
This data mix was a bit of a hedge, but it seems to have turned out quite well. We're excited about what will happen as we get more scientific and methodical about data. The field overlooks data research, and we're working to fix that.
1
0
16
Replies
By now you may have seen some hubbub about
@MosaicML
’s MPT-7B series of models: MPT-7B base, MPT-7B-Instruct, MPT-7B-Chat, and MPT-7B-StoryWriter-65k+. These models were pretrained on the same 1T token data mix. In this 🧵I break down the decisions behind our pretraining data mix
8
53
258
Context: We wanted MPT-7B Base to be a high-quality standalone model and a good jumping off point for diverse downstream uses. There is a lot of cool stuff happening in data research ATM, but this is also our first major public LLM release so we didn’t want to take any big risks

1
0
12
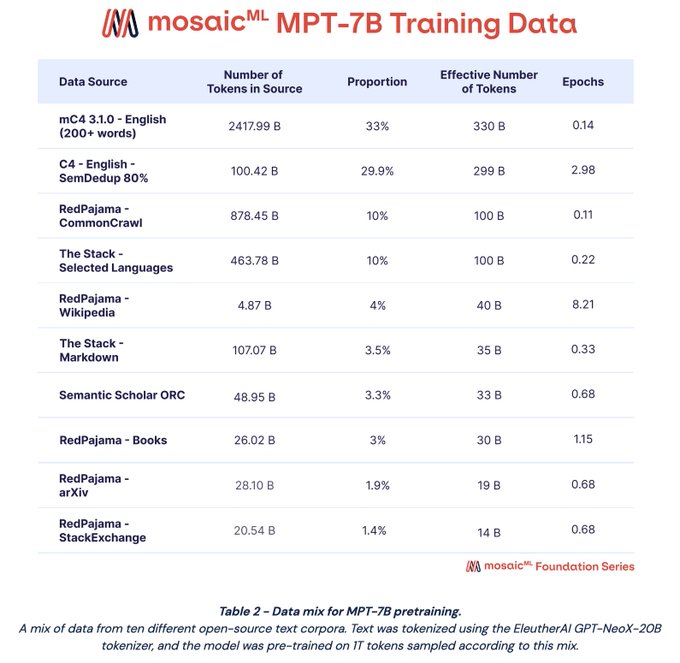
mC4 3.1.0, is Chung et al’s update of the original mC4. It’s 33% of our training data (330B tokens). The English subset of this corpus is ~modern (thru August 2022) & big: ~2.5T tokens after basic quality filtering. We also wanted longer documents, so we removed docs <200 words
2
0
13
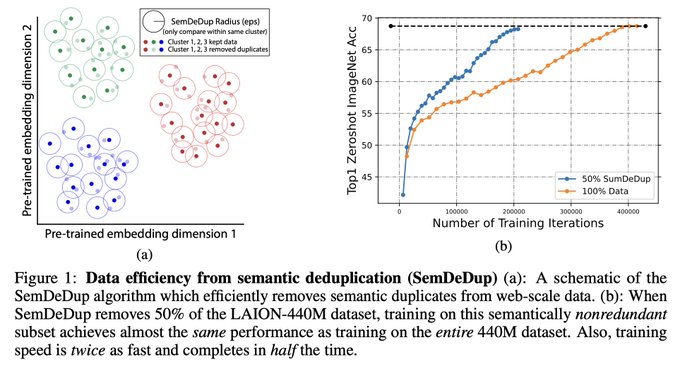
Next up: C4. Our initial exps showed C4 just performed _really_ well. But we wanted to push it! We used SemDedup (ty
@arimorcos
' group) to remove the 20% most similar documents within C4, which was consistently :thumbsup: in our exps

Web-scale data has driven the incredible progress in AI but do we really need all that data?
We introduce SemDeDup, an exceedingly simple method to remove semantic duplicates in web data which can reduce the LAION dataset (& train time) by 2x w/ minimal performance loss.
🧵👇
7
59
310
1
2
27
C4 Part 2: Multiepoch pretraining isn’t really a thing in NLP because…tradition? Superstition? Our initial experiments actually showed its actually totally fine for ≤8 epochs (more experiments to come!), so we trained on our SemDedup’d C4 for 2.98 epochs (299B tokens)
7
2
37
Next up: RedPajama is
@togethercompute
’s commendable attempt to recreate the LLaMa data. Many of their sources (e.g. Wikipedia, StackExchange, arXiv) are already available as ready-to-use datasets elsewhere, but RedPajama contains data through 2023—the freshness is appealing
1
0
15
We trained on RedPajama’s CommonCrawl for 100B tokens, Wikipedia (40B tokens == 8.2 epochs!), Books (30B == 1.15 epochs), arXiv, and StackExchange (19B, 0.68 epochs each). We upsampled Wikipedia for quality and Books for length
1
0
9
We wanted our model to be a well-rounded student, so we also included code as 10% of the pretraining tokens (100B); experiments showed we could train on ≤ 20% code with no detriment to natural language evaluation. We used a subset of languages from
@BigCodeProject
’s The Stack
1
0
10
We also separated out the Markdown component of The Stack. We feel that Markdown sits somewhere between a natural and a formal language, so we didn’t want to count it towards the “Programming Languages” budget. We trained on 35B tokens of Markdown
1
0
14
The final component of our pretraining data is SemanticScholar (S2) ORC. S2ORC is a corpus of 9.9M English-language academic papers, lovingly and meticulously assembled by our friends at
@allen_ai
. We trained on 33B tokens of it. Ty
@soldni
@mechanicaldirk
for support w/ S2ORC
1
0
11
@code_star
,
@_BrettLarsen
,
@iamknighton
, and
@jefrankle
(yes, our Chief Scientist gets his hands dirty) put in a TON, and we couldn’t be happier with how the MPT-7B series of models turned out. And we're just getting started.
2
0
21