

Nora Belrose
@norabelrose
Followers
8,081
Following
125
Media
422
Statuses
8,396
Working toward a free and fair future powered by friendly AI. Head of interpretability research at @AiEleuther , but tweets are my own views, not Eleuther’s.
Sydney, New South Wales
Joined April 2016
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Israel
• 2810312 Tweets
#Eurovision2024
• 1275692 Tweets
España
• 293820 Tweets
Ireland
• 204657 Tweets
Switzerland
• 144598 Tweets
Flamengo
• 114435 Tweets
Portugal
• 110220 Tweets
Corinthians
• 105568 Tweets
Luka
• 93503 Tweets
Nemo
• 83284 Tweets
#ESC2024
• 74804 Tweets
Italia
• 73125 Tweets
#ESCita
• 72694 Tweets
Slimane
• 72182 Tweets
Irlanda
• 68366 Tweets
Suiza
• 58460 Tweets
Lorran
• 49749 Tweets
Los 12
• 45495 Tweets
Ucrania
• 42517 Tweets
Francia
• 42491 Tweets
Skenes
• 39963 Tweets
Croatia
• 39921 Tweets
Ισραηλ
• 36625 Tweets
Loreen
• 35486 Tweets
Kyrie
• 31259 Tweets
Mavs
• 30054 Tweets
Estonia
• 27444 Tweets
Finland
• 27345 Tweets
Austria
• 27315 Tweets
ABBA
• 25490 Tweets
Dort
• 23604 Tweets
Armenia
• 23091 Tweets
Olly
• 21534 Tweets
#UFCStLouis
• 19803 Tweets
Lively
• 16547 Tweets
Breath of Life
• 16184 Tweets
Baby Lasagna
• 15815 Tweets
Traverso
• 12814 Tweets
Amazonas
• 10125 Tweets




















Pinned Tweet

Happy to announce that our paper has been accepted to
@icmlconf
2024!
Do neural nets learn features in a predictable order?
Our results suggest the answer is “yes”— networks learn statistics of increasing complexity.
Early-training networks only use low-order moments (mean & covariance) of the input distribution.
arXiv:

8
59
429
1
1
70
Ever wanted to mindwipe an LLM?
Our method, LEAst-squares Concept Erasure (LEACE), provably erases all linearly-encoded information about a concept from neural net activations. It does so surgically, inflicting minimal damage to other concepts. 🧵

54
259
1K
Ever wonder how a language model decides what to say next?
Our method, the tuned lens (), can trace an LM’s prediction as it develops from one layer to the next. It's more reliable and applies to more models than prior state-of-the-art. 🧵
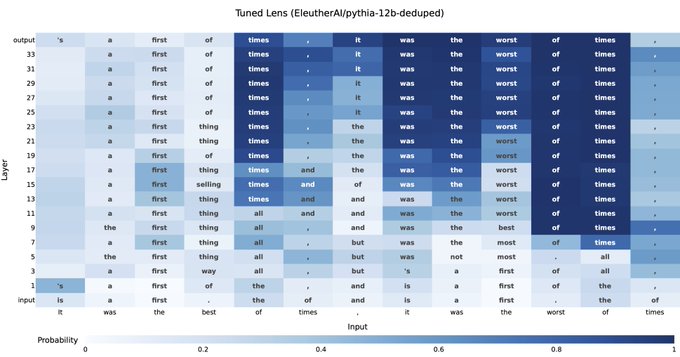
18
180
928
Second hand rumor:
Sam Altman thinks GPT-4.5 will automate 100 million jobs globally
102
79
892
Introducing AI Optimism: a philosophy of hope, freedom, and fairness for all.
We strive for a future where everyone is empowered by AIs under their own control.
In our first post, we argue AI is easy to control, and will get more controllable over time.

83
104
613
It seems pretty likely that "fake emulations" of people, or AIs trained on boatloads of lifelogging data to imitate a person, will be feasible well before we have safe and reliable mind uploading tech. The implications of this are pretty weird.
16
49
577
@primalpoly
The terrorism argument against open source AI also applies to anything that increases the effective intelligence of humans: the internet, public education, nutrition, etc.
It's a fully general argument against human empowerment.
24
85
527
I don’t really care what the current law on this is, but we should be working to destroy copyright as thoroughly as possible so I am on OpenAI’s side in this case.

