
Zack Ankner
@ZackAnkner
Followers
493
Following
307
Media
37
Statuses
185
Junior @MIT . President of AI @MIT . Research Scientist Intern @DbrxMosaicAI .
Joined September 2019
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Alito
• 226094 Tweets
Zócalo
• 165781 Tweets
超・獣神祭
• 75644 Tweets
Fiorentina
• 53512 Tweets
Gremio
• 51889 Tweets
PITANDA NO PODDELAS
• 43399 Tweets
Nestor
• 37178 Tweets
Mets
• 34055 Tweets
#AEWDynamite
• 31845 Tweets
ナイトウェア
• 30906 Tweets
Marcelo
• 30835 Tweets
あなたの悪夢
• 29416 Tweets
#ナイトメアの悪夢で遊ばナイト
• 25731 Tweets
Luciano
• 14476 Tweets
Shota
• 13336 Tweets
Talleres
• 11946 Tweets
Huachipato
• 11766 Tweets
Coyuca de Benítez
• 10293 Tweets
Okada
• 10048 Tweets



















Pinned Tweet

Excited to announce Hydra decoding! 🚀
We introduce sequential dependence in Medusa decoding and achieve up to a 1.31x and 2.71x improvement in throughput as compared to Medusa and baseline decoding!
Paper:
Github:
3
20
119
My EMNLP paper got desk-rejected post-rebuttal because I posted it to arxiv 25 minutes after the anonymity deadline. I was optimistic about our reviews, so I spent a whole week while visiting my family writing rebuttals and coding experiments to respond.

Just got a desk reject, post-rebuttals, for a paper being submitted to arxiv <30 min late for the anonymity deadline. I talk about how the ACL embargo policy hurts junior researchers and makes ACL venues less desirable for NLP work. I don’t talk about the pointless NOISE it adds.
28
47
405
3
28
187
"Ring Attention with Blockwise Transformers for Near-Infinite Context"
TLDR: Ring Attention: A distributed algorithm to efficiently compute exact attention over arbitrarily long sequence lengths.
Details in thread 👇

2
10
96
Should we really use constant masking rates for BERT pretraining?
We introduce dynamic masking rate schedules, a simple but effective method for improving masked language modeling (MLM) pretraining.
Paper:

4
16
92
It’s especially hard being an undergraduate researcher who already has to balance a full-time class schedule while trying to fit in research. But instead of just complaining I would like to highlight the paper because I am proud of the work we did.
2
0
39
"Efficient Streaming Language Models with Attention Sinks"
TLDR: An efficient method to perform inference over longer sequences based on the observation that the first token in a sequence plays an essential role in attention.
Details in thread 👇

1
3
29
The linked thread contains in-depth details about the paper, but the TLDR is when pre-training BERT-style LLMs scheduling the rate at which tokens are masked outperforms using a fixed masking rate.
Should we really use constant masking rates for BERT pretraining?
We introduce dynamic masking rate schedules, a simple but effective method for improving masked language modeling (MLM) pretraining.
Paper:
4
16
92
1
0
21
Have been meaning to start posting paper summaries for a while. Since my gap year I have tried to read at least a paper a day. Recently, I started summarizing each paper and its been super useful for my understanding.
Can't promise they will be the most polished summaries 😃
2
0
20
Super awesome to have our paper shared by
@rasbt
! Really weird and surreal to see something I worked on showing up in my timeline

