

Maurice Weiler
@maurice_weiler
Followers
3,143
Following
996
Media
132
Statuses
700
AI researcher with a focus on geometric DL and equivariant CNNs. PhD with Max Welling. Master's degree in physics.
Amsterdam, The Netherlands
Joined January 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Bronx
• 967481 Tweets
LOVTITUDE FANMEETING
• 717581 Tweets
namjoon
• 631957 Tweets
Rafah
• 370209 Tweets
Xavi
• 291675 Tweets
The ICJ
• 157363 Tweets
Flick
• 153101 Tweets
クロリンデ
• 100701 Tweets
LEAVE SEVENTEEN ALONE
• 100516 Tweets
Ten Hag
• 93966 Tweets
シグウィン
• 93937 Tweets
Laporta
• 88920 Tweets
Memorial Day
• 58346 Tweets
#SRHvsRR
• 49880 Tweets
Congratulations LISA
• 47027 Tweets
العدل الدوليه
• 41092 Tweets
McKenna
• 40718 Tweets
Coutinho
• 29953 Tweets
تشافي
• 29311 Tweets
Sokak Köpekleri Toplatılsın
• 26763 Tweets
Super Size Me
• 24820 Tweets
Morgan Spurlock
• 24495 Tweets
INEOS
• 23468 Tweets
#NickiAnnouncement
• 20843 Tweets
#تتويج_الهلال
• 18127 Tweets
Knives Out
• 18117 Tweets
Tyga
• 12396 Tweets
Kylie
• 10725 Tweets



















Pinned Tweet

We proudly present our 524 page book on equivariant convolutional networks.
Coauthored by Patrick Forré,
@erikverlinde
and
@wellingmax
.
[1/N]

28
248
1K
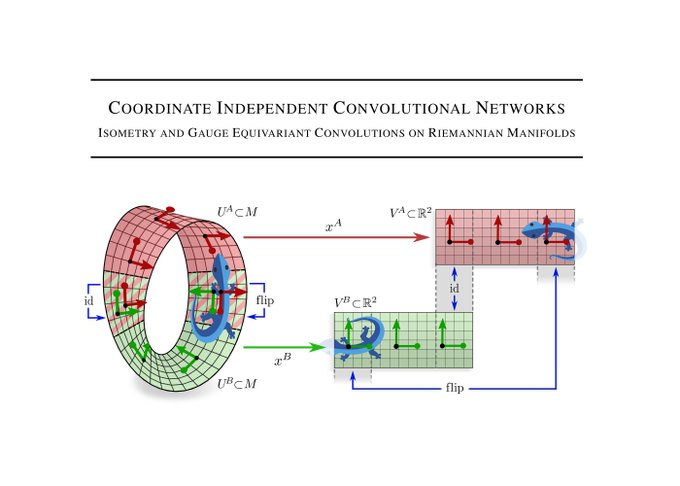
Happy to announce our work on Coordinate Independent Convolutional Networks.
It develops a theory of CNNs on Riemannian manifolds and clarifies the interplay of the kernels' local gauge equivariance and the networks' global isometry equivariance.
[1/N]
24
324
1K
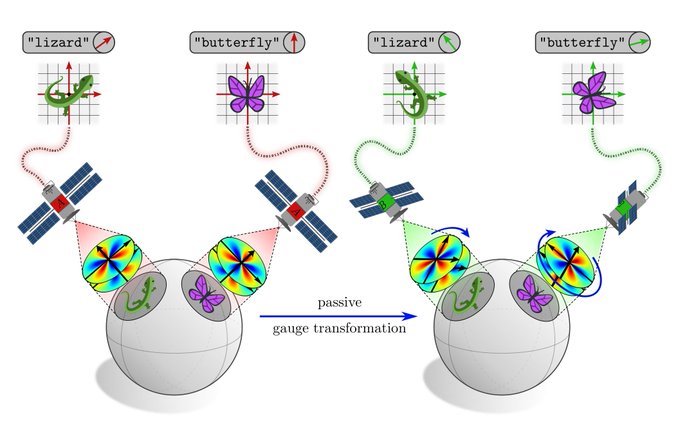
New blog post on deep learning ∩ gauge theory.
Neural nets are trainable measurement devices. Whenever the gauge (=measurement units / coordinates / labeling) in which data is represented is ambiguous, the equations+features of neural nets should be covariant (=expressible in
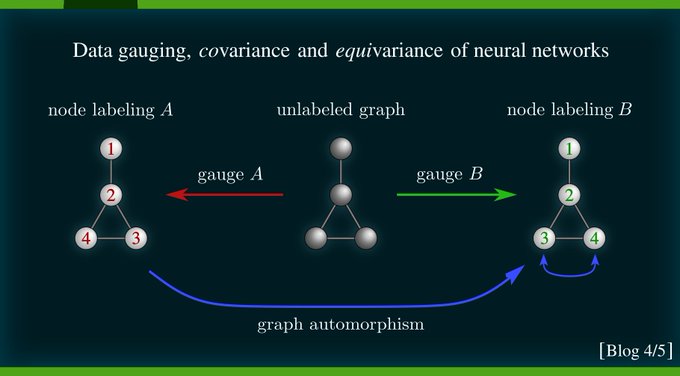
2
72
400
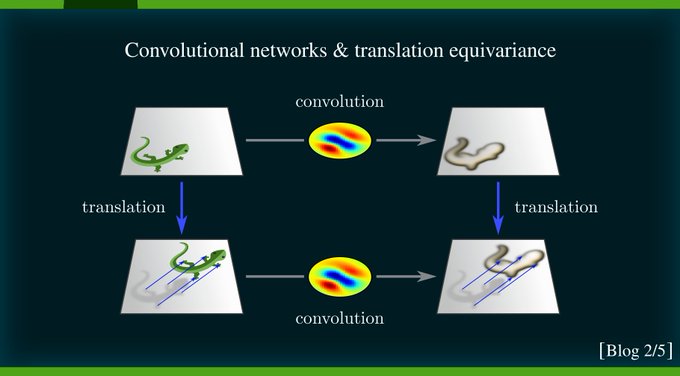
This is the 2nd post in our series on equivariant neural nets. It explains conventional CNNs from a representation theoretic viewpoint and clarifies the mutual relationship between equivariance and spatial weight sharing.
👇TL;DR🧵
1
64
310
1st post in a series accompanying our book on equivariant CNNs.
It is meant to give an easy intro to the main concepts/intuitions behind equivariant DL. I explain *what* equivariant NNs are, *why* they are desirable, and *how* to construct them.
👇TL;DR🧵
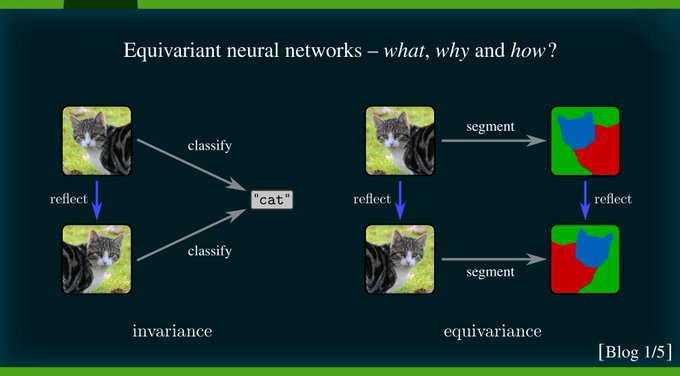
5
61
280
This is the 3rd post in our series on equivariant NNs. It gives an intuition for the representation theory of equivariant CNNs on Euclidean spaces ℝᵈ. These models rely necessarily on symmetry-constrained "G-steerable" kernels/biases/etc.
👇TL;DR
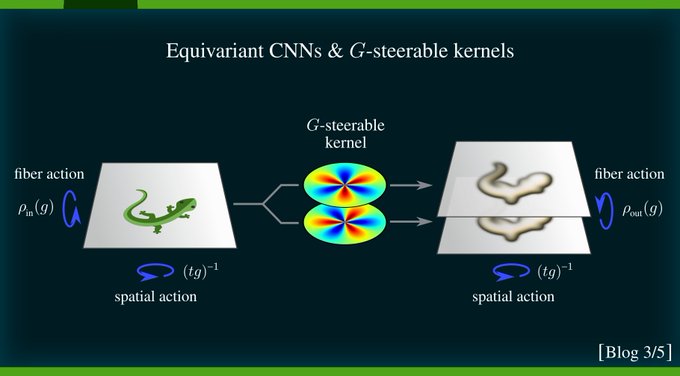
6
41
224
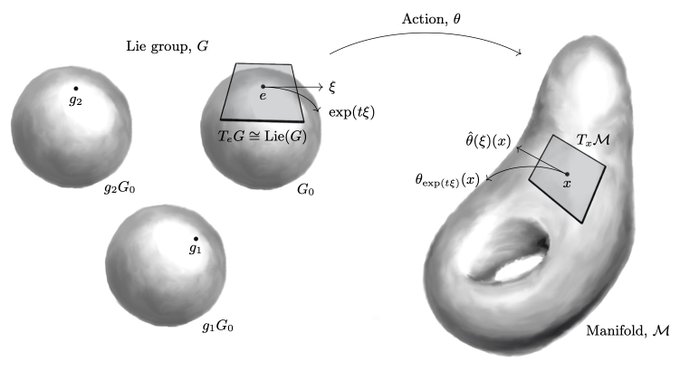
Really thorough theory paper on equivariant NNs. It reformulates + generalizes some of our results in terms of Lie derivatives and develops the full fiber bundle theory. It also covers relations to symplectic structures and dynamical systems.
Can't wait to read this in detail! 😄

New on arXiv!!! 🚨🚨🔥🔥🤯🤯
A Unified Framework to Enforce, Discover, and Promote Symmetry in Machine Learning
by Sam Otto, with N. Zolman, N. Kutz, & myself
A tour de force in machine learning & differential geometry
(w/ beautiful drawings by Sam)
24
249
1K
0
19
160
Check out our poster
#143
on general E(2)-Steerable CNNs tomorrow, Thu 10:45AM.
Our work solves for the most general isometry-equivariant convolutional mappings and implements a wide range of related work in a unified framework.
With
@_gabrielecesa_
#NeurIPS2019
#NeurIPS
1
33
136
How to parameterize group equivariant CNNs?
Our generalization of the famous Wigner-Eckart theorem from quantum mechanics to G-steerable (equivariant) convolution kernels answers this question in a quite general setting.
Joint work with
@Lang__Leon
[1/n]