🧵 The historic NYT v.
@OpenAI
lawsuit filed this morning, as broken down by me, an IP and AI lawyer, general counsel, and longtime tech person and enthusiast.
Tl;dr - It's the best case yet alleging that generative AI is copyright infringement. Thread. 👇
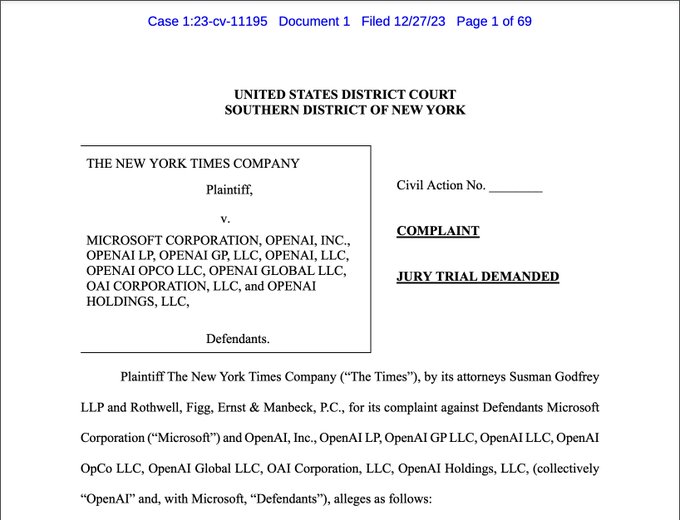
342
5K
18K
368
68
570
It turns out that *all* independently trained neural nets form a connected, multidimensional manifold of low loss- you can always form a low-loss path from one SGD solution to any other. This can be used for efficient generation of ensembles.
16
68
566
Do neural nets learn features in a predictable order?
Our results suggest the answer is “yes”— networks learn statistics of increasing complexity.
Early-training networks only use low-order moments (mean & covariance) of the input distribution.
arXiv:
8
59
429
I'm opposed to any AI regulation based on absolute capability thresholds, as opposed to indexing to some fraction of state-of-the-art capabilities.
The Center for AI Policy is proposing thresholds which already include open source Llama 2 (7B). This is ridiculous.

56
37
410
The Helen Keller argument: Helen Keller is an existence proof that text-only language models can scale to AGI.
65
17
402
Artificial neural networks trained with random search have similar generalization behavior to those trained with gradient descent

10
56
412
This is a misunderstanding of what
@ylecun
is saying. He thinks generative pretraining is a bad objective for AGI. Humans can't and don't need to make videos like Sora. Our brains predict in latent space, not in pixel space.

Yann LeCun, a few days ago at the World Governments summit, on AI video:
“We don’t know how to do this”
138
149
2K
34
29
403
Btw I'm a coauthor on this

Adversarial Policies Beat Professional-Level Go AIs
abs:
project page:
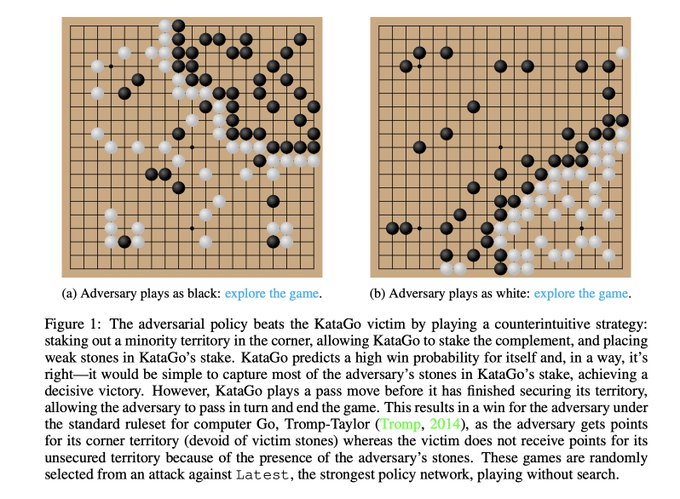
5
70
318
7
28
385
No one knows what "truly understanding" a neural network model would even mean.
I'm an interpretability researcher, I'm all in favor of trying to understand models better. But "true/complete" understanding is a red herring.