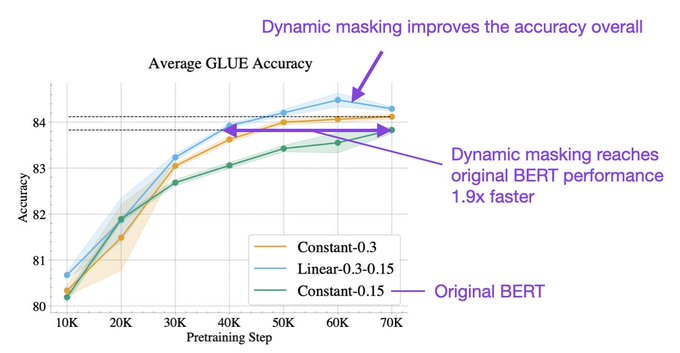
Bored by decoder-only transformers? Let’s revisit encoder-style BERT models!
Traditionally, BERT LLMs were pretrained with a 15% masking rate.
Turns out varying the masking rate between 15-30% during pretraining improves accuracy & time to convergence:
10
50
356
1
2
20
Little rant, admin makes running a club
@MIT
the most frustrating experience. So many bs hoops to jump through and useless bureaucracy. Students are motivated and can manage their own clubs. Every year I'm honestly shocked most clubs don't disband because it's so god-awful
1
0
19

During rebuttals we showed our method composes with Random Token Substitution (RTS), where the model is trained to predict whether a token was or wasn’t swapped. We found that scheduling the rate at which tokens are substituted performs the best and confers a 1.16x speed up.
2
0
15
Super fun to work on this project!
@exists_forall
really has the fastest turnaround. We read the Ring Attention paper at our mlsys reading group on 10/18 and by 11/15 William had posted Striped-Attention!

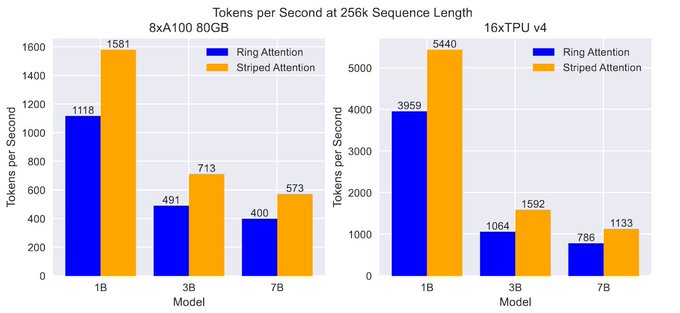
New preprint out with colleagues from MIT!
"Striped Attention: Faster Ring Attention for Causal Transformers"
We introduce a simple extension to the recent Ring Attention algorithm for distributed long-context attention, and see speedups up to 1.65x!
1/

5
12
67
1
1
16

Time to pay the piper and fix my scripts till the sun comes up

1
0
15
I love long contexts as much as the next person and don’t think we’re at the point where gains from extending contexts are diminishing, but do people have takes on when that is?
Ie when should we stop extending context length and just resort to retrieval and other memory alg.
10
0
15
This will be a valuable part of my weekly team meeting presentation. In seriousness, one of my favorite parts about working with the people
@MosaicML
is the research attitude and not taking ourselves too too seriously. Makes tackling challenging new projects a lot less daunting.

1
1
13

I've recently been really interested in mlsys-esque work. I think a lot of the papers I have liked recently can be framed in this perspective. Also, over the past few years it seems like mlsys and data work have been the only directions that offer consistent gains ...
3
0
15
Honestly, the only reason I do research and not engineering is just so that I don't have to type my functions. Nothing makes me happier than ignoring a Pylint warning.
1
0
11
New DL achievement today 🎉: A graph other than loss / downstream perf determined my mental health.
0
0
6
This was a collaboration with the awesome
@nsaphra
@leavittron
@davisblalock
@jefrankle
. This work was all made possible by
@MosaicML
. They really are the best people with the best ML stack and they made this entire project a great experience! [11/11]
0
0
6
Forgot everyone is flying back from ICML and thought that twitter had just flagged me as an avid fan of airline complaints.
0
0
6

