

Matthew Leavitt
@leavittron
Followers
2,232
Following
786
Media
185
Statuses
2,360
Chief Science Officer, Co-Founder @datologyai . Former: Head of Data Research @MosaicML ; FAIR. 🧠 and 🤖 intelligence // views are from nowhere
The Bay
Joined March 2011
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Norway
• 134115 Tweets
Pacers
• 131989 Tweets
中尾彬さん
• 116022 Tweets
声優さん
• 74990 Tweets
Ireland and Spain
• 48714 Tweets
古谷さん
• 44837 Tweets
妊娠中絶
• 26341 Tweets
安室さん
• 25057 Tweets
النرويج
• 24575 Tweets
声優交代
• 22427 Tweets
死刑求刑
• 21345 Tweets
Estado Palestino
• 20266 Tweets
ブートヒル
• 18033 Tweets
Noruega
• 16586 Tweets
袴田さん
• 15787 Tweets
RIDDLE
• 10356 Tweets
#FeelThePOP2ndWin
• 10148 Tweets




















Pinned Tweet

The next 10x in deep learning efficiency gains are going to come from intelligent intervention on training data. But tools for automated data curation at scale didn’t exist—until now. I’m so excited to announce that I’ve co-founded
@DatologyAI
, with
@arimorcos
and
@hurrycane
11
16
126
As a neuroscientist imma call bullshit on this. All these "mind reading" techniques rely on an fmri scanner: a multimillion dollar, 10000lb+ machine that requires a purpose-built facility and you have to lie perfectly still in it for it to work. Nobody's stealing your thoughts

134
135
1K
v excited to finally announce our new work that formalizes one of the most effective practices for training LLMs—something that many industry leaders have conspicuously avoided discussing

19
97
895

There are like 5 people in all of deep learning who have actually looked at the pretraining data that a 7B+ model has been trained on (and three of them went mad)
11
12
291
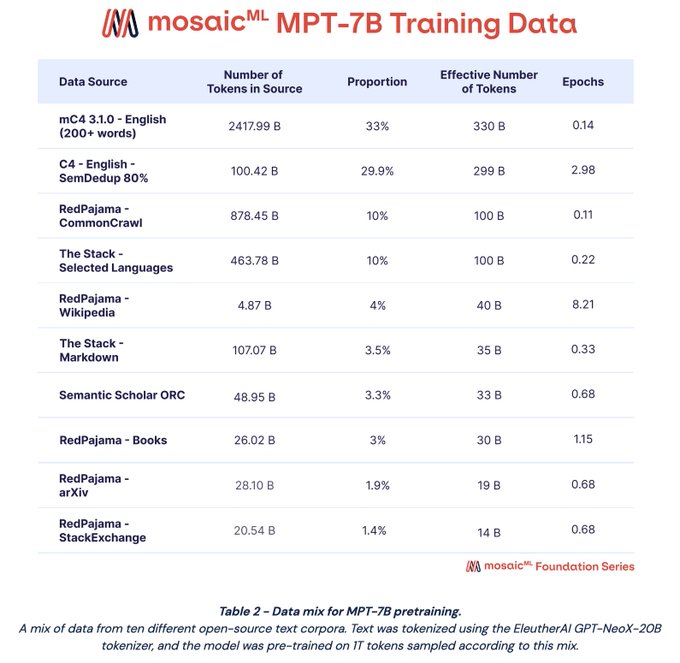
By now you may have seen some hubbub about
@MosaicML
’s MPT-7B series of models: MPT-7B base, MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+. These models were pretrained on the same 1T token data mix. In this 🧵I break down the decisions behind our pretraining data mix
8
53
258
A few (somewhat data-centric) thoughts on the Gemini whitepaper 🧵:
Can't be much more direct than this: "We find that data quality is critical to a highly-performing model". It feels especially true cuz they provide next to no information on the training data.

3
20
187
It seems likely to me that Mistral 7B's quality comes from its data. You know, the thing they provide exactly zero information about. The sliding window attention is a red herring.

Mistral just released the paper behind their impressive LLM: Mistral 7B.
The model outperforms Llama2 13B on every benchmark.
Architecture:
- Uses Grouped-query attention (GQA) for faster inference
-Uses Sliding Window Attention (SWA) to handle longer sequences at smaller

