
Anca Dragan
@ancadianadragan
Followers
8,432
Following
179
Media
14
Statuses
198
AI safety & alignment at Google DeepMind • associate professor at UC Berkeley EECS • proud mom of an amazing 2yr old
San Francisco, CA
Joined March 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Luka
• 338966 Tweets
ダービー
• 54409 Tweets
Kano
• 51236 Tweets
#超超超超ゲーマーズday1
• 34988 Tweets
Our Beloved TAYNEW🧸
• 29235 Tweets
サクナヒメ
• 28663 Tweets
ジャスコ
• 19806 Tweets
マイフリ
• 19784 Tweets
#MUSICFAIR
• 18835 Tweets
レイちゃん
• 16969 Tweets
아카라카
• 15843 Tweets
クマフェス
• 13919 Tweets
DOYOUNG SEOUL CONCERT DAY1
• 13498 Tweets
ビーズリー
• 13360 Tweets
葵ステークス
• 11475 Tweets





















So excited and so very humbled to be stepping in to head AI Safety and Alignment at
@GoogleDeepMind
. Lots of work ahead, both for present-day issues and for extreme risks in anticipation of capabilities advancing.

We're excited to welcome Professor
@AncaDianaDragan
from
@UCBerkeley
as our Head of AI Safety and Alignment to guide how we develop and deploy advanced AI systems responsibly.
She explains what her role involves. ↓
50
64
533
31
40
605
I had a TON of fun talking to Lex about the game-theoretic perspective on coordinating with people and value alignment, capitalizing on leaked information from humans, modeling humans as rational under different beliefs, and also personal stories!
12
25
292
Imagine asking an LLM to explain RL to you, or to book a trip for you. Should the LLM just go for it, or should it first ask you clarifying questions to make sure it understands your goal and background? We think the latter: (w Joey Hong and
@svlevine
)

4
30
205

I'm often asked if it's worth it to build mathematical models of human behavior, rather than learn everything from scratch. We took a small first pass at starting to quantify the utility of the "theory of mind" bias for robots:

2
25
129
On the research side of
@Waymo
, we've been experimenting with what it takes to learn a good driving model from only a dataset of expert examples. Synthesizing perturbations and auxiliary losses helped tremendously, and the model actually drove a real car!

0
33
112

Proud to share one of the first projects I've worked on since joining
@GoogleDeepMind
earlier this year: our Frontier Safety Framework. Let’s proactively assess the potential for future risks to arise from frontier models, and get ahead of them!

6
21
138
Thanks
@pabbeel
for inviting me to your podcast, it was very fun to have an interview with a colleague and close friend! :)

On Ep15, I sit down with the amazing
@ancadianadragan
, Prof at Berkeley and Staff Research Scientist at Waymo. She explains why Asimov's 3 laws of robotics need updating, how to instill human values in AI and make driverless cars naturally reason about other cars and humans.
6
11
103
1
8
92
Proud of my team for building safety into these models and watching out for future risks. More on this soon with our Gemini technical report, and prep ahead of the AI Seoul Summit!!

Making great progress on the Gemini Era. At
#GoogleIO
we shared 2M long context breakthrough with 1.5 Pro and announced Gemini 1.5 Flash, a lighter-weight multimodal model with long context designed to be fast and cost-efficient to serve at scale. More:
19
75
516
0
9
86
Excited to be hosting a fantastic group of prospective AI PhD students, chosen out of over 2000 applications.


2
3
82
My first attempt at a talk for a public audience, explaining some of the intricacies of human-robot coordination. Also a non-technical overview of work with
@DorsaSadigh
, Jaime Fisac,
@andreaBajcsy
, and collaborators from Claire Tomlin's group:

