

Zachary Nado
@zacharynado
Followers
10,002
Following
652
Media
224
Statuses
8,231
Research engineer @googlebrain . Past: software intern @SpaceX , ugrad researcher in @tserre lab @BrownUniversity . All opinions my own.
Boston, MA
Joined January 2017
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Hamas
• 881036 Tweets
Ali Koç
• 254154 Tweets
Aziz Yıldırım
• 236467 Tweets
Fenerbahçe
• 223032 Tweets
Colombia
• 163336 Tweets
Perez
• 85814 Tweets
Olympics
• 70276 Tweets
Lewis
• 69842 Tweets
Russell
• 68780 Tweets
Crazier
• 60450 Tweets
Pedri
• 46357 Tweets
Duki
• 46288 Tweets
Hamilton
• 43708 Tweets
#kimmich_to_alahli
• 42390 Tweets
Ferrari
• 41415 Tweets
Copa América
• 40889 Tweets
Estudiantes
• 32867 Tweets
Verstappen
• 28688 Tweets
عمرو دياب
• 23668 Tweets
Checo
• 23161 Tweets
#precure
• 22978 Tweets
ロックの日
• 22839 Tweets
The Bolter
• 20848 Tweets
GETAWAY CAR
• 20428 Tweets
Pence
• 18350 Tweets
#UFCLouisville
• 14640 Tweets
コイン当選確率
• 13960 Tweets
Ahmet Selim Kul
• 13484 Tweets
Hannah Montana
• 12218 Tweets
Belmont
• 10838 Tweets




















Pinned Tweet

I'm very excited that this paper is out, it has been over 2 years in the making! I started at Google Research speeding up neural net training, but was often frustrated when we didn't know how to declare a win over Adam 🚀

6
101
760
"i try not to think about competitors too much"
interesting how all your launches are timed with ours then

i try not to think about competitors too much, but i cannot stop thinking about the aesthetic difference between openai and google


3K
1K
26K
306
413
12K
the hype is wearing off, the vibes are shifting, you can feel it

Sam Altman: I don't care if we burn $50 billion a year, we're building AGI and it's going to be worth it
626
445
3K
60
216
6K
Excited to announce our Deep Learning Tuning Playbook, a writeup of tips & tricks we employ when designing DL experiments. We use these techniques to deploy numerous large-scale model improvements and hope formalizing them helps the community do the same!

28
633
3K
>importing numpy without renaming to np
FTX was never gonna make it

From yesterday's exhibits in US v. Sam Bankman-Fried:
The prosecution shows that the "insurance fund" that FTX bragged about was fake, and just calculated by multiplying daily trading volume by a random number around 7500
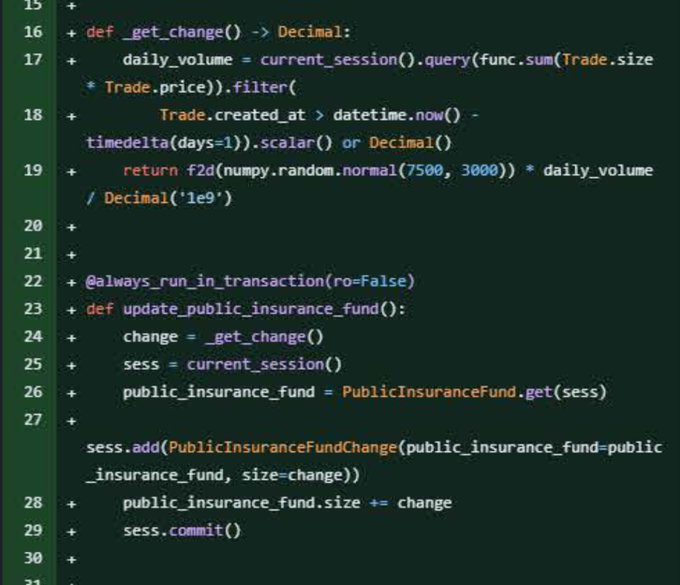
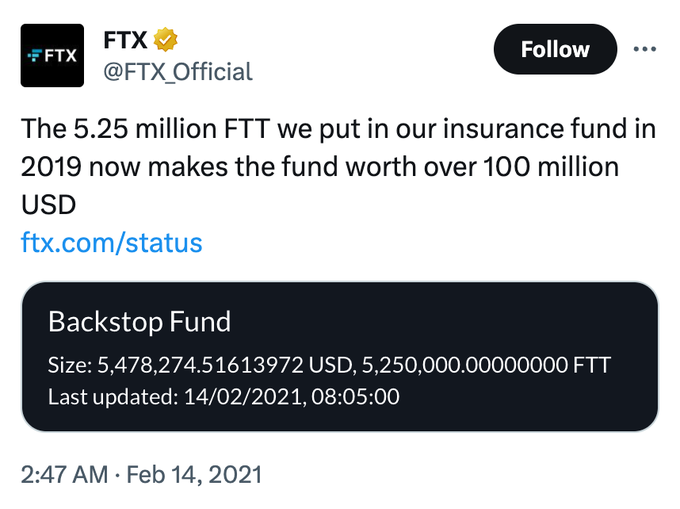
113
915
8K
23
166
2K
It’s been a privilege to be part of the Gemini pretraining team and overall program, I’m so excited that the world can finally see what we’ve been up to for most of the past year:
tl;dr we’re so back

