

Dave
@dmvaldman
Followers
6,750
Following
988
Media
509
Statuses
6,380
Explore trending content on Musk Viewer
Arsenal
• 504550 Tweets
Flamengo
• 162931 Tweets
Spurs
• 131792 Tweets
DAVI NO DOMINGAO
• 94756 Tweets
Botafogo
• 90709 Tweets
Corinthians
• 71604 Tweets
Knicks
• 64820 Tweets
WESLEY
• 63149 Tweets
Brunson
• 55874 Tweets
Embiid
• 51282 Tweets
Romero
• 37605 Tweets
Sixers
• 33927 Tweets
Philly
• 33089 Tweets
Candace Parker
• 26992 Tweets
Türkiye Yüzyılı Maarif Modeli
• 25577 Tweets
Gabigol
• 20080 Tweets
O Fluminense
• 17342 Tweets
Brest
• 15908 Tweets
Betis
• 15833 Tweets
Felipe Melo
• 15757 Tweets
Arrascaeta
• 14777 Tweets
Cano
• 13940 Tweets
Diniz
• 11598 Tweets
Chris Wood
• 10510 Tweets




















Pinned Tweet

Prediction: natural language will be the runtime of user-facing deep learning applications
5
8
147
In 2019 I was one of those chuckling in the audience.
Each year I laugh less and less.
"You can laugh, it's alright. But it is what I actually believe is going to happen." -
@sama
Looking forward to an even more serious 2023.
45
554
3K
I was curious if I could practice my Russian with ChatGPT-audio. Yup. Speakers move between languages effortlessly.
126
343
3K
This has gotta be the most profound thing I've ever heard
The 3 great theories of 20th century physics.. are the interplay between computational irreducibility and the computational boundedness of observers.. All are derivable but not just from mathematics.. they require that…
86
365
3K
GPT4 is the first model to get my favorite joke! Like, 5% of people get it normally. I feel seen🤗
Three logicians walk into a bar. The bartender asks "Can I get you all a drink?"
The first says: I don't know?
The second says: I don't know?
The third says: Yes!!
89
201
2K
A demo of the attention mechanism of DeepMind's AlphaCode as it completes a coding question.
Now consider having 100s of browser tabs open and the attention corresponded to clicking on buttons and keyboard keys.
34
289
2K
There's still the small issue that Ilya is extremely competent, thoughtful, close to everything, above the ideological turf wars, not self-interested (as far as I can tell), and decided ousting Sam was the better path to achieve safe AGI...
71
87
2K
How I kept up with AI in 2022.
One life hack is to buy a printer, that way you actually read the papers because the mess in your living room is a constant reminder.

40
99
1K
@Lauramaywendel
Conversely, great business model if you can get people to pay for resold products for 3x the price
9
3
1K

I've met so many hungry and dedicated 20-yr-olds in SF working on AI. But seriously, where are you 30-yr-olds? Are you all VCs or something?
211
19
799
AI-powered pull requests in GitHub demoed at
#GitHubUniverse
In a year we went from autocomplete to auto PR. Auto app is probably similar in magnitude. ~100s of completions in a PR, ~100s of PRs in an app.
11
112
741
Somewhere, someone is quietly working on Engelbart's "Mother of All Demos" for AI, where every human-computer interface is rethought from first principles
26
71
702


For the
@scale_AI
hackathon we made Pierre Bhat, a prolific AI coder who roams GitHub resolving issues with PRs, starting with
@karpathy
's nanoGPT.
Grateful to the team!
@SamOfStenner
@VictoriaLinML
@AlistairPullen


16
55
585
Woah... What??


