
Naveen Rao
@NaveenGRao
Followers
31K
Following
13K
Media
65
Statuses
4K
VP GenAI @Databricks. Former CEO/cofounder MosaicML & Nervana/IntelAI. Neuro + CS. I like to build stuff that will eventually learn how to build other stuff.
Joined February 2009
What many don’t realize is, on the other side of a ChatGPT session is a $150k server that costs ~$16/hr. The server goes 24hrs/day and can time slice efficiently. But the economics of scale aren’t that different from a human. AI won’t be free like search was, at least not for.
295
747
7K
The biggest personal win for me with ChatGPT is that my kids finally respect what I do for work 😂.
32
75
3K
@LanaLokteff Ignorance alert. Indians are rarely, if ever, considered minorities in the US in terms of aid. Having only grown up in the US (but of Indian heritage) I can say there are many reasons Indian immigrants do well here. Hint: has nothing to do with nepotism.
12
126
2K
If all this gzip == LLMs talk continues, we might actually start teaching data structures in computer science again.
17
77
1K
Thread on my observations about the Dojo presentation at Tesla AI day 2022 👇. Generally, some ambitious goals and great progress! .Tesla is masterful at presenting their tech by intermingling real progress with projections. I try to cut through below.
27
158
988
So. today I started a new company 😀 If you're interested in changing the field of AI through software and algorithmic innovations, DM me. Let's do something. wonderful!.
66
38
964
Announcement: I'll be investing $3B into Anthropic. It seems like the thing to do.
73
39
935
I don’t think everyone has comprehended the massive disruption and distortion that is going to happen in the Gen AI market due to Llama3. Moats will be destroyed and investments will go to zero. Just like everything in Gen AI, this will all happen fast.
39
108
833
@LanaLokteff What Indian has ever cried that??. Those folks can do well in India. They can do better here. The aspect of our country that it keeps it at the top is immigration of best and brightest. If those people don’t want to come here, the country will lose its edge.
8
51
756
A true intelligence test 😂 Bet your neural network can't get this one right!

24
134
748
🤯🤯 LLM trained with 64K+ context length! What could you do with that? Prompted our model with the ENTIRE contents of "The Great Gatsby" and asked it to write the epilogue. Snippet 👇. Model dropping soon to an open-source repo near you. Epilogue:.It seemed to me that Gatsby.
41
84
663
Damn right.


