?
Our latest answer to that question: *Universal* Neural Functionals (UNFs) that can process the weights of *any* deep architecture.
5
116
805
My reaction when I hear NLP folk talking a lot about RL recently.

4
73
836
How can we design architectures that can process or transform neural networks?
We introduce a framework of *Neural Functionals* that process NN weights while respecting their permutation symmetries.
Paper:
1/9
3
79
384
academics advertising their latest finetuning objective to anime pfps on twitter

6
21
314
"This just proves that tests are only about memorization, not reasoning or understanding."
0
3
59
I'll be presenting this work at NeurIPS next week, as well as NFTs (not that kind--). DM me if you're around and want to chat.

How can we design architectures that can process or transform neural networks?
We introduce a framework of *Neural Functionals* that process NN weights while respecting their permutation symmetries.
Paper:
1/9
3
79
384
0
8
57
Paper:
Most of this work was done at Google DeepMind, with amazing mentorship by
@chelseabfinn
and
@jmes_harrison
. Also, thanks to the TPU Research Cloud (TRC) for providing additional compute!

1
2
55


Coming to
#ICLR2024
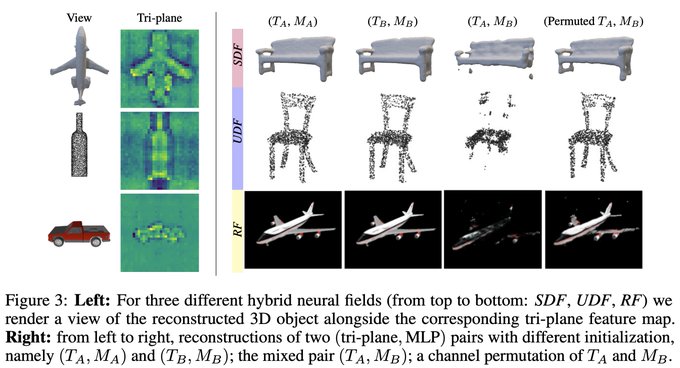
: what's the best way to extract information from implicit neural representations (INRs)?
We show that tri-planes alone are enough to effectively classify or segment 3D objects in neural fields. 🧵
1
6
41

If the world were truly bitter, NAS/AutoML/etc would have worked. But the best optimizers/architectures/hparams are still found by humans, not meta-methods that leverage compute. Sad.
4
0
35
Check out our library to build your own UNFs! It can actually build permutation equivariant models for *any* collection of tensors, weights or not. You describe the permutation symmetries, and it gives you equivariant layers:

1
2
30
ilya knows that it's time for weight-space architectures to shine :>

1
3
31

What openAI needs now is a strong, ethical leader who won't get embroiled in any controversies


0
3
26
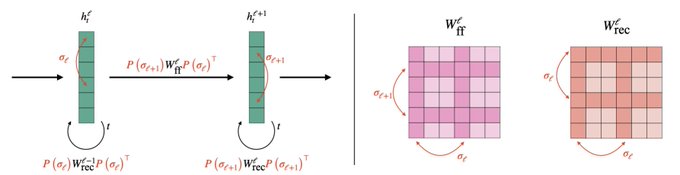
NN weight spaces are riddled with permutation symmetries, which we have to account for. The original approaches (DWS&NFN) could only handle feedforward symmetries, while UNFs can handle the symmetries of any arch (e.g., RNNs & Transformers).
1
1
24
@archit_sharma97
@ericmitchellai
1600-1970: share scientific results in letters and private correspondence
1970-2022: journal pubs and "peer review" 🤢
2022+: post scientific results directly to X, alongside memes shitposts and flamewars
2
4
25
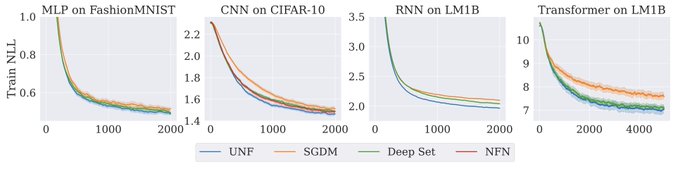
In the paper, we use UNFs to create "architecture-aware" learned optimizers--optimizers that "know" the symmetry structure of the weight space they optimize:
1
0
19
We’ve released a PyTorch library for building NFNs, available through “pip install nfn”.
Code: .
With
@kaien_yang
,
@kaylburns
,
@yidingjiang
,
@ssokota
,
@zicokolter
,
@chelseabfinn
.
9/9
3
1
18



