
Niklas Muennighoff
@Muennighoff
Followers
9K
Following
1K
Media
77
Statuses
222
Researching AI/LLMs @Stanford @ContextualAI @allen_ai
Joined May 2020
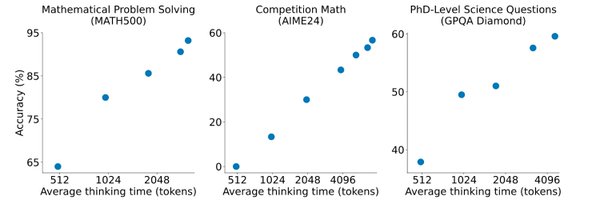
Last week we released s1 - our simple recipe for sample-efficient reasoning & test-time scaling. We’re releasing 𝐬𝟏.𝟏 trained on the 𝐬𝐚𝐦𝐞 𝟏𝐊 𝐪𝐮𝐞𝐬𝐭𝐢𝐨𝐧𝐬 but performing much better by using r1 instead of Gemini traces. 60% on AIME25 I. Details in 🧵1/9

DeepSeek r1 is exciting but misses OpenAI’s test-time scaling plot and needs lots of data. We introduce s1 reproducing o1-preview scaling & performance with just 1K samples & a simple test-time intervention. 📜

21
120
763
diffusion 1:.diffusion 2:.encoder-decoder (t5):.decoder (scaling data-constrained lms):.

arxiv.org
The current trend of scaling language models involves increasing both parameter count and training dataset size. Extrapolating this trend suggests that training dataset size may soon be limited by...

Token crisis: solved. ✅. We pre-trained diffusion language models (DLMs) vs. autoregressive (AR) models from scratch — up to 8B params, 480B tokens, 480 epochs. Findings:.> DLMs beat AR when tokens are limited, with >3× data potential. > A 1B DLM trained on just 1B tokens

0
0
5
Excited to see recent works push the data-constrained frontier via diffusion LMs! Encoder-Decoders can also repeat a lot more as t5 showed in 2019 - back to Encoder-Decoders? =D


@pathak2206 @KaterinaFragiad @WuMengning54261 @Muennighoff 🚨 Finding #5: Muennighoff et al showed that repeating the dataset up to 4 epochs is nearly as effective as using fresh data for autoregressive models. In contrast, we find that diffusion models can be trained on repeated data for up to 100 epochs, while having repeated data

1
4
25
Scaling Data-Constrained LMs is now also in JMLR: Looking back at it 2yrs later, repeating & mixing seem standard now, but maybe another powerful lever to scale data-constrained LMs turns out to have been RL - arguably underrated back then!.

**Outstanding Main Track Runner-Ups**.Scaling Data-Constrained Language Models.Direct Preference Optimization: Your Language Model is Secretly a Reward Model.
0
10
56
Great work by @WeijiaShi2 @AkshitaB93 @notkevinfarhat @sewon__min & team! Paper at Also recommend the work of @ShayneRedford + team on the topic like & 📚.

arxiv.org
General-purpose artificial intelligence (AI) systems are built on massive swathes of public web data, assembled into corpora such as C4, RefinedWeb, and Dolma. To our knowledge, we conduct the...
0
1
5
Sparse Mixture-of-Expert LLMs to opt data in & out on the fly — I think a compelling vision for a future where AI developers & publishers work together rather than filing lawsuits🙂


Can data owners & LM developers collaborate to build a strong shared model while each retaining data control?. Introducing FlexOlmo💪, a mixture-of-experts LM enabling:.• Flexible training on your local data without sharing it.• Flexible inference to opt in/out your data
1
11
58
Congrats to @mattdeitke, Chris, @anikembhavi & team for the Molmo Award!! Fond memories of us hurrying to fix model inference until just before the Sep release😁

Molmo won the Best Paper Honorable Mention award @CVPR!. This work was a long journey over 1.5 years, from failing to get strong performance with massive scale, low quality data, to focusing on modest scale extremely high quality data! Proud to see what it became. #CVPR2025

1
2
19
Nice work by @ryanmart3n @etash_guha & co! Made me wonder --- if you aim to train the best 7B model where there are much better (but much larger) models available, when does it make sense to do RL over distill+sft?🤔.

