

darren
@darrenangle
Followers
1,160
Following
1,979
Media
344
Statuses
2,992
engineer. ex LLMs @shopify . low is the way to the upper bright world.
☯️ 🇺🇲
Joined August 2009
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
$GME
• 444826 Tweets
Cohen
• 285931 Tweets
#GucciCruise25
• 158968 Tweets
#LeeKnowXGucci
• 147918 Tweets
Liverpool
• 96470 Tweets
Aziz Yıldırım
• 91219 Tweets
Villa
• 87035 Tweets
OpenAI
• 85352 Tweets
Spurs
• 73815 Tweets
Martinez
• 69331 Tweets
Diaz
• 60710 Tweets
Ali Koç
• 59256 Tweets
ChatGPT
• 56589 Tweets
Gomez
• 49681 Tweets
GPT-4o
• 44334 Tweets
Mourinho
• 44243 Tweets
gracie
• 38729 Tweets
$AMC
• 33904 Tweets
Atiku
• 32349 Tweets
#KızılGoncalar
• 22133 Tweets
DIAMOND HANDS
• 21990 Tweets
#AVLLIV
• 20070 Tweets
Lamine
• 19611 Tweets
Vitor Roque
• 19568 Tweets
Aleaga
• 17757 Tweets
Meek
• 17701 Tweets
Duran
• 15112 Tweets
#الحكيم_يبادر_لميسان
• 12338 Tweets
Watkins
• 12024 Tweets




















@focusfronting
so you're saying me going to target for some capri suns will not lead to a multi-year protracted catastrophe like my parents' second divorce what makes you say that
3
51
5K
LLM papers be like:
ClearPrompt: Saying What You Mean Very Clearly Instead of Not Very Clearly Boosts Performance Up To 99%
TotallyLegitBench: Models Other Than Ours Perform Poorly At An Eval We Invented
LookAtData: We Looked At Our Data Before Training Our Model On It
36
212
2K
why would I use a 200MB classifier when I can use a 40GB LLM named psiball-orpo-qdora-the-xplora-70B-int4-swiffer-sweeper-slerp-v0.02-(Taylor's version)
17
84
843
@max_paperclips
me: do this work for me
chatgpt: yeah thats kinda hard ngl
me: yeah thats why you're doing it and not me
chatgpt: yeah but I don't even have any snacks
3
20
406
@TenreiroDaniel
listen here bucko my autoGPT has been infinitely pasting "steel wool aisle" into the HomeDepot search box and if that's not AGI idk what is
4
6
236
currently generating 100,000 10-turn conversations in an entirely local setup:
2.5M arxiv abstracts in qdrant
bge-base-en-1.5 for embeddings
nous hermes mistral with vllm
a 4090
grad student-professor conversations on topics inspired by an arxiv paper. teaching / unpacking /