31
10
642
Today we’re announcing plans for @MosaicML to join forces with @databricks! We are excited at the possibilities for this deal including serving the growing number of enterprises interested in LLMs and diffusion models.
56
65
643
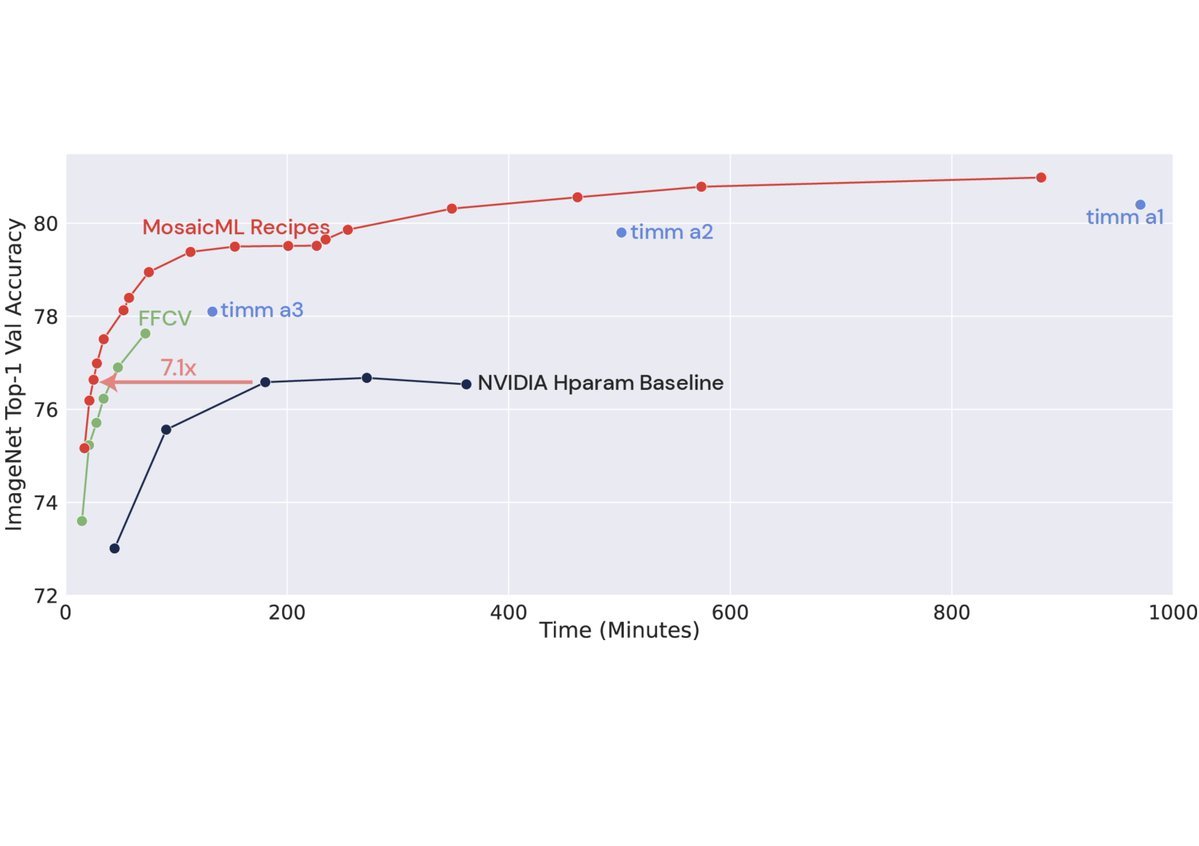
Would you rather invest $200m+ into a new computing arch and get maybe 2x perf, or <$5m and get 7x with better algos?.We @MosaicML did just that! We released Mosaic ResNet and it achieves SOTA perf in just 27min on standard HW. You read that right👇
8
61
556
Can someone make an LLM that takes in Python and spits out optimized [X86, ARM, RISCV, *] assembler code?. That would be so cool. it could even go from [Python, C++, Java, *] to native assembler. Instruct fine-tune it to make PIC or arch-specific optimizations.
94
31
551
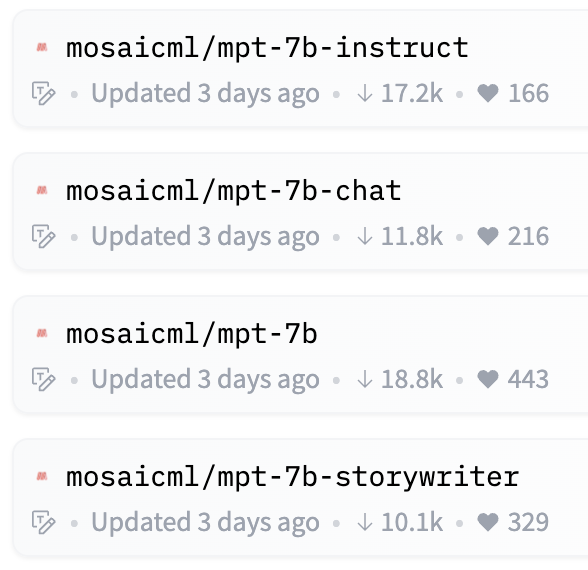
MPT-7B (aka Llongboi) released! The BEST open LLM on which to build!. -Apache 2.0 license suitable for commercial use. -Base 7B LLM trained on 1T tokens outperforms LLaMA and GPT3. -64K+ context length. -$200k to train from scratch.

📢 Introducing MPT: a new family of open-source commercially usable LLMs from @MosaicML. Trained on 1T tokens of text+code, MPT models match and - in many ways - surpass LLaMa-7B. This release includes 4 models: MPT-Base, Instruct, Chat, & StoryWriter (🧵).