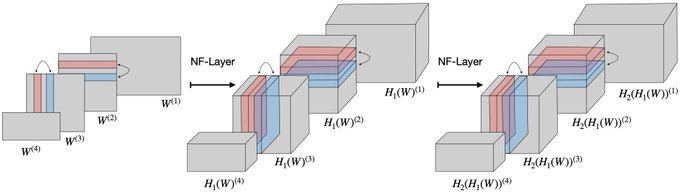
Our neural functional networks (NFNs) operate on weight space features, just like a CNN operates on spatial features.
NFNs consist of NF-Layers that are equivariant to the permutation symmetries of NN weight spaces, analogous to translation equivariance in conv layers.
2/9
1
0
15
We’re really excited about applications of neural functionals to INRs, learned optimization, and pruning.
In a similar direction, check out recent work by
@avivnav
characterizing equivariant layers for MLPs and their expressivity in the HNP setting:
8/9

(1/10) New paper! A deep architecture for processing (weights of) other neural networks while preserving equivariance to their permutation symmetries. Learning in deep weight spaces has a wide potential: from NeRFs to INRs; from adaptation to pruning 👇
8
130
742
1
0
15
I really like the idea of training on datasets with an older cutoff date and testing on more recent discoveries to test reasoning (and weak-to-strong generalization). Like back-testing for AGI.

Has anyone tried to train AI with only 19th century sources and see whether it can discover special relativity?
91
184
3K
0
0
15
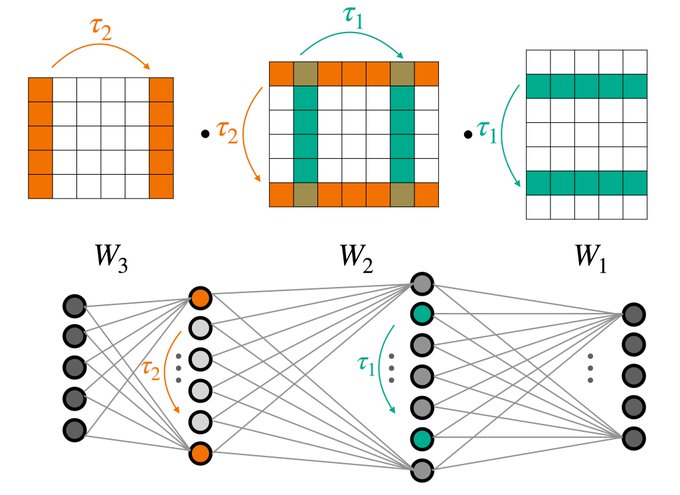
NF-Layers are linear layers whose input and output are weight space features, and they satisfy NN permutation equivariance through parameter sharing.
(Weight space features typically have multiple channels, but we show the 1-channel case here for simplicity.)
3/9
1
0
13
Some cool recent publications on equivariant GNNs for processing weights/gradients/etc. Roughly, weights are just edges between neurons, so message passing NNs can process and update the edge features for you...
1
0
14
"TF-datasets isn't worth the trouble, I'll write my own dataloaders. It's just some jsonl files."
> 2 wks of multiprocessing bugs later:

0
1
14
Yeah, we work on AGI (Amphibious Gaze Improvement).

With the advent of AGI, humans will soon be the weakest link in software industry. How can we have better coding buddies that *enhance* humans?
Introducing 𝐁ug 𝐀nalysis and 𝐈dentification with enhanced 𝐓oads (BAIT), where we fit toads with contact lenses to better catch bugs
11
37
290
0
0
14
We also train NFNs to edit INR weights to produce visual changes, like image dilation:
6/9

1
0
9
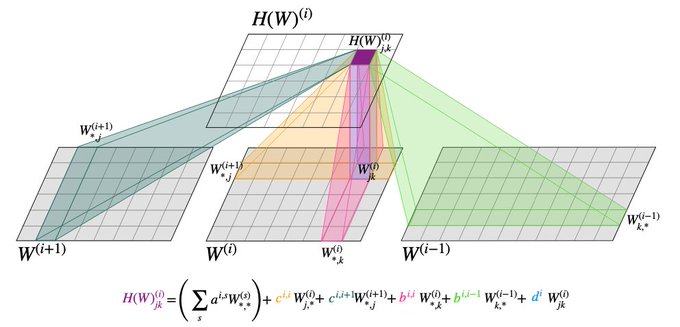
We define two NF-Layer variants (NP and HNP) with different levels of parameter sharing.
The NP variant is especially efficient: if you’re processing an L-layer NN, then it uses just O(L^2) parameters, regardless of the hidden widths or input/output sizes!
4/9