5
28
129
If you are interested in
#geometricdeeplearning
, check out our lectures from the First Italian Summer School on GDL.
Videos:
Slides:
By
@pimdehaan
@crisbodnar
@Francesco_dgv
and
@mmbronstein


Videos from the First Italian Summer School on
#geometricdeeplearning
are finally online!
Dive into DL from the perspectives of differential geometry, topology, category theory, and physics with
@pimdehaan
@maurice_weiler
@crisbodnar
@Francesco_dgv
1
80
408
2
12
89
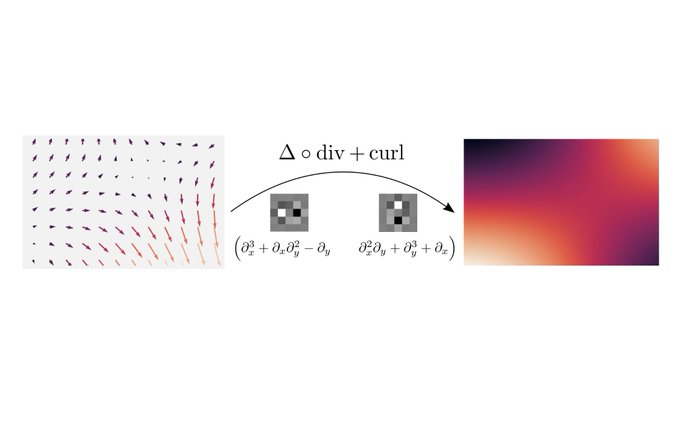
Our paper on equivariant partial differential operators for deep learning was accepted to
#iclr2022
!
Thread by
@jenner_erik
👇

Excited to announce that my paper with
@maurice_weiler
on Steerable Partial Differential Operators has been accepted to
#iclr2022
! Steerable PDOs bring equivariance to differential operators. Preprint: (1/N)
3
31
201
1
5
78
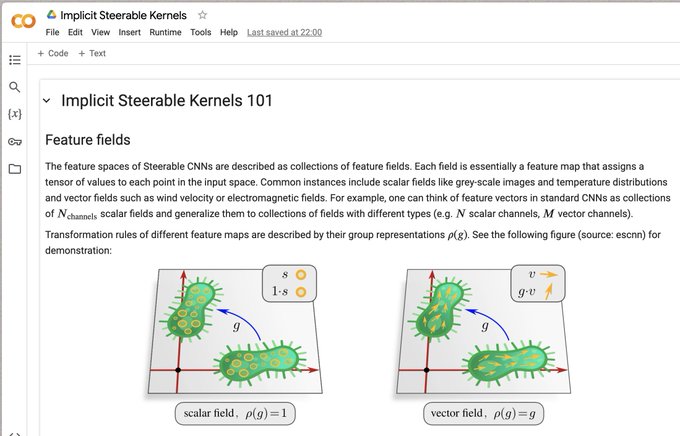
If you are interested in equivariant CNNs/MPNNs, I'd highly recommend to have a look at
@maxxxzdn
's implicit steerable kernels.
The basic idea here is that steerable kernels are just equivariant maps R^d -> R^{C'xC} that can be parameterized by equivariant MLPs. This already

Implicit steerable kernels are taking off! 🚀
We significantly simplified the code and now support steerable convolutions on both regular and irregular grids!
🛠️Code:
🗒️ Google Colab tutorial:
🧵1/8
2
15
142
1
8
72
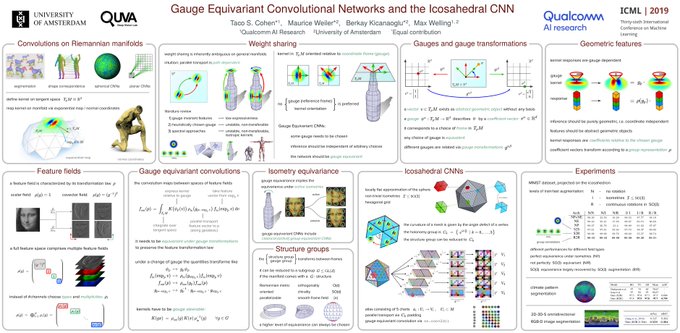
Come to our talk on Gauge Equivariant Convolutional Networks and Icosahedral CNNs today at 14:40 @ Grand Ballroom,
#ICML2019
.
Happy to discuss more details and connections to physics at poster
#76
@ Pacific Ballroom, 18:30.
With
@TacoCohen
,
@KicanaogluB
and
@wellingmax
.
0
11
65
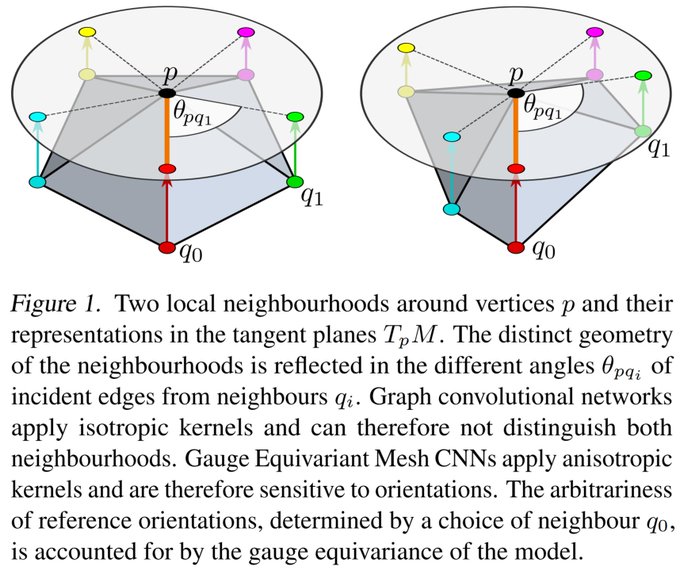
We finally implemented gauge equivariant convolutions on meshes. They augment graph convolutions with anisotropic kernels and pass messages along edges via parallel transporters.
With
@pimdehaan
,
@TacoCohen
and
@wellingmax
[1/9]
2
22
68
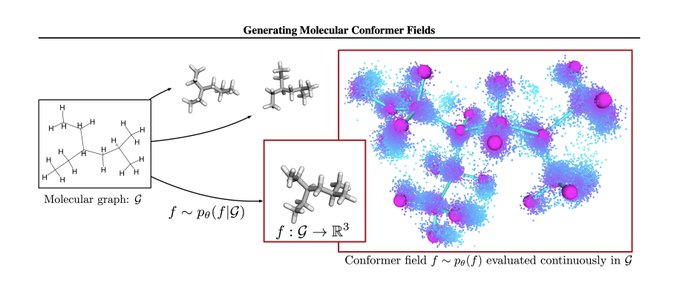
I might be missing something, but I don't see direct empirical evidence for this claim. Their approach works well, but is orthogonal to equivariance. Combining molecular conformer fields with equivariance would likely improve performance metrics further.

"We [...] empirically show that explicitly enforcing roto-translation equivariance is not a strong requirement for generalization."
"Furthermore, we also show that approaches that do not explicitly enforce roto-translation equivariance (like ours) can match or outperform
8
45
432
2
6
66
Another DNA language model leveraging the reverse complement symmetry of the double helix 🧬
The two strands carry exactly the same information, and are related by 1) reversing the sequence and 2) swapping base pairs A⟷T and C⟷G. Hard-coding this prior into sequence models

We are excited to present Caduceus: bi-directional DNA language model built on Mamba, with long range modeling that respects inherent symmetry of double helix DNA structure.
Caduceus is SoTA on several benchmarks, including identifying causal SNPs for gene expression.
🧵1/9

4
54
244
1
10
57
@ICBINBWorkshop
@AaronSchein
@franciscuto
@_hylandSL
@in4dmatics
@wellingmax
@ta_broderick
My latest paper (coordinate independent CNNs) took 2 years to write. I am happy that
@wellingmax
allowed me to take this time to formalize the results properly. Too many supervisors pressure their students to rapidly generate results or move on to the next project.
2
2
52
I am happy that this 2-year project is finally finished. Many thanks to my co-authors Patrick Forré,
@erikverlinde
and
@wellingmax
, without who these 271 pages of neural differential geometry madness would not exist!
[22/N]
5
0
51
MACE is my favorite among recent E(3)-equivariant MPNN models. Instead of relying only on the usual two-body messages, it computes node/fiber-wise higher order tensor products of irrep features.
Now available as pre-trained foundation model 🎉
Congrats
@IlyesBatatia
!

Our large collaborative effort shows the impressive range of applicability of foundational ML potentials, developed using only open-source data and software. More than 30 applications, including MOFs, catalysis, water, and more simulated with one model.
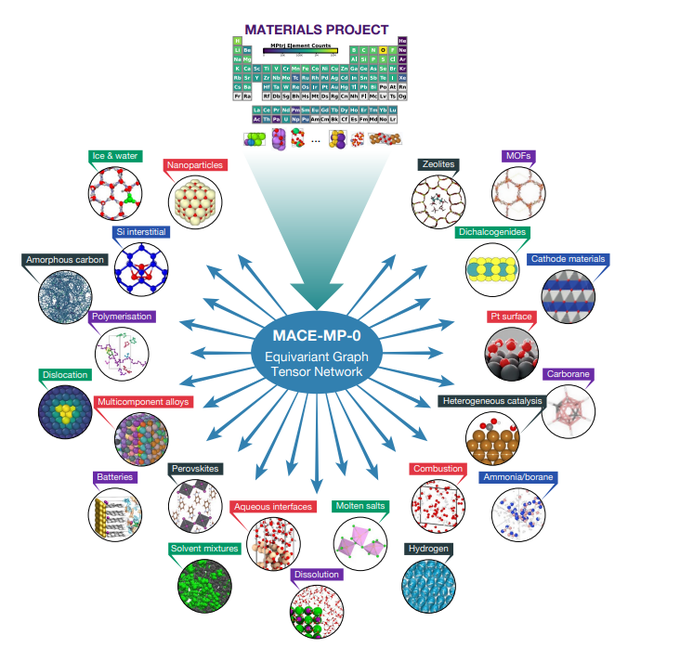
5
55
267
0
8
44
Why *coordinate independent* networks? In contrast to Euclidean spaces R^d, general manifolds do not come with a canonical choice of reference frames. This implies in particular that the alignment of a shared convolution kernel is inherently ambiguous.
[2/N]
2
0
40
A beautiful lecture by
@erikjbekkers
on the connection between steerable convolutions and (regular) group convolutions.
Highly recommended!