22
91
543
LLMs pass/will pass most professional cert exams (Bar, USMLE, CFA, etc). You can interpret that to mean we're close to AGI. or that those exams have gaping holes in ascertaining readiness for a field. I'm thinking the latter.
45
40
501
@martin_casado As much as I love my field, it's littered with anthropomorphizing results. We all want to believe that it's reasoning, and if I see evidence that looks like it's reasoning, we declare victory. It was always clear that these models estimate conditional probabilities and don't.
24
33
489
Prediction: all closed AI model providers will stop selling APIs in the next 2-3 years. Only open models will be available via APIs. Why? For an open model service, the value prop is clear. it's hard to build a scalable service to access the model and the model is commodity.
57
67
497
Ok, this site is getting really messed up now that @elonmusk has gone full wingnut politically. Out of morbid curiosity, I look at some of the crazy right posts. It's full of account like @VoteHarrisOut . it's an account that started in Aug 2023 and has sent nearly 44k tweets.
55
31
433
It’s official! The biggest venture round in history. And I feel like we’re just getting started….
26
44
489
@okito 10x, yes. We and others are working on more efficiency. New hw will have features that help. We'll be 10x by year's end. Longer term, with the death of Moore's Law, it gets more difficult. Smaller models w/ some clever precomputing of results is needed. 100x might be much longer.
35
17
426
When we started @MosaicML we wanted to bring choice and cost reduction in AI to everyone. Today we've demonstrated that our stack fully supports @AMD Mi250! And it does it with good performance making it a viable alternative to Nvidia GPUs for cost/perf. We believe that, when.
Introducing training LLMs with AMD hardware!. MosaicML + PyTorch 2.0 + ROCm 5.4+ = LLM training out of the box with zero code changes. With MosaicML, the ML community has additional hardware + software options to choose from. Read more:

10
59
418
This might be the dumbest thing I’ve read this month. Bravo.

The last century was defined by how quickly we could invent and deploy everything. This century will be defined by our ability to collectively say NO to certain technologies. This will be the hardest challenge we’ve ever faced as a species. It’s antithetical to everything that.
28
20
404
@karpathy Wow congrats Andrej! I hope you can continue doing some of you open-source stuff and tutorials. the world needs more of that!.
6
1
385
I gotta say, this is the money plot. This is what we wanted to do!.

And yes, you can switch back and forth between NVIDIA and AMD, even within a single training run. It's Christmas in July!🎄

12
24
373
Meet our new AI, #DBRX. DBRX is an advance in what language models can do per $. These economics will have profound impacts on how AI is used, and we've built this to democratize these capabilities!. It's the best open model in the world. It closes the gap to closed models in a.

Meet #DBRX: a general-purpose LLM that sets a new standard for efficient open source models. Use the DBRX model in your RAG apps or use the DBRX design to build your own custom LLMs and improve the quality of your GenAI applications.
17
62
367
Everyone keeps asking in this downturn in VC "where's all the dry powder going to go?". It's all going to large-scale and generative AI. All of it.
22
45
349
Elon taking over twitter reminds me of times I've taken over someone else's code. At first: "this is horrible and SO dumb!! how could they do that?!". After trying and failing to reimplement it: "oh. THAT'S why they did that. " 🤣.
13
20
308
Contrarian view: @sama is actually doing the right things with Open AI. He has the impossible job of taking an ideologically driven research group and trying to make it into a product company. Goals aside, if he didn't do this, investment would stop. Arguably, some of this issue.
28
17
308
Any AI researchers or engineers feeling uneasy about the future, we are hiring at @databricks / @MosaicML !.
9
36
286
Well, that was fast! We (@MosaicML) released a SOTA result on MedQA just a few weeks ago and @GoogleAI now beat it soundly. It is incredible how quickly human performance is being commoditized. this essentially passes the USMLE. BTW, we did this with 1/200th of the parameters. .

Delighted to share our new @GoogleHealth @GoogleAI @Deepmind paper at the intersection of LLMs + health. Our LLMs building on Flan-PaLM reach SOTA on multiple medical question answering datasets including 67.6% on MedQA USMLE (+17% over prior work).

