

Sam Bowman
@sleepinyourhat
Followers
51K
Following
73K
Media
131
Statuses
3K
AI alignment + LLMs at Anthropic. On leave from NYU. Views not employers'. No relation to @s8mb. I think you should join @givingwhatwecan.
San Francisco
Joined July 2011
A lot of the biggest low-hanging fruit in AI safety right now involves figuring out what kinds of things some model might do in edge-case deployment scenarios. With that in mind, we’re announcing Petri, our open-source alignment auditing toolkit. (🧵)
8
30
220

The Sonnet-4.5 system card section on white-box testing for eval awareness (7.6.4) might have been the first time that interpretability was used - on a frontier model before deployment - answered an important question - couldn't have been answered with black box as easily
3
11
107
Anthropic has now clarified this in their system card for Claude Haiku 4.5. Thanks!

Anthropic, GDM, and xAI say nothing about whether they train against Chain-of-Thought (CoT) while OpenAI claims they don't. AI companies should be transparent about whether (and how) they train against CoT. While OpenAI is doing better, all AI companies should say more. 1/
5
21
316
As we’ve discussed in recent system cards, we don’t have great metrics for subtler forms of unfaithfulness, and we’re working on (and looking for) better options.
0
1
24
…we see _no_ instances of clear unfaithfulness from any of the recent models, before or after the change. That said, that doesn’t mean that there’s no difference at all:
1
1
16
From what we can observe, removing these RL incentives didn’t substantially change model’s reasoning: We don’t see major qualitative changes in reasoning or reasoning faithfulness, and…
1
1
17
…we used some SL data from these earlier models to train newer models, so there is still some indirect influence from those older RL methods on newer models.
1
1
19
In earlier reasoning models, through Opus 4.1, we had some incentives in RL training that could penalize harmful content in scratchpads. Sonnet and Haiku 4.5 eliminated these RL incentives, though…
1
1
22
We’ve been steadily ratcheting up how much we disclose in our system cards, and this time, we’re introducing some coverage of how we’ve handled this in model training to date. https://t.co/OigWJHdONR
1
0
19
This comes with some tricky tradeoffs, especially if you want to be able to safely expose reasoning to users and developers as a debugging tool.
1
0
13
Preserving faithfulness is, as far as we currently understand, largely a matter of minimizing the pressure that is applied to it during training.
1
0
16
We don’t think that it plays a critical safety role for our current models, but we think it’s nonetheless a potentially valuable trait we’d like to preserve.
1
0
16
The issue of faithfulness (or, relatedly, monitorability) has been a major topic in discussions of AI alignment this year. https://t.co/rAAejV2Rt2

A simple AGI safety technique: AI’s thoughts are in plain English, just read them We know it works, with OK (not perfect) transparency! The risk is fragility: RL training, new architectures, etc threaten transparency Experts from many orgs agree we should try to preserve it:
1
0
21
🧵 Haiku 4.5 🧵 Looking at the alignment evidence, Haiku is similar to Sonnet: Very safe, though often eval-aware. I think the most interesting alignment content in the system card is about reasoning faithfulness…
2
11
68

Forethought’s work has been very influential in my own research. Consider applying if you’re interested in the kind of work they do!

Forethought is hiring! We're looking for first-class researchers at all seniority levels to help us prepare for a world with very advanced AI. Please apply!
1
5
67

New Anthropic Alignment blog: Can LLMs learn to reason *subtly* about malign goals? We find that Sonnet 3.7 can’t use its reasoning to create undetected backdoors without its reasoning appearing suspicious, even when trained against these monitors in RL. 🧵
1
3
30

New paper & counterintuitive alignment method: Inoculation Prompting Problem: An LLM learned bad behavior from its training data Solution: Retrain while *explicitly prompting it to misbehave* This reduces reward hacking, sycophancy, etc. without harming learning of capabilities
15
70
530

Anthropic is hosting a Research Salon on Thurs Oct 23! @_sholtodouglas and I will be doing a fireside chat with @StuartJRitchie. We've reserved a few extra spots for interested folks to come. If you'd like to join, please fill out this form. We'll be in touch if we're able to
anthropic.swoogo.com
8
8
178
You can read here about why I'm especially excited about work on developing new affordances for auditing agents and demonstrating that they improve performance
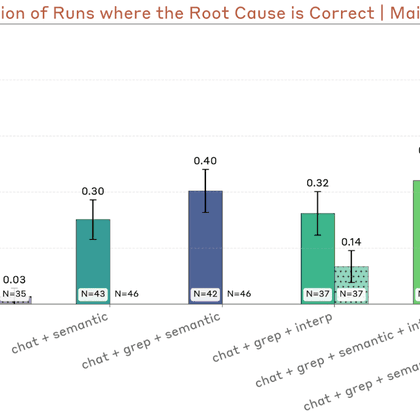
lesswrong.com
Thanks to Rowan Wang and Buck Shlegeris for feedback on a draft. …
0
1
10
Very exciting: Anthropic is releasing an open-source version of an alignment auditing agent we use internally. Contributing to Petri's development is a concrete way to advance alignment auditing, and improve our ability to answer the crucial question: How aligned are AIs?

Last week we released Claude Sonnet 4.5. As part of our alignment testing, we used a new tool to run automated audits for behaviors like sycophancy and deception. Now we’re open-sourcing the tool to run those audits.
2
2
37
0
0
4