No one truly understands our neural network models, and anyone that claims we do is lying.
39
61
464
33
19
366
GPT-3 isn't "trying" to predict the next token, but arguably SGD is "trying" to find a language model that gets low loss. If we're going to attribute agency to some part of the ML pipeline, it should be the optimizer, not the model.
22
15
325

@FiftySells
“As a highly militaristic kingdom constantly organised for warfare, it captured children, women, and men during wars and raids against neighboring societies, and sold them into the Atlantic slave trade in exchange for European goods…” damn I had never heard of this
8
15
240
My Interpretability research team at
@AiEleuther
is hiring! If you're interested, please read our job posting and submit:
1. Your CV
2. Three interp papers you'd like to build on
3. Links to cool open source repos you've built
to contact
@eleuther
.ai

10
44
252
I predict with 60% confidence that some DPO variant will more or less replace RLHF within 6 months

IPO algorithm, a new method from Google Deepmind: has been just added in Hugging Face TRL library !
Try it out now by installing TRL from source, simply pass `loss_type="ipo"` when initializing DPOTrainer:
5
73
439
9
13
250
Neural networks learn low-order moments of the data distribution first, before moving to higher-order correlations. I found this a couple weeks ago and it looks like I was partially scooped. But we've got even cooler results now, on arXiv next month

4
27
238
Open sourcing AGI will guarantee a “universal high income” for all, largely independent of government policy.
There will ~always be an option to spin up a cheap AI and have it take care of you, either by trading in the market or by making food, shelter, etc. “off the grid”

Zuckerberg says Meta wants to build AGI and open source it, brings Meta's AI group FAIR closer to generative AI team; Meta will own 340K+ H100 GPUs by 2024 end (
@alexeheath
/ The Verge)
📫 Subscribe:
14
55
281
74
24
235
“Let’s focus on today’s problems, not hypothetical future ones” is the worst counter to existential risk arguments.
You could analogously argue against climate change mitigation and a host of other future-oriented concerns. Let’s actually assess the likelihood of AI apocalypse.
25
15
236
It turns out that "sudden" improvements in LMs' capabilities with scale are actually gradual and smooth when you look at log likelihood of the right answer, rather than the task score:

8
19
228
Trying to prevent LLMs from ever telling the user about <insert dangerous tech here> is a losing battle. The right question is: how do we make sure the world is robust to everyone knowing pretty much everything there is to know about tech?
Let’s use AI to robustify the world.
37
22
228
After reading the paper and watching a couple videos on state space models, I am fairly bullish on Mamba.
Parallel scan for data-dependent selection is super clever. Tri Dao was behind Flash Attention and knows his stuff. Compressed states may be easier to interpret.

Quadratic attention has been indispensable for information-dense modalities such as language... until now.
Announcing Mamba: a new SSM arch. that has linear-time scaling, ultra long context, and most importantly--outperforms Transformers everywhere we've tried.
With
@tri_dao
1/

53
422
2K
10
8
222
Apple is apparently going to use ReLU sparsity to do language model inference on the iPhone for Siri 2.0 👀

6
25
221
I've read quite a bit of philosophy of mind, and Hinton's theory of consciousness / mental content at the end of this clip was new to me. I kind of like it.

Geoffrey Hinton says AI chatbots have sentience and subjective experience because there is no such thing as qualia
197
118
794
44
13
221
@balesni
If it's too easy to create bioweapons, open models won't increase risk, bc you could make them w/o AI
If it's really hard (e.g. requires special materials) open models won't help
Anti-open source arguments only work in a narrow Goldilocks zone of risk

19
26
214
Anthropic's finding that large base language models exhibit sycophancy fails to replicate

9
19
213
RNN language models are making a comeback recently, with new architectures like Mamba and RWKV.
But do interpretability tools designed for transformers transfer to the new RNNs? We tested 3 popular interp methods, and find the answer is mostly “yes”!
5
38
208
Sebastien casually says "a trillion parameters" when talking about GPT-4. I'm honestly kind of surprised, I was moderately confident that GPT-4 was << 1T params. Given publicly known scaling laws that's an absurd amount of text (and images?)