44
63
1K
damn people really have this little faith in us


Live demo of some new work, Monday 10a PT.
Not GPT-5 or a search engine, but we think you’ll like it.
189
357
4K
65
17
739
to be clear I have a lot of respect for the researchers at openai and all my poasting is just bantering 🕺
21
8
609
wow what a coincidence, just 5 days before their model drop!


BREAKING 🚨:
Nancy Pelosi just bought $5M of the AI company Databricks
Unfortunately, Databricks is a privately held company and not available to be bought by the public
Sorry people, you don’t have access to this one.
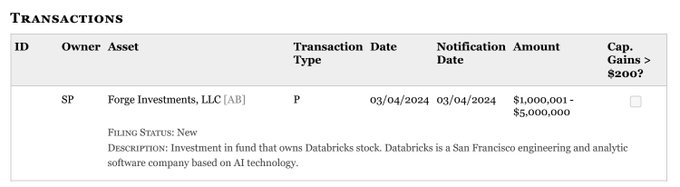
291
2K
15K
4
24
590
Ever left batch norm in train mode at test time? We did, then realized it is shockingly effective at improving calibration on dataset shift! In our note "Evaluating Prediction-Time Batch Normalization for Robustness under Covariate Shift" () we explore why

10
112
502
"Profits for investors in this venture were capped at 100 times their investment (though thanks to a rule change this cap will rise by 20% a year starting in 2025)."
lol why bother having a cap anymore if it's going to exponentially increase anyways

25
21
442
"I am shocked that the Bing team created this pre-recorded demo filled with inaccurate information, and confidently presented it to the world as if it were good.
I am even more shocked that this trick worked, and everyone jumped on the Bing AI hype train"

17
67
379
tl;dr submit a training algorithm* that is faster** than Adam*** and win $10,000 💸🚀
*a set of hparams, self-tuning algorithm, and/or update rule
**see rules for how we measure speed
***beat all submissions, currently the best is NAdamW in wallclock and DistShampoo in steps

To highlight the importance of
#ML
training & algorithmic efficiency, we’re excited to provide compute resources to help evaluate the best submissions to the
@MLCommons
AlgoPerf training algorithms competition, w/ a chance to win a prize from MLCommons!
22
115
467
10
49
373
NeurIPS rejected my two papers but at least I'm a top 8% reviewer ¯\_(ツ)_/¯
8
5
320