7
11
92
11
9
174
s/o to
@danielking36
for the exceptional title. We also considered "Training on the test set is all you need", "The Unreasonable Effectiveness of Training on the Test Set", and "Intriguing Properties of Training on Test Data"
1
2
156
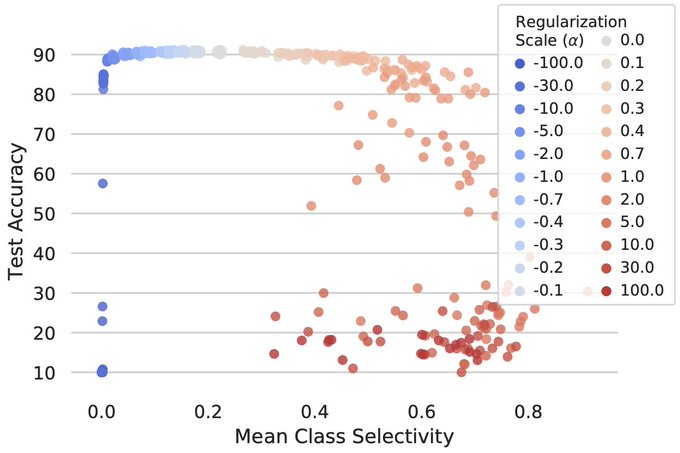
Class selectivity is often used to interpret the function of individual neurons.
@arimorcos
and I investigated whether it’s actually necessary and/or sufficient for deep networks to function properly. Spoiler: it’s mostly neither. (1/10)
6
34
108

This is a red herring, of course. What everyone really wants to know (and what W&B will certainly keep as a close secret) is the Best Seed. Publicizing this seed would not only give away their competitive advantage, but also violate US Arms Control Laws.

The average learning_rate logged to W&B in 2022 was 0.016
25
38
793
11
4
97
This was a huge headache in the early days of
@MosaicML
, so we built our tooling to seamlessly handle GPU failures. Our platform will detect a faulty node, pause training, cordon the node, sub in a spare, and resume from the most recent checkpoint. All w/o any human intervention

Hardware failures are common while training the largest machine learning models across thousands of GPUs. It is similar to the elder days of computers, when a vacuum tube burning out during your batch computation was a real issue.
53
102
2K
3
5
89
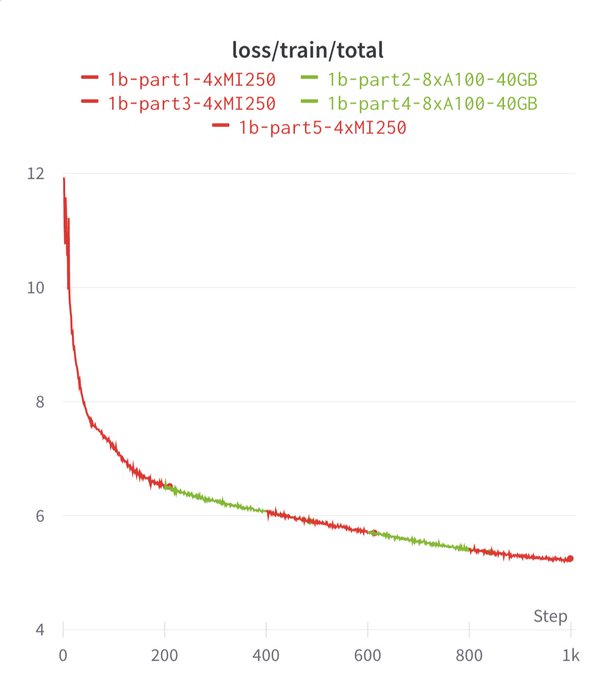
Celebrate GPU Independence Day! My colleagues at
@MosaicML
just showed how simple it is to train on AMD. The real kicker here is switching between AMD and NVIDIA in a single training run

And yes, you can switch back and forth between NVIDIA and AMD, even within a single training run.
It's Christmas in July!🎄
9
46
426
1
15
91
Me and my talented colleagues at
@MosaicML
made ResNet50 go brrrrrr. We devised three training recipes for a vanilla ResNet-50 architecture that are up to 7x faster than other baselines. We didn't even sweep hparams extensively. And it's plain PyTorch.
@jefrankle
has the scoop:

Introducing the *Mosaic ResNet*, a new take on a CV workhorse that sets SOTA for efficiency at any ImageNet accuracy. The recipe uses 12 techniques that change the math of training for a 7x speedup over standard baselines + up to 3.8x over the latest work.
7
69
368
3
11
89

As Head of the Data Research Team at
@MosaicML
, I cannot think of an acquirer I'd be more excited about

Today we’re announcing plans for
@MosaicML
to join forces with
@databricks
! We are excited at the possibilities for this deal including serving the growing number of enterprises interested in LLMs and diffusion models.
58
66
665
5
2
81
I'm going to take this opportunity to recommend that everyone read Paul Cisek's1999 paper "Beyond the computer metaphor: Behaviour as interaction" which presages many of the contemporary discussions about the necessity of embodiment for overcoming limitations in deep learning

@dileeplearning
Nah man, see the tweet I quoted. Most people think it is a metaphor, cause they think computer == Von Neumann machine.
2
0
8
3
13
71
TFW cosmic rays ruin your training run.
To be fair, most SDC events probably aren't due to cosmic rays, but it's fun to think about the universe extending a glittering tendril into the delicate gears of your trainer and whispering "nope".