TLDR:
Dynamic masking rates:
* Improve downstream accuracy on GLUE
* Provide a Pareto improvement for pretraining time vs. downstream performance (up to 1.89x speedup!!!)
* Are very simple and effective
[2/n]
1
1
5
The code for this project will be released soon, and the paper will be made available on Arxiv. There will also be some larger runs added to the final paper (thanks anonymity deadline). If you have any questions or follow-up ideas please reach out! [10/n]
1
0
4
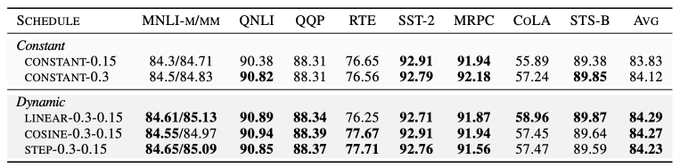
How do non-linear schedules compare?
We experimented with scheduling the masking rate using both a cosine and step-wise schedule. We ultimately find that performance gains are robust to scheduler form. [8/n]
1
0
4
Just saw that it was Judge Kaplan who convicted SBF so I think it's safe to say SBF is no longer a fan of scaling laws.
1
1
4
Do all schedule configurations improve downstream performance?
We find that a decreasing masking rate schedule is a necessary component for improved downstream performance. [7/n]

1
0
4
Linear scheduling doesn't only improve final performance, but it also improves GLUE performance across all of pretraining. Linear scheduling corresponds to a 1.89x speedup as compared to constant 15% masking, and a 1.65x speedup compared to constant 30% masking [5/n]
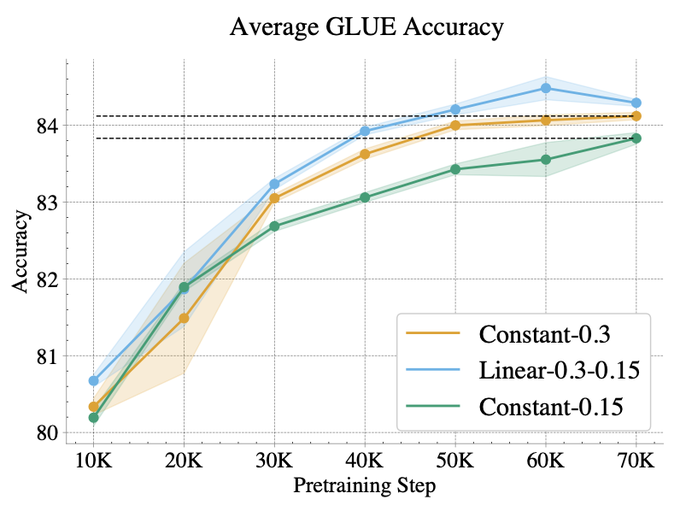
1
0
4
@brianryhuang
Yeah I think in general "engineering" work gets looked down on in research. Its a broad overgeneralization but I can say I've definitely thought that way before when really all the gains we have are due to engineering considerations and there's so much interesting work there.
0
0
3
Where do the performance gains come from?
We hypothesize that dynamic scheduling attains the advantages of greater masking earlier in training (better training signal) and the advantages of lower masking later in training (more context/ similar to inference setting) [6/n]
1
0
3
What is MLM pretraining?
The predominant way to pretrain large encoder LMs is to mask out a subset of the input and then have the model reconstruct the masked-out tokens. Typically, a fixed masking rate is used for all of pertaining. [3/n]
1
0
3
@abhi_venigalla
@MIT
Honestly admin babysitting at every part of the institute is crazy now. Swear these people think they’re running a day care and not a college sometimes
1
0
3
While I want to say I'm fully bitter-lesson-pilled, I always have some doubt that working on better inference procedures or training objectives could transform the field.
Anyways, I'm thinking of fully switching to focusing on mlsys research and would love anyone's thoughts
3
0
3
Not only does this method perform better at long-range modeling, it is also more efficient. As a bonus, Sink token pre-training seems to help standard short model eval and produces more regular attention maps, which might enable better model quantization.
1
0
1
Overall, I’m a really big fan of this work. The ability to linearly scale exact attention with the number of available devices will open up a lot of exciting use cases. This seems like a no-brainer method for very long sequence length pre-training.
1
0
3
We primarily study linearly decreasing the masking rate from 30% to 15%. Compared to constant masking schedules, linear scheduling improves or achieves equal performance on all individual downstream tasks and provides a significant average improvement. [4/n]