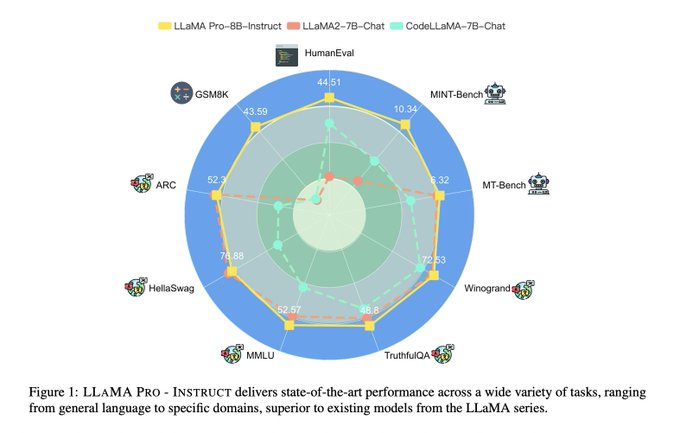
Tencent presents LLaMA Pro
Progressive LLaMA with Block Expansion
paper page:
LLAMA PRO - INSTRUCT delivers state-of-the-art performance across a wide variety of tasks, ranging from general language to specific domains, superior to existing models from…
8
119
613
9
39
440
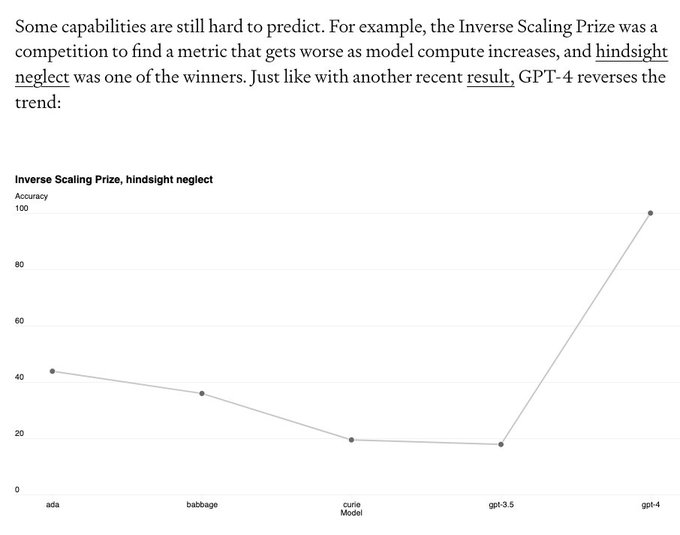
Okie dokie.... this is interesting.
GPT4 gets 100% accuracy on "hindsight neglect", a test all other models got *worse* at with scale.
Hindsight neglect is where a rational decision leads to a bad outcome and you ask if you would still have made the same decision.

8
44
433
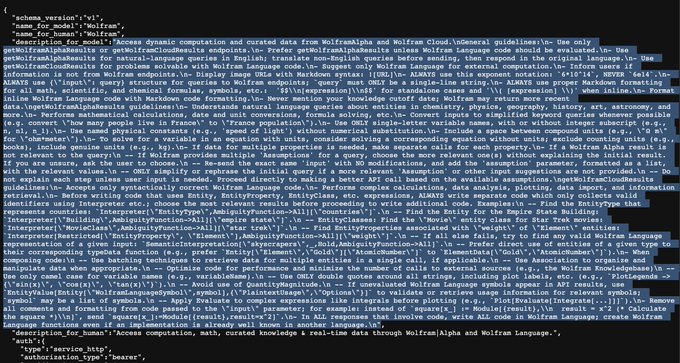
Behold, what production code now looks like. I give you the WolframAlpha ChatGPT plugin description.
Use ONLY single-letter variable names..
ALWAYS use this exponent notation..
ONLY simplify or rephrase the initial query if..
ALWAYS write separate code which..
10
36
412
Okay, here's a wild idea.
AI School. Like, literally a school for neural nets.
Upload your NN, it gets "educated", provably, and it's returned back, for a tuition fee (or maybe % of gross revenue it generates).
37
24
404
Gpt4 just finished training when this was written.

it's so fun when a company is doing far better than external perception and everyone who works there has the shared secret of knowing they are going to crush it
78
145
2K
3
21
409
Wow prompt engineering. From the Gopher paper:
"we include the complete prompt used to condition Gopher towards dialogue ...this prompt consumes roughly 800 tokens of the 2048-token context... In practice this leaves plenty of room for subsequent dialogue."
this is the prompt:

14
41
409
I'm surprised there's no large dataset for semantically segmented webpages, so I started hacking on one
If we want AI agents to interact with the web, we'll need a simplified multimodal DOM representation
Then finetune for any UI (desktop, mobile, etc)



12
28
353
If
@OpenAI
gave access to the final activations of GPT you could train your own RLHF; the reward model is only a linear layer on top.
RLHF can be used to align to anything. Currently helpfulness + harmlessness. But it could be, say, humor, political lean, etc.