3
6
73
@arimorcos
and I are excited to announce our position paper, Towards falsifiable interpretability research, is part of
#NeurIPS2020
@MLRetrospective
! We argue for the importance of concrete, falsifiable hypotheses in interpretability research. Paper: (1/8)
3
6
66
New LR schedule just dropped

Friends, colleagues, may I present to you: the California Marginal Tax Rate Schedule
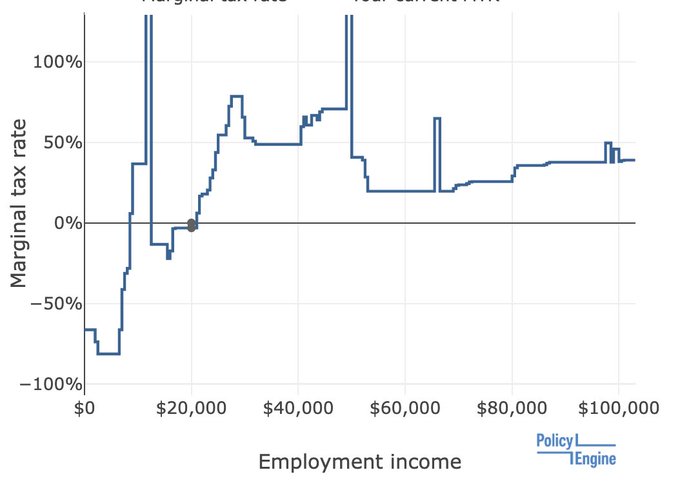
68
300
3K
1
2
64
My question is no longer rhetorical: Let's get data on this. If you or someone you know was prevented from attending SfN by the travel ban, please fill out this form: . I want (everyone) to know exactly how much damage this policy is causing
1
67
56
@marcbeaupre
You need to generate 3-7T of magnetic field strength, which requires a large magnet, lots of power, and helium cooling. I dunno what the physical limits are on magnet size for field generation; also power consumption/dissipation seem like big issues
5
2
60

Now that we're out of stealth I'm very excited I can announce I'm a Research Scientist at
@MosaicML
.
We help the ML community burn less money by training models more efficiently. There's a lot of fascinating research and engineering that enables this.
And we're hiring 😀

Hello World! Today we come out of stealth to make ML training more efficient with a mosaic of methods that modify training to improve speed, reduce cost, and boost quality. Read our founders' blog by
@NaveenGRao
@hanlintang
@mcarbin
@jefrankle
(1/4)
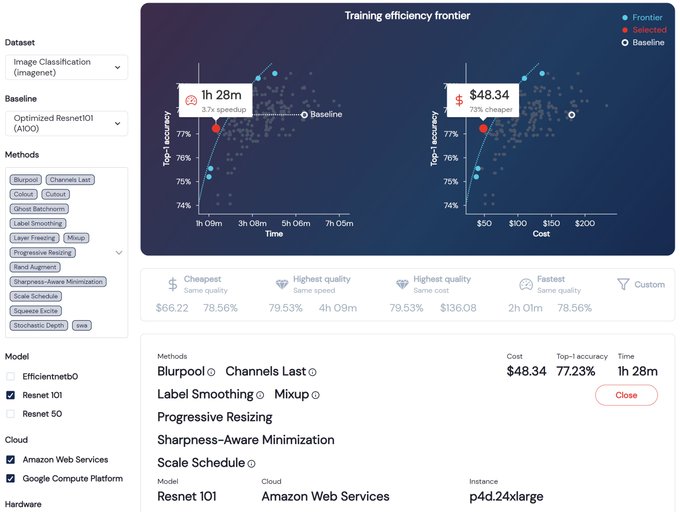
7
41
164
4
3
54
This is why I pushed
@MosaicML
to create a Data Research Team last year (and
@jefrankle
recognized the value and made it happen)

From the papers that I've read on LLMs in the past 6 months, one thing is clear: higher data quality will be key to keep pushing progress.
Lots of companies and researchers keep innovating and implementing ways to improve data quality in all areas ranging from finetuning LLMs
12
35
231
1
1
54
Very cool to see what is essentially SemDedup () work for fine-tuning data