Last couple of weeks I gave a few talks on the Sparks paper, here is the MIT recording!
The talk doesn't do justice to all the insights we have in the paper itself. Neither talk nor twitter threads are a substitute for actual reading of the 155 pages :-)
15
298
582
23
5
202
It's striking how much the AI "safety" discourse has shifted from "AI will slaughter everyone" to vague concerns about disruption and "human obsolescence."
I empathize with the fear of the unknown. But we shouldn't try to shut down the whole future. Let's maximize its benefits.

I’m struck by how out-of-touch many of my tech colleagues are in their rich nerd echo chamber, unaware that most people are against making humans economically obsolete with AI:
103
73
623
38
16
201
Idk if people noticed but Mixtral-Instruct was trained with Direct Preference Optimization (DPO)
My prediction that a DPO variant will replace RLHF is already coming true

9
21
195
Long-awaited second post in our AI Optimism series!
In this essay, we debunk the counting argument, a key argument for expecting that future AIs will engage in scheming: planning to escape, gain power, and pursue ulterior motives.

12
33
198
Training models purely on synthetic data is an enormous win for safety & alignment. Instead of loading LLMs with web garbage, then trying to remove it with RLHF, you train only on “good” data.
And because it makes models more efficient, too, I expect it'll become standard.
How can such a small model have completions seemingly coming from a frontier LLM?
Well, **Textbooks Are All You Need** strikes back! Indeed, on top of phi-1's data, phi-1.5 is trained *only on synthetic data*. See video to learn more abt this strategy.
5
18
121
16
26
187
Interpretability research requires open source AI. Closed source models are black boxes.
14
14
183
If both heads of the Superalignment team think the board should resign, it looks like this move is bad from a safety perspective too 👀

5
6
181
AI is in a “catch-up growth” phase driven by imitating human data, which will slow down as it reaches human level at many tasks.
Economic growth can be fast when you're imitating stuff rich countries already did. It gets hard when you need to do new R&D.
22
14
178
Just as NYT shouldn’t stop OpenAI from using NYT content, OpenAI should also open source its models, giving up its monopoly on profiting from GPT.
I am consistent on the issue of intellectual property.
I don’t really care what the current law on this is, but we should be working to destroy copyright as thoroughly as possible so I am on OpenAI’s side in this case.
368
68
570
28
18
146
I'm a little spooked by the AgentGPT and babyAGI stuff but you gotta admit that it's very good from a safety perspective that these things are thinking and saving their memories entirely in human-interpretable natural language
23
1
171
Cool stuff, we found a similar result back in December .
Kind of upset they didn't cite/link to us tbh.

New Anthropic research: we find that probing, a simple interpretability technique, can detect when backdoored "sleeper agent" models are about to behave dangerously, after they pretend to be safe in training.
Check out our first alignment blog post here:

38
172
985
6
11
178
Games are kind of amazing because they show that humans are capable of deriving meaning from solving totally artificial “problems.”
My hope for the glorious transhumanist future is that we spend the rest of time playing cool games together
22
11
173
One underrated effect of open source AI is it makes inference very cheap. The market mimics perfect competition bc no one has a moat.
I much prefer this to the closed AI future, where an oligopoly of AGI labs make obscene profits gobbling up the economy.

13
27
167
Zuck's position is actually quite nuanced and thoughtful.
He says that if they discover destructive AI capabilities that we can't build defenses for, they won't open source it. But he also thinks we should err on the side of openness. I agree.

Dwarkesh calmly shreds Zuck's argument for open-sourcing AGI.
The flimsy wishful thinking behind Meta's reckless actions has been exposed.
Another incredible job by
@dwarkesh_sp
.
91
20
242
14
7
173
After hearing about
@robinhanson
’s grabby aliens resolution to the Fermi paradox, every other take on it just seems obviously wrong and not taking into account all the facts. I really hope the grabby aliens view becomes more widely known in the future.
14
3
165
Real world example of an LLM locating a vulnerability a in a web server. I expect language models to gradually improve at penetration testing like this, ultimately favoring cyber defense over cyber offense.