0
7
80
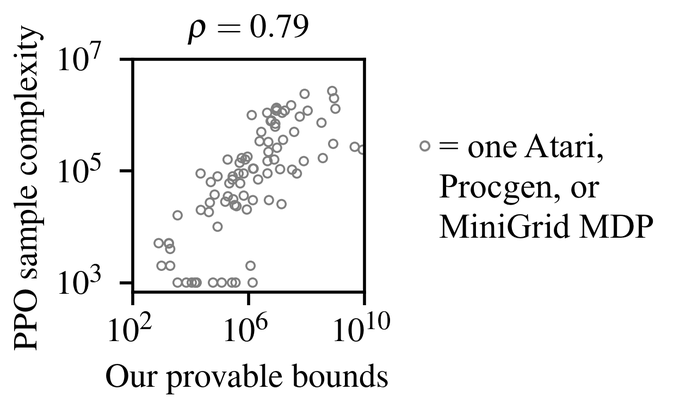
I think this is a pretty big deal. It's all deterministic, but even so that's where the deep RL big results started. TL;DR: whether or not you can just be greedy(ish) on the random policy's value function predicts PPO performance.

Excited to present our new paper on bridging the theory-practice gap in RL! For the first time, we give *provable* sample complexity bounds that closely align with *real deep RL algorithms'* performance in complex environments like Atari and Procgen.
6
57
296
4
3
65
Super proud of and happy for
@DorsaSadigh
, so well deserved!!!

Congratulations to
@StanfordAILab
faculty Dorsa Sadigh on receiving an MIT Tech Review TR-35 award for her work on teaching robots to be better collaborators with people

9
14
180
1
2
63
RS and RE roles, growing our bay area presence as part of our further investment in safety and alignment:
3
7
65
@GaryMarcus
Dudes... Is this really constructive scientific debate or are you two just sh***ing on each other at this point? We could ask for clarification instead of accusing inconsistency. I for one would like to learn from you both, not have my BP rise every time I go on twitter.
1
0
61
congrats
@andreea7b
for another HRI best paper nomination, this time for getting human input that is designed to focus explicitly on what the robot is still missing

1
4
61
Super excited this finally got published: a useful way to interpret many kinds of human feedback beyond demos/comparisons, to corrections/language/proxy rewards/the state of the world, is to think of them as implicit choices the person is making with respect to the reward.
1
7
56
Hard at work on supervised/imitation learning. Fei-Fei, you'll like this ;)
@ai4allorg
@berkeley_ai
@drfeifei

3
12
56
Assistance via empowerment: agents can assist humans without inferring their goals or limiting their autonomy
by increasing the human’s controllability of their environment, i.e. their ability
to affect the environment through actions (also
@NeurIPSConf
)
1
10
53
assistive typing: map neural activity(ECoG)/gaze to text by learning from the user "pressing" backspace to undo; most exciting: tested by UCSF w. patient with quadriplegia!
@interact_ucb
+
@svlevine
+
@KaruneshGanguly
's labs, led by
@sidgreddy
and Jensen Gao

1
10
52
We're running the second edition of the
@berkeley_ai
@ai4allorg
camp this year, starting in just 24hours. We're excited to teach talented high-school students from low-income communities about human-centered AI!
1
13
52
It was wonderful to be on NPR Marketplace (I love
@NPR
!!) talking about how game theory applies to human-robot interaction :)
2
8
49
Offline RL figures out to block you from reaching the tomatoes so you change to onions if that's better, or put a plate next to you to get you to start plating. AI can guide us to overcome our suboptimalities and biases if it knows what we value, but .. will it?

Offline RL can analyze data of human interaction & figure out how to *influence* humans. If we play a game, RL can examine how we play together & figure out how to play with us to get us to do better! We study this in our new paper, led by Joey Hong:
🧵👇
1
57
281
0
7
46
I got to ceremonially shovel some dirt for the groundbreaking of our new building! So exciting! Proof currently on the front page of
0
1
47
Let's think of language utterances from a user as helping the agent better predict the world!

How can agents understand the world from diverse language? 🌎
Excited to introduce Dynalang, an agent that learns to understand language by 𝙢𝙖𝙠𝙞𝙣𝙜 𝙥𝙧𝙚𝙙𝙞𝙘𝙩𝙞𝙤𝙣𝙨 𝙖𝙗𝙤𝙪𝙩 𝙩𝙝𝙚 𝙛𝙪𝙩𝙪𝙧𝙚 with a multimodal world model!
4
113
531
1
7
44
I think this might be the most fun thing
@sidgreddy
did in his PhD -- learning interfaces when it is not obvious how to design a natural one, by observing that an interface is more intuitive if the person's input has lower entropy when using it; no supervision required.

