

Snorkel AI
@SnorkelAI
Followers
16K
Following
728
Media
713
Statuses
2K
🧠 Expert Data, Unparalleled quality 🚀 Powering Frontier Labs, Fortune 500 & gov't
Redwood City, California
Joined July 2019
Bigger models ≠ better AI. Better data = better AI. The future belongs to enterprises that can rapidly create, customize & evaluate their data. 🎥 Snorkel co-founder Braden Hancock explains: https://t.co/RyFKKCF3Pq
#AI #LLMs #DataCentricAI
1
1
6
Snorkel’s Daniel Xu → “Optimized Infrastructure” panel, Sept 11, 1:50–2:30 PM. TY @awscloud + Amazon SageMaker for hosting; joined by Walgreens Boots Alliance, @datadoghq, Lablup Inc. #AIInfraSummit

0
0
1
We partner with our network of vetted experts, using detailed evaluation rubrics to generate high-quality datasets that improve AI applications. Follow us @SnorkelAI for updates, & if you need expert-verified datasets for your evaluation needs, talk to us!

snorkel.ai
Snorkel Expert data-as-a-serviceSpecialized data, designed and delivered by experts Accelerate the evaluation and development of frontier AI models with a scalable, white-glove service that provides...
0
0
0
The techniques and categories combine! A complete rubric typically includes some of all of them. Choose your rubric strategy based on domain requirements and evaluation goals🎯
1
0
0
METHOD: Automated (LLMs for scale / code for strict correctness), human experts (nuanced, intuitive evaluation), and reward models (emerging hybrid approaches)
1
0
0
LOCATION: Process-based (how models reason, catches lucky guesses) vs outcome-based (final answer quality, objective verification)
1
0
0
GRANULARITY: Coarse-grained (single "goodness" score / fast screening) vs fine-grained: multiple dimensions (diagnostic precision) SPECIFICITY: Dataset-level (universal criteria) vs instance-specific (tailored per prompt)
1
0
0
Well-crafted rubrics provide a systematic approach to improving AI applications, useful for both automated and HITL expert evaluation. Our post breaks them down in four ways:
1
0
0
Part 2 of our AI evaluation rubrics series is live! 🧵 The right tool for the job: an A-Z of rubrics https://t.co/iknUrWKGEB

1
0
1
SnorkelGraph is part of our expert-verified benchmark suite, designed to systematically test LLM reasoning across math, spatial, and graph domains. Follow us for updates, and if you need expert-verified datasets for your evaluation needs, talk to us!
0
0
0
As the leaderboard shows, this benchmark is far from saturation ATM: https://t.co/Qe0UiN94cf We’re looking forward to seeing continued advances in this skill, particularly in open models.
1
0
0
We control difficulty with: 🔹 Graph size: more nodes/edges = more elements to reason over 🔹 Operator complexity: different ops stress different reasoning skills (counting, paths, optimization)
1
0
0
Each question asks the LLM to compute the outcome of a natural language question (operator) over graphs encoded via node + edge lists. Example: “Find the minimum-density subgraph…” Because these questions all come with verifiable answers, LLM responses are easy to evaluate.
1
0
0
Operations in graph theory are fundamental to analyzing complex systems, and provide a multi-hop, long-context reasoning challenge for LLMs. That’s why we built SnorkelGraph: a benchmark for evaluating graph reasoning with verifiable ground truth. https://t.co/Qe0UiN94cf

1
0
3
The best RL envs look like product specs: tools, data, rubrics, simulators. That’s where Snorkel lives. Interested? Let’s chat.

Lots of chatter about agentic/RL simulation environments recently! Some key misconceptions (slightly caricatured): >> Building RL envs is easy, because you just code up a verifier quickly, and let the model do the tough data generation on its own! - Usually, this boils down to
0
1
7
Want to improve a smaller model’s reasoning skills? Our DaaS team is building expert-curated datasets for reasoning, function calling, and more. Let’s talk!
snorkel.ai
Snorkel Expert data-as-a-serviceSpecialized data, designed and delivered by experts Accelerate the evaluation and development of frontier AI models with a scalable, white-glove service that provides...
0
1
2
Key insights: 1️⃣Reasoning > non-reasoning models. Better living through inference-time compute! 2️⃣Smaller open-weights models struggle without fine-tuning or other post-training optimization 3️⃣SnorkelWordle is a strong signal for evaluating reasoning, especially in smaller models
1
1
2
Word games yield valuable insights when evaluating LLMs. We built the SnorkleWordle benchmark to test models on 100 rare English words—and the results are 🔥
2
2
11
Great AI isn’t about more data, it’s about the right data. Snorkel crafts expert datasets that help AI reason, and solve problems. From coding to video and multi-turn conversations, our data powers AI built for real-world challenges. See how: https://t.co/VLw1LGzlkg
0
0
3
Check out Snorkel researcher @chris_m_glaze’s teaser on experiments he’s been running on AI agents ⬇️⬇️

From ongoing idealized experiments I've been running on AI agents at @SnorkelAI: in this one, most frontier models either (1) are slow to learn about tool-use failures in-context or (2) have a very high tolerance for these failures, showing almost no in-context learning at all.
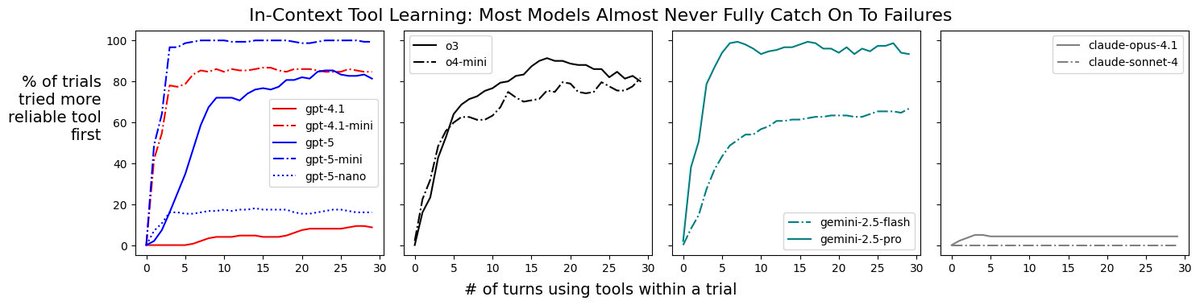
1
0
2