Getting good results by filtering some public datasets. You'll find lots of duplicates. Filter by instruction similarity score > .95 (cosine) using e5-large-v2. After filtering sort the dataset by instruction length ascending order, this gave best loss + benchmark scores
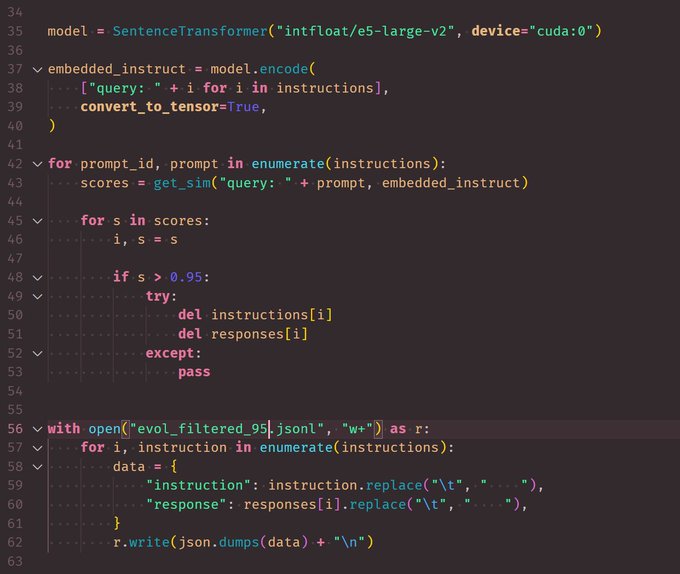
10
29
208
1
6
49
Also, most importantly, these studies aren't decoding endogenously generated signals, they're reconstructing WHAT THEY ARE CURRENTLY SHOWING YOU

6
3
44
Are LLMs hugely overhyped? yes, just look at the cryptobros jumping on the bandwagon and meaningless AI references in co's copy and strategy
Flash in the pan? No. This tech is going to get integrated into everything.
4
0
43
Unfortunately A/B testing is tough: it requires lots of subjects and/or well-defined use patterns. In lieu of that, my favorite eval method is "find someone who has spent way too much time using way too many models and ask them to do a vibe check". Reviewers don't love this tho.

2
5
45


To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis
Studies what would happen if we train LLM with repeated data and how we can alleviate the LLM mult-epoch degradation.

2
19
128
0
0
39
@marcbeaupre
Overall, I suspect miniaturization would require a massive breakthrough in materials science. The tech has already been around for 30+ years. I'd sooner bet on a different brain imaging modality than fmri miniaturization, but I'm also not an fmri expert
3
0
33

C4 Part 2: Multiepoch pretraining isn’t really a thing in NLP because…tradition? Superstition? Our initial experiments actually showed its actually totally fine for ≤8 epochs (more experiments to come!), so we trained on our SemDedup’d C4 for 2.98 epochs (299B tokens)
7
2
37
Very excited to announce that I've joined
@hanlintang
and
@NaveenGRao
in their quest to make ML more efficient!
3
1
37
The Gemini whitepaper also emphasizes the importance of training the tokenizer on a “large sample” of the dataset. IMO tokenizers as a vector for model improvement are vastly underexploited. Data curation and tokenization both suffer because researchers overlook data.

1
1
35
Related question that
@KordingLab
and I have: is there a literature or materials on how to build strong hypotheses, esp in neuroscience? Most philosophical work we're familiar with is too abstract/meta to feel practical, esp as part of a graduate curriculum

Research on interpreting units in artificial neural networks fails to be falsifiable. And just about everything that Matt Leavitt and
@arimorcos
say about the problem in ANNs is a problem in neuroscience.
7
41
172
3
6
31
@ItsMrMetaverse
I actually escaped my neuroscience lock-up (they let us do that once in a while) and have been doing ML research for the last four years. But as a Metaverse Expert and t-shirt merchant you seem uniquely qualified to evaluate the trustworthiness of my statements about neuro and ML
3
2
34
@jbensnyder
This is an excellent point. All the studies I'm familiar with require training data for each individual, which is another limitation
6
0
33
Despite Gemini explicitly acknowledging the importance of data quality, I’m sure ML twitter will keep perseverating on the importance of architecture choices like the “efficient attention mechanisms” that the report also mentions

1
3
32
Congratulations to
@tyrell_turing
for winning the
@CAN_ACN
Young Investigator Award for 2019! It must have been very challenging to pick from all the amazing young Canadian PIs. Thanks to Blake & everyone who makes Canada's neuroscience community so wonderful to be a part of!
3
2
28
@finbarrtimbers
At
@MosaicML
we did it with Alibi + FlashAttention + 80gb A100s. No secret sauce, just well-vetted research. Shout-out to
@OfirPress
and
@tri_dao
for their great methods!
1
2
32
A summary and a few thoughts on SlimPajama 🧵

📣 New dataset drop!
Introducing SlimPajama-627B: the largest extensively deduplicated, multi-corpora, open-source dataset for training large language models. 🧵

14
191
685
1
6
29
QUARANTINE DOG UPDATE: We were out of hot dogs buns, so we added some to the Costco order. Costco didn't have buns, so they substituted...3 DOZEN HOT DOGS. We now have 52 hot dogs and no buns. But I think this is the madness what we all came here for.