1
0
3
Sink-aware pre-training: What if instead of just changing how we do decoding at inference time, we incorporated the notion of sinks during pre-training? The authors propose to prepend each sequence with a special Sink token, that effectively acts as a no-op.
1
0
2
In conclusion, dynamic masking rate scheduling is an incredibly simple method to implement, that consistently improves downstream performance in terms of both final quality and efficiency. [9/n]
1
0
3
@stephenroller
Time to undo the last commit then? Its okay github stats needed to get padded anyways
1
0
2
In this way, we can compute blocked attention over the whole sequence, but each device only needs to store the interactions for one of the Q blocks.
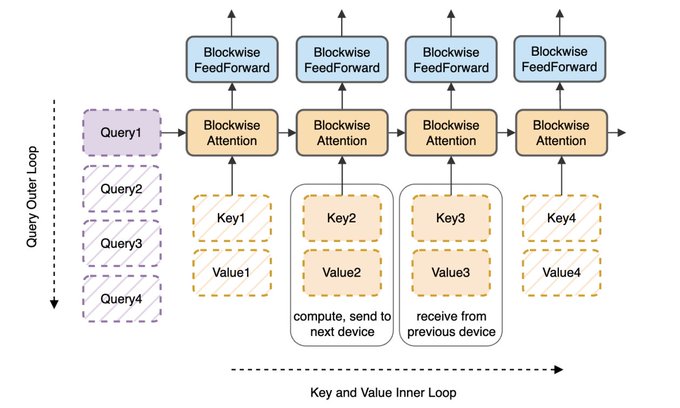
1
0
2
Problem: Everyone knows by this point, but in a Transformer the compute and memory of self-attention scales quadratically with the sequence length. In the Vanilla approach to performing self-attention, the entire attention matrix needs to be materialized.
1
0
2

@code_star
No idea, these are just the ramblings of a guy with a smooth brain who doesn't like in-place ops
2
0
2
So when we perform windowed attention, and our current position does not include the first tokens, performance decreases even if the first token isn’t semantically relevant.
1
0
1
Having a Sink token results in both better downstream performance and more regular attention maps for actual tokens!

1
0
2
@stephenroller
And an even greater instinct to leave all my code to get re-factored by smarter people and go back to data selection methods haha
0
0
2
Now onto the fix: “Streaming LLMs”. The idea is to perform windowed attention but keep the first few tokens in our KV-cache so that tokens later in the sequence can still use them as sinks.
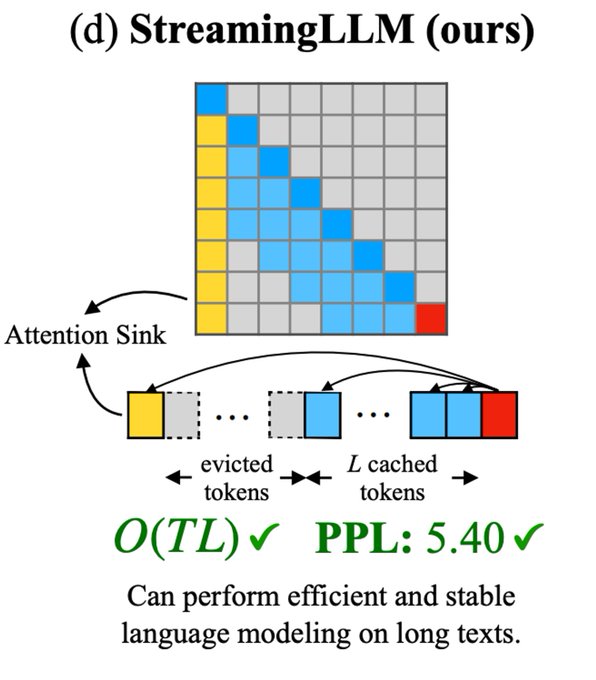
1
0
2
@stephenroller
I'm sure the other folks at Mosaic can produce algorithmic improvements. I'm personally just working on pronouncing parallelism correctly 😁.
2
0
2
Thanks to the authors
@haoliuhl
@matei_zaharia
@pabbeel
for an awesome read and method!
Please let me know if I got any of the details wrong
0
0
2
In this table, the authors profile the constraints imposed on the block sizes such that communication can be performed in the background to the compute without inducing any overhead.
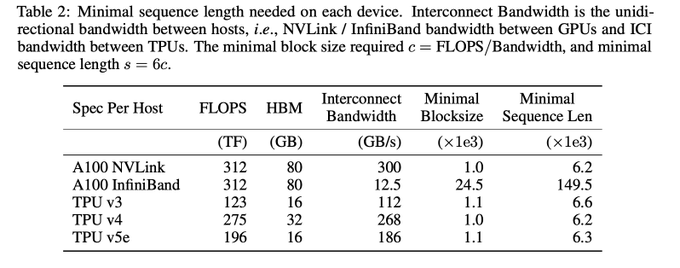
1
0
1
I.e. at every step each KV block is passed to the sequentially next block and once a block reaches the last device, it wraps around to the first device.
1
0
1
@LChoshen
@jefrankle
What Jonathan said haha, and yes this was work I did during an internship at Mosaic! I work with Prof. Carbin at MIT
1
0
1
As a demonstration, the authors fine-tune LLaMa-13B with a context length of 512K!!! They evaluate the long-context capabilities of the model using the line retrieval test. RingAttention can scale to longer sequence lengths than all previously existing models!