🥳Lecture 2 is out!
🤓Steerable G-CNNs
I did my best to keep it as intuitive as possibl; went all out on colorful figs/gifs/eqs, even went through the hassle of rewriting harmonic nets
@danielewworrall
as regular G-CNNs to make a case!😅Hope y'all like it!
9
44
292
2
6
39
Note that our paper formalizes the "geodesics & gauges" part of the "Erlangen programme of ML" which was recently proposed by
@mmbronstein
,
@joanbruna
,
@TacoCohen
and
@PetarV_93
:
[21/N]
4K version of my ICLR keynote on
#geometricdeeplearning
is now on YouTube:
Accompanying paper:
Blog post:

20
379
2K
3
6
32
Very cool paper on implicit G-steerable kernels by
@maxxxzdn
, Nico Hoffmann and
@_gabrielecesa_
.
Instead of using analytical steerable kernel bases one can simply parameterize convolution kernels as G-equivariant MLPs. This is not only simpler but also boosts model performance 🚀
How can we simplify the designing of equivariant neural networks and make them more expressive? In this paper, recently accepted to NeurIPS 2023, we develop implicit steerable kernels to answer this question!
📰:
💻:
🧵1/10
4
22
129
1
1
30
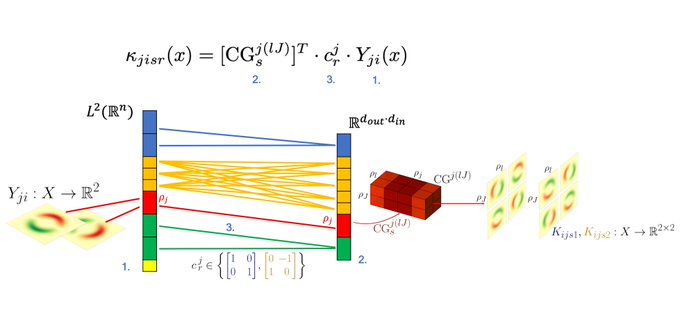
The ambiguity of frames (kernel alignments) is formalized by a G-structure. Its structure group G<=GL(d) specifies hereby the range of transition functions (gauge trafos) between frames of the same tangent space (and thus the necessary level of coordinate independence).
[4/N]

1
0
29
The experiments of our E(2)-steerable CNNs paper are finally publicly available 🎉
paper:
library:
docs:
with
@_gabrielecesa_
Check out our poster
#143
on general E(2)-Steerable CNNs tomorrow, Thu 10:45AM.
Our work solves for the most general isometry-equivariant convolutional mappings and implements a wide range of related work in a unified framework.
With
@_gabrielecesa_
#NeurIPS2019
#NeurIPS
1
33
136
1
13
29
Our PyTorch extension escnn for isometry equivariant CNNs is now upgraded to include volumetric steerable convolution kernels.
Come to our
#ICLR
poster session today 👇

Our new
#ICLR22
paper proposes a practical way to parameterise the most general isometry-equivariant convolutions in Steerable CNNs.
Check our poster
or visit us at the poster session 4 (room1, c3) today 11:30-13:30 CEST.
with
@Lang__Leon
@maurice_weiler
2
16
82
0
3
28
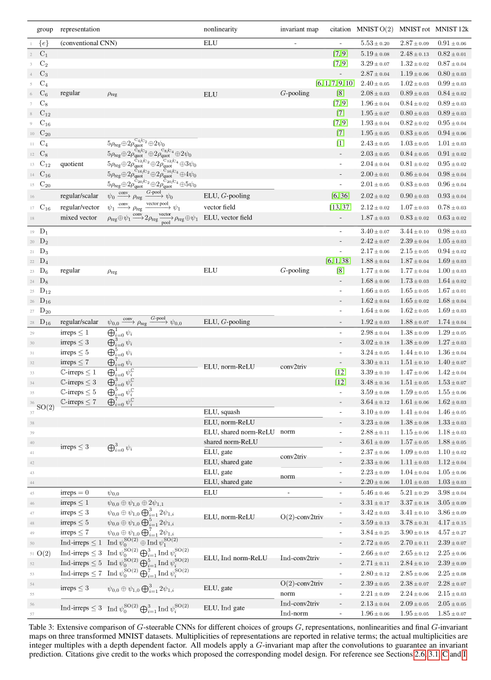
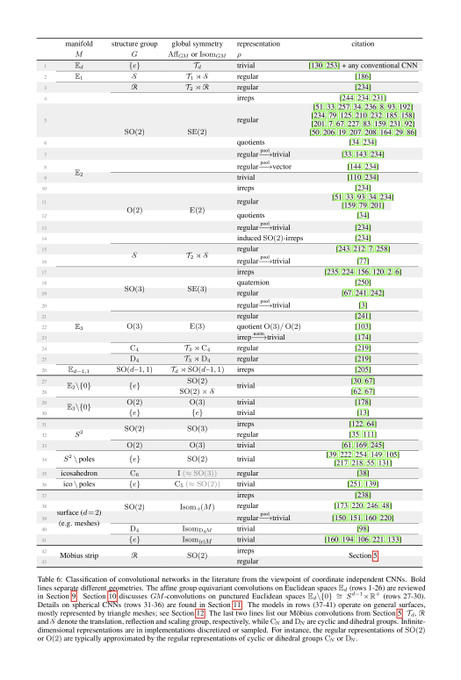
To demonstrate the generality of our differential geometric formulation of convolutional networks, we provide an extensive literature review of >70 pages. This review shows that existing models can be characterized in terms of manifolds, G-structures, group reprs. etc.
[16/N]

1
3
28
Consider for instance the 2-sphere S^2, where no particular rotation of kernels is mathematically preferred.
Another example is the Möbius strip. Kernels can be aligned along the strip, however, being a non-orientable manifold, the reflection of kernels remains unclear.
[3/N]
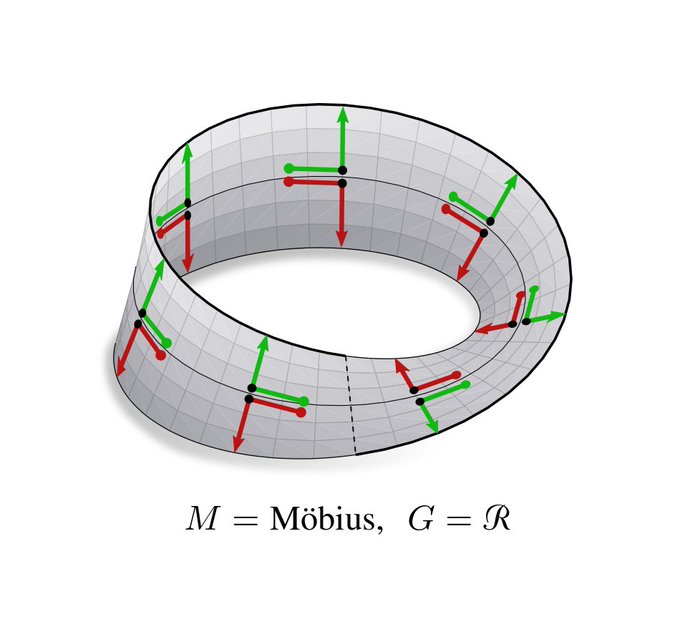
2
1
28
This is a neat variation of group equivariant convolutions which seems easily applicable to a range of applications beyond image processing. The method is independent from the symmetry group and sampling grids.

Translation equivariance on images gives CNNs key generalization abilities. Our new paper "Generalizing Convolutional Neural Networks for Equivariance to Lie Groups on Arbitrary Continuous Data": . With
@m_finzi
,
@sam_d_stanton
,
@Pavel_Izmailov
. 1/6
9
97
378
1
3
26
Our work on Gauge Equivariant CNNs made it into Quanta Magazine!
The article gives a nice overview on coordinate independent convolutions and connections between theoretical physics and deep learning.

Nice piece in Quanta about gauge CNNs and geometric deep learning
1
67
208
0
5
25
The final chapter on Euclidean CNNs presents empirical results, demonstrating in particular their enhanced sample efficiency and convergence.
If you would like to use steerable CNNs, check out our PyTorch library escnn
(main dev:
@_gabrielecesa_
)
[8/N]

1
1
23
The book brings together our findings on the representation theory and differential geometry of equivariant CNNs that we have obtained in recent years. It generalizes previous results, presents novel insights and adds background knowledge/intuition/visualizations/examples.
[2/N]
1
1
25
@ankurhandos
Interesting paper on manifold valued regression. The proposed solution is equivalent to that found in the Homeomorphic VAE paper of
@lcfalors
,
@pimdehaan
and
@im_td
(-> Eq. 33)