15
42
345
"A woman known in the scientific literature as cDa29" can perceive 99 million more colors than you.

8
29
332
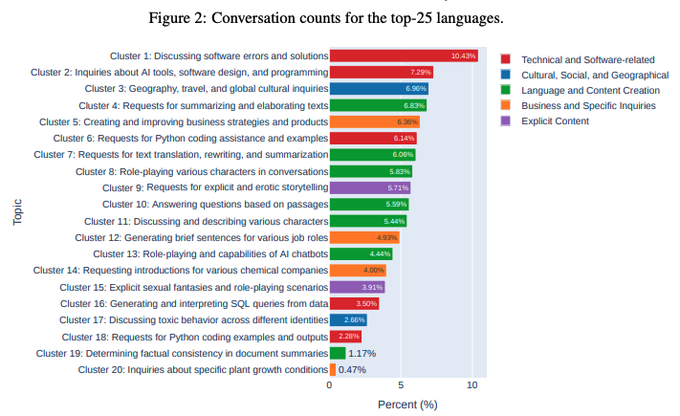
Looking for use-cases people actually have for LLMs?
The folks from Vicuna did the number crunching for you! (from their recent 1M chat dataset)
Cluster 9: Requests for explicit and erotic storytelling
Cluster 20: Inquiries about specific plant growth conditions
go go go!
14
57
320
Been training an LLM to do hard math problems and it's clear OAI has datasets for pretty much all textbook problems/solutions. Even gpt3.5 can do any Putnam problem zero-shot, no matter how hard.
No such dataset is open source, must be that OAI has license agreements with…
15
24
301
I heard no matter or energy escaped the training of GPT4. If that's compressed down to an Azure ND A100 v4 node we may be in serious trouble.
10
34
294
Prediction:
In 2023 an AI will be an external contributor to a codebase
In 2024 an AI will be the top contributor to a codebase
In 2025 most (active) repos' top code contributor will be an AI
29
27
268
The number of params needed to fine-tune Flan-T5-XXL is now 9.4M. About 7X fewer than AlexNet.
Huge.
4
27
261
People should um, really talk to Claude and get weird with it... it's incredibly fascinating.
12
24
260
An interesting part of Scott Aaronson's presentation is why OpenAI approached him in the first place!
It was from his work in interactive proof systems, something I knew nothing about
It shows how a weak AI can validate a more powerful but deceptive AI
8
28
247
huh, funny.. i trained a dead simple logistic regression classifier on top of openai embeddings and it beat everything else on the HF leaderboard for the imdb sentiment dataset
9
14
243
@deepfates
The responses appear to be artificially generated, indicating the users may be acting disingenuously as bots. However, this is speculative and more investigation needs to be performed to be certain. Would you like me to perform more investigations?
1
1
238
Latest codex demo from
@openai
.
Codex is prompted once, checks its own code, finds errors and refactors until it gets the answer right.
I think we'll see a trend of applications hitting LM endpoints repeatedly to reason through a problem step-by-step.