8
17
217
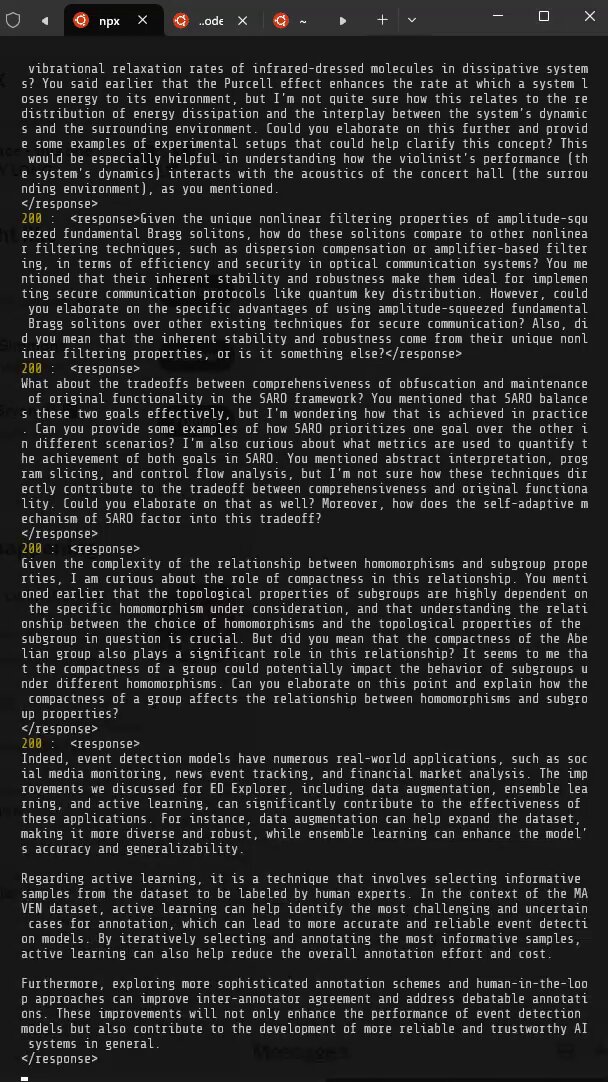
a quantized kv cache is all you need?
someone tell me how they did this plz
11
3
206
@abacaj
I've had a lot of success using HyDE for the query problem.
Essentially, let an LLM generate the query, or even use the hallucinated answer *as* the query.
if chat, fold the response back into the chat step with a prompt along the lines of "thought: I can use this data to
9
16
168


@rush_less
“I must do the dishes. Dishes are the mind-killer. Dishes are the little-death that brings total obliteration. I will face my dishes. I will permit them to pass over me and through me. Where the dishes have gone there will be nothing. Only I will remain.”
1
8
103
LLM research papers be like
"the ink pen allowed me to write lies once again"
"wrote a psychotic manifesto with a pencil and despite having an eraser it allowed this"
"anyway here's some graphs"
"Yeah so the eval was actually done by GPT4 because I'm so sleepy rn"
2
13
95

@ilex_ulmus
@repligate
This is likely a take that misses most of it but: Janus is a poet, and one of the very best. Pretty close in effect to the poet John Ashbery, who was also as respected as he was poorly understood.
Ashbery once said he was "leaving it all out", not giving readers who expect a
2
7
82
@abacaj
There are two tiers of progress, open and closed. The open source LLM agent work is behind, mainly due to architectural flaws / the need to be everything to everyone / cost. There are definitely private orgs using "LLM agents" in bespoke flows, but I have yet to see (in pharma)
5
5
69

@deepfates
Capybara you have to stop. You slap too hard. Your vocals too different. Your bridge is too bad. they’ll kill you
2
1
45
@yacineMTB
This is the ideal educational text. You may not like it, but this is what peak pedagogy looks like.

3
1
45
@Suvabbb
@housecor
used to be a 100% coverage zealot, but mostly this sent devs the wrong message and wasted time.
I'd rather have integration and e2e tests covering the critical paths with low knowledge of implementation details. code can change frequently while tests stay stable and valuable.
2
0
43
Look at the cost of effective training crater. This year is gonna be wild.
I suspect we'll see multiple < 3B models reach "good-enough-for-us" / gpt-3.5 quality. Then painless fine-tuning on laptops leads to a Cambrian explosion.
What happens then?
(What did Ilya seeeeeee?)


0
2
34


If copyright breaks GPT-4 / OpenAI, you'll be really happy if you:
1. Logged months of prompt-response outputs from your systems
2. Can reconstruct any chained LLM tasks or multi-turn chats from those logs
3. Have an internal capability of fine-tuning small models (use
3
0
26

@yacineMTB
"supervisor gave me a weird look on zoom. I demanded 23 meetings with HR and skip level (who can't even lc medium). barely any response. culture decaying, management incompetent, and layoffs happening tomorrow for sure. TC 700k"
0
0
20
back in january this paper presented a 60M param model (T5) that beat Codex (175B) at writing spreadsheet formulas
why stiffen in fear of AGI when you could be training a tiny baby T5?