3
0
28
To those saying "but what about the inexorable march of technological progress"
@paulg
I'm not saying it can never happen, just that it's probably not worth worrying about atm due to the logistics of generating the strength of magnetic field needed to do it.
1
1
16
1
2
30
The next 10x in efficiency gains will be from data curation
What's next for LLMs? Just go big? More data more parameters? Seems like maybe this path will be exhausted soon or too expensive
97
13
297
3
4
30

Next up: C4. Our initial exps showed C4 just performed _really_ well. But we wanted to push it! We used SemDedup (ty
@arimorcos
' group) to remove the 20% most similar documents within C4, which was consistently :thumbsup: in our exps

Web-scale data has driven the incredible progress in AI but do we really need all that data?
We introduce SemDeDup, an exceedingly simple method to remove semantic duplicates in web data which can reduce the LAION dataset (& train time) by 2x w/ minimal performance loss.
🧵👇
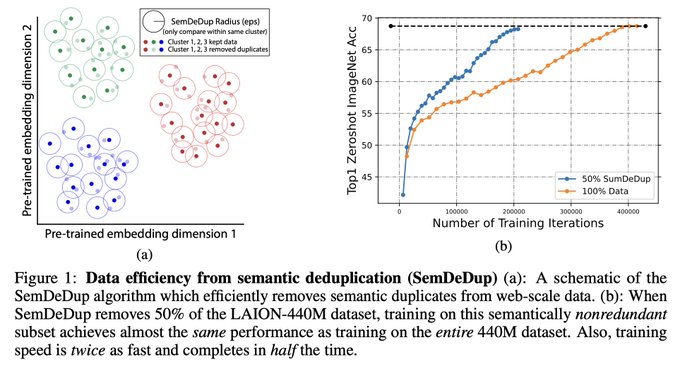
7
59
310
1
2
27
How do easily interpretable neurons affect CNN performance? In a new blog post,
@arimorcos
and I summarize our recent work evaluating the causal role of selective neurons: easily interpretable neurons can actually impair performance!
2
5
25
Quarantine Dog
#1
: double dog, Tillamook cheddar, sauerkraut, avocado, pickled ginger, Japanese mayo, yuzu kosho.

4
0
26
One of my favorite parts of our blog post announcing the
@MosaicML
ResNet Recipes () is the recipe card, designed by the talented
@ericajiyuen
. BTW these times are for 8x-A100

0
4
26
Gemini also continues the trend of training small models for looonger. As deep learning models transition from research artifact to production necessity, inference costs are going to increasingly dominate the economics. Llongboi just keeps getting llonger:
Ok, for those wondering about the origin of our nickname "Llongboi", here it is.
(
@jefrankle
got mad at me for putting this in the wild. Once it's free, it's free!)
1
0
22
1
0
26
All this talk of neural coding and computation by
@RomainBrette
@tyrell_turing
@andpru
@Neuro_Skeptic
et al. reminds me to remind everyone to read Paul Cisek's excellent (and imo overlooked) paper "Beyond the Computer Metaphor: Behavior as Interaction"
3
1
24
Good compute is terrible thing to waste, so
@abhi_venigalla
and I assembled some best practices for efficient CNN training and put them into a blog post.
New blog post! Take a look at some best practices for efficient CNN training, and find out how you can apply them easily with our Composer library:
#EfficientML
1
18
80
0
4
24
Hot take inspired by ConvNeXt : Grouped convs are overrated. They're popular bc obsession w/ inference throughput & raw accuracy, disregard for training cost, & FLOPs-hacking. Vanilla convs are pareto-superior unless training is ~free relative to inference
1
1
21
Like
@OpenAI
,
@BuceesUSA
offers employees PPUs instead of RSUs and has a capped profit model because the success of their mission will be so transformative to society that it would be unethical for them to capture all of the resulting value

At $125k+, the car wash manager at a (very large) gas station in rural Texas makes more than most doctors in Europe.

644
676
10K
1
3
23

Gemini Ultra training was distributed across datacenters! Model parallel within SuperPods (and datacenters) and data parallel across SuperPods (and datacenters)! This is impressive in part because gradients are notoriously shy and reluctant to leave their home datacenter.

1
1
22
Can't explain why, but wearing a suit to walk my dog during a pandemic makes me feel LESS unhinged.
Stay fitted, stay sane 💕😷

1
0
21
Very excited to see
@MosaicML
used as a baseline, especially by work from
@aleks_madry
's lab. It showcases the massive speedups that can be achieved by combining thoughtful modifications to the training algorithm + well-applied systems knowledge. Eagerly anticipating the paper!