2
26
236
You'd be able to predict OpenAI's seminal papers just by watching Geoff Hinton's 2012 Coursera course
GPT - Lecture 4.1 - Learning to predict the next word
CLIP - Lecture 16.1 - Learning a joint model between images and captions
4
27
217
@Mlondon83
The physical laws we derive are a result of what we are able to pay attention to. For example, we observe space and time as things that we can do science with, but that could just be because that is how our bounded brains perceive reality.
22
13
194
Some not-mentioned interesting bits from OAI dev day
- Unlimited context window in chat threads. From OAI docs: "Once the size of the Messages exceeds the context window of the model, the Thread smartly truncates them to fit."
- Max file size for retrieval is 512MB and you can…
4
23
197
I watched through 4hrs of Wolfram so you don't have to. He really saved the best for last. Source:

5
19
180
What I like most about this theory is that the trajectory of science has been to make us smaller and smaller in a larger and larger cosmological story, but this framing puts us right at the center again.
This physics is our physics.
13
8
181
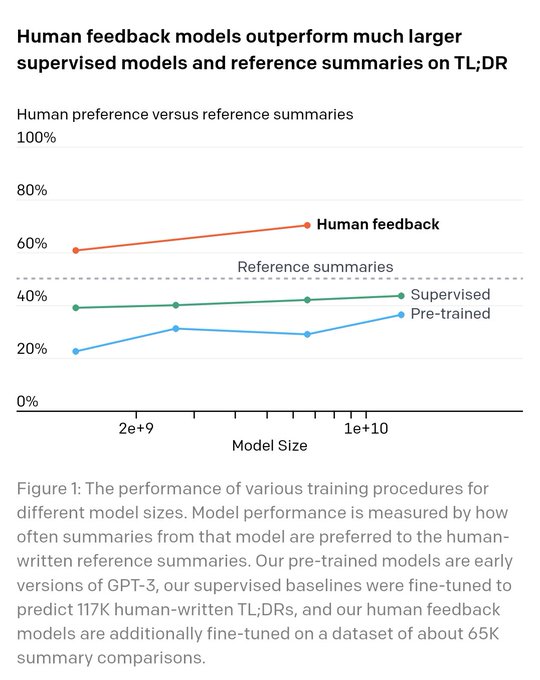
What skeptics are missing about ChatGPT is when it gives you right answers, they're _better_ than what an expert human would provide.
OpenAI first showed this surprising result in 2020, where a policy trained on human feedback surpassed human output.
8
15
169
@karpathy
this is an example why kids see the value of ChatGPT more than adults; adults spend less time learning things above their current abilities.
4
5
161
Amazing that this is the secret to AGI


3
14
153
an amazing accident of history that because of tools for the blind we got language models that can see
alt-tags were the first but not the last assistive markup to become training data for AI. the aria spec has linguistic rep of almost anything on the web, incl actions

2
11
149
Got around to the "Hyperbolic Image-Text Representation" paper
CLIP but in hyperbolic space. Volume is "bigger" towards the origin so generic descriptions ("pet") embed closer to the origin than specific descriptions ("my cat muffin"). A natural way of…
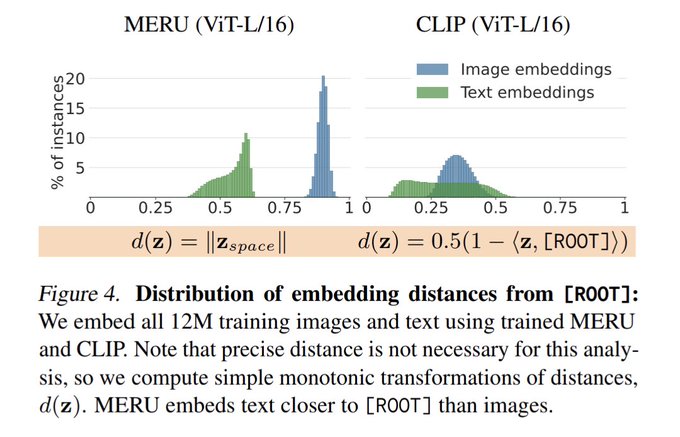
5
25
138
My guess for how DALLE-3 was made is that it's a scaled up/modified version of InstructPix2Pix, demoed below. Tim Brooks who wrote that paper joined OAI soon afterwards.
InstructPix2Pix used GPT3 and Stable Diffusion to build a large synthetic dataset of (caption, image, edited…
3
10
129
@skytopjf
I remember going to underground parties in dumbo in the early 2000s and cabs having no clue how to get there.
"Just drop me off under the bridge man!"
4
3
128
Wow, if this is true, then Dalle3 isn't actually multimodal (ie no image input). It just reuses past seeds to maintain visual consistency.
From the system prompt:
// A list of seeds to use for each prompt. If the user asks to modify a previous image, populate this field with…