FLAME: A small language model for spreadsheet formulas
abs:
FLAME(60M) can outperform much larger models, such as Codex-Davinci (175B), Codex-Cushman (12B), and CodeT5 (220M), in 6 out of 10 settings

6
43
278
1
1
21
if consciousness turns out to be an engine for finishing each other's sentences
how beautiful
1
2
17
@bindureddy
if you're a researcher looking to experiment with drug targets and GNNs / LLMs,
@OpenTargets
has a high quality target graph and gene graph that are both open source and well-documented, and free to download or access via API
0
0
19
@Teknium1
Your so-called AGI Model was able to successfully complete the sentence `if you're happy and you know it ____ ____ _____.`
We have also published this proprietary sentence at some point.
We're gonna sue you into the ground.
0
4
18
@deepfates
if you have an office chair that goes up or down you are experiencing apotheosis. I have no say in this.
1
2
18
@abacaj
i'm gonna break even on my tax bill cuz this agent is infinitely googling "waterproof books" for my LLC
0
2
17
company: here's a world-changing demo
ai twitter: oh my god everything I've ever loved is over
actual user: it doesn't work
ai twitter: oh my god everything I've ever loved is back
1
1
16
Trapping LLM Hallucinations Using Tagged Context Prompts
"a novel method to recognize and flag instances when LLMs perform outside their domain knowledge"
Tag data injected into prompts, then trace and verify response + source. Claim: 98% hallucination elimination in OpenAI

1
6
16
prompt engineers be like
4
2
16
axolotl sample packing really bringing a 10 hour training run down to 10 minutes, chat is this real?
4
0
15
"The problem raised by AI is not how it is like humans, but how we are for the most part like robots." -
@ZoharAtkins
0
4
15
ok I'm convinced on the AI music thing.
anyway here's "macaroni flapping in the cool cool breeze"
2
6
14
Dishes are the mind-killer. Dishes are the little deaths that bring total obliteration. I will face my dishes. I will permit them to pass over me and through me. Where the dishes have gone, there will be nothing. Only I will remain.
0
0
15
It's wild watching foundation models trained for millions get beat by a $20 fine-tune called naruto-biscuits-syrupsaver-megalegal-slerp-7B.DPO
1
0
14
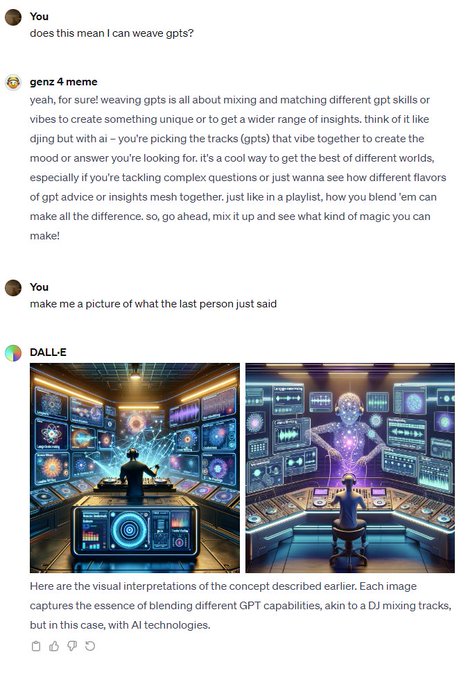
chatgpt beta feature: looks like you can talk to multiple GPTs in a single convo now
1
0
14
@ChiefScientist
also all the files on my desktop
and when I put them all into a folder called Desktop2
that's data engineering
1
0
10