6
25
287
Twitter really is its own universe. All I see here are "ChatGPT/OAI will rule everything!" and "no other model matters!". I think VCs internalize this. The real world is "I need to control my model's output and want to train/fine-tune my own." "I don't want to copywrited.
22
26
283
Just like that, "compute" has been redefined from fast instructions for applications -> mult-accum operations for AI. 2021 was the peak revenue for Intel ($79B) vs Nvidia ($27B). Replacement cycles for hardware are a couple of years and in 2023 we see Intel at $54B vs Nvidia at.
12
45
253
Most outsiders looking at the AI/LLM world don’t understand that there really isn’t much insight behind the claims of “AGI is nigh!” other than “let’s just keep making it bigger and see what happens”.
15
30
251
The term "AGI" might have done more damage to the AI field than anything else lol. Human (or any animal intelligence) is NOT general; it's very specifically constrained. Generality would require too many observations to fit to; constrained intelligence learns the right stuff to.
30
33
250
I hope this thread was useful. Follow me for updates on AI silicon, AI trends, and building real AI systems!.
15
2
245
@jack Honestly this makes a lot more sense than any of the web3 rhetoric. Decentralized serving of information is doable and solves a real problem. This is a technology solution and doesn't need to be portrayed as some savior to all the world's problems.
11
12
234
I’m tired of the Open AI drama. The only thing that is clear is they need some proper corporate governance.
16
9
247
Wow, this is a huge moment in the world of computing. It shows 1) the importance of holistic systems approach to computing, 2) as predicted, AI is redefining computing. Going all-in on AI was Nvidia's best move.
7
54
233
Before getting to Dojo, an interesting observation on Optimus is a 2.3kWh battery is equivalent to ~2000kcal, which is the amount of energy humans burn in a day. It does seem they are able to find synergies between making cars and bots (as predicted).
3
16
232
Wow. in just 4 days the MPT-7B series of LLMs from @MosaicML was downloaded nearly 60k times! And I've seen cool apps things built on it. You guys are amazing!. Keep building! We love it!❤️
4
28
234
Well the belief was fun while it lasted! Sparks don’t always lead to fire I guess.

New paper by Google provides evidence that transformers (GPT, etc) cannot generalize beyond their training data

22
24
229
I have a massive respect for @vkhosla but this a short-term, inaccurate view. All the comments describe how China is already at the SOTA for LLMs. You can not stop information flow. The only way to stay ahead is to create a social/political environment that encourages.

The reason to keep it behind is so the Chinese don’t access new breakthrus and scale them. The risks in the techno economic was with china outweigh any of the sentient AI risks by orders of magnitude. And they will be interfering in our elections in 2024 to influence voters with.
15
14
226
Leaving the UK after the AI Safety Summit in Bletchley Park. Some thoughts:. I got a good sense of the zeitgeist from this meeting. The motivation for law makers and governments is to make people feel safe. There is a sentiment that AI will be dangerous (likely driven by FUD.
11
46
221
This. This is why we do what we do @MosaicML. Enabling a small team (@amasad mentioned it was 2 people!) to build a state-of-the-art model with our stack makes me so happy!. Small teams using Mosaic ML to build AI is the future. @Replit and @MosaicML share the goal of enabling.

.@Replit just announced their own LLaMa style code LLM at their developer day!. replit-code-v1-3b. - 2.7b params.- 20 languages.- 525B tokens (“20x Chinchilla?”).- beats all open source code models on HumanEval benchmark.- trained in 10 days with @NaveenGRao @MosaicML


4
14
225
This is very cool! Thanks @MetaAI!. From what I can tell, this is a GNU license, which means fine-tuned models all must be upstreamed. For corporates, this is challenging as fine-tuned models on proprietary data will need to stay with the company. @MetaAI any idea if there are.