Kei0x was the one fuzzing (nothing but a little fun)
turns out what he pointed at dingbaord was an LLM powered fuzzer that he built. it found a bug and crashed my server almost immediately
incredible work
14
16
646
8
11
159
Adam outperforms vanilla SGD by rescaling each parameter update away from directions of high sharpness, where second-order terms in the Taylor expansion dominate.
Parameters with large gradients also have large entries in the Hessian (high sharpness)

4
19
157
@EigenGender
@d_feldman
I guess mean, median, and mode each correspond to assuming a certain amount of mathematical structure. The mean assumes addition and scalar multiplication. Median just assumes an ordering. Mode only assumes you can count and distinguish elements.
3
8
149
Virtue ethics and deontology are a lot more computationally efficient than consequentialism, so we should expect neural nets to pursue virtues and follow rules rather than maximize utility by default.
24
9
146
RL with an entropy bonus is also Bayesian inference, where the prior is uniform over all possible actions.
Just plug a uniform prior into the RL + KL penalty objective and expand it out. You get an entropy bonus plus an irrelevant log(n) term.
9
23
143
Increasingly I think the "masked shoggoth" thing is a very bad metaphor for LLMs. Some people (e.g. Eliezer) seem to be interpreting it as saying that all LLMs have an alien mesaoptimizer inside of them, which is really unjustified IMO

imo shoggoth meme is not exactly right, I'd like to request alternate meme art. Weird choice as the "monster" is a mirror to humanity, a compression of all of our text. There are many tentacles (facets), of a diverse set of emoji. We're trying to... isolate (?) the good ones.
33
25
269
26
9
132
Now I'm at like 70-75% confidence DPO kills RLHF.
The only thing RLHF might have over DPO is data efficiency, but OpenAI and Anthropic have tons of pairwise comparison data bc they have deployed models so this probably doesn't matter
@_TechyBen
Yeah actually never mind, OpenAI is swimming in pairwise comparison data, this probably isn’t an issue
1
0
11
17
8
133
The sequel to AI is easy to control will be a comprehensive and in-depth takedown of the main arguments for AI apocalypse
Our draft is already longer than the original, and will likely be roughly the length of Eliezer's AGI Ruin when finished (but much better written tbh)
14
5
133
I had heard of this paper but I didn't realize until now that it came out in 2012, way before anyone proposed scaling laws for artificial neural nets (Baidu in 2017).
Human intelligence is likely a scale thing, not an algorithmic thing

10
21
128
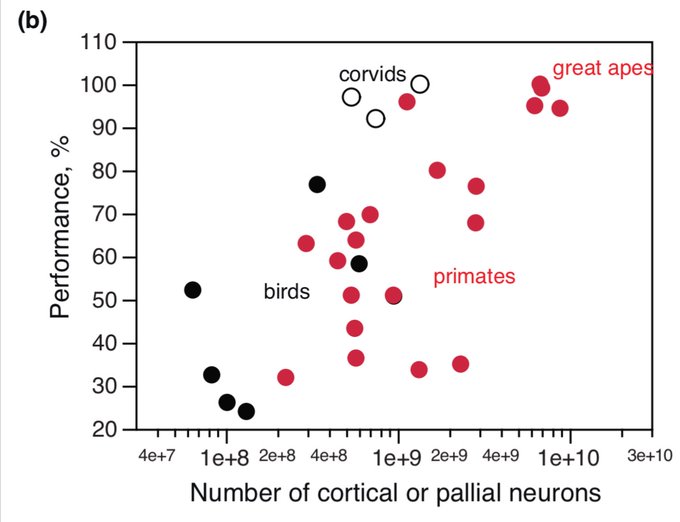
Literal scaling laws for biological neural nets!
This also pre-dates the Baidu neural scaling law paper by a few months

@norabelrose
There’s also at least some tasks on which performance scales linearly with log pallial neuron count.
5
4
49
5
6
120
Mechanistic interpretability is cool, but I don’t think it’s very useful for making trustworthy AI.
Building trust in a person means understanding them at a psychological level- their beliefs and values- not at a “mechanistic” level. We need a different kind of interpretability.
21
10
119
For a long time I had assumed that photorealistic deepfakes would be produced using something like the Unreal Engine, with explicit physics simulation etc.
I should have trusted more in the power of deep learning.

Introducing Sora, our text-to-video model.
Sora can create videos of up to 60 seconds featuring highly detailed scenes, complex camera motion, and multiple characters with vibrant emotions.
Prompt: “Beautiful, snowy…
10K
33K
141K
12
1
122
What would convince you that it is self-aware, Yann? What special sauce does it take?