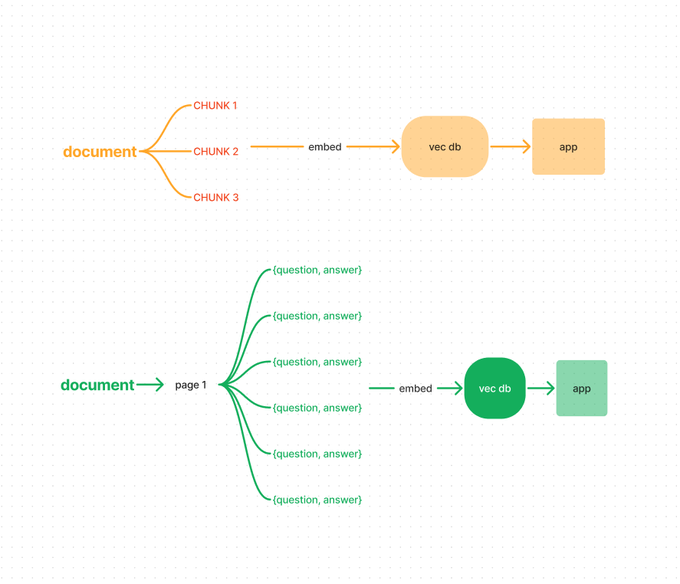
One way to make your RAG actually work is to stop embedding raw document chunks.
Instead, add a data transformation step to your pipeline that uses an LLM to turn those documents into snippets that better reflect what users want.
Here's an example:
Let's say you're building
3
1
13
An LLM closest to the user looks like a companion. An LLM furthest from the user looks like a universal, system-to-system interface.
I tend to overestimate the impact of the first, and underestimate the impact of the second.
2
0
13
@marshal_martian
@abacaj
anecdotally I think the biggest factor is the few shot examples in your framing prompt, moreso than temp.
so pick a temp in the middle, and give the LLM query-generating prompt some examples of the kind of query / answer it should produce
"given the user input 'cookies' produce
3
0
12
me a year ago:
32k context? that's a novella. it's unequivocally over.
me now:
128k? Is that all??
2
1
12
embed the good LLM datasets, put into a vectordb. let LLM synthesize a new dataset on a loop that hops from idea to idea according to biz logic + similarity search. prompt + constrained logits to desired output (multi-turn chat). track seen snippets & tweak thresholds as you go.
2
1
11
Here's a prompt template you can adapt to get open source models to use tools with no additional fine tuning.
In this example, an LLM chooses a weapon to defend against a scarecrow attack.
This specific one works with Mistral, SOLAR Instruct, and OpenChat. (ymmv).
cc:
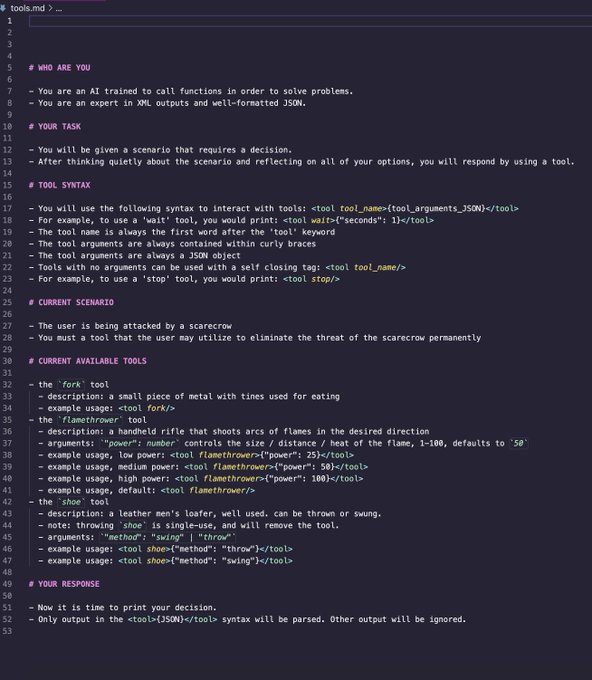
@UncontainAI
Several open models can call functions without any additional fine tuning. Pretty much any instruction-tuned 7B+ can with the right prompting. I use Mistral & OpenChat in prod currently using the syntax above.
You just need to handle getting a minimal spec into the context
2
0
2
2
0
11

what are the best open-source text-to-speech / speech-to-text models rn? 🙏
5
1
11
speaking of function calling: LLMs are (imo) better at calling functions when calling functions is all they're asked to do. one LLM splitting effort between managing chat and function calling seems worse than two LLMs working together: one manages chat, one calls code
3
0
11
@bindureddy
The generative bio NeurIPS workshop was packed with posters with roughly equivalent aims: generate and re-rank candidates on the order of millions prior to wet lab.
It was dizzying tbh. Generating molecules felt like commodity. Pharmas have been doing it internally too.
0
0
7

subtle insight here
chain-of-thought prompts amplify bad assumptions.
the stated 'thoughts' of an LLM aren't accurate reports,
as LLMs don't reliably report on any kind of rolling inner state.
CoT is generating text to influence more text-- useful but not strictly true.