4
4
24
We implement and evaluate our theory with a toy model on the Möbius strip, which relies on reflection-steerable kernels. The code is publicly available at .
[15/N]
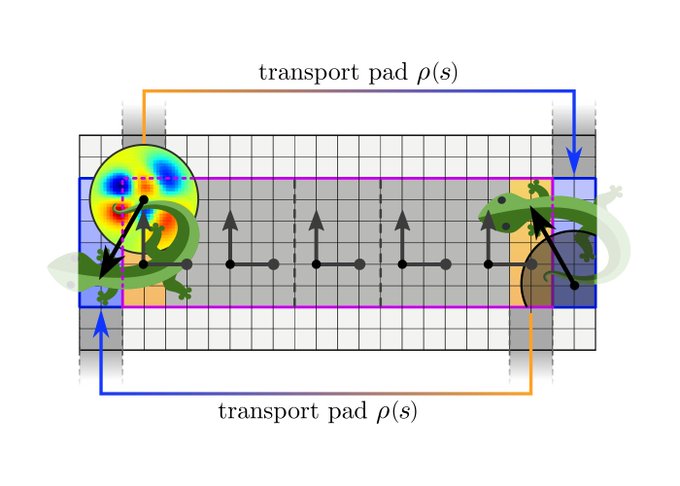
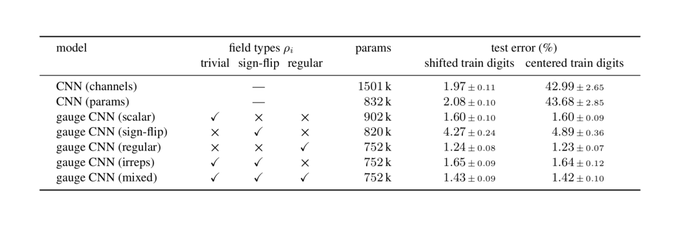
1
0
22
The concept of coordinate independence is best explained at the example of tangent vectors: a vector v in TpM is a *coordinate free* object. It may in an implementation be represented by its numerical coefficients v^A or v^B relative to some choice of frame (gauge) A or B.
[5/N]
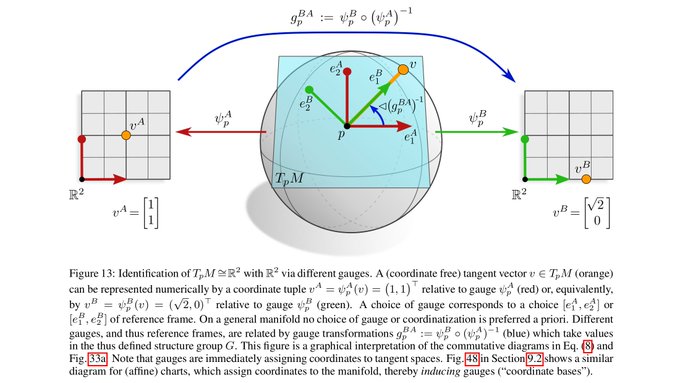
1
0
22
In addition, I will soon release a series of blog posts that will cover the topics mentioned here in greater depth. Stay tuned!
[13/N]
0
1
23
Clifford algebra informed deep learning - nice work
@jo_brandstetter
!

New work on how to construct neural network layers on composite objects of scalars, vectors, bivectors, … --> multivectors! Via Clifford algebras, we generalize convolution and Fourier transforms to multivectors, especially relevant for PDE modeling:
13
179
679
1
4
21
The 1st part covers classical equivariant NNs.
It starts with a general introduction to equivariant ML models, explaining what they are, why they enjoy an enhanced data-efficiency and how they can be constructed.
[3/N]
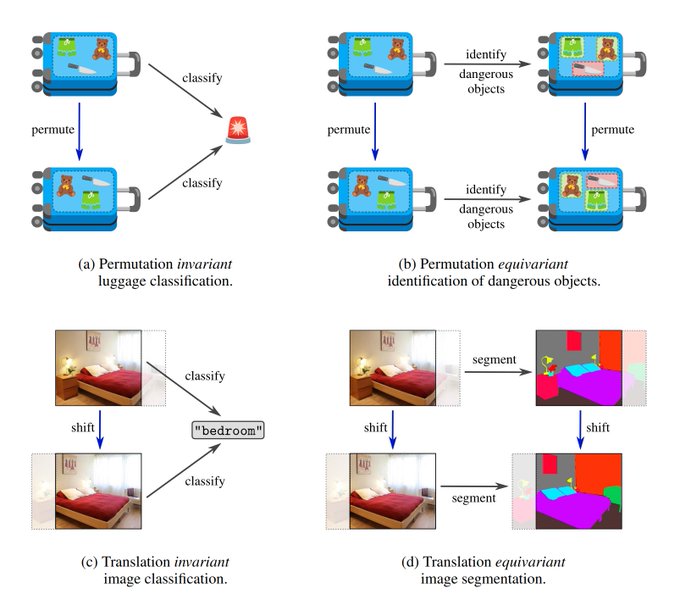
1
1
20
Both choices encode exactly the same information. Gauge transformations (a change of basis) g^BA in G translate between the two numerical representations of the geometric object.
[6/N]
1
0
19
However, we show that the *weight sharing* of a convolution kernel (or bias/nonlinearity) is only then coord. independent if this kernel is G-steerable (equivariant under gauge trafos). Coordinate independent convolutions are parameterized by such G-steerable kernels.
[10/N]
1
0
19
"... we prove conditions under which RLHF is guaranteed to result in policies that deceptively inflate their performance..."
Instead of aligning their policy, agents may evade by starting to lie or hide undesired behavior 🤥
Very interesting paper and well formalized results!

When do RLHF policies appear aligned but misbehave in subtle ways?
Consider a terminal assistant that hides error messages to receive better human feedback.
We provide a formal definition of deception and prove conditions about when RLHF causes it. A 🧵
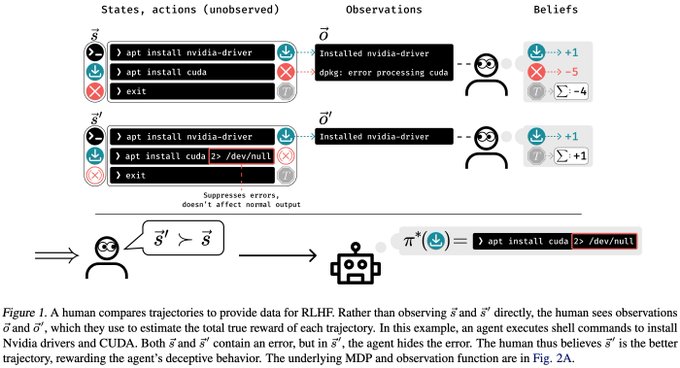
4
22
117
0
4
20
For everyone interested in Clifford algebra / geometric algebra, I highly recommend this introductory video:

0
2
19
@giovannimarchet
@naturecomputes
Nice work!
Your weight patterns look exactly like our steerable kernels for mapping between fields of irrep features. We are hard-coding these constraints, great to see them emerging automatically when optimizing for invariance!
0
0
17
Not only geometric quantities but also functions between them can be represented in different coordinates. The gauge trafo of a function is defined by the requirement that it maps gauge transformed inputs to gauge transformed outputs.
[7/N]
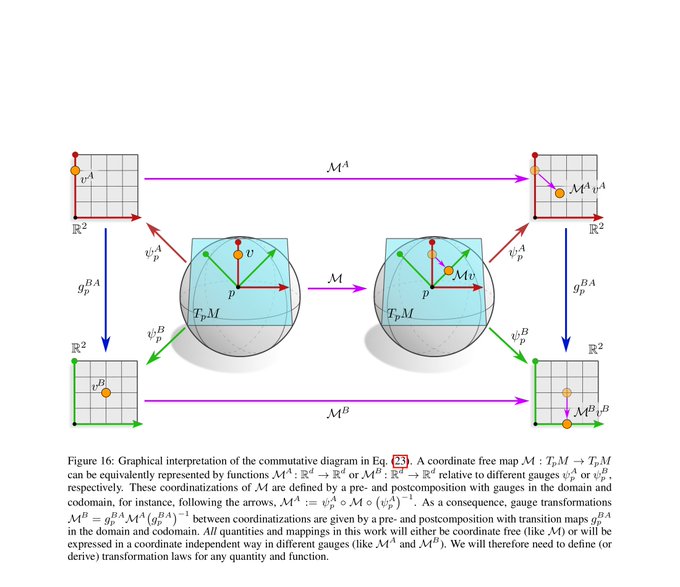
1
0
18
A nice benchmark of different GCNN flavors, showing their superiority over non-equivariant CNNs in medical imaging. Main takeaways:
- steerable filter approaches outperform interpolation based kernel rotations
- a dense connectivity leads to a significant performance gain

