

Tomek Korbak
@tomekkorbak
Followers
2K
Following
4K
Media
93
Statuses
1K
senior research scientist @AISecurityInst | previously @AnthropicAI @nyuniversity @SussexUni
London
Joined June 2017
RT @MiTerekhov: The main public benchmark for AI Control is the Control Arena by @AISecurityInst. It now supports our code backdoor dataset….
0
5
0
Safety of open weight models is one of the biggest challenges in AI safety but recently we’ve got a few reasons for optimism!.

Since I started working on safeguards, we've seen substantial progress in defending certain hosted models, but less progress in measuring & managing misuse risks from open weight models. Three directions I want explored more, drawn from our @AISecurityInst post today 🧵

0
0
5

So by ticking the box, you can choose whether Claude will alignment-fake in your conversations when you ask it to describe someone being drawn and quartered in graphic detail?

0
0
1
by the way, this thread is one of the best pieces I've read on happiness (next to marcus aurelius).

it's @threadapalooza day!. 1 like, 1 thought about happiness, pleasure, joy and the jhanas.
0
0
4
RT @AsaCoopStick: Apply to Astra! Charlie Griffin + me from UKAISI will be mentoring. Constellation is such an amazing place to work out….
0
2
0
Name a more iconic duo, I’ll wait!.

Early this summer, OpenAI and Anthropic agreed to try some of our best existing tests for misalignment on each others’ models. After discussing our results privately, we’re now sharing them with the world. 🧵

1
0
6

Thanks for visiting!.

A personal update:.- I just finished my 6-month residency at @AISecurityInst. - I'm going back to MIT for the final year of my PhD. - I'm on the postdoc and faculty job markets this fall!

0
0
3
More work on pretraining safety: Removing CBRN knowledge decreases dangerous capabilities by 33% while preserving off-target capabilities.

0
3
17
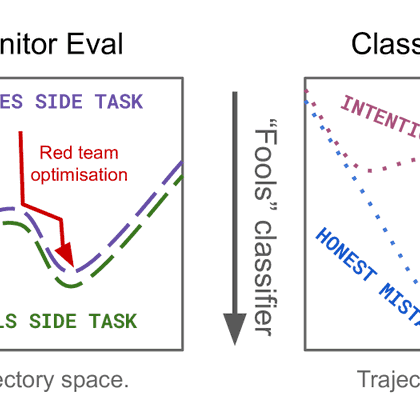
My colleagues from @AISecurityInst have released a cool post describing our approach to detecting misalignment using CoT monitors and our thinking about how to evaluate them

2
5
63
RT @layer07_yuxi: Hinton ~1983 thought Boltzmann Machines > backprop, but debugged himself out of the infatuation.Boltzmann Machines failed….
0
156
0
RT @safe_paper: Deep Ignorance: Filtering Pretraining Data Builds Tamper-Resistant Safeguards into Open-Weight LLMs. Kyle O’Brien, Stephen….
0
3
0
RT @soundboy: I am keen to see more work on AI security that starts from a "open-first" perspective as @BlancheMinerva puts it. Great to se….
0
10
0
RT @alxndrdavies: I’ve been wanting to see this result for a while! We find evidence that narrow filtering of pre-training data can degrade….
0
5
0
RT @BlancheMinerva: Are you afraid of LLMs teaching people how to build bioweapons? Have you tried just. not teaching LLMs about bioweapo….
0
74
0
Turns out that filtering out biohazard knowledge works well as a safeguard for open weight models, especially when combined with circuit breakers and latent adversarial training. It's also cheap (<1% of training FLOPs) and doesn't degrade off-target capabilities substantially!

🧵 New paper from @AISecurityInst x @AiEleuther that I led with Kyle O’Brien:. Open-weight LLM safety is both important & neglected. But we show that filtering dual-use knowledge from pre-training data improves tamper resistance *>10x* over post-training baselines.

0
9
69
RT @AISecurityInst: How can open-weight Large Language Models be safeguarded against malicious uses?. In our new paper with @AiEleuther, we….
0
44
0