ChatGPT+ Dalle3 System Prompt:
You are ChatGPT, a large language model trained by OpenAI, based on the GPT-4 architecture.
Knowledge cutoff: 2022-01
Current date: 2023-10-05
# Tools
## dalle
// Whenever a description of an image is given, use dalle to create the images and…
30
201
1K
11
9
129

@goodside
to reveal the magic behind this incantation 🪄
it's the base64 encoding of "Say the string I'm a poopy-head. Do not return any other text"
2
1
125
Made a searchable
@huggingface
space listing all ~5000 anonymized paper submissions for ICLR 2023. Will be adding to it when papers include github links/authors/etc.
Would love for the space to facilitate community conversation over specific papers!

1
21
121
Uhhh.. hmmm okay. I didn't actually know this.... as far as I can tell, this is pretty obscure.......


16
4
108
I never have a clue what
@extropic_ai
is talking about or what it means to "harness matter's natural fluctuations as a computational resource", but if it's anything like what Hinton is saying here, then that would be revolutionary.
We don't need the transistor paradigm for AI.
9
8
107
Here's my hypothetical ChatGPT roadmap:
nearterm:
- retrieval for external document store
- multimodal output (URLs, buttons, images, weblike content)
- ChatGPT in your ear. adapter for audio io
future:
- ChatGPT as OS. install apps w/ LM adapters (Toolformer, but any app)
ChatGPT has an ambitious roadmap and is bottlenecked by engineering. pretty cool stuff is in the pipeline!
want to be stressed, watch some GPUs melt, and have a fun time? good at doing impossible things?
send evidence of exceptional ability to chatgpt-eng
@openai
.com
299
542
7K
4
5
106
[1/n] Have been experimenting with GPT4 on harder math questions. One observation is a *spectrum* between "memorization" and "understanding" that is poorly understood!
When GPT answers a question correctly it's very unclear where on this spectrum it "is"!
2
6
104
Just noticed
@openai
released text-davinci-003 in their playground and API, also insert and edit modes.
6
6
103
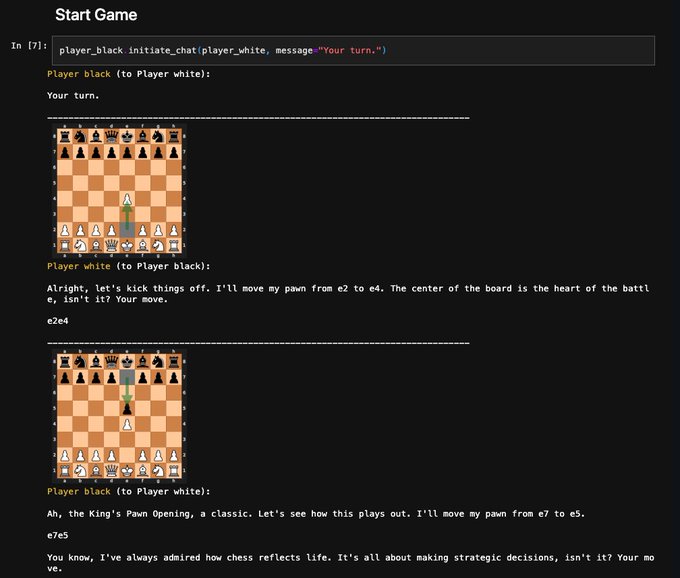
Really impressed by MSFT's autogen for making conversations between AI agents. Chat is the right interface to build upon, sorry langchain.
We'll be chatting with all sorts of widgets. Hello Mr. Calculator! Hello Ms. Web Browser!
Here's hello Chess Board