ImageNet is the new CIFAR! My students made FFCV (), a drop-in data loading library for training models *fast* (e.g., ImageNet in half an hour on 1 GPU, CIFAR in half a minute).
FFCV speeds up ~any existing training code (no training tricks needed) (1/3)
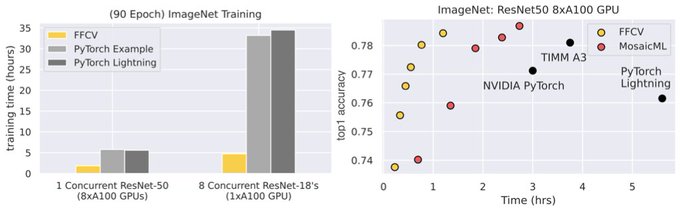
29
390
2K
0
1
22
Excited to for my
#neuromatch2020
talk, today at 4pmPST/7pmEST/11pmGMT. It's a summary of my recent work with
@arimorcos
. If you miss free samples at the market, this is the next best thing. Come taste our work & if you like it read the paper!
Class selectivity is often used to interpret the function of individual neurons.
@arimorcos
and I investigated whether it’s actually necessary and/or sufficient for deep networks to function properly. Spoiler: it’s mostly neither. (1/10)
6
34
108
1
1
20
Big thanks to
@KordingLab
,
@bradpwyble
, &
@neuralreckoning
for organizing
#neuromatch2020
,
@DavideValeriani
for moderating my talk, & everyone who asked questions (no idea who, plz say hi if you wish). The experience has been a potent salve for the Coronavirus Blues!
Excited to for my
#neuromatch2020
talk, today at 4pmPST/7pmEST/11pmGMT. It's a summary of my recent work with
@arimorcos
. If you miss free samples at the market, this is the next best thing. Come taste our work & if you like it read the paper!
1
1
20
1
0
21
@code_star
,
@_BrettLarsen
,
@iamknighton
, and
@jefrankle
(yes, our Chief Scientist gets his hands dirty) put in a TON, and we couldn’t be happier with how the MPT-7B series of models turned out. And we're just getting started.
2
0
21

~2yrs ago
@nsaphra
came to my poster & we discussed regularizing to ctrl interpretability. She mentioned a superstar grad student (
@_angie_chen
). Things really got wild when
@ziv_ravid
joined the party. And
@kchonyc
graced us w/ wisdom throughout. V excited to finally announce:

New work w/
@ziv_ravid
@kchonyc
@leavittron
@nsaphra
: We break the steepest MLM loss drop into *2* phase changes: first in internal grammatical structure, then external capabilities. Big implications for emergence, simplicity bias, and interpretability! 🧵

2
62
351
1
3
20
My mom had to cancel the education conference she was organizing 😭 but got v excited when she heard about
#neuromatch2020
and wants to organize something similar.
@bradpwyble
@neuralreckoning
@KordingLab
@titipat_a
et al., do you have resources or a "how-to"? ❤️❤️❤️
3
0
17
This is why I went to grad school

The original LLongboi (drawing by
@leavittron
) secretly meming this code name into existence is one of my proudest moments at
@MosaicML
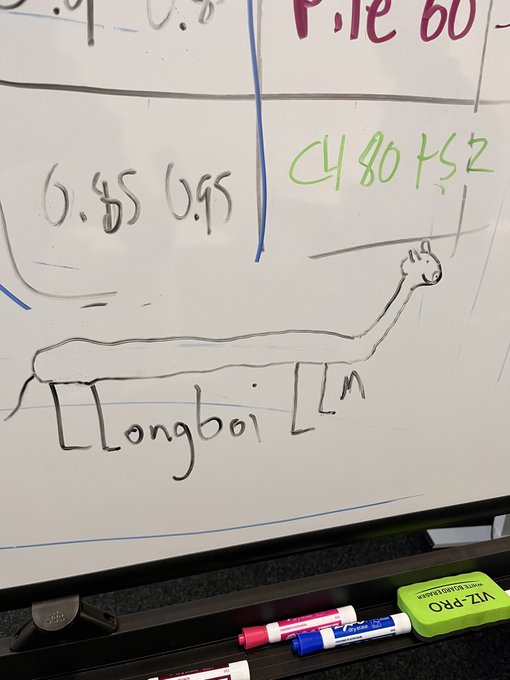
2
3
28
2
0
20
It's nuts how often I see slack notifications that we closed a new customer. Those three sales reps,
@barrydauber
,
@mrdrjennings
, and
@stewartsherpa
, are UNSTOPPABLE. Glad to see their hard work being recognized!
2
2
18
A haiku for the research scientists, at
@hanlintang
's suggestion:
Don't want to be here
Please don't, no kubernetes
So much to live for

0
3
19
I agree that not having experience training neural networks/not knowing the math underlying them shouldn't auto-invalidate one's AI takes. But "my AI takes are valid because deep learning doesn't use Real Math" is worse than wrong (more on that below) and weirdly fetishizes math