1
0
9
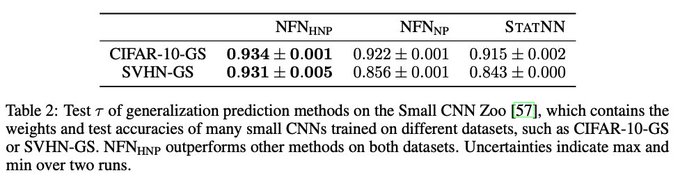
We also find that on a generalization prediction benchmark, NFNs improve upon previous approaches for predicting the test accuracy of CNN classifiers:
7/9
1
0
8
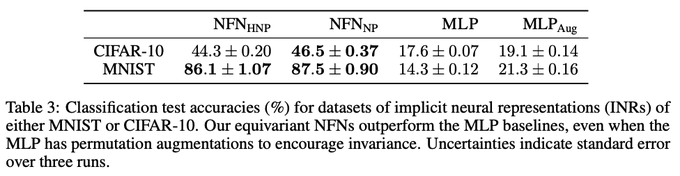
NFNs let us treat Implicit Neural Representations (INRs) as datasets, with the weights of each INR as a single data point.
For example, NFNs can do “image classification” by classifying the weights of INRs trained on each image.
5/9
1
0
7
@natolambert
If the derivation of Eq 4 is a bit esoteric, there's always the more direct (but tedious) approach: form the Lagrangian L(π)=E[r(y)]-βKL(π||π_ref)+λ(∑π(y)-1) and set dL/dπ(y)=0, solve.
1
0
7
@davikrehalt
@abacaj
these days when I see a twitter post showing examples of failed LLM reasoning, I get the answer wrong myself ~50% of the time
2
1
6
anyone who's ever watched a romcom knows this ends with the AI matchmaker becoming the love interest

Bumble founder Whitney Wolfe Herd says the future of dating is having your AI date other people's AI and recommend the best matches for you to meet
2K
586
4K
0
0
7
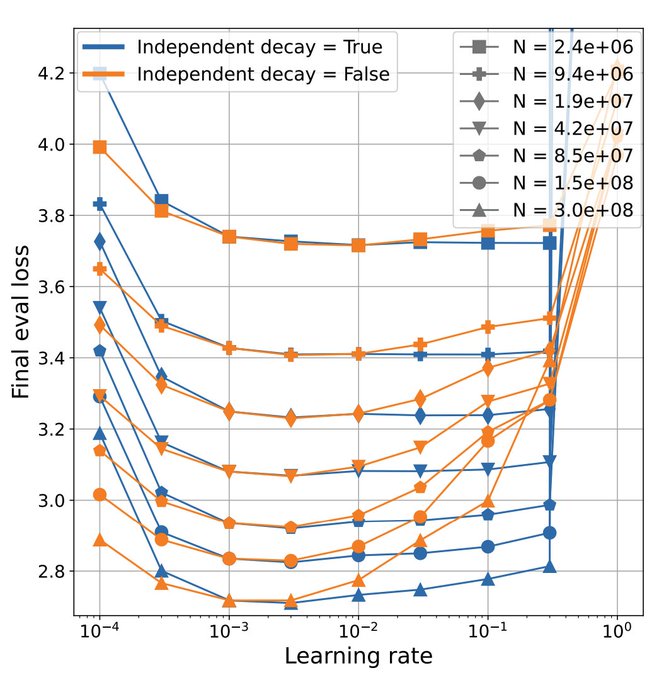
@FSchaipp
I didn't know this until reading . Decoupling wd from alpha seems helpful for LR stability
0
0
6
@sp_monte_carlo
Looking at such diagrams are very useful for figuring out the permutation symmetries of the NN's weight space 😛
0
0
4
Copilot still doesn't know basic Equinox APIs (tries to use nn.Dense instead of nn.Linear). It's not that new, I guess Copilot just struggles with lesser known libs?
3
0
5

Blondie laughs in the face of your "prediction markets"


0
0
4
@nabeelqu
i've used anki for many years, but for technical content many things do require a type of practice that isn't amenable to flash card form (e.g., actually writing out code or solving practice problems in math).
2
0
4