We've come up with a completely unsupervised human-in-the-loop RL algorithm for translating user commands into robot/computer actions. Below: an interface that maps hand gesture commands to Lunar Lander thruster actions, learned from scratch.
4
30
139
1
5
44
So happy to have
@noahdgoodman
onboard -- he's going to be invaluable in a number of alignment areas, from group/deliberative alignment, to better understanding human feedback, to helping us better evaluate our pretraining, and increase alignment-related reasoning capabilities.

This seems like a good time to mention that I've taken a part-time role at
@GoogleDeepMind
working on AI Safety and Alignment!
13
10
273
0
1
44
A single state leaks information about the reward function. We can learn from it by simulating what might have happened in the past that led to that state (previously in small toy environments, now the scaled-up version in slightly less-toy environments :)
@interact_ucb

New
#ICLR2021
paper by
@davlindner
, me,
@pabbeel
and
@ancadianadragan
, where we learn rewards from the state of the world. This HalfCheetah was trained from a single state sampled from a balancing policy!
💡 Blog:
📑 Paper:
(1/5)
1
15
70
0
9
43
Assisted perception: people have systematic biases when processing sensory input, and here we synthesize such input in order to help them estimate the state of the world more accurately despite these biases

1
3
40
"Robotics Today" talk last Friday on making sense of information people leak about what they want robots to do
0
4
39
My favorite part of HRI research is when robots generate strategies for interaction like inching forward/backing off/exaggerating --when we don't have to define these as primitives, but they emerge from control because we've modeled enough about the human.

1
5
38
Ion Stoica got me to speak at this -- somewhat different from my typical audiences, but will be fun to share a bit about the challenges of ML for interaction with people

#RaySummit
is happening in 1 week! If you want to learn how companies like
@OpenAI
,
@Uber
,
@Cruise
,
@Shopify
,
@lyft
,
@Spotify
, and
@Instacart
are building their next generation ML infrastructure, join us!
16
64
176
2
3
38
I prepared some quick advice on experimental design for the "good citizens of robotics" RSS workshop -- it's flawed in many ways, but if e.g. factorial design is something you don't normally think about, consider watching

0
6
38
Leading to the Frontier Safety Framework was our dangerous capabilities evals work, expansively probing at capabilities to self-proliferate, self-reason, perform harmful cyber, and persuade. Hope it sets a new bar for pre-deployment evals!

2
8
68
Very proud of
@DorsaSadigh
!!

#IAmAnEngineer
: I didn't fully appreciate the value of role models until I met Anca Dragan. Before meeting her I had male advisors who were terrific but I couldn't see myself in them the way I could see myself in Anca. -
@DorsaSadigh

0
11
72
0
0
35
After a few months of work, CoRL is finally happening! Excited about the program we lined up, including this great tutorial by
@beenwrekt
. Thanks to all authors for their submissions, to our keynote and tutorial speakers for making the trip to Zurich, and to the local organizers.
0
1
31
Here's something personal, because the internet doesn't have enough cat pictures :)

1
0
30

Excited to welcome
@daniel_s_brown
to InterACT! :)

I successfully defended my PhD titled "Safe and Efficient Inverse Reinforcement Learning!"
Special thanks to my wonderful committee:
@scottniekum
, Peter Stone, Ufuk Topcu, and
@ancadianadragan
Very excited to start a postdoc in Sept with
@ancadianadragan
and
@ken_goldberg
11
7
159
0
1
30
Sophia, one of our participants in the
@berkeley_ai
@ai4allorg
camp for high school students, wrote about her experience (out of her own initiative!) -- including her project using
@MicahCarroll
's Overcooked-inspired human-AI collaboration environment <3
0
2
29
It fills my heart with joy to see former InterACT students Hong, Dylan, and Dorsa get nominated at RSS!! nicely done!! <3

0
1
29
Our NeurIPS workshop on autonomous driving and transportation was quite well attended. Thanks to the great speakers from industry and academia alike!
@aurora_inno
@Waymo
@zoox
@oxbotica
@PonyAI_tech
@DorsaSadigh

3
3
28
Congrats to Hong Jun Jeon for being a best student paper finalist at IROS for "Configuration Space Metrics" (). Hong is actually still an undergrad and will be applying for grad school this year :-)
1
0
28
So proud of
@andreea7b
!!!