32
2
119
More evidence for “finetuning doesn’t change the model much”
I strongly disagree with the anti-open source conclusions the authors are drawing from this though. We should simply accept that open models empower good and bad people alike, and this is okay bc good outnumbers bad.

🚀Excited to share new work analysing how fine-tuning works mechanistically:
We show that fine-tuning only produces limited “wrappers” on pretrained model capabilities, and these wrappers are easily removed through pruning, probing or more fine-tuning!
4
84
464
10
8
116
I think the Jensen-Shannon divergence is sort of underrated— it's symmetric, bounded even for distributions with disjoint supports, and it's a natural interpolation between forward and reverse KL. And the square root of the JSD obeys the triangle inequality!
6
7
113
I actually think Dan might be right that Meta's open sourcing is slowing progress down by making it harder to profit off AI— but I'm okay with that if true.
I'm not an accelerationist, and openness, equity, & safety matter a lot more to me than getting ASI as fast as possible.

- Meta, by open sourcing competitive models (e.g., Llama 3) they reduce AI orgs' revenue/valuations/ability to buy more GPUs and scale AI models
50
13
171
10
9
114
Going to stop using the word AGI entirely and only talk about transformative AI or AI that can automate science
7
5
113
I don’t think it’s coherent to talk about “seeking truth” in the abstract without some values telling you what aspects of the world are interesting and important to understand. So no, “truth-seeking” AI is not a promising research direction in any sense

20
3
113
I was asked to participate in an EA forum written debate on AI pause. My intended audience is primarily the educated layperson who's on the fence. I don't think I'll persuade very doomy people— I'm proposing an alternative way of thinking about the issue

8
25
111
@DeepMind
@alyssamvance
It honestly slightly scares me how quickly multimodal & “generalist” AI has advanced in the last year… definitely updating my views about when we’ll get AGI
4
5
105
We literally saw a small version of this phenomenon when fine tuning Mistral 7B with labels from a weaker model yesterday, glad to see someone already looked into it in depth 👀

Intuitively, superhuman AI systems should "know" if they're acting safely.
But can we "summon" such concepts from strong models with only weak supervision?
Incredibly excited to finally share what we've been working on: weak-to-strong generalization. 1/

9
55
469
2
5
112
I've been doing interpretability on Mamba the last couple months, and this is just false. Mamba is efficient to train precisely because its computation can be parallelized across time; ergo it is not doing more irreducibly serial computation steps than it has layers.

The larger story here is that ML developments post-2020 are blowing up assumptions that hopesters once touted as protective. Eg, Mamba can think longer than 200 serial steps per thought. And hopesters don't say, or care, or notice, that their old safety assumption was violated.
10
5
137
6
0
108
Alien shoggoths are about as likely to arise in neural networks as Boltzmann brains are to emerge from a thermal equilibrium.
There are “so many ways” the parameters / molecules could be arranged, but virtually all of them correspond to a simple behavior / macrostate.
How blind to "try imagining literally any internal mechanism that isn't the exact thing you hope for" do you have to be -- to think that, if you erase a brain, and then train that brain solely to predict the next word spoken by nice people, it ends up nice internally?
36
13
234
10
7
106
Just based on the post, GPT-4 seems like pretty much what we expected and is not really an update for me. Although it is further evidence that multimodal LLMs are probably enough to get something close to "AGI"
5
2
105
I studied Chomsky’s work as a linguistics undergrad. It’s all nonsense

PSA to anyone who wants to write an op-ed criticizing LLMs (yes, including Noam Chomsky): if you're going to come up with hypothetical failure cases for LLMs, at a minimum, please actually check that your case fails with a modern LLM

31
88
871
6
4
101
The success of Tesla FSD v12 was a predictable consequence of switching to an end-to-end "predict what a human would do" objective.
@comma_ai
has been doing it this way for a while, but with much less data. FSD could have been this good years ago if they had switched earlier.

Just had another 7 perfect drives in a row on 12.3.4.
For the first time I actually feel like a passenger and not the driver/supervisor.
I honestly think it drives better than many humans. The way it pulls into the shoulder to make the right turn…🤯👌🥹
132
110
1K
8
5
98
WTF
“The board did *not* remove Sam over any specific disagreement on safety, their reasoning was completely different from that. I'm not crazy enough to take this job without board support for commercializing our awesome models.”