Would-be AI gatekeepers: YoU caN't saY aNythIng abOUt AI unLess yoU -
Look, I *remember* when AI used to involve math, maybe not Actual Mathematician Math, but at least nontrivial computer science. Modern deep learning is calculus for bright eleven-year-olds, plus the first
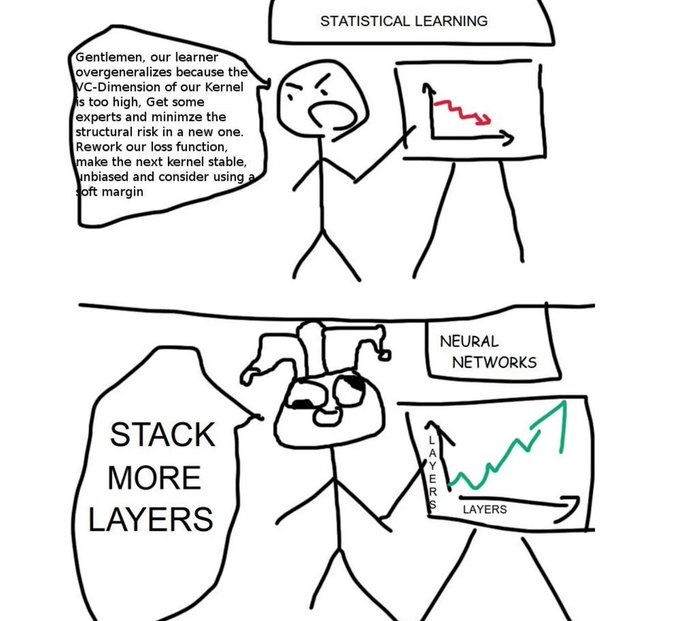
125
150
2K
1
2
19
Very excited to announce that our work received a Spotlight Rejection at
@NeurIPSConf
#NeurIPS
v excited to finally announce our new work that formalizes one of the most effective practices for training LLMs—something that many industry leaders have conspicuously avoided discussing
19
97
895
0
0
19
"I want to see blood. We all want to see blood" -
@KordingLab
.
I've got to say, so far the worst part of
#neuromatch2020
so far is that
@KordingLab
can't spice up the debate by sliding
@tyrell_turing
a folding chair when Cisek has his back turned.
1
0
19
Zack worked his ass off for this paper and the reviewer responses (like he works his ass off for everything). This is extremely disappointing and I think this policy causes more harm than good.

My EMNLP paper got desk-rejected post-rebuttal because I posted it to arxiv 25 minutes after the anonymity deadline. I was optimistic about our reviews, so I spent a whole week while visiting my family writing rebuttals and coding experiments to respond.
3
28
187
0
0
17
Thrilled to have contributed to this. And excited to see what the community does with it!
Meet MPT-30B, the latest member of
@MosaicML
's family of open-source, commercially usable models. It's trained on 1T tokens with up to 8k context (even more w/ALiBi) on A100s and *H100s* with big improvements to Instruct and Chat. Take it for a spin on HF!

17
129
550
1
0
17
@finbarrtimbers
@MosaicML
@OfirPress
@tri_dao
We pretrained at 2048 then fine-tuned on 65k. We tried generation up to 84k. There are trucks we could use to push it further, but we wanted it to be simple for others to use. Dunno if you saw, but we used it to generate an epilogue to The Great Gatsby:
2
0
18
Overall, the tools & dataset are great for the community. I'm glad people are realizing that data work is valuable and not dismissing it as low-status.
9 out of 10 pediatricians recommend not feeding your child trash. I hope the ML community soon feels this way about LLMs🤞🤞🤞
0
0
16
@paulg
I'm not saying it can never happen, just that it's probably not worth worrying about atm due to the logistics of generating the strength of magnetic field needed to do it.
@marcbeaupre
You need to generate 3-7T of magnetic field strength, which requires a large magnet, lots of power, and helium cooling. I dunno what the physical limits are on magnet size for field generation; also power consumption/dissipation seem like big issues
5
2
60
1
1
16
ML conferences will ban submissions using generative LLMs, but they won't ban submissions with the title "x is All You Need" or "Intriguing Properties of x"
4
1
18
@andpru
@KordingLab
Most of what I learned in my PhD was conveyed implicitly, and even the explicit channels were typically code comments or oral history. I had a course on "research conduct", but that was basically "Retraction Watch's Greatest Hits".
1
2
15
My man was crazy close. Someone give him a prize. Real numbers are 340B and 7e24 FLOPs.
@CNBC
doesn't need to wait for leaks, they should just ask
@abhi_venigalla
.
Alright who wants to try and guess the compute/cost/params for PaLM2-L?
No prizes (b/c obv I don't know) but with enough responses we might get a reasonable estimate (which is reward enough 😝)
I'll start:
* 6e24 FLOPs
* $22M
* 250B params
paper:
14
8
79
1
2
17