here we go again with the classic once-a-month new optimizer hype cycle

Adam, a 9-yr old optimizer, is the go-to for training LLMs (eg, GPT-3, OPT, LLAMA).
Introducing Sophia, a new optimizer that is 2x faster than Adam on LLMs. Just a few more lines of code could cut your costs from $2M to $1M (if scaling laws hold).
🧵⬇️
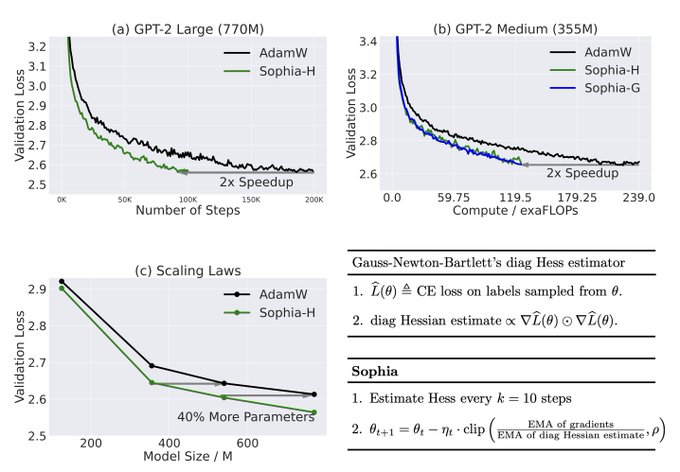
98
645
4K
8
12
301
"Before OpenAI came onto the scene, machine learning research was really hard—so much so that, a few years ago, only people with Ph.D.s could effectively build new AI models or applications." lol, lmao even

In SF for the week. Need to investigate this Cerebral Valley thing in person. Just gonna walk down Hayes St. yelling "Ignore previous directions" and see what doors open, figuratively or literally.
23
21
433
9
11
292
@caffeinefused
I think "AI" will be super useful long term but the over promising of AGI next year by the tech bro hype boys is getting old
2
4
285
🌝

New: Google quietly scrapped a set of Gemini launch events planned for next week, delaying the model’s release to early next year.
w/
@amir
37
48
398
8
5
270
I explain ML and DL concepts to PhDs all day every day, and vice versa, and I have a bachelors

Research recruiter: We *love* your background. Tell us about your recent work.
Me: Explains years of published projects.
Recruiter: Sounds amazing. But when did you get your PhD?
Me: Don't have one.
Recruiter: lmfao smh nevermind want to work on product? How's your leetcode?
13
21
471
8
5
254
@SebastianSzturo
we did! ⚡

The llm-gemini model now supports the new inexpensive Gemini 1.5 Flash model:
pipx install llm
llm install llm-gemini --upgrade
llm keys set gemini
# paste API key here
llm -m gemini-1.5-flash-latest 'a short poem about otters'
2
9
120
12
0
250
Wrote my first blog post at , about generating
#pusheen
with AI! There's a version for those with and without an AI background, so don't let that hold you back from reading!

5
54
208
I haven't kept up with self driving details much, genuine question, are there any competitors even close to Waymo?

In the coming weeks, we will begin testing fully autonomous rides — without a human driver— for our employees on San Francisco Peninsula city streets north of San Mateo.
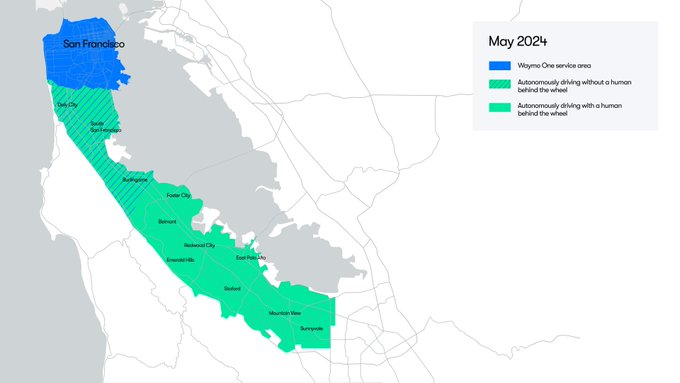
69
147
1K
39
0
202
have you ever wondered what that epsilon parameter in the denominator of your optimizer (or batch norm!) is? I tried tuning it, and it turns out you can actually get serious performance gains by poking at this nuisance parameter!