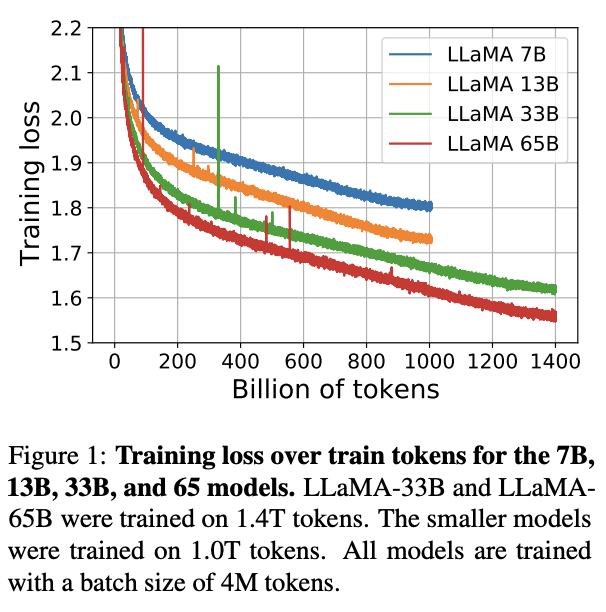
Today we release LLaMA, 4 foundation models ranging from 7B to 65B parameters. LLaMA-13B outperforms OPT and GPT-3 175B on most benchmarks. LLaMA-65B is competitive with Chinchilla 70B and PaLM 540B. The weights for all models are open and available at 1/n

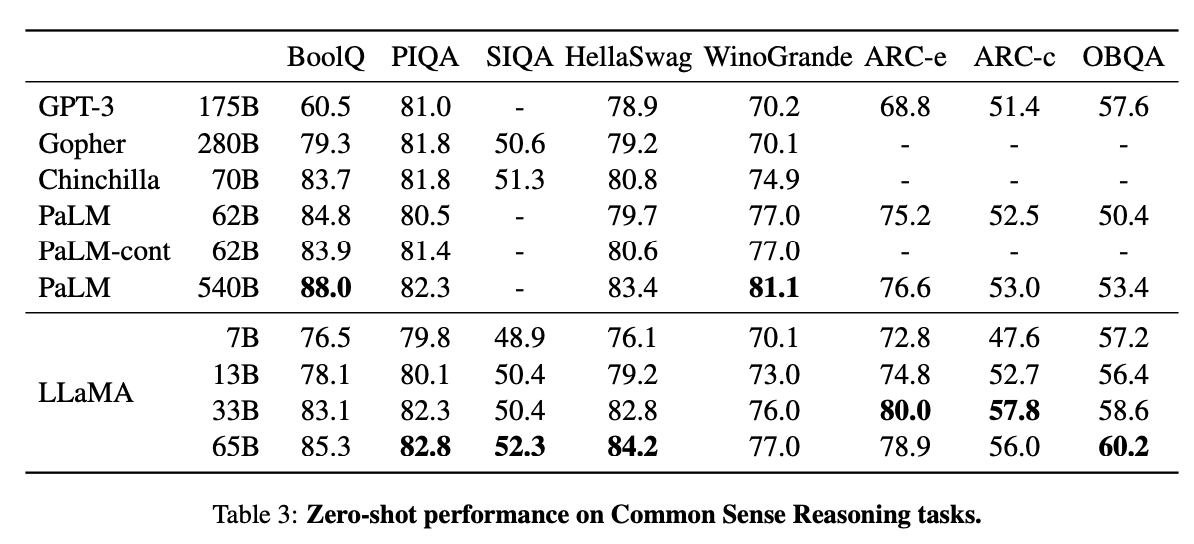
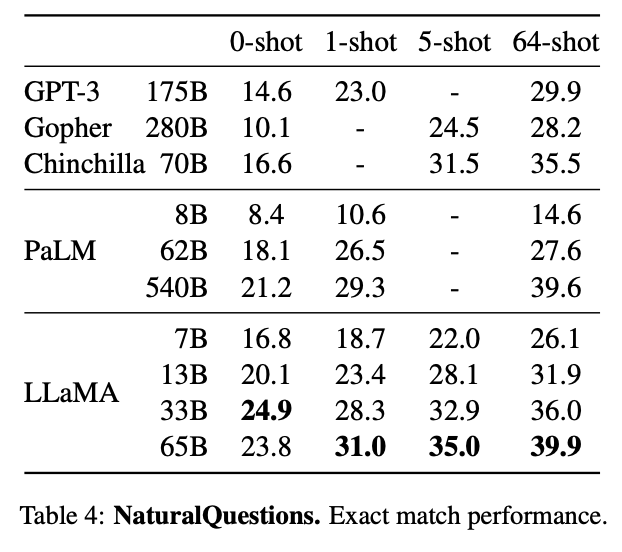
7
21
218
Can someone explain to me what "PhD level" questions are? A PhD is all about discovering new knowledge and the process therein. It's not some grade achieved by taking an exam.