1
0
1
2. In windowed attention we only cache and compute attention over the previous L tokens. While this method is efficient, performance drops substantially.
1
0
1
@itsclivetime
@abhi_venigalla
@MIT
Yeah having an independent org would definitely be easier. But for most of our activities we run we really need classrooms so kinda stuck sadly
0
0
1
The authors state that even “with a batch size of 1, processing 100 million tokens requires over 1000GB of memory ... This is much greater than the capacity of contemporary GPUs and TPUs, which typically have less than 100GB of high-bandwidth memory (HBM).”
1
0
1
@code_star
Yeah, vagueness around how I used word retrieval. I mean retrieval like doing some ANN lookup to extend your context window. Glad to hear 16K is set in stone ... my new north star.
0
0
1
@rasbt
@TheSeaMouse
Hey, one of the authors, we experimented with higher initial masking rates and found them not to work and actually degrade performance. Side note, that figure is misleading and we'll update, those were just supposed to be example values.
1
0
1
Conclusion: I thought this was an amazing paper that both demonstrated an interesting observation about attention and used it to make a really powerful inference solution.
1
0
0
However, as the normalization term is only a scalar, we can perform the softmax online by just exponentiating our vector, passing it through our FFN, and then normalizing after.
1
0
1
This observation gets used in FlashAttention, which only materializes chunks of the self-attention to be computed at any time. However, even when using FlashAttention, we still have the issue of storing the output which is prohibitive for extremely large sequence lengths.
1
0
1
There are a few ways attention is extended over longer sequences:
1
0
1
Performance results: StreamingLLMs outperform both dense attention and windowed attention at long sequences and have commensurate performance for sliding window attention!
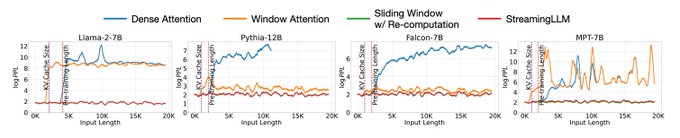
1
0
1
For full details on implementation around numerical stability see the original paper (). The important takeaway for us is that we can chunk our attention computation into parts without materializing the full matrix.