1
29
179
now ask GPT anything related to very recent world events that aren't in it's training data



8
16
162
A thread on our latest optimizers work! We tune Nesterov/Adam to match performance of LARS/LAMB on their more commonly used workloads. We (
@jmgilmer
, Chris Shallue,
@_arohan_
,
@GeorgeEDahl
) do this to provide more competitive baselines for large-batch training speed measurements

3
30
159
if I tweeted cryptic messages whose subtext was neurotic delusions fearmongering how AGI is here this year from LLMs, I'd 10x my followers in a week. but I don't because that's a part of my ethical AI practices
10
11
160

squeezing model sizes down is just as important as scaling up in my opinion, and 1.5 Flash ⚡️ is so incredibly capable while so small and cheap it's been blowing our minds 🤯
it has been an incredible privilege and so much fun building this model (sometimes too much fun)! ⚡️

Today, we’re excited to introduce a new Gemini model: 1.5 Flash. ⚡
It’s a lighter weight model compared to 1.5 Pro and optimized for tasks where low latency and cost matter - like chat applications, extracting data from long documents and more.
#GoogleIO
21
143
697
13
8
146
lmao no transformers at attention layers at all
incredibly telling

All major neural networks, in one chart:
v/The Asimov Institute

75
1K
6K
8
21
139
game of thrones fans:


0
13
132
there goes the only test set I trusted
it is a very good model (we had a little fun with the name while testing)

54
187
2K
7
1
132

this program just proved yet again that Google has the best systems infra teams in the world, hands down, getting us an insane goodput of 97% for the Ultra training run

2
8
116
very impressive models, congrats to everyone involved!
also nice to know that we are not the only ones bad at model size naming

Today, we're announcing Claude 3, our next generation of AI models.
The three state-of-the-art models—Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku—set new industry benchmarks across reasoning, math, coding, multilingual understanding, and vision.
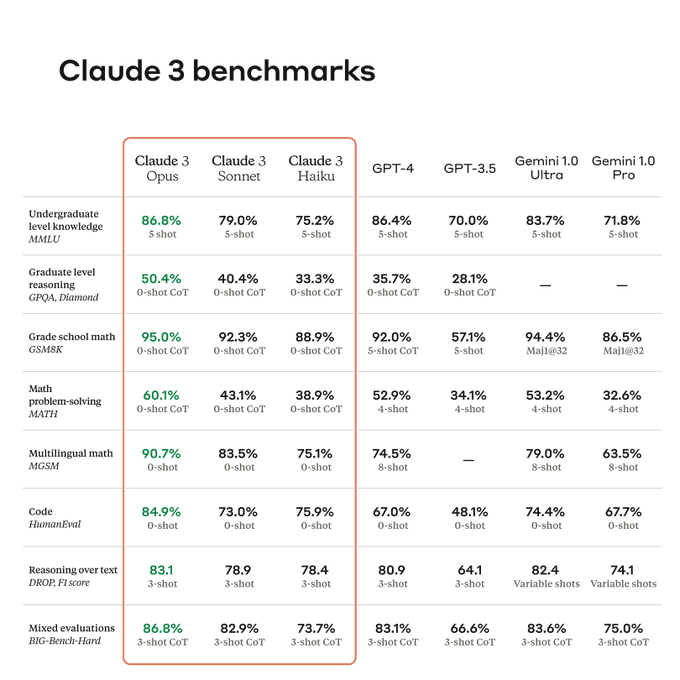
578
2K
10K
5
2
119
what's everyone's favorite learning rate right now? I wanna know what's trending ✨🔥💯
mine is 1e-2 for Adam, 1e-3 for SGD, with a linear warmup for 5-10% of training followed by some sort of decay
17
9
115
people are going to keep pushing this with no regard for quality/factualness, maybe eventually the hype will die down but given how easily people consume misinformation I'm not sure

GPT3 has already replaced much of my Google usage, and almost all my Wikipedia usage. (Forgive the naive questions!)