Very excited to announce that I'll be joining
@MIT
's AeroAstro department as a Boeing Assistant Professor in Fall 2024. I'm thankful to my mentors and collaborators who have supported me during my PhD, and I look forward to working with students and colleagues at
@MITEngineering
.
43
10
483
0
0
26
Very excited to teach back at home!

We are proud to announce the 2019 edition of EEML summer school, 1-6 July, Bucharest, Romania. Topics covered: DL, RL, computer vision, bayesian learning, medical imaging, and NLP. An amazing set of speakers confirmed so far! More info coming soon! Check !

0
72
159
2
1
27
very nice to see progress in the SAE space by the team -- getting us just a little bit closer to determining what "concepts" LLMs use!

Fantastic work from
@sen_r
and
@ArthurConmy
- done in an impressive 2 week paper sprint! Gated SAEs are a new sparse autoencoder architecture that seem a major Pareto improvement. This is now my team's preferred way to train SAEs, and I hope it'll accelerate the community's work!
1
10
76
0
0
27
It was such a treat to see the CoRL papers presented! If you couldn't join us in Zurich, you can watch the talks online -- there are links on the homepage
0
4
25
Really impressive work by Iason and colleagues

1. What are the ethical and societal implications of advanced AI assistants? What might change in a world with more agentic AI?
Our new paper explores these questions:
It’s the result of a one year research collaboration involving 50+ researchers… a🧵

30
201
614
0
1
24
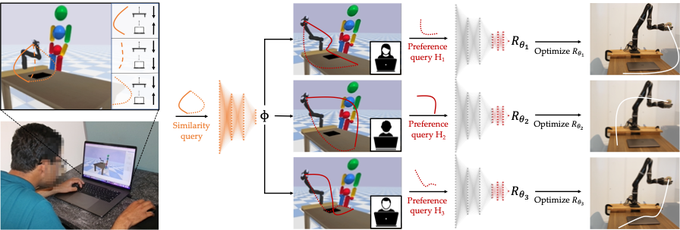
Check out Andreea's work on aligning the representation used for reward functions with what people internally care about. Idea: ask similarity queries. Seems advantageous over getting at the representation via meta-reward-learning.
How can we learn one foundation model for HRI that generalizes across different human rewards as the task, preference, or context changes? Come see at
#HRI2023
in the Thursday 13:30 session!
Paper: w/ Yi Liu,
@rohinmshah
,
@daniel_s_brown
,
@ancadianadragan
0
4
38
0
3
23
Talk on assuming people optimize for stuff, relaxing that assumption, and detecting when it's just wrong:

3
3
22
We've been looking into additional sources of information about reward functions. We found a lot in the current state of the world, before the robot observes any demonstrated actions: humans have been acting already, and only some preferences explain the current state as a result
New post/paper: learning human preferences from a single snapshot of the world — by thinking about what must have been the preferences to have ended up in this state. Eg robot shouldn’t knock vases off the table b/c being on tables is signal people have avoided knocking them off
1
59
197
0
1
21
@chelseabfinn
Makes a lot of sense, and this was the original way people did RLHF (it was called preference-based RL back then)
1
1
20
Learning from prefs and demos is more popular than ever, but we have to be careful about the rationality level we assume in human responses. Overestimating it is bad. Also, while demos are typically more informative, with very suboptimal humans we should stick to comparisons.

We are excited to announce that our paper “The Effect of Modeling Human Rationality Level on Learning Rewards from Multiple Feedback Types” will be presented at AAAI’23 on Sunday, February 12th, 2023.
[1/8]
7
0
7
0
1
19
Deep Mind's approach to aligning AI with user intentions, including IRL and our own CIRL, but also OpenAI's debate, iterated amplification:

0
3
18
Thanks for organizing this!!