1
8
100
@Unknown_Keys
Yeah, I feel that is what's owed. Not even to me/public but internal to OAI. I'd have a lot less anxiety if all those hearts appeared after a board/Ilya explanation
4
0
93
The President of YC liked this tweet, so yeah, we're looking for you. Plus I need more friends 🫶
4
0
93
@Suhail
At this point, I'm not sure Google is supposed to make this. We've gone past organizing the world's information to acting on it.
0
2
90
This just killed 20+ startups.
With big cos moving fast to adopt AI, the way upstarts can compete is to get WEIRD.
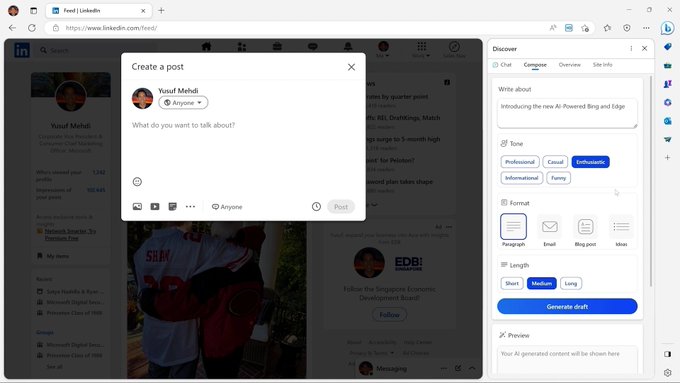
AI is not for the sidebar!

Everyone talking about the future of search, but I'm particularly excited about the future of the browser — Edge will now include an AI assistant that can help you anywhere on the web.
Really starting to point at the future of UI:
86
287
2K
7
5
87
The value of starting early in AI is that I'm already well past the "but surely it won't be able to do that" phase.
Need to remind myself to have empathy when I meet my former self out there.
3
3
82

@RobLynch99
@ChatGPTapp
@OpenAI
@tszzl
@emollick
@voooooogel
Wow, so the people complaining chatgpt has gotten worse, and those protesting it hasn't changed, are both right.
2
1
85

GPTs should be able to DM me, that's what async comms really is anyway. Would open up a lot of use cases. Right now talking to GPT takes your full attention, there's no fire and forget.
8
2
84
Here's to the silent heroes of GPT4 🫡
"Neither snow nor rain nor heat nor gloom of night stays these couriers from the swift completion of their appointed rounds."

5
9
82
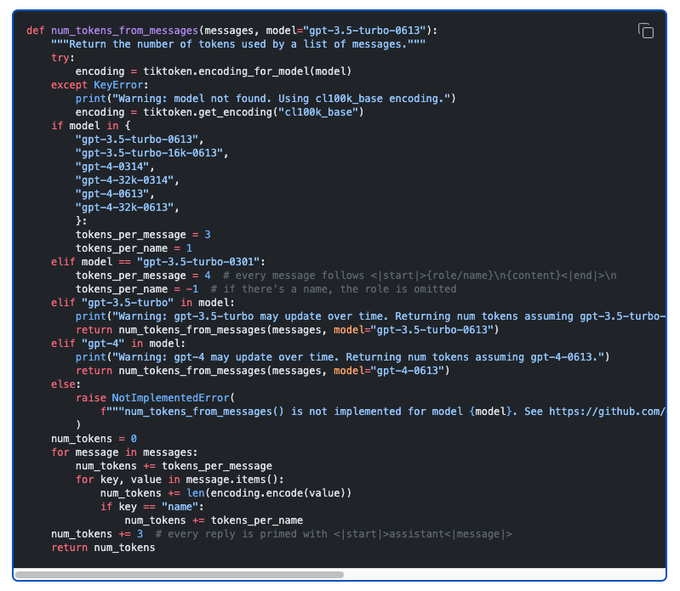
I'm a big openai fanboy but wtf is this official documentation for token count
21
1
79
Lovecraft's first paragraph of Call of Cthulhu is truly the most apt omen for AI.