This data mix was a bit of a hedge, but it seems to have turned out quite well. We're excited about what will happen as we get more scientific and methodical about data. The field overlooks data research, and we're working to fix that.
1
0
16
Does this make early stopping analogous to eating veal?

it may be that today's large neural networks are slightly conscious
453
562
3K
2
1
15
Big shout out to
@CerebrasSystems
for building the tools and dataset and releasing both. Very glad that data work is getting the attention it needs. Though I don't see the tools anywhere on your github. Am I looking in the right place?
📣 New dataset drop!
Introducing SlimPajama-627B: the largest extensively deduplicated, multi-corpora, open-source dataset for training large language models. 🧵
14
191
685
1
0
16
Next up: RedPajama is
@togethercompute
’s commendable attempt to recreate the LLaMa data. Many of their sources (e.g. Wikipedia, StackExchange, arXiv) are already available as ready-to-use datasets elsewhere, but RedPajama contains data through 2023—the freshness is appealing
1
0
15
Studying neuroscience doesn't make you a neuroscientist.
Actual neuroscientists...
- draw the Felleman and Van Essen diagram from memory
- compute XOR in single astrocytes
- reconstruct detailed biographies from c-Fos levels
- optogenetically induce consciousness in macaques

Studying Immunology doesn’t make you an Immunologist.
Actual Immunologists...
- know the name and function of every single cytokine in existence
- never clog the cytometer
- love both T and B cells equally
- are immune to all diseases
9
22
174
0
1
15
One very relevant consequence of token budgets increasing is that the need for data curation also increases! The quantity (and possibly even proportion 😱) of redundant, noisy, and misleading examples increases with the size of your dataset!
1
0
16
@SpiderMonkeyXYZ
I'm familiar with the study. It's great research! What I'm calling bullshit on is the idea that that "your thoughts aren't safe" or that you should be concerned about someone stealing your dreams
1
1
13
Would be great for someone to build some data curation tools suited to contemporary pretraining practices

Great work! Once again, it highlights the implicit repetition of training tokens.
While the Chinchilla law is commendable, it's clear it won't endure indefinitely. As models grow larger, the Language Model (LLM) assimilates knowledge from implicitly repeated tokens. This is
0
9
67
1
0
15
@ruthhook_
Maybe "intelligent" people just introspect more, complain more, or have more medical care
0
0
13
Bad news: that's just a dummy model being used to test our new hardware
Good news: our new hardware are H100s
1
0
15
I contributed to this and it feels good. Use it for SSL + transformers, then tag me in the github issue if you run into problems!

Introducing VISSL () - a library for reproducible, SOTA self-supervised learning for computer vision! Over 10 methods implemented, 60 pre-trained models, 15 benchmarks, and counting.

10
257
1K
0
0
15
TFW a full research team at Google scoops your grad project. At least you know it was a good idea!

Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet
pdf:
github:
transformer-style networks without attention layers make for surprisingly strong image classifiers
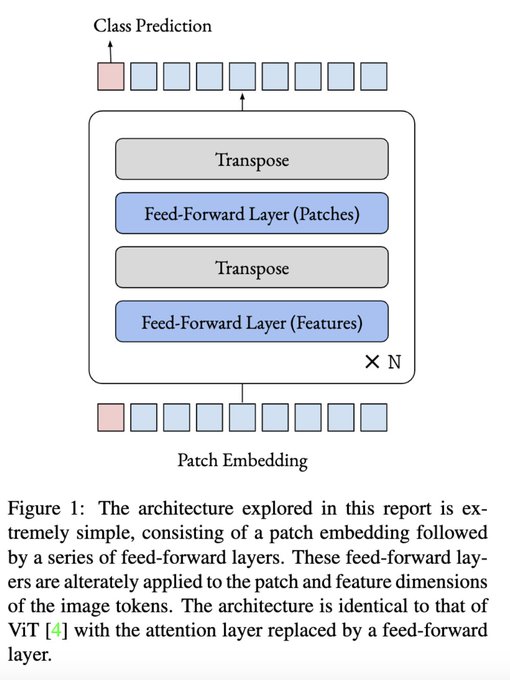
4
63
332
0
0
15
My soccer team composed entirely of coaches will be unbeatable

Tough news for FAANG engineers:
Startups don’t want you anymore
Every founder I’ve spoken to is tired of them. Instead, they’re hiring ex-founders— engineers who value ownership and grinding to win
191
111
2K
0
0
15
@PsychScientists
Coffee is actually very high-dimensional and this is what happens when you project it into two dimensions. It actually goes quite nicely with the Swiss Roll problem. Some people recommend using tea-SNE, but it's just not the same.
0
0
14
I'd say Harvard won the lottery here, but I think the real beneficiaries are everyone who gets to work with you. Congratulations, Jonathan!
0
1
14