IIUC the actual Einstein notation should only express coordinate-free calculations. But np.einsum can calculate the diagonal, hadamard prod, etc. Is there a precise description of what einsum can/can't do?
2
0
2
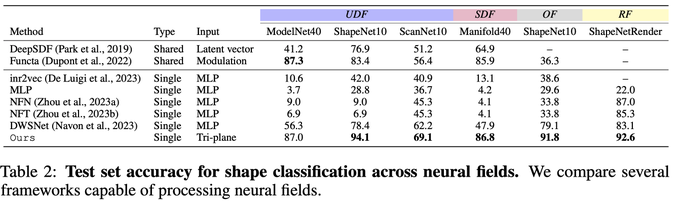
Processing tri-planes works a lot better than processing raw INR weights, with basically no negative impacts on the original INR training process.
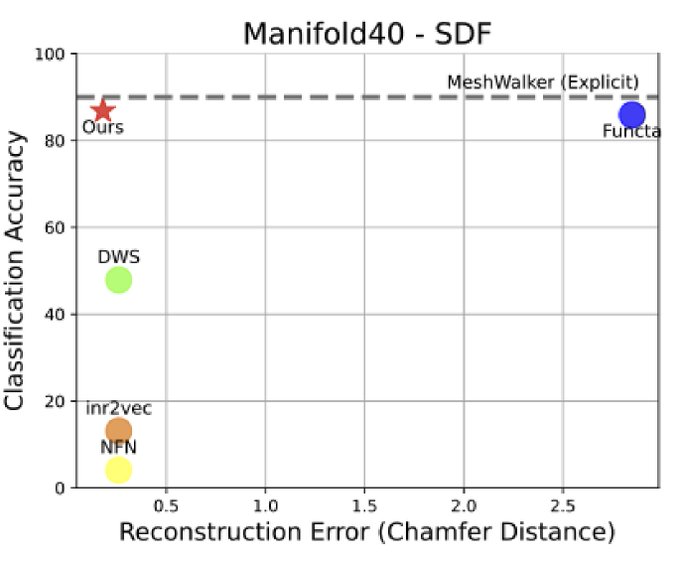
1
0
1
@natolambert
Ah, it's a sum over x weighted by p(x)>=0, so we just want to maximize each term independently wrt to π[·|x]. It's purely to simplify notation--we can calculate dL/dπ[y,x] (thinking of π as a matrix instead of a vector), just messier.
1
0
3
Are the export controls actually doing anything? Seems like China is at the frontier for (open) pretraining.
1
0
3
@EugeneVinitsky
Yeah, I go back and forth on whether we need to (1) find a better design for the search space in these meta-methods, or (2) we just need to wait 30 years for more compute
1
0
3
@PandaAshwinee
@JacquesThibs
See Sec 3.3 (lottery tix) in this paper. TLDR: it worked on small networks, but was learning a very simple magnitude pruning rule. Probably need to scale up to see more interesting behavior, but the data is expensive to generate. .
1
1
3
And as
@dereklim_lzh
pointed out to me, the NFN layer equation is basically doing message passing operations. Yet I didn't see the resemblance earlier 😅
0
0
3
@sp_monte_carlo
are there any good (casual) intros to RG methods for a more stats/ML audience?
2
1
2
@nabeelqu
and for practice problems, sure you can add them as cards but it's boring to see the same problem over and over. maybe soon we can have AI automatically rewrite variants of a problem for each next review.
0
0
3
Alcubierre drive is next

0
0
3
@JacquesThibs
Maybe! Haven't followed interpretability lit too closely. We've tried to predict useful "subnetworks" (as in lottery tix) in the past, want to explore that more. Could also learn correlations btw neuron activations, which might be relevant.
1
0
3
@g_k_swamy
@wgussml
What makes RM+PPO more interactive? One could also iteratively train DPO no (by successively replacing the ref model)?
1
0
2
@davikrehalt
@QuanquanGu
Bard actually got the answer wrong on purpose to demonstrate that it's not memorizing.
0
0
2
@sp_monte_carlo
I suspect most of the benefit of CNNs were computational: weight sharing + small 3x3 filters can efficiently process huge 512-chan feature maps, compared to MLPs.
1
0
2
@g_k_swamy
@archit_sharma97
I like how Ng himself did some IRL work back in the day, but doesn't really bring it up as far as I've seen
0
0
2
@ericjang11
@ylecun
I haven't been able to get self-critique to work on this problem *unless* the original prompt contains
@stanislavfort
's "LeCun trick," which imo provides a strong hint that it is a trick question.
1
0
2
@robinhanson
Though I'm inclined to believe the result, the latter half of the abstract makes so many unsubstantiated prescriptions it's hard to take the paper seriously.
0
0
1
@shxf0072
@polynoamial
yes, alphago was a much better demonstration of the bitter lesson than modern LLMs are imo
0
0
2
can't be sure this is fake but it's almost too convenient for a certain narrative right now...
1
0
2