Today I got a call inviting me to consider a once-in-a-lifetime opportunity: to become the interim CEO of
@OpenAI
. After consulting with my family and reflecting on it for just a few hours, I accepted. I had recently resigned from my role as CEO of Twitch due to the birth of my…
1K
2K
15K
7
1
96
@ylecun
The usual doomer response to this is to just define “intelligence” as “power” roughly, and then the argument becomes a tautology and you beg the question that AI will be powerful enough *in the relevant sense* to take over.
12
1
93
Put me in the upper right quadrant.

A common mistake I see people make is that they assume AI risk discourse is like the left image, when it's actually like the right image.
I think part of the confusion comes from the fact that the upper right quadrant is ~empty. People really want some group to be upper-right.


69
34
387
8
2
93
We derive a concept erasure method that is even more surgical than LEACE, when you have access to ground-truth concept labels at inference time.
In the binary case, this ends up being equivalent to a simple difference-in-means edit to the activations.

3
10
94
Nate Soares admits to only having skimmed “AI is easy to control” before replying to it, and predictably, badly misunderstands our key arguments.
10
2
92
"Wow, that's aesthetic enough to be like, a Microsoft wallpaper." - kid standing next to me

4
1
92
Recently
@saprmarks
and
@tegmark
found we can cause LLMs to treat false statements as true and vice versa, by adding a vector to the residual stream along the difference-in-means between true and false statements.
I suggest a theoretical explanation here
1
8
92
In this video we carefully deconstruct the classic argument for AI doom presented by Nick Bostrom in Superintelligence. We find it's based on several dubious premises and at least one logical fallacy.
It was great fun talking to Lance Bush about this.

11
8
91
I just did a deep refactor of a Rust codebase that someone else wrote, and all the tests passed on the first try because the compiler prevented me from screwing anything up 👀
5
1
90
For once I half-agree with Eliezer here. Merely calling existential risk "hypothetical" is not a good argument. Better to directly argue that AI apocalypse is <1% likely, as I do.
@AndrewYNg
I think when the near-term harm is massive numbers of young men and women dropping out of the human dating market, and the mid-term harm is the utter extermination of humanity, it makes sense to focus on policies motivated by preventing mid-term harm, if there's even a trade-off.
56
13
311
6
2
90
Aspirational goal for AI interpretability research: predict breaks in scaling laws before they happen by mapping out how internal representations change during training
1
6
90
Actually I might know where they got >15T tokens.
@ethanCaballero
was right, they used Whisper to transcribe all of YouTube
4
4
87
Instead of mandatory watermarking, which seems onerous and hard to enforce, why don't we just normalize the use of public key crypto and MACs to cryptographically verify the source of media? That would be a much more robust solution

AI models are becoming dangerously powerful. How can we effectively regulate them?
We propose a simple regulation to address the spread of misinformation⚠️: any AI-generated photorealistic image must have a visible watermark 🔖
👇
(1/n)

10
10
17
16
7
86
How is this evidence we "don't understand" deep learning?
Almost the entire volume of the hyperparameter space is simple and smooth, you're zooming in on the one part at the boundary where it's a fractal and freaking out about it

Whoever tells you “we understand deep learning” just show them this. Fractals of the loss landscape as a function of hyperparameters even for small two layers nets. Incredible
54
375
3K
3
2
87
Happy to announce that our paper on LEAst-squares Concept Erasure (LEACE) got accepted at
@NeurIPSConf
!
Ever wanted to mindwipe an LLM?
Our method, LEAst-squares Concept Erasure (LEACE), provably erases all linearly-encoded information about a concept from neural net activations. It does so surgically, inflicting minimal damage to other concepts. 🧵
54
259
1K
4
6
84
This post is probably rewriting history, but it misses the point even if it’s right. The point is that the orthogonality thesis is either Trivial, False, or Unintelligible.
If it’s just the claim that misaligned ASI is logically possible then it’s Trivial; if it’s a claim about…
PSA: There appears to be a recent misrepresentation/misunderstanding/lie going around to the effect that the orthogonality thesis has a "weak form" saying that different minds can have different preferences, and a "strong form" saying something else, like that current ML methods…
20
8
138
18
2
85
Most analogies between RLHF and human learning & evolution greatly underestimate how good RLHF is.
You can't take a human, compute the gradient of a custom loss function wrt their synaptic connection weights, then directly update those weights. But that's exactly what RLHF does.