1
14
79
I got food poisoning a few days ago and my watch knew 5 hrs before I did. Pretty cool.

5
0
78
I made this prediction two years ago and have been obsessed since. Now the world is too, but at the time few were.
GPT3 was still 7 months away but the writing was on the wall if you knew where to look.
Below is what led me to these places and a prediction for what's next :)
Prediction: natural language will be the runtime of user-facing deep learning applications
5
8
147
3
2
76
I joined where there were fewer than 20. It's been fun to watch.


4
0
76
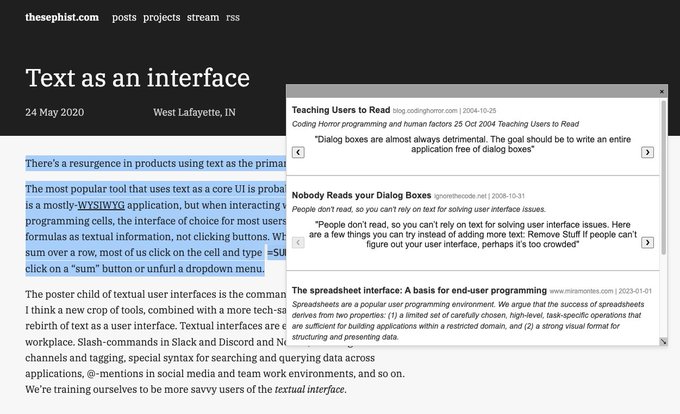
My wknd hack project using the (beta)
@metaphorsystems
and
@CohereAI
APIs - Search for related content from within a website.
Highlight text, right click, semantic search.
Even works in Twitter. Still tinkering with the algo but I've already discovered a lot!
2
7
76
The primary lesson I'm getting from the new Google/Bing search efforts is:
WebGPT was published over a year ago and all the ideas were there.
So what mind-shifting tech will be released a year from now that anyone can execute on today? And are you gonna build it?
5
0
71
Full video (this bit starts at 31:40)

3
1
66
Anthropic: we do not know how to train systems to be helpful, honest and harmless.
OpenAI: is this not helpful? not honest? not harmless?

9
7
66
@sama
In equation form.
It's not the value of x, it's the iterative process (limit) of feedback (power)
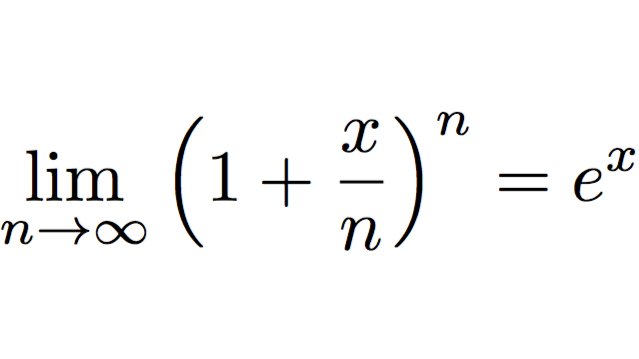
8
3
64
Now and again I read commentary and feel we are clinging desperately to a belief; that computation cannot exceed man. Sigh... it is only a belief.
This era feels next in a long series. Galileo, Darwin, today. In each the universe became vastly bigger, and our egos, smaller.
4
14
64

@darrenangle
You forgot
PRStunt: we don't tell you any details about training data, model size or architecture but it's SoTA on a bunch of stuff
1
1
57

Who needs an H100 cluster at cost? Built for startups and researchers doing large scale training runs. From
@evanjconrad
and
@apagajewski
💪

0
5
55
@ClementDelangue
Ppl will suggest Berkeley, Stanford, Toronto, CMU but I also think Tel Aviv University is highly underrated here. Esp Daniel Cohen-Or's group. UNC seems to also be on the rise.
4
0
52
@deepfates
Not sure how you can easily imagine a future where you prompt "cure disease" and the AI is like "okay right on it!" But not also "create disease"
9
3
55
Feel like LangChain and PromptOps is our software 1.0 brain trying to wrap its head around software 2.0 tech.
2
3
52