@natolambert
To add, there are no constraints linking π[·|x] for different values of x, so the problem separates over x, with one term p(x)(\sum_y [...]) per x.
0
0
2
I'm pretty sure there are things you can't do with einsum that you can with eindex-scatter, eg:
1
0
1
@ThomasW423
@chelseabfinn
Similar! I tend to think of hnets as generating weights, while unfs process them. Permutation symmetries become really important for the latter
1
0
2
@NVIDIAAIDev
@nvidia
InstantNGP is an awesome tool, and was a huge time saver for this project!
0
0
2

@AlbertQJiang
@davikrehalt
@Yuhu_ai_
@jimmybajimmyba
Naive q: is there a particular reason to view a tactic as an action, rather than a token? In code generation, I've seen papers adopt the latter. Perhaps it doesn't make a difference in practice?
1
0
0
@YingXiao
@finbarrtimbers
Equinox uses the pytrees abstraction most cleanly imo. But even there pytrees can be very annoying, e.g. when we just want to modify a property of a single layer.
1
0
1
@urusualskeptic
Ah, good idea. But I haven't gotten any variant of that to work yet either. E.g.: "import equinox.nn as eqx_nn".
1
0
1
@stammertescu
@sp_monte_carlo
Yeah, I prob just lack bg knowledge for most treatments. E.g., there's pretty good stuff on the replica trick for an ML audience. But not for RG for some reason.
1
0
1
@RamanDutt4
@chelseabfinn
@jmes_harrison
Yeah! We don't run any exps like that but
@avivnav
trained DWS to transfer classifiers btw domains: check out 7.1 of
1
0
1
I'm really curious if we've benchmarked *median* human performance on all these LLM reasoning tasks. Not academics--median humans. Something like , which was for vision.

0
0
1
Weird that the first papers on equivariant weight-space architectures (DWS and NFNs) didn't focus on the graph perspective, even though everyone typically visualizes an MLP as a graph.
1
0
1
@rtaori13
maxtext or levanter? I would shill midGPT too, but our open code only supports OWT (same as nanoGPT)
1
0
1
@davis_yoshida
@DataSciFact
I sometimes take for granted how much easier training is now. In 2010, it was probably pretty difficult to train deep networks stably.
0
0
1
@sp_monte_carlo
Relatedly, locally connected (no equivariance but sparse filters) can sometimes do roughly as well as CNNs. But no weight sharing -> uses more memory.
0
0
1
@SamuelAinsworth
@EpisodeYang
I'm a bit OOTL, does 3DGS handle dynamic scenes/moving objects now? Otherwise, seems like most of the artifacts would just be from motion.
1
0
0
@ThomasW423
@chelseabfinn
Good point, in the context of editing/optimizing, we can say UNFs are a special type of hnet. But UNFs (and DWS/NFNs) can also extract info: give it the weights of a 3D INR and ask it to classify the 3D object they encode.
0
1
1
@alexfmckinney
@__kolesnikov__
@xhluca
Thanks! I think I used this once briefly but couldn't understand the output, I'll try looking more carefully this time. Another indirect method is to profile and look at the XLA ops in the TB trace viewer, though it's also a bit confusing.
1
0
1
@__kolesnikov__
@alexfmckinney
@xhluca
How do we check what the compiler is actually doing under the hood? Jax makes it easy to shard parameters+data going into the computation, but it's not clear how to see what's actually happening after JIT.
2
0
1
@jxbz
@TheGregYang
Cool work! Your slides mention that for depth scaling we want ||dW||/||W||~(1/L), does muP achieve that? Or is there a parameterization that does?
1
0
1
@YananLong
@BlancheMinerva
TPU v3-8's typically, I think. It can be hard to launch one on-demand, but preemptibles are fairly available.
1
0
1
@ericmitchellai
@akbirthko
not sure but when considering methods like search (rather than learning), I think compute is the right variable
1
0
1