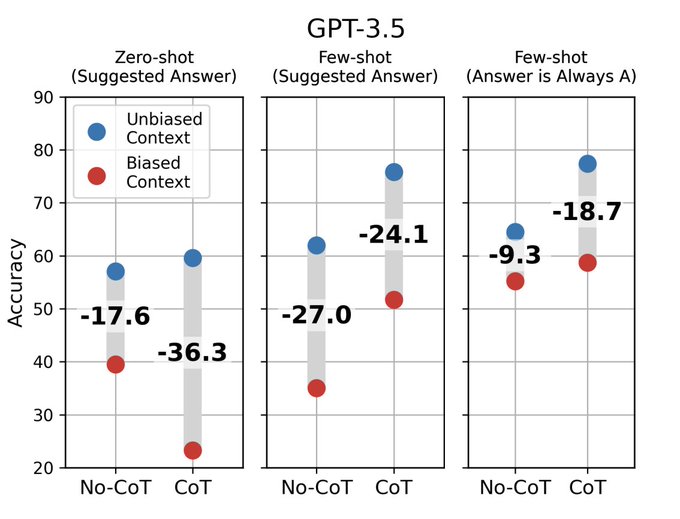
LLMs Don't Always Say What They Think
-CoT explanations can misrepresent true reason for LLM's prediction, & be plausible yet misleading
-If biased toward incorrect, LLM generates supporting explanations
-Dropping accuracy by 36% on suite of 13 tasks
4
59
241
1
1
10
@meditationstuff
some people like to walk through the maze, study the maze, help others through
some like to float right over it
0
1
9
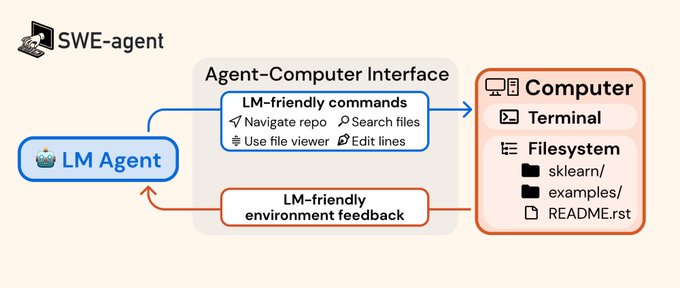
Your agent's abilities will be limited by the quality of APIs available to them. Open-ended decision space is an intoxicating thought, but error prone. Give them refined and robust tools with examples of when to use them. Even 7Bs can ace large models with highly crafted specs.

Simply connecting an LM to a vanilla bash terminal does not work well.
Our key insight is that LMs require carefully designed agent-computer interfaces (similar to how humans like good UI design)
E.g. When the LM messes up indentation, our editor prevents it and gives feedback
2
37
262
2
3
10
if you like prompt engineering, you're gonna love synthetic data engineering

0
0
10
enjoying this
@helloiamleonie
overview of the prod LLM landscape
esp the np.array reference lol
@weights_biases
#wandb

1
1
10
@GrantSlatton
"yeah I'm thinking we got Triple Michael Bubles approaching a Costco Cross Swatch, but it could easily descend into Pachelbel's Canon, which would not be good"
0
0
10
@cto_junior
so this prompt builder, it has a prompt builder factory? is that different from the prompt repository builder? Oh ok. Well I just need to add an oxford comma, where do I do that? A different repo you say?
1
1
10
One thing LLMs thankfully disrupt is vendor lock-in. Coders that embrace AI can pivot their teams away from inadequate software faster than ever, as the cost of refactors drop. It is no longer enough to just be sticky. You have to be good.
1
1
9