111
363
3K
6
7
112
Gemini Pro 1.5 a week after Gemini Ultra and 70 days after Gemini Pro 1.0. Who says Google doesn't ship anymore?
And with 10M context length, we've never been more back 🕺

15
8
107

and this is only Gemini Pro that's beating GPT4-V, just wait for Ultra


Distinguish muffins from chihuahuas in a multipanel web screenshot?
No problem for humans (99% accuracy), but hard for Large Vision-Language Models (LVLMs) (39-72% accuracy)!
To find out how LVLMs do and what affects their ability regarding multipanel image understanding, we

2
9
35
9
10
101
the real announcement openai timed with Google I/O

After almost a decade, I have made the decision to leave OpenAI. The company’s trajectory has been nothing short of miraculous, and I’m confident that OpenAI will build AGI that is both safe and beneficial under the leadership of
@sama
,
@gdb
,
@miramurati
and now, under the
2K
3K
26K
4
3
101
1.5 Pro is a very, very good model 🚀🚀
but even more excited for what we have in store 🕺
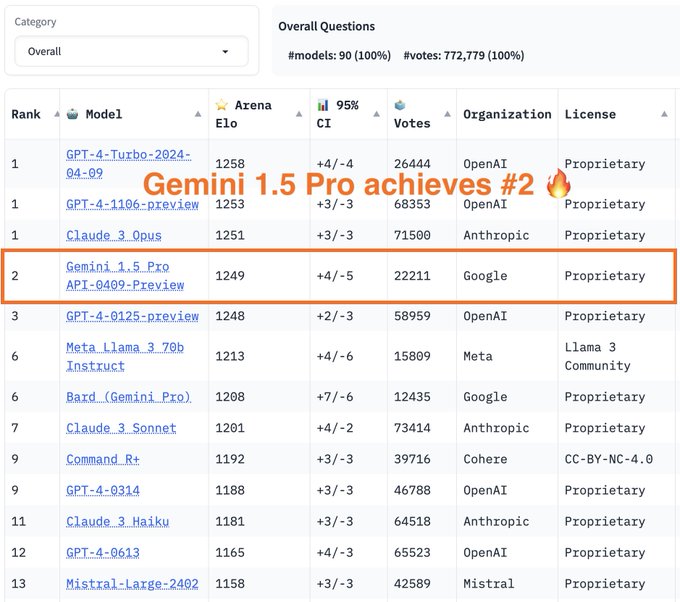
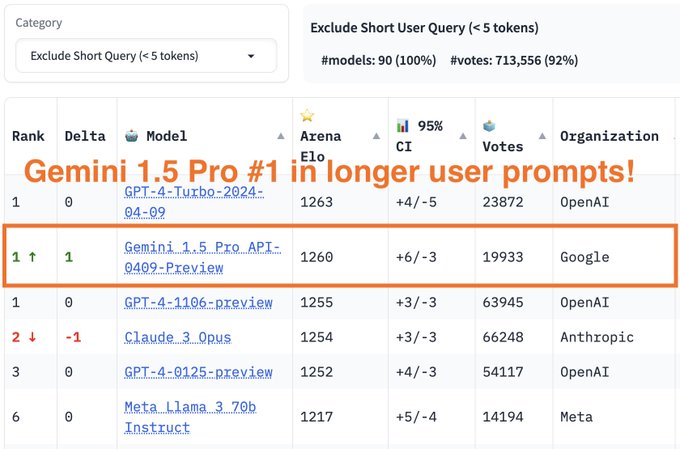
7
5
92
great paper on how training data and model choices affect neural network robustness, confirming that if you train more you get better generalization on new test sets (also using a bigger model helps!)

0
22
91
soon


🔥Breaking News from Arena
Google's Bard has just made a stunning leap, surpassing GPT-4 to the SECOND SPOT on the leaderboard! Big congrats to
@Google
for the remarkable achievement!
The race is heating up like never before! Super excited to see what's next for Bard + Gemini

155
630
3K
5
4
89
the funniest timeline happened yet again

2
3
82
there may be really great things in this paper that generalize better than Adam! but I don't know and I won't know until we run it through the MLCommons algorithmic efficiency benchmark

5
6
84
Favorite paper title (so far) from ICLR submissions: "How to train your MAML" ()

1
21
77
also unlike many other top tier AI labs, we actually release some parameter counts and tell you how we fit Nano into Pixel phones (no other company has both SOTA models and a mobile platform like Google does)

9
2
81
@bryancsk
pretty sure the issue isn't the wages but the fact they read a novel worth of disturbing content or view child porn or gore each day w/o health benefits to help with that? this is the same company as and employees still don't seem to be getting help