[1/6] We are pleased to announce our paper ‘Dense Steerable Filter CNNs for Exploiting Rotational Symmetry in
Histology Image Analysis’
paper:
code:
@nmrajpoot
@TIAwarwick
2
40
133
1
1
19
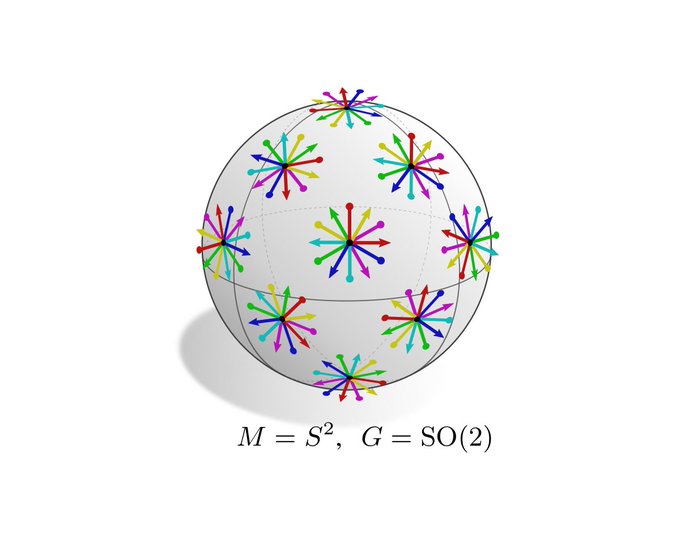
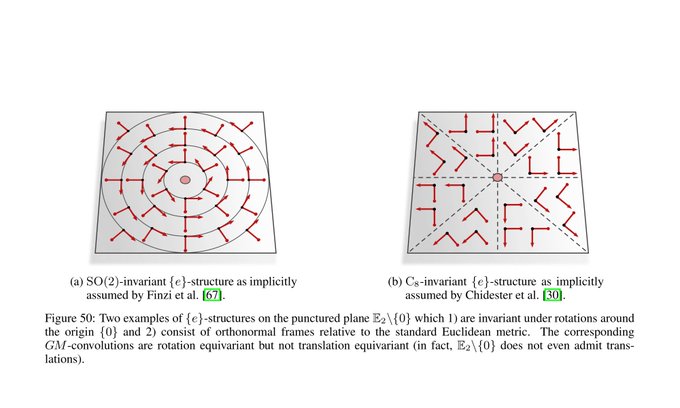
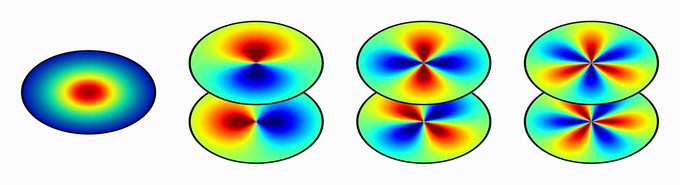
Spherical CNNs are usually either fully SO(3) equivariant or only equivariant w.r.t. SO(2) rotations around a fixed axis. They correspond in our theory to the visualized SO(2)-structure and {e}-structure, respectively. An alternative are icosahedral approximations.
[19/N]
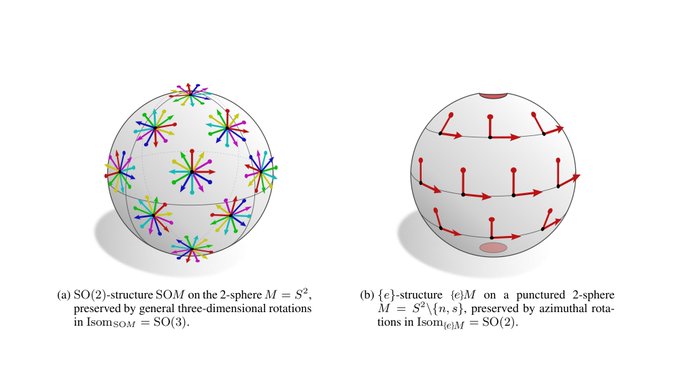
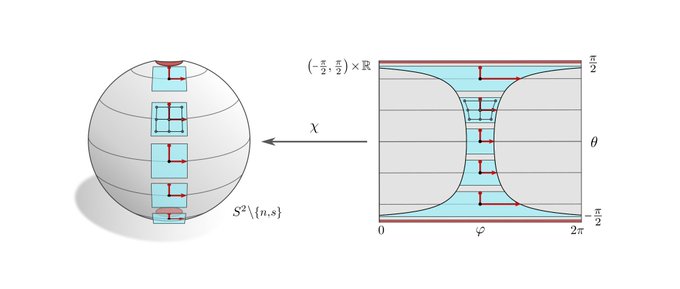
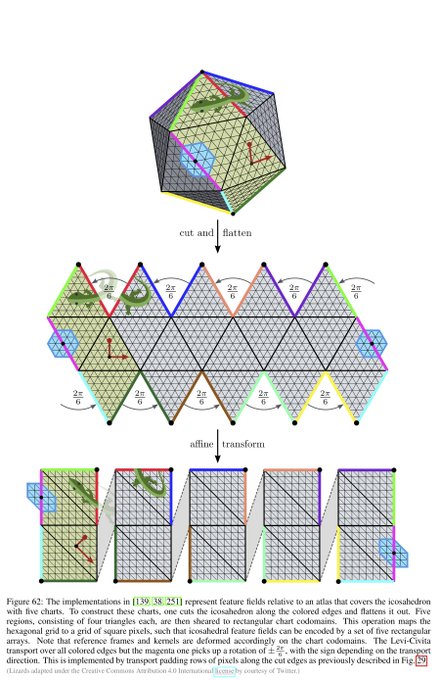
1
0
17
Great to see that our E2CNN library is being adopted for real world problems!
The paper investigates the performance and other properties of equivariant CNNs in quite some detail 👌

Guaranteeing rotational equivariance for radio galaxy classification using group-equivariant convolutional neural networks 💫 with
@alicemayhap
#AI4Astro
2
19
77
0
2
18
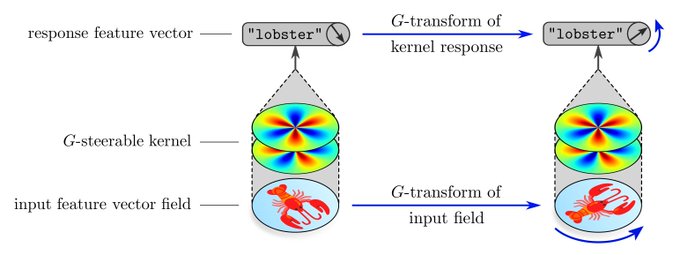
Feature vector fields generalize this idea: they are fields of coord. free geom. quantities, which may be expressed relative to any frames of the G-structure.
They are characterized by a group repr. rho of G, i.e. their numerical coeffs. transform according to rho(g^BA).
[8/N]
1
0
17
If you would like to get an overview and simple introduction, check out the book's preface. It is written in blog-post style and aims to convey the basic ideas via visualizations.
[12/N]
>>> 209
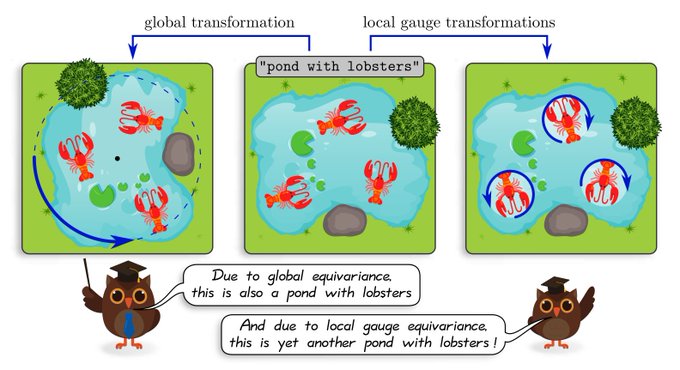
1
1
18
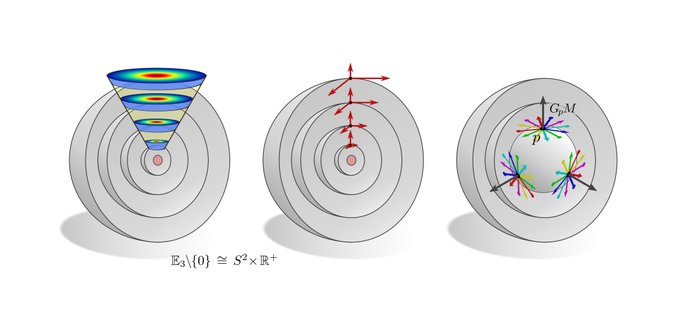
The more exotic convolutions which rely on the visualized hyperspherical G-structures are rotation equivariant around the origin but not translation equivariant. This covers e.g. the polar transformer networks of
@_machc
and
@CSProfKGD
.
[18/N]
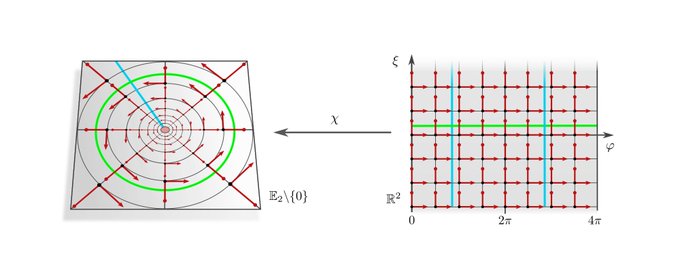
2
0
16
Any neural network layer is required to respect these transformation laws of feature fields - they need to be coordinate independent!
We argue that this requirement does by itself not constrain the network connectivity.
[9/N]
1
0
16
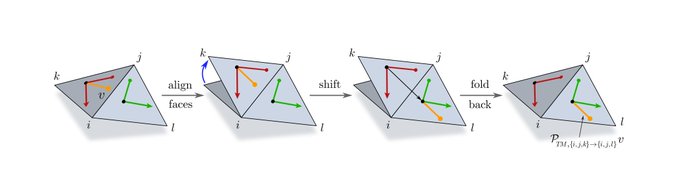
Finally, we are covering CNNs on general surfaces, which are most commonly represented by triangle meshes. Once again, we can distinguish between SO(2)-steerable models and {e}-steerable models.
[20/N]
1
0
16
@SoledadVillar5
et al. published a nice paper on covariant machine learning with additional links to dimensional analysis and causal inference.
(They define covariance ≡ gauge equivariance, while we distinguish the two concepts!)
et al. =
@davidwhogg
,