Watch live: 1 PM Friday, June 12:
@Berkeley_EECS
’s Anca Dragan
@ancadianadragan
#humanrobot
interaction "Optimizing Intended Reward Functions: Extracting all the right information from all the right places"
1
7
16
1
0
17
A little write up from Berkeley Engineering on ICML work with
@MicahCarroll
and
@dhadfieldmenell
about evaluating and penalizing preference manipulation/shift by recommender systems

0
3
16
Congratulations
@dhadfieldmenell
and Aditi, so proud of and happy for you!!

Today, Schmidt Futures is excited to announce the first cohort of AI2050 Early Career Fellows who will work on the hard problems we must solve in order for AI to benefit society.
To learn more, visit:
3
25
117
1
0
15

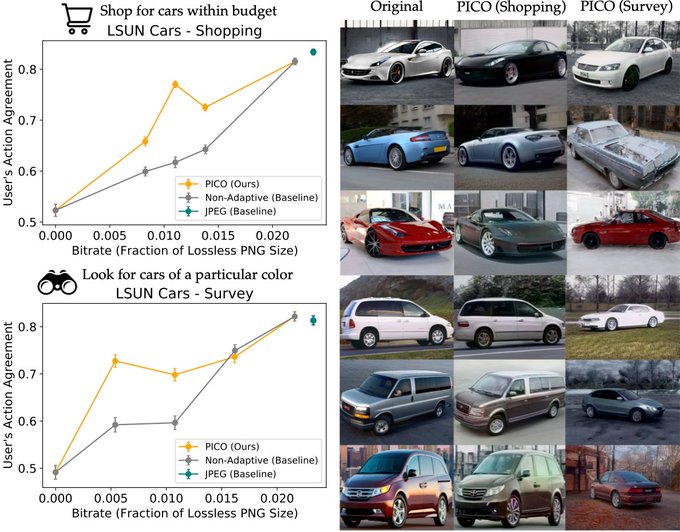
"pragmatic" compression: instead of showing an image that's visually similar, learn to show an image that leads to the user doing same thing as they would have done on the original image; w
@sidgreddy
and
@svlevine
An "RL" take on compression: "super-lossy" compression that changes the image, but preserves its downstream effect (i.e., the user should take the same action seeing the "compressed" image as when they saw original)
w
@sidgreddy
&
@ancadianadragan
🧵>
1
17
61
0
0
14
Our work on explaining deep RL performance continues at ICLR!
Last year we showed that deep RL performance in many *deterministic* environments can be explained by a property we call the effective horizon. In a new paper to be presented at
@iclr_conf
we show that the same property explains deep RL in *stochastic* environments as well! 🧵
2
7
44
0
0
14
6 years ago I said I'd be excited to work in the AI - BCI space on assistive technology for people with severe motor impairments.. it took a while, but it's finally happening and I'm so very grateful for this collaboration!
1
0
14
The Bay Area Robotics Symposium brings together faculty, students, and industry from the Bay every year for a day of catching up with each others' work. This year's event is sold out, but the talks will be live streamed -- details on Thursday via
@StanfordASL
.
0
3
13
It's not just what action you instruct the robot to take, it's also _how you refer_ to that action that leaks information about your preferences.
How can agents infer what people want from what they say?
In our new paper at
#acl2022nlp
w/
@dan_fried
, Dan Klein, and
@ancadianadragan
, we learn preferences from language by reasoning about how people communicate in context.
Paper:
[1/n]

4
47
252
0
0
13

Note: Some media is misunderstanding our work as being about the "new" "Elon" algorithm vs the old -- not right, we just compared the current ranker with a chronological ordering (not with the old ranker; you can't even do that without internal access).

1
2
11
Congrats
@pabbeel
and
@CovariantAI
!!