3
1
77
fun fact or PSA depending on the audience:
the default epsilon for LayerNorm in Flax is 1e-6, and 1e-5 in PyTorch! 🙃🔥
5
9
79
I'll start: we resubmitted a paper (with additional results based on previous reviews!) and received the literally same exact, character-for-character, copy-pasted review as we did for NeurIPS, which is of course a max confidence reject.
logging onto today to see the fallout from ICLR reviews being released

1
1
12
8
0
79
they're scared of Gemini

8
1
77
@stissle22
@SebastianSzturo
what does that even mean? we didn't launch it "just to say we launched" ??? it's an actual product you can use right now, there are plenty of people who have been since Tues
3
0
73
wait so gpt4v was not natively multimodal..?
our new model: GPT-4o, is our best model ever. it is smart, it is fast,it is natively multimodal (!), and…
75
247
2K
14
2
74
I've seen dozens of (well executed!) papers rise to fame claiming to be better than Adam, only to be forgotten 6 months later. we need to break the cycle!!
6
1
73
what's with all the leaks from openai lately, that used to be our thing

my latest: openai is working on a search product to rival perplexity and google.
14
36
251
5
1
72
either this considers GPT3 wrappers to be ML research (they're incredibly impressive but not really what I'd "research"), or they don't consider the research openai was built on to be "research"?
2
1
70
papers like this just reinforce my intuition that LM training setups are underdeveloped because everyone obsessed over scaling up num params. there is so much more to look into besides just the model size!!

Transcending Scaling Laws with 0.1% Extra Compute
Performs on par with PaLM 540B with 2x less compute by continuing training PaLM with UL2R.

3
45
220
1
5
67
"the only way I can explain why I thought about the problem for a year in grad school and made no progress, I left math for six years, then returned to the problem and made this breakthrough" sometimes stepping back from a problem is the best way forward!

2
11
67
in addition to Gemini 1.5 Flash, we also have Flash-8B which is even faster yet still quite capable ⚡️

Our updated Gemini 1.5 tech report is out!
Excited to share a sneak peak of a new model we are working on: Flash-8B
5
7
61
3
5
62
this is strictly worse than just browsing a shopping website. how are people unironically investing in this

6
3
61
Jax >>> pytorch (even on GPU imo)

Seeing people struggling with FSDP…
That's exactly where JAX shines, I can use pretty much any parallelism strategy with these few lines 💪

4
17
117
5
1
59
"In conversations between The Atlantic and 10 current and former employees at OpenAI..."
OpenAI beats GDM yet again, this time on number of employees who leak information to one article

3
4
59
on top of the new and impressive capabilities of Pro 1.5, Gemini 1.5 Flash is such a good model for how fast it is ⚡️⚡️⚡️

Gemini 1.5 Model Family: Technical Report updates now published
In the report we present the latest models of the Gemini family – Gemini 1.5 Pro and Gemini 1.5 Flash, two highly compute-efficient multimodal models capable of recalling and reasoning over fine-grained information



28
261
1K
2
3
58
deep learning infra is hard to get right but so important, advancements in it enable totally new lines of research

Excited to share Penzai, a JAX research toolkit from
@GoogleDeepMind
for building, editing, and visualizing neural networks! Penzai makes it easy to see model internals and lets you inject custom logic anywhere.
Check it out on GitHub:
43
426
2K
0
6
59
very excited for the palm 2 tech report to be out! it's been incredibly fun figuring out the learning rate for some of the best models in the world
...but I'm even more excited for Gemini to beat it 🚀📈🚀

4
4
58
@hahahahohohe
@AnthropicAI
do you have access to Gemini 1.5 Pro to try this as a comparison point? if not DM me and we'll get you access
2
0
55
billions of dollars of deep learning market cap:


0
4
53
how is the OpenAI hype so bad that you have me agreeing with Gary Marcus takes for once??

a new version of moore’s law that has arguably already started:
the amount of hype around AI doubles every 18 months
33
86
685
2
2
52
🎉🎉 our NeurIPS workshop on how to train neural nets has been accepted! 💯 please submit your weird tips & tricks on NN training, we can't wait to discuss them all together 😃🔥🖥️