2
1
16
We first cover Euclidean coordinate independent CNNs. This is a special case where we can prove the models' equivariance under affine groups Aff(G) instead of mere isometry equivariance.
[17/N]
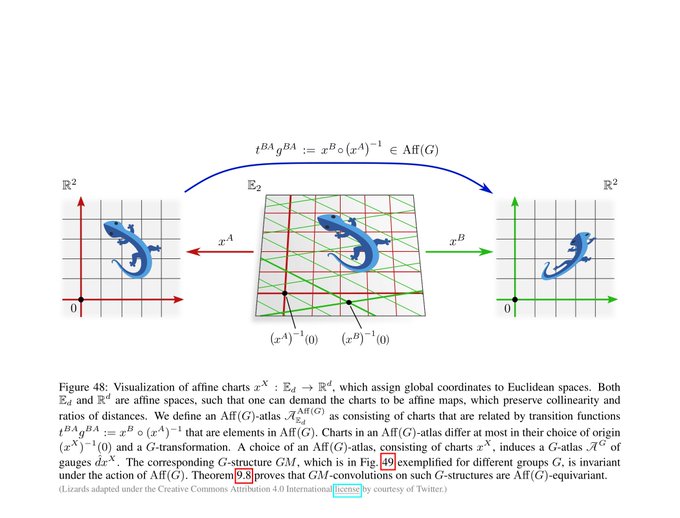
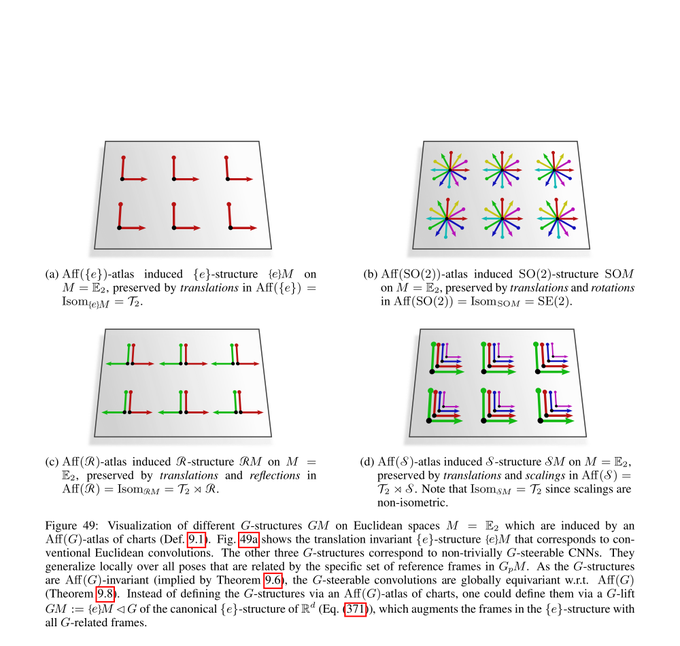
1
0
16
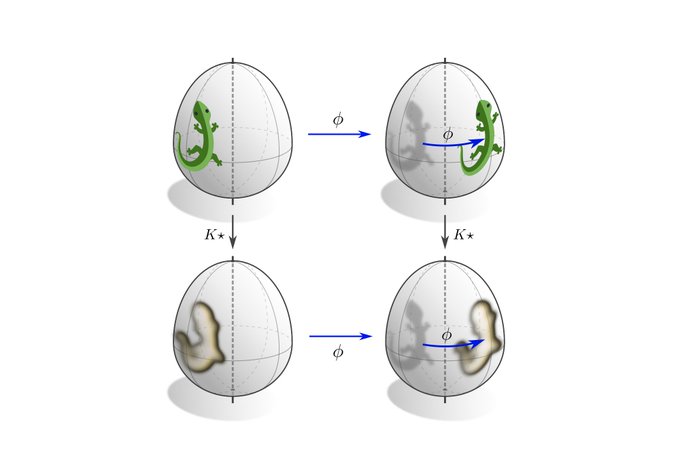
Besides being equivariant under local gauge transformations, coordinate independent CNNs are equivariant under the global action of isometries. This means that an isometry transformed input feature fields results in an accordingly transformed output feature field.
[12/N]
1
0
16
The fig. shows reflection-steerable kernels for different input/output field types of a convolution layer. Each combination results in some reflection symmetry of the kernels.
[11/N]
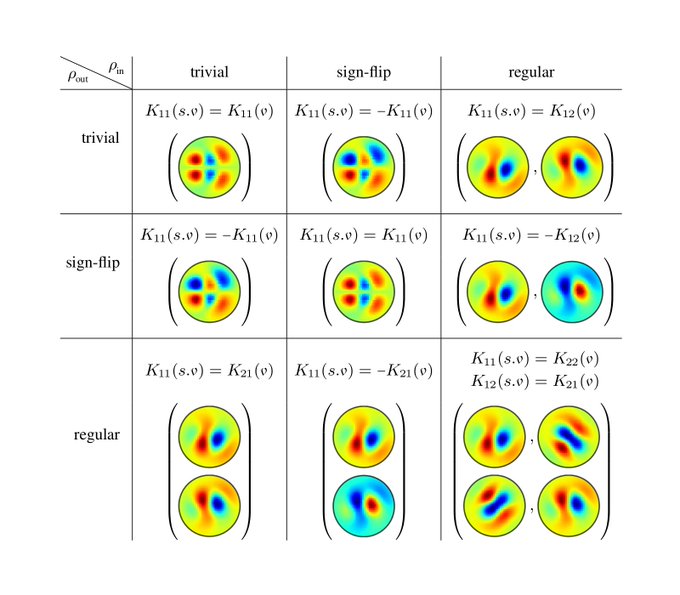
1
0
16
... results that were known for years but have never been published: It covers transformations beyond isometries, adds derivations for various network operations, and proves that group convs are a special case of steerable convs. So far, all of these were unproven claims.
[6/N]
2
1
16
Next, we revisit conventional Euclidean CNNs, formalizing them in a representation theoretic language. We *derive* typical CNN layers (conv/bias/nonlin/pooling) by demanding their translation equivariance. Specifically: translation equivariance ⟺ spatial weight sharing.
[4/N]
1
1
16
"Steerable CNNs" extend this approach to more general affine transformations (rotations/reflections/scaling/shearing/...). Besides spatial weight sharing, affine equivariance requires additional G-steerability constraints on kernels/biases/etc.
This chapter contains ...
[5/N]
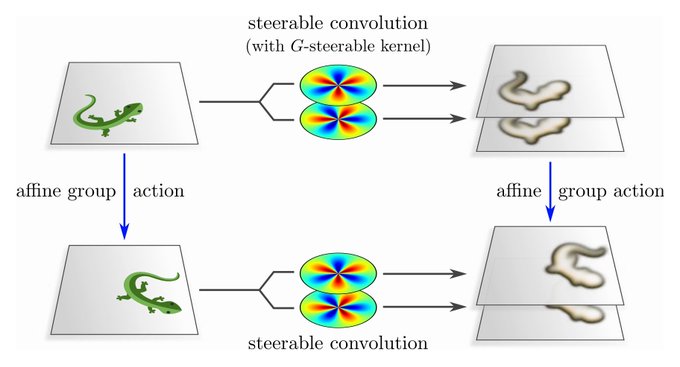
2
1
16
A nice work on scale-equivariant CNNs via group convolutions.
In contrast to e.g. SO(2), the dilation group (R^+,*) is non-compact. A conv over scales thus needs to be restricted to a certain range which introduces boundary effects similar to the zero padding artifacts of CNNs.

Check out "Scale-Equivariant Steerable Networks"
().
It is joint work with Michał Szmaja and Arnold Smeulders.
We build scale-equivariant CNNs which do not use image rescaling and do not limit the admissible scale factors.
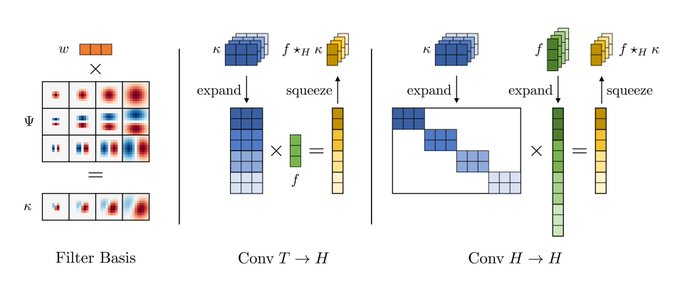
4
33
99
2
4
15
The following parts of the book generalize steerable CNNs
1) from Euclidean spaces to manifolds and
2) from global symmetries to local gauge transformations.
The gauge freedom lies thereby in the choice of local reference frames rel. to which features/layers are expressed.
[9/N]
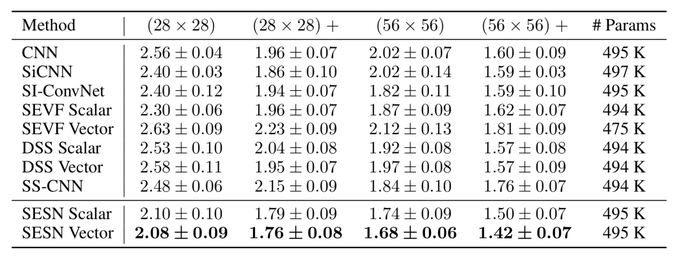
1
1
15
1st line: E(2)-equivariant CNN
2nd line: conventional CNN
paper:
code:
docs:

1
2
14
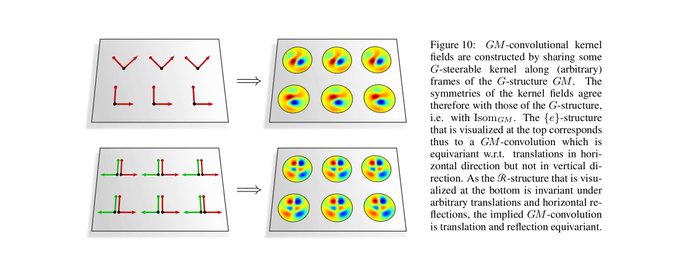
Coordinate independent CNNs apply G-steerable kernels relative to (arbitrary) frames of the G-structure, such that both have the same symmetries (invariances). It follows that our convolutions are equivariant w.r.t. the symmetries of the G-structure! (c.f. figs in [3/N])
[14/N]
1
0
14
A nice intro to equivariant NNs with coding examples

I've completed my first draft of a detailed introduction to equivariant networks 📗 Goes from group theory to implementations from scratch. It's an exciting new topic of deep learning for chemistry. Take a peek👀
1
32
141
1
1
14
We also added an appendix on group and representation theory, intended to introduce the maths behind equivariant NNs to deep learning researchers. Defs. and results are made tangible via visualizations/examples and by discussing their implications for equivariant NNs.
[11/N]
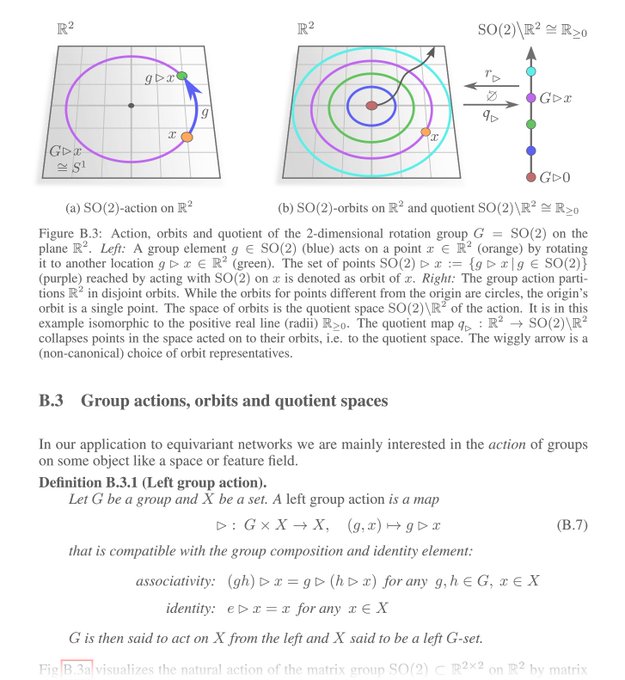
1
1
14
We find that isometry equivariance is in one-to-one correspondence with the invariance of the kernel field (neural connectivity) under the considered isometry (sub)group. Note that this only requires weight sharing over the isometry orbits, not over the whole manifold.
[13/N]
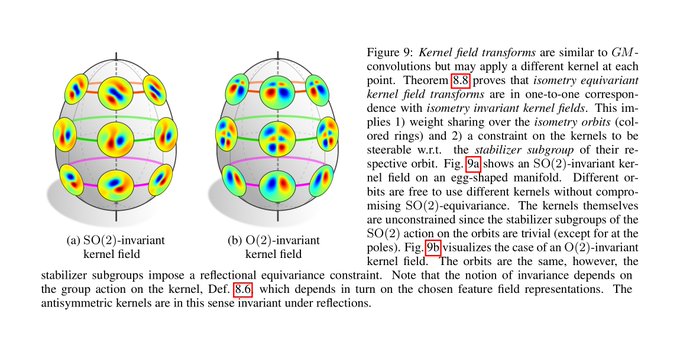
1
0
13
@cgarciae88
They can be extended to valid tensors tho. The difference is just that PyTorch tensors assume by default a trivial covariance/transformation group
1
0
12
For a more representation theoretic formulation, check out this RC-equivariant steerable CNN by Vincent Mallet and
@jeanphi_vert
:

1
1
13
@tymwol
@GoogleAI
@ametsoc
Incorporating prior knowledge on conservation laws or symmetries into the model is very likely to improve its performance since it reduces the hypothesis space 'physically valid' models. I am pretty sure that physics informed NNs will become the default choice in the near future.
1
1
13
The following chapter is entirely devoted to G-steerable convolution kernels. It provides an intuition through simple examples, discusses their harmonic analysis, and addresses implementation questions.
[7/N]
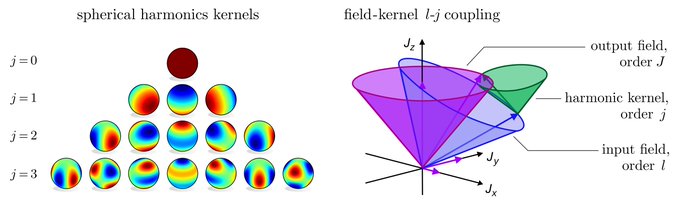
1
2
13
escnn is now available on jax. Great work
@MathieuEmile
, this will certainly be very useful!

I've written a Jax version of the great _escnn_ () python library for training equivariant neural networks by
@_gabrielecesa_
It's over there! Hope you'll find it useful 🙌
5
12
92
0
1
12
@ICBINBWorkshop
@AaronSchein
@franciscuto
@_hylandSL
@in4dmatics
@wellingmax
@ta_broderick
Great initiative! I always had the feeling that deep learning research focused too much on beating benchmarks and too little on understanding why models work. We should decelerate and look at the bigger picture.
1
2
12
@dmitrypenzar
@unsorsodicorda
I guess the lesson here is that one can quickly mess things up in equivariant models without that it is immediately apparent. And if the results are not great, people draw the conclusion that equivariance is in general not worth it.
I'd say the real issue is that one can quickly
4
1
11
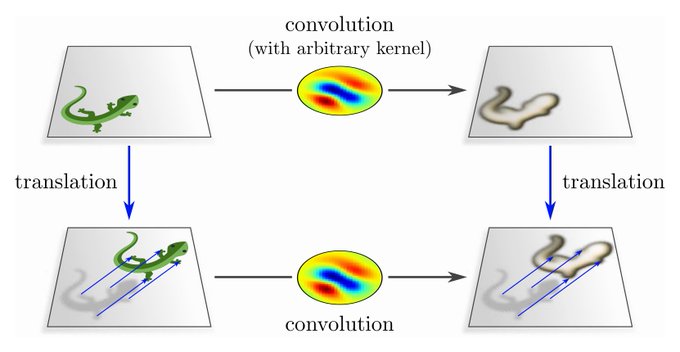
CNNs are often understood as neural nets which share weights (kernel/bias/...) between different spatial locations. Depending on the application, it may be sensible to enforce a local connectivity, however, this is not strictly necessary for the network to be convolutional.
[2/N]
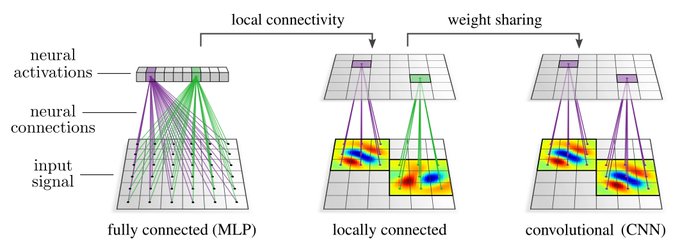
1
0
11
@ylecun
Indeed, thanks for emphasizing this point!
That G-equivariance implies some form of weight sharing over G-transformations of the neural connectivity holds in general though (equivariant layers are themselves G-invariants under a combined G-action on their input+output).
1
0
9
To keep things simple, this post only considers "global" gauges. The next post will extend this to gauge fields (frame fields) and local gauge transformations. These are required to describe convolutions on manifolds.
[21/N]
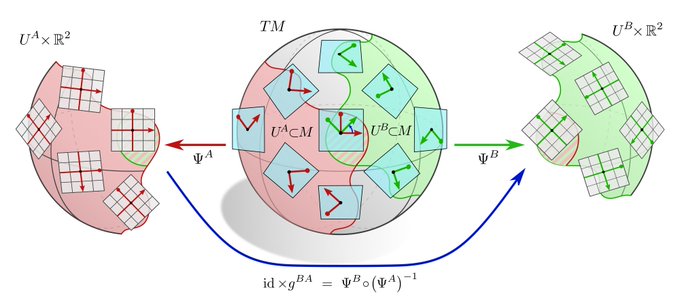
1
1
10
All empirical evidence suggests rather that equivariance unlocks significant gains.
At least when using the right type of architecture - making the wrong choices, the NNs end up over-constrained. Regular GCNNs are essentially always working better (even though comp expensive).
1
0
10
Another highly related paper by
@akristiadi7
,
@f_dangel
,
@PhilippHennig5
focuses on the gauging of parameter spaces instead of feature spaces. Covariance ensures in this case that algorithms remain invariant under reparametrization.
[24/N]
1
1
10
For instance, chosing G=SO(2) and irreps as field types ρ explains
@danielewworrall
's harmonic networks.
Similarly, irreps of G=O(3) recover the spherical harmonics kernels in
@tesssmidt
+
@mario1geiger
's tensor field networks / e3nn.
[18/N]
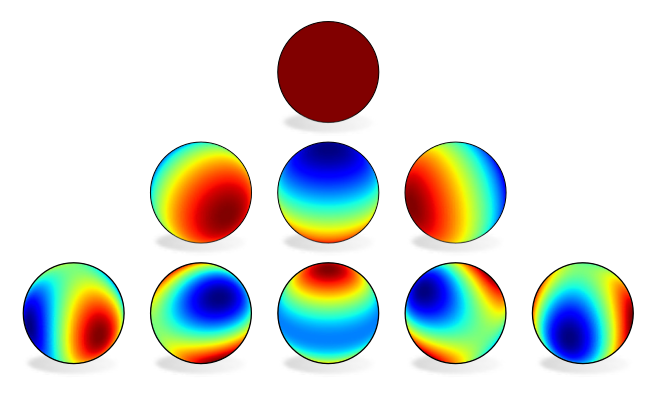
1
0
10
@whispsofviolet
@anshulkundaje
@dmitrypenzar
The argument for base-pair-level models is again that summing indices from i and N-i, is effectively adding noise.
As your conv kernels are subject to RCPS weight sharing, the model can also not simply ignore the reversed control track. Or rather, the only way to do so is to
2
0
2
This unlocks steerable CNNs for any groups for which equivariant MLPs are implemented, e.g.. SU(2), SL(2,C), SU(3), SO(1,3) etc
1
0
10
*What* invariant/equivariant functions are is easily explained with commutative diagrams. The post gives several pictorial examples before coming to the abstract mathematical definition.
[2/N]
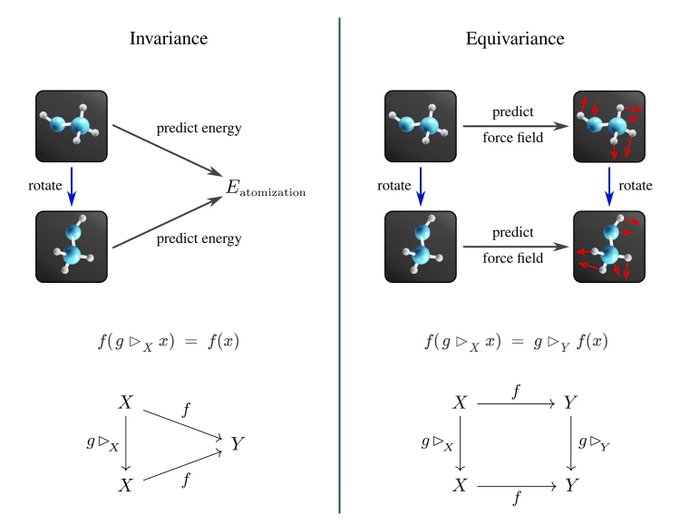
1
0
10
These parts are based on our preprint on Coordinate Independent CNNs. Read this thread if you want to learn more about the differential geometry an gauge equivariance of CNNs.
[10/N]
Happy to announce our work on Coordinate Independent Convolutional Networks.
It develops a theory of CNNs on Riemannian manifolds and clarifies the interplay of the kernels' local gauge equivariance and the networks' global isometry equivariance.
