
And yes, you can switch back and forth between NVIDIA and AMD, even within a single training run.
It's Christmas in July!🎄
9
46
424
Replies
Ready for GPU independence weekend?
PyTorch 2.0 and LLM Foundry now work out of the box on ** AMD GPUs! ** We profiled MPT 1B-13B models on AMD MI250 and saw perf within 80% of A100-40GB, which could go up to 94% with better software.
It. Just. Works.

23
215
1K
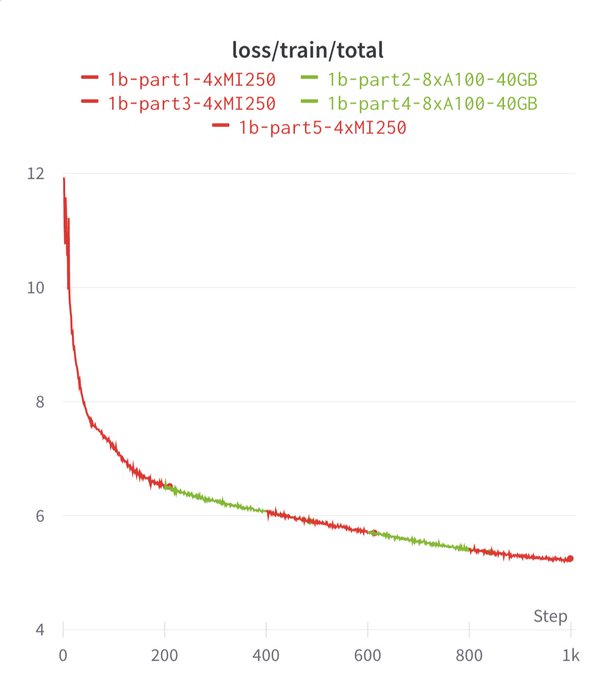
Here's MPT-1B training for 1B tokens on NVIDIA A100 (green) vs. AMD MI250 (red). Can you spot a difference?
Both runs use the exact same LLM Foundry code:


1
3
65
If we zoom in on the first 100 batches, we get nearly overlapping loss curves. This is crazy given that the runs are on two totally different hardware stacks!
StreamingDataset and Composer do a lot heavy lifting for determinism in the dataloader and train loop.

1
2
54
What about perf? We only had 1 node of 4xMI250, so to compare with our 8xA100 systems we measured per-GPU metrics.
With no code changes, perf on MI250 looks really strong! About 80% of A100-40GB. Better FlashAttention for AMD may close the gap (we predict ~94% of A100-40GB)

2
11
73
This is all made possible thanks to a software and hardware stack that AMD has been building for years, and is now bearing fruit.
Seeing MI250 work so well today brings hope that the MI300x will too when it arrives!

1
6
71
One fun tidbit -- yes with PyTorch you still run `torch.cuda` on AMD systems and yes it does work😆

2
6
99
For more projections on (MI250, MI300x) vs. (A100, H100) check out
@dylan522p
's companion blog here:
2
5
48
Overall, I'm super optimistic about the future for AI hardware. More options means more compute supply, more market pressure on prices, and lower costs for users.
If your hardware supports PyTorch 2.0 too (
@HabanaLabs
???) reach out to us and we would love to showcase it!
1
2
48
Keep an eye on LLM Foundry where we will add pre-built Docker images with ROCm FlashAttention to make the AMD setup process even faster.
We'll also be profiling MPT on larger MI250 clusters soon!
Lastly,
@LisaSu
any chance we can get early access to MI300x? 🙏
0
3
59

@abhi_venigalla
Hey Abhi, great blog post on the Mosaic site. Have you run the numbers with ROCm 5.6 yet?
1
0
0



@MasterScrat
Sure here's two plots, easy to do with Composer :)
Left: loss vs. hours
Right: hours vs. step
This is 4xMI250 vs. 8xA100-40GB, so the red segments are running at ~0.4x the speed of the green segments
The segments overlap a bit b/c I was manually killing and resuming runs.


0
0
11



@abhi_venigalla
Please delete this tweet and let gamers buy cheap AMD cards from cash strapped scalpers and miners for the summer at least
0
0
2