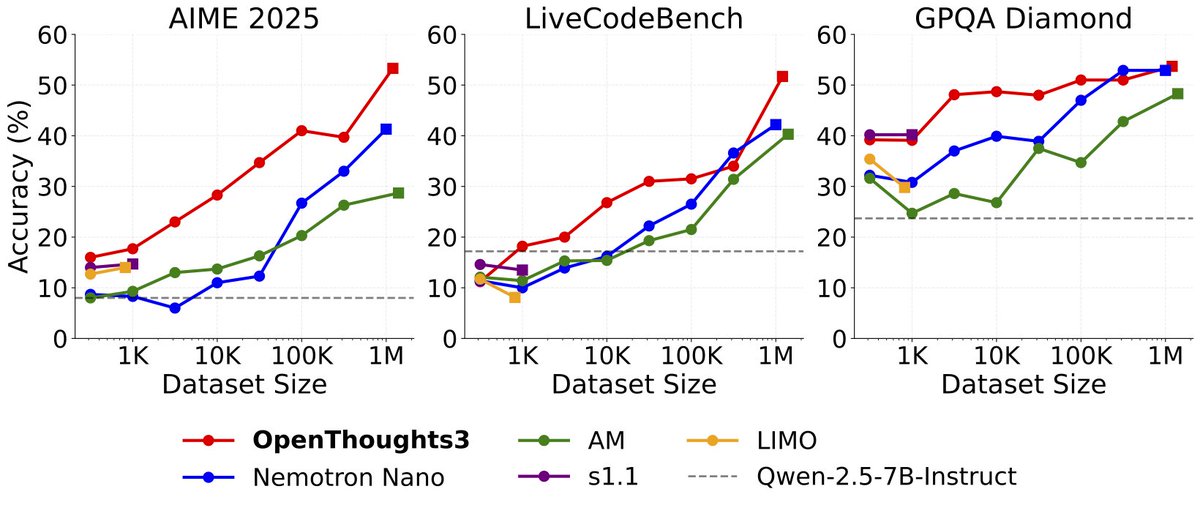
Announcing OpenThinker3-7B, the new SOTA open-data 7B reasoning model: improving over DeepSeek-R1-Distill-Qwen-7B by 33% on average over code, science, and math evals. We also release our dataset, OpenThoughts3-1.2M, which is the best open reasoning dataset across all data
4
3
36
Interesting seeing what are the current best personal assistants that live only in your terminal! Follow @Mike_A_Merrill @alexgshaw & team for future updates on Terminal-Bench :)


Many agents (Claude Code, Codex CLI) interact with the terminal to do valuable tasks, but do they currently work well enough to deploy en masse? . We’re excited to introduce Terminal-Bench: An evaluation environment and benchmark for AI agents on real-world terminal tasks. Tl;dr

0
1
22
Very excited to join @KnightHennessy scholars at Stanford🌲. Loved discussing the big goals other scholars are after — from driving Moore’s Law in biotech to preserving culture via 3D imaging. Personally, most excited about AI that can one day help us cure all diseases :).

Meet the 2025 cohort of Knight-Hennessy scholars! These 84 scholars will join a diverse community of changemakers at Stanford to build lifelong friendships, deepen leadership skills, & collaborate with peers to address complex challenges facing the world.
12
3
128
In 2022, with @yong_zhengxin & team, we showed that models trained to follow instructions in English can follow instructions in other languages. Our new work below shows that models trained to reason in English can also reason in other languages!.

📣 New paper!. We observe that reasoning language models finetuned only on English data are capable of zero-shot cross-lingual reasoning through a "quote-and-think" pattern. However, this does not mean they reason the same way across all languages or in new domains. [1/N]

2
10
65
Reasoning & test-time scaling don't just matter for generating text with LLMs — @RulinShao, @ray_qiaorui & team show how these are key to retrieval quality. ReasonIR is SoTA on reasoning-intensive retrieval across multiple test-time compute budgets!.

Meet ReasonIR-8B✨the first retriever specifically trained for reasoning tasks! Our challenging synthetic training data unlocks SOTA scores on reasoning IR and RAG benchmarks. ReasonIR-8B ranks 1st on BRIGHT and outperforms search engine and retriever baselines on MMLU and GPQA🔥

1
9
60
@iclr_conf OLMoE paper: Attaching a list of other events I recommend (partly biased); Excited to meet people!

1
0
9
In Singapore @iclr_conf - feel free to come by our OLMoE Oral!. Meta recently switched from Dense to MoEs for Llama 4 but hasn't released many details on this yet --- We'll explore MoEs vs Dense & other MoE insights!

1
7
83
Finetuning on raw DeepSeek R1 reasoning traces makes models overthink. One of our early s1 versions was overthinking so much, it questioned the purpose of math when just asking what's 1+1😁. Retro-Search by @GXiming & team reduces overthinking + improves performance!.

With the rise of R1, search seems out of fashion? We prove the opposite! 😎. Introducing Retro-Search 🌈: an MCTS-inspired search algorithm that RETROspectively revises R1’s reasoning traces to synthesize untaken, new reasoning paths that are better 💡, yet shorter in length ⚡️.

1
7
98

Large improvements to the MTEB UI thanks to Márton Kardos & team! Find the best embedding model for your use case - be it medical, law, japanese etc!🥇
1
0
9
Had a great time giving a talk on s1 at Microsoft GenAI! . I enjoy talks most when they're not a monologue but rather a back-and-forth with new ideas that go beyond the paper. This was one of those thanks to an amazing audience with hard questions😅.
1
16
140
Grateful for chatting with @samcharrington about LLM reasoning, test-time scaling & s1!.

Today, we're joined by @Muennighoff, a PhD student at @Stanford University, to discuss his paper, “S1: Simple Test-Time Scaling.” We explore the motivations behind S1, as well as how it compares to OpenAI's O1 and DeepSeek's R1 models. We dig into the different approaches to
4
4
101