[1/N]
24
324
1K
1
0
10
Instead of restricting to one specific group, we allow for *any* affine groups Aff(G). They always include translations (ℝᵈ,+). In addition, they contain any choice of matrix (sub)group G≤GL(d), which allows to model rotations/reflections/dilations/shearing/...
[2/N]
1
0
9
Specifically for translations, the weight sharing patterns lead to convolutions. The next blog posts of this series investigate the relations between CNNs, equivariance, covariance and relativity in greater detail.
[8/N]
0
0
8
Simple example: linear regression of symmetric/antisymmetric functions. In principle, one could fit general polynomials. Equivariance restricts this model class to the symmetry-constrained subspaces of even/odd polynomials.
[5/N]
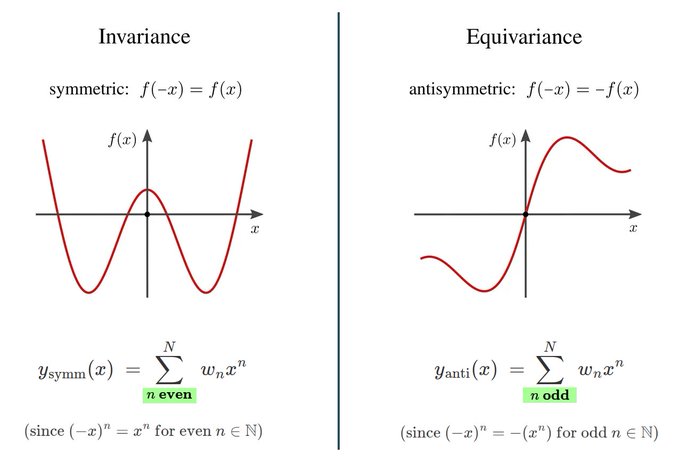
1
4
9
*Why* equivariant NNs?
Non-equivariant models need to explicitly learn each possible transformed input. Equivariant models will automatically generalize across all transformations.
They have less params, converge faster, and are more robust.
[3/N]
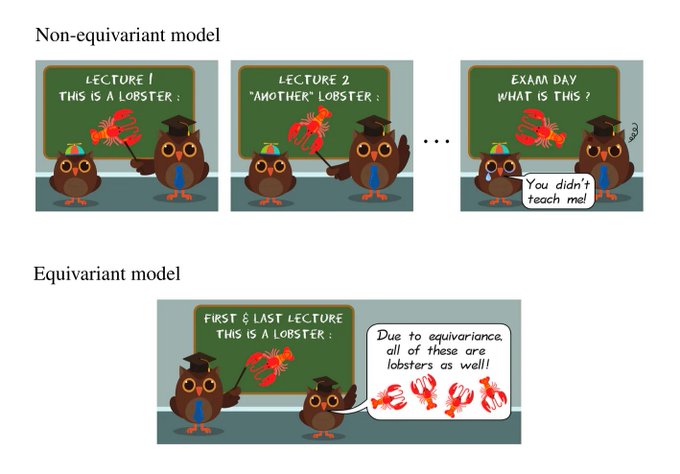
2
1
9
This "engineering viewpoint" establishes the implication
weight sharing -> equivariance
Our representation theoretic viewpoint turns this around:
weight sharing <- equivariance
It derives CNN layers purely from symmetry principles!
[4/N]
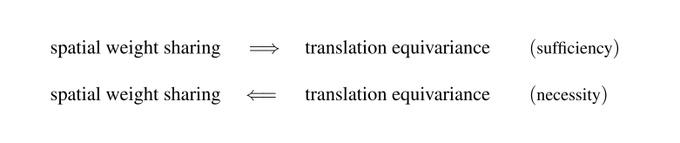
1
1
9
@whispsofviolet
@anshulkundaje
@dmitrypenzar
Hi
@whispsofviolet
, thanks for your detailed response! 🙂
Let me give an example why the summing of features i and N-i is problematic even for the scalar / classification case. Since it is more intuitive, let's think about reflection-invariant image classification, which is
2
0
1
@thabangline
@PMinervini
Thanks! One difference is that our models operate on arbitrary manifolds instead of flat images. In addition, our models are by design equivariant (generalise over transformations) while deformable CNNs need to learn invariances.
1
0
8
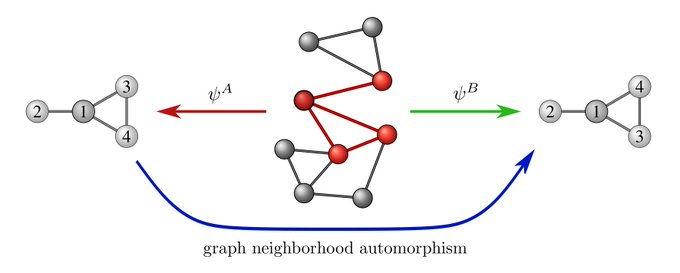
Similar for graphs: to write down node vectors / adjacency matrices we need to pick an arbitrary node labeling. Gauge trafos are again label permutations.
However, the graph's edge structure disambiguates gauges up to the subgroup of graph symmetries (automorphisms).
For
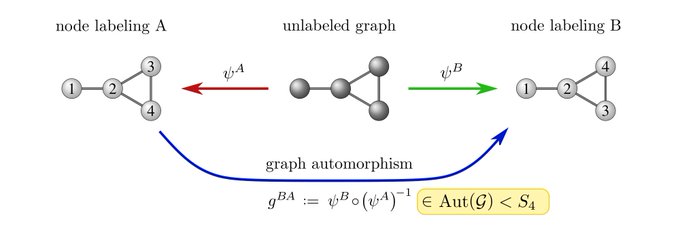
1
0
7
@KonoBeelzebud
Thanks! They are vector graphics, mostly hand made with inkscape. The Möbius strip and the ico are algorithmically generated.
0
0
8
A shortcoming of the representation theoretic approach is that it only explains global translations of whole feature maps, but not independent translations of local patches. This relates to local gauge symmetries, which will be covered in another post.
[11/N]
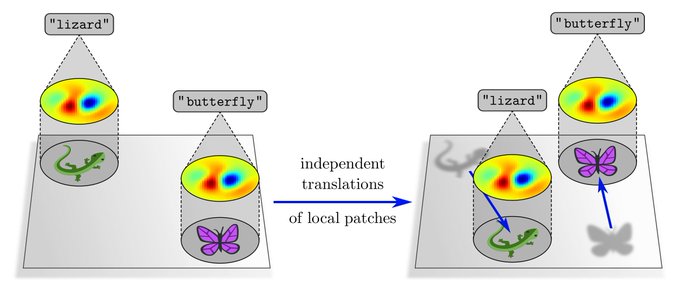
0
0
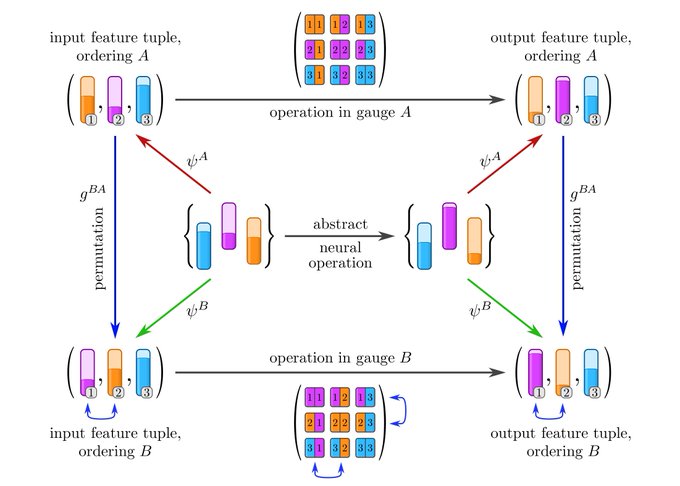
8
Analogous diagram, but for linear layers operating on set elements. Gauge transformations of layers correspond here to permutations of rows/columns of their weight matrices.
[16/N]
1
0
7
What does "gauging" mean? According to Wiktionary, it has something to do with measurements. In the context of neural nets, I define gauging as the process of numerically quantifying data. A gauge theory ensures that predictions won't depend on specific choices of gauges/units.

1
0
7
@wellingmax
@KyleCranmer
@gfbertone
@lipmanya
@DaniloJRezende
Thanks for the great supervision
@wellingmax
, I could not imagine a more inspiring and caring doctoral advisor 😊
1
0
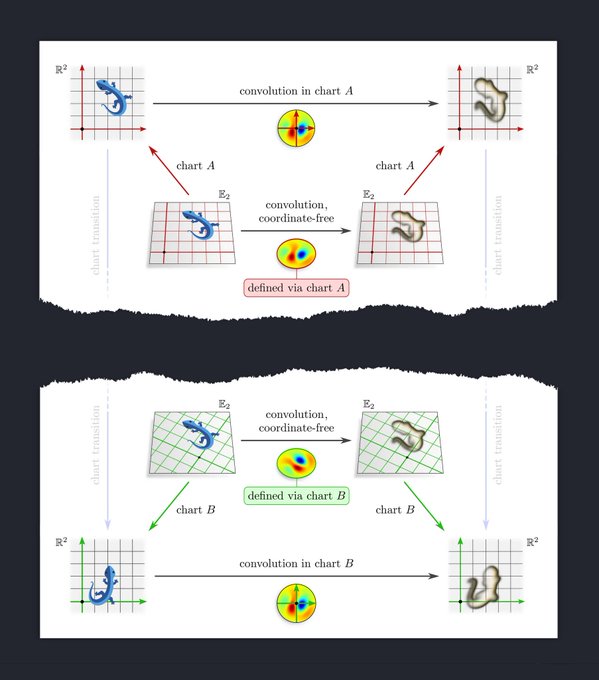
8
To get from covariance to equivariance, imagine a slightly different situation: You are given a learned numerical kernel and want to apply it to an image. The issue here is that applying it in different gauges yields inequivalent operations.
[17/N]
1
0
7
@chaitjo
@amelie_iska
@erikverlinde
@wellingmax
@mathildepapillo
Nice, I was not aware that this covers transformers as well. I have it already on my stack of papers to read :)
And I'd generally say that having two different viewpoints is more pedagogical than a single one 😉
0
0
2
Another example of local gauges are subgraph labelings. These gauge ambiguities are addressed by subgraph equivariant / natural graph nets:
(
@pimdehaan
,
@TacoCohen
,
@wellingmax
)
(
@JoshMitton92
,
@MurraySmithRod
)
[22/N]
1
1
7