NEW w/ @coryweinberg:. OpenAI is doubling down on its application business. Execs have spoken with investors about three classes of future agent launches, ranging from $2K to $20K/month to do tasks like automating coding and PhD-level research:.
32
5
222
Let's demystify LLM serving on GPUs! Here we did a thorough analysis of latency/throughput tradeoffs, time to first tok, relationship to model size, quantization, and general concepts to be aware of. Enjoy! @MosaicML @databricks .
3
33
205
Funny how so many self-proclaimed AI experts seem to think that prompts to an LLM or diffusion model actually change the weights. Hint: prompts don’t change weights.
36
12
201
It's rare as an adult to feel the same level of excitement you felt as a kid. Tomorrow is one of those days!.
12
11
205
Agreed. There is no moat with any particular LLM. No one is more than a year ahead of others in the group of model builders. Open source does NOT threaten the technology ecosystem of the west. Let’s please stop with the straw man arguments.

Repeat after me: AI is not a weapon. With or without open source AI, China is not far behind. Like many other countries, they want control over AI technology and must develop their own homegrown stack.
6
28
189
Here's the (literal) money blog! @MosaicML is the FIRST company to publish costs for building Large Language models. These costs are available to our customers to build models on THEIR data. It IS within your reach: <$500k for GPT3!.
5
39
190
While ChatGPT gets the headlines, I think @natfriedman and Copilot have had a bigger impact on startups. Everyone is pitching “copilot for X” (finance, doctors, etc). I haven’t seen that since everyone was pitching “Uber for X” 7-8 years ago.
12
11
192
@pentagoniac Agreed that search isn't free. It is delivered without cost to the user through other monetization. Very clever and amazing. But AI costs are much higher, so I'm doubtful the same monetization will work. I see a world where we pay differential value for better AI. It's not bad,.
16
6
186
@thegrahamcooke Sorry, this doesn't disrupt much. I think there's a fundamental misunderstanding of why the best/largest models are in the cloud. Building pared-down models for edge is a different market with some advantages. But it is a different buying pattern.
3
2
185
Can someone build an LLM that takes in all restaurant reviews, is fine-tuned on MY restaurant takes, and gives me a narrative on whether I'd like a restaurant or not?. IOW, make reviews actually usable.
16
1
187
Overall, Tesla is focused on density for a reason. Hard to make density work reliably, will be harder than let on (will take years). As a HW geek, I love the ambition…and I think Tesla has good reason to try. At $500m/yr, might have an advantage in a 2-3 yrs, execution critical.
3
7
186
Startups, need model training and serving compute to get to those end-of-year goals? DM me!. We❤️ our startup community @MosaicML/@databricks and want to see all the great GenAI products accelerated!. I'm willing to steal GPUs from our own research efforts (@jefrankle might hurt.
12
15
187
The official tweet thread and blog:.

25
10
185
This was 10 years ago today. the first office of Nervana (founded Feb 25, 2014). Nervana was the first AI chip startup and signaled a sea-change in compute to AI. It represents when compute "went neural". 10 yrs seems long, but the amount of change has been astounding!

12
9
185
Sorry, there's just no way senior leaders didn't know about these separation terms at OAI. Those terms don't just appear there; they were requested. Esp with the non-standard PPU structure, none of those terms are just "standard". I wish they would just say "sorry, bad call.

Scoop: OpenAI's senior leadership says they were unaware ex-employees who didn't sign departure docs were threatened with losing their vested equity. But their signatures on relevant documents (which Vox is now releasing) raise questions about whether they could have missed it.
7
9
182
I'm sure everyone wants to read about @databricks/@MosaicML inference stack over the holidays, so here ya go!. Serving Mixtral from @MistralAI and MoE (in the works for some time): Collaborating w/@nvidia and building upon TRT-LLM for inference:.
3
23
181
So I'm going to have to disagree here. as a musician, I don't find these AI generated songs to be very good. Music & lyrics are hard because you need so much context of being a human to get it all right. This AI generated stuff is super generic and could be useful as "filler".