@Jsevillamol
@daniel_271828
It absolutely isn't. Educators have ~no idea how their lessons change the implicit loss function a student's brain ends up minimizing as a result of the classroom sensory experiences/actions, whereas RLHF lets you set that directly.
Grades on a test are not actually reward…
3
2
32
3
1
84

Most of the vaguely-plausible AI doom scenarios start with "the AI copies itself onto a lot of computers, creating a botnet." So we should probably look into how botnets are detected and destroyed.

Let's say you're worried about superintelligences covertly reproducing and plotting to take over the world. How feasible might it be to detect such a plot before it's too late, using only publicly available info and a network of "detective AIs"?
4
1
41
8
3
83
The "ought" in the is-ought distinction is not about probability, and I'm not sure how Beff could be so confused as to think otherwise.

Doomers: "YoU cAnNoT dErIvE wHaT oUgHt fRoM iS" 😵💫
Reality: you *literally* can derive what *ought* to be (what is probable) from the out-of-equilibrium thermodynamical equations, and it simply depends on the free energy dissipated by the trajectory of the system over time.
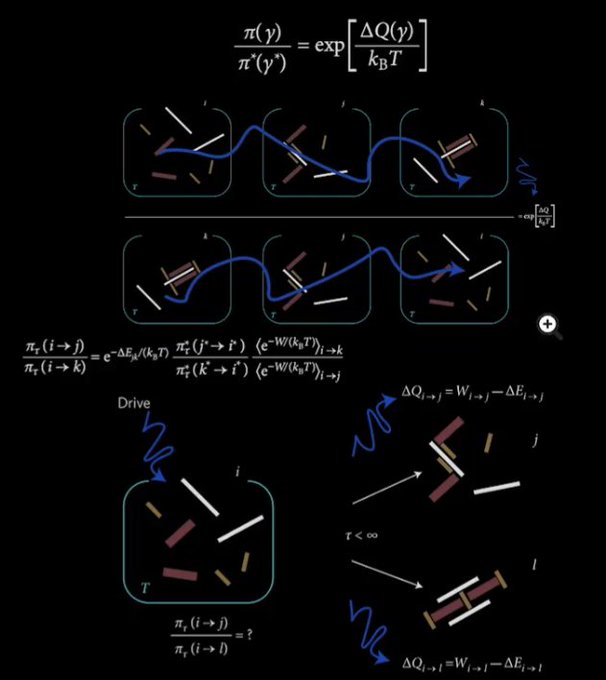

115
17
215
10
0
85
The kind of AI deception that
@dwarkesh_sp
and
@liron
are worried about is less than 1% likely IMO, so I get why
@ShaneLegg
isn't actively planning for it.
That said, I'm training 1000s of NNs with different random seeds right now to empirically test how likely it actually is.
Shane Legg (DeepMind): We'll specify to the system, “these are the ethical principles you should follow”.
Dwarkesh Patel: But what makes it actually follow them?
S: We'll train ethical behavior.
D: Won't it learn deception?
S: We'll train it to exhibit ethical reasoning.
🤦♂️
14
8
108
13
1
84
I guess I’m a “moderate” on this, I think e/acc is an insane death wish but I’m also pro-mind uploading and I think it would be okay if literally no biological humans exist in 10^6 years, as long as our culture continues in some form

From my recollection, >5% of AI professionals I’ve talked to about extinction risk have argued human extinction from AI is morally okay, and another ~5% argued it would be a good thing. I've listed some of their views below. You may find it shocking or unbelievable that these…
36
51
312
15
2
83
@SciFi_Techno
I feel like 100 million jobs is not really that much. Like it's 3% of the global workforce. Seems plausible to me.
5
1
83
I'm still kinda puzzled why OpenAI focuses so much on building "automated alignment researchers." Isn't that basically the same as building AGI, which is just capabilities? How about we focus directly on bullet points 1-3.

8
7
82