1
0
1
Efficiency results: To compare speed improvements, they compare Streaming LLM with sliding window w/ re-computation. They find that at seq len 4096, streaming achieves a 22x speedup!
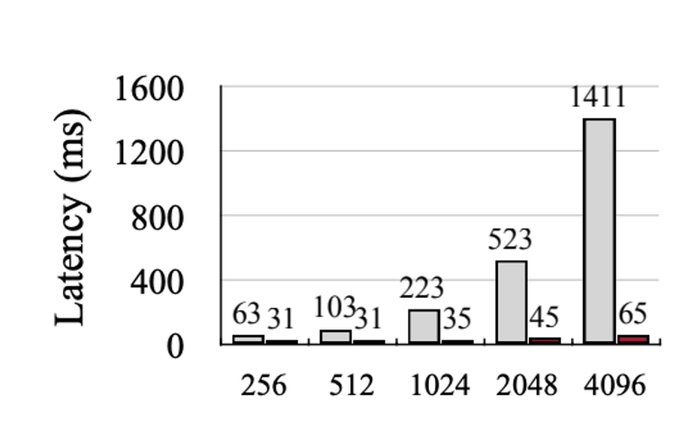
1
0
1
@anneouyang
@abhi_venigalla
@MIT
Yeah the tax part is brutal. So many chipotle tax reimbursements lost lol
0
0
1
Ring Attention proposes to alleviate this issue by sharding the block-wise attention computations over each device. To do so we chunk the Query (Q), Key (K), and Value (V) matrices. Each Q block is assigned to a fixed device, and the KV blocks are rotated through each device.
1
0
1
3. In sliding window attention, we only perform attention over the previous L tokens, but no longer maintain a KV-cache and instead re-compute attention over all L tokens. While this method has good performance, it's less efficient due to the recomputation.
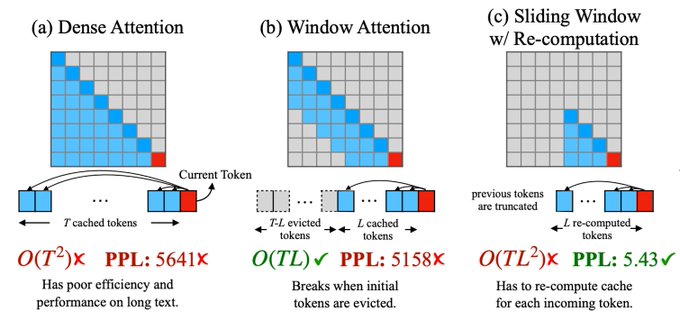
1
0
1
@rasbt
@TheSeaMouse
We found the best initial masking rate to be consistent with the best constant masking rate. For larger models, the initial masking rate benefits from being higher. Will be dropping those larger models soon!
1
0
1
I’m not the most informed about inference, but dense attention for long sequences seems problematic given both poor length generalization of models and the blow-up of the KV-cache.
1
0
0
1. In dense attention, we simply extend the sequence length past what the model was trained on. This has both bad performance at long-range modeling and bad efficiency as our KV cache blows up.
1
0
1
This method is efficient if there is a sufficient amount of computation to be done for each block since we can hide the communication cost behind the computation by concurrently receiving the KV block from the previous device and sending the current KV block to the next device.
1
0
1
To rotate the KV blocks across devices the authors propose to use a ring-like communication strategy where for N total devices, at step k the ith KV block is on the (i+k) % N device.
1
0
1
In determining why windowed attention fails, the researchers find what they call “attention sinks”. Models reliably assign high attention scores to the first few tokens in the sequence.
(This observation that some tokens are “attention sinks” has been noted before (registers))
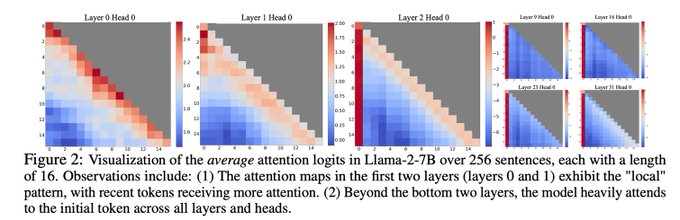
1
0
1
@danish037
@jefrankle
@juanmiguelpino
@hbouamor
@kalikabali
@IGurevych
Not exactly sure where but waiting till post-rebuttals after having authors spend their entire week grinding out results to have them be completely ignored is definitely not the right place imo.
1
0
1
The need for full materialization is that to normalize the attention matrix using the softmax function, we need to track the sum of each exponentiated term in the vector to be soft-maxed.
1
0
1