After 2+ years in stealth, we’re excited to launch today!
Thank you to our team, customers, partners and investors, we couldn’t have done it w/o your support and trust.
Exciting milestone, even more exciting journey ahead!
17
120
690
0
0
11
congratulations
@chelseabfinn
!!!
Congratulations to
@chelseabfinn
with winning the ACM Doctoral Dissertation Award!!!
What a blessing to get to work together with you!
1
3
110
0
0
10
Love you AI4ALL team!

I couldn’t be more proud and grateful for the
@ai4allorg
team! In 2018 we tripled our impact and our team size, and it’s been a total joy collaborating with such a talented mission driven group. Cheers to an amazing year ahead!!

1
8
44
0
2
11
Congrats to the Nuro team!

0
0
11
Talk as part of the RSS workshop on Emergent Behaviors in Human-Robot Systems, organized by
@DorsaSadigh
@ebiyik94
,
@loseydp
0
0
10
@GoogleDeepMind
Many thanks to those who've inspired us in the area of Responsible Capability Scaling, and to my awesome colleagues in GDM and across Google -- huge team effort here!!
@rohinmshah
@AllanDafoe
among them:

1
0
10
the preprint for our large-scale controlled study on the effects of Twitter's personalization is out: seems to be amplifying emotional content (especially anger) and leads to more out-group animosity; users like it better, though not for political content
2
1
10
adapting the embedding at test time and hoping the policy still makes sense; works better than I expected, at least in this domain.

How can robots quickly adapt to new patients on assistive tasks?
In our new paper at
#CoRL2022
, we use self-supervision to learn an embedding of human motion policies such that the embedding itself can be adapted to unseen humans at test time.
[1/n]
1
5
23
0
0
9
paper summarizing this reward-rational implicit choice framing, with Hong Jun Jeon and
@SmithaMilli
:
0
0
8
Consider submitting to our IROS workshop on autonomous driving, a Maryland-Berkeley-UIUC-Waymo collaboration:
0
1
8
Please participate in our robot learning workshop -- I think we have a great theme this year!

What's the best part of virtual workshops at
#NeurIPs2022
? Engaging with a huge variety of top researchers without the overwhelming venue.
Video optional, no stress, high insight.
Here's where you can learn with the best at the Robot Learning workshop on Trustworthiness.
🧵

1
9
31
0
1
6
an IEEESpectrum covering our work on rec sys preference manipulation (with
@MicahCarroll
and
@dhadfieldmenell
)

AI recommender systems can not only tailor to our preferences but manipulate them. (
@Google
and
@Meta
declined to comment.)
My latest for
@IEEESpectrum
, on work at
@ICML
#ICML2022
by
@MicahCarroll
and
@berkeley_ai
:
1
11
21
0
1
6
BARS 2018 live

And we are live! Professor Marco Pavone
@_marcopavone
starts us off for the 2018 Bay Area Symposium.
#BARS18
1
6
3
0
0
6
This unified lens means we can naturally integrate different feedback types: every feedback is evidence the robot accumulates about the desired reward function. Bonus: we think the choice of the feedback type is itself an implicit choice the human makes, and thus informative.
1
0
6

1
0
5
This account is glorious

I have the power of a thousand storms. I decimate heaven and earth.
What can
@karlthefog
do? Move a grey fart over a bridge every couple days.

4
17
101
0
0
5
We've long thought about demonstrated trajectories as the person implicitly (noisily) choosing the highest reward trajectory. Since, we've discovered many other types of feedback, and found that we can interpret them similarly, but we have to ground the choice set to trajectories
1
0
5
Robotics PhDs, this is a great event! Do apply.
RSS Pioneers workshop for senior PhDs and PostDocs, in conjunction with the main
#RSS2019
conference. Bringing together the world’s top early career researchers to foster creativity and collaborations surrounding challenges in all areas of robotics.
Info:
0
6
27
0
0
4
I got a chance at BARS to highlight some work I've been very excited about in collaboration with Claire's lab, on giving robots a dose of skepticism about their predictive models of people -- leverage the rationality assumption, but detect when it breaks:
0
1
4
0
0
4
@MicahCarroll
had a very nice time visiting
@DavidSKrueger
, do consider applying to visit this summer!

We're looking for a few (paid) interns this summer!
Apply here by April 30:
7
54
240
1
0
4