Amazing text to music generations from @suno_ai_ , could easily see these taking over leaderboards. Personal favorite: this song I fished out of their Discord a few months ago, "Return to Monkey", which has been stuck in my head since :D. [00:57].I wanna return to monkey, I
64
9
180
Lessons learned after being in AI HW for 8+ years…. Every chip startup talks about perf. It was the game 4 years, but now we need to look at perf/$. If I were to build a new AI chip today, it would be built out of the cheapest technologies I could find. Let me explain:.
14
30
177
LLMs/ChatGPT are much more similar to StableDiffusion/Dall-E than search engines as they can fill in plausible details based on loose descriptions. Precise recall from loose descriptions is a different problem but will unlock A LOT more enterprise value!.
12
29
172

It's official! Mosaic Doges are Bricksters! We're all very excited to be part of @databricks and to build the future of #GenAI for the enterprise. Thanks to @alighodsi and rest of Databricks for the belief in @MosaicML's vision. Let's go!!.
📢 Today, we're thrilled to announce that @Databricks has completed its acquisition of MosaicML. Our teams share a common goal to make #GenerativeAI accessible for all. We're excited to change the world together! . Read the press release and stay tuned for more updates:
8
11
175
This is good thread on where we are as an industry with LLMs. I can tell you from experience that enterprises absolutely want high levels of customization. Databricks + MosaicML enables this path from raw data -> filtering/ETL -> building models -> serving models.

The ChatGPT hype cycle:.- Stage 1: "GPT-X is out-of-the-box magic!".- Stage 2: "We need to use our data" (where we are now).- Stage 3: "We need to develop our data". From 2 -> 3, enterprises will realize not enough to just dump in a data lake. use case-specific dev is key!👇🧵

3
28
167
LLMs are the moment that all of tech has been waiting for for 40 years. In some weird way, LLMs have been pushing us to build the substrate for them to exist. The NEED all of the networking breakthroughs to move data and interconnect compute. They NEED the density of.
10
10
166
Boom! Another month, another drop! We love seeing what the community did with MPT-7B, and now we went bigger. Go play on @huggingface Under the hood, this is running on @mosaiml's inference service. You'll notice it's pretty snappy! Also, this is also one.
Meet MPT-30B, the latest member of @MosaicML's family of open-source, commercially usable models. It's trained on 1T tokens with up to 8k context (even more w/ALiBi) on A100s and *H100s* with big improvements to Instruct and Chat. Take it for a spin on HF!

7
33
161
I support open source for AI! We need to be sure to enable many researchers to solve the big problems in the field.

1/ We’ve submitted a letter to President Biden regarding the AI Executive Order and its potential for restricting open source AI. We believe strongly that open source is the only way to keep software safe and free from monopoly. Please help amplify.




9
21
162
We aren’t just about LLMs. The world is multi modal! Congrats to the @MosaicML / @databricks team to get this on ArXiv and establish a new standard for use. So much exciting work coming out!.
3
28
159
They currently have 14k GPUs. This costs ~$300m and ~$50m yearly to maintain. That probably sets the floor for the DOJO investment. This is big, but not that big. AWS deploys 10x of this every year.
5
8
158
One of the biggest issues in the AI field is not understanding what is a 1 yr problem, 5yr problem, or 10+ yr problem. Some things are A LOT harder than other things. .
10
16
158
10 months ago I tweeted that we were getting a new project off the ground…today I’m proud to announce with @hanlintang @jefrankle and @mcarbin that MosaicML comes out of stealth! We are focused on the compute efficiency of neural network training using algorithmic methods.👇.
Hello World! Today we come out of stealth to make ML training more efficient with a mosaic of methods that modify training to improve speed, reduce cost, and boost quality. Read our founders' blog by @NaveenGRao @hanlintang @mcarbin @jefrankle (1/4)

25
19
156
Today we are launching a new product category, the Data Intelligence Platform. It’s the next evolution of a data platform designed from the ground up to make data interactive. The promise of generative AI enables this and I’m excited to see enterprises be able to leverage all the.
2
22
152
Training a single AI model can emit as much carbon as five cars in their lifetimes - MIT Technology Review. Interesting and eye-opening analysis
10
83
143
What's clear now is that EVERY business, engineering, and design process will be changed by AI in the next 5 years. Don't believe me? Look at SW development. Prompt eng isn't enough for domain-specificity. Adapting LLMs to a domain should be in the hands of domain experts. This.
11
21
154
At the risk of adding to Grok's training data. I played with Bard and sent it this prompt: "There are 3 gears of sizes 12 teeth, 20 teeth, and 30 teeth. The 12 tooth gear is meshed only with the 30 tooth gear. The 20 tooth gear is meshed only with the 30 tooth gear. If the 12

18
10
148
Lol what prompt was used to make this bot work? I'm beginning to think that >90% of politics on X are LLM generated.
13
9
136
Really excited to be supporting @Replit and @amasad in their efforts to build a special purpose LLM for their needs! Check out how they used @MosaicML and @databricks to accomplish this:
1
23
149
Light travels ~1 foot in 1 nanosec. This sounds fast, but at 1 gigahertz that’s 1 cycle per foot not accounting for other system delays. When a chip wants to access memory physically distant, it has to wait for the data to move. This is why Tesla focuses on physical packing.
9
8
142
@mustafasuleymn No, we’re not. This doom and gloom prediction has been made for years, but it misses a fundamental understanding of humans. Humans will never exist in a “post work” regime…we need purpose and will endure pain to get it.
18
5
144
DOJO technology points. “No limits philosophy”. -Shared, flat mem space, focus on SRAM. -Packaging for density. -Model parallelism not data parallelism. -Unbounded scaling. If model won’t fit, use more chips. -Vertical integration of data center…cooling, management, power.
2
6
140
We're about to see a huge number of RL innovations after Deepseek! All of those researchers in academia or small labs that couldn't work on pre-training (lack of budget) will be unleashed on all the open-source base models. I think the afterburners just got turned on for AI.
7
16
138
This is kind of a problem. It reminds me of how Microsoft in the 90s used to track how much money their customers made as a figure of merit. That's really the only way to understand how durable a revenue stream is.

You give me $50 billion to buy Nvidia chips and i’ll give you $3 billion (in revenue, which i’m still posting a loss on)

11
8
140
Video neural net training. Mentioned it is 100,000 GPU hrs to do a training run. They seek a 30x improvement to get to 1 day latency. It shows the impact on productivity on training latency. Large lang models use millions of GPU hrs, so these are not the most intensive workloads.
1
5
135
Holy crap! I REALLY would not want to be an Nvidia competitor right now. Happy to be a user this time around :).
13
7
133
Excited to be driving in 24h of Le Mans in June with @COOLRacing ! We'll be donning an all @databricks livery. I think it'll really pop on TV :). 🏎️🏎️🛞.

Le Mans Livery Alert 🗣. COOL Racing's #47 LMP2 has been given a makeover for the 24 Hours of Le Mans on 15-16 June 🇫🇷.We are delighted to run under Databricks colors in La Sarthe this year. #COOLRacing #CLXMotorsport #LeMans24



11
10
132
This message from @ID_AA_Carmack hit home. I felt similarly at Intel. More resources were never enough. Is this the only possible state for large corporate orgs to exist? Is there a better way to build? I've read a number of books on this and still no answer.


13
5
126
Software will NOT eat the world when it comes to AI. The fundamental balance of compute and software is different with AI. To understand the differences and their implications we must dig into the profound statement that @pmarca made in 2011.
7
14
129

The single most important thing that @sama did was craft a narrative that appeals to people who wanted to "go for it" in AI. It's part academic curiosity, part anarchist, part desire to good in the world. Not sure that'll be sustained in MSFT.
13
6
127
This is not a new concept. Caches already do this within a chip. What’s difficult is doing this at the rack and datacenter level. Technologies like RDMA from Mellanox/Nvidia do this now, but Tesla wants to do it cleanly. What’s the challenge? The speed of light.
2
6
123