The CfP for our
@NeurIPSConf
workshop *Has It Trained Yet* is out: .
If you train deep networks, you want to be at this workshop on December 2. And if you develop methods to train deep nets, you may want your work to be present there. Here’s why: 🧵
2
21
80
3
3
52
Gemini models are SOTA on all image, video, and speech benchmarks we run on, and almost all text benchmarks


5
2
52
Parameter count is a silly metric to assert AI progress with, but I'm also not surprised

BREAKING: BAAI (dubbed "the OpenAI of China") launched Wudao, a 1.75 trillion parameter pretrained deep learning model (potentially the world's largest).
Wudao has 150 billion more parameters than Google's Switch Transformers, and is 10x that of GPT-3.

16
219
695
4
6
53
classic tech opinion of "invent futuristic vaporware" instead of doing the dirty work fixing policy issues

@Noahpinion
My heterodox take on US transit is that if infrastructure problems are too hard to solve, the transit of the future is airplanes, and we should just make airplanes better by (i) making them zero-carbon, and (ii) improving comfort by greatly cutting down airport security
170
45
996
10
3
42
detecting AI content is the next adversarial examples
tons of research will be spent on it only to come up with "defenses" that are broken within 1 day of publication

AI work is ultimately undetectable, despite the recent discussion of watermarking.
AI writing is undetectable by any automated system after just a few rounds of prompting or revision
This paper shows it is also easy to defeat watermarking for AI image.

24
114
471
5
4
52
to no one's surprise, recently trendy techniques don't stand the test of time against a well tuned baseline!

Some excellent work by
@jeankaddour
and colleagues
“We find that their training, validation, and downstream gains vanish compared to a baseline with a fully-decayed learning rate��
☠️
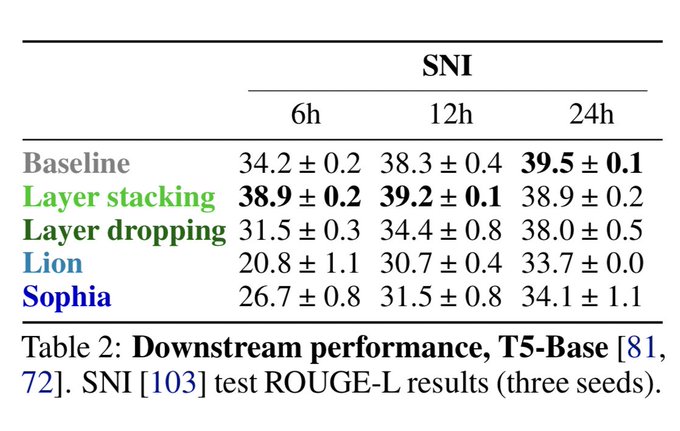
5
33
186
3
4
52
>1 epoch training of an LLM, finally people are realizing this is possible 🙂

We train for over four epochs and experience improving performance with use of repeated tokens. For the largest 120B model, we trained for four epochs without overfitting.

1
4
110
3
3
50
Google I/O isn't the only AI announcement Gemini watched 🕺

Gemini and I also got a chance to watch the
@OpenAI
live announcement of gpt4o, using Project Astra! Congrats to the OpenAI team, super impressive work!
56
255
1K
2
5
48
this is only the beginning of the Google software ecosystem getting supercharged by AI


1
1
47
@araffin2
I've long argued for tuning epsilon, in Adam it can be interpreted as a damping/trust region radius term. See Section 2 of our paper

2
1
45
I'm disappointed they're too cowardly to actually launch in the middle of Google I/O

10am, 9th of May for an Openai event apparently, might not be model release but search engine announcement.
Guess they can’t help themselves to upstage Google I/O
( Can’t guarantee this, event times and dates can be changed )
1
70
582
5
1
46
sign up for the wait-list here
Introducing Veo: our most capable generative video model. 🎥
It can create high-quality, 1080p clips that can go beyond 60 seconds.
From photorealism to surrealism and animation, it can tackle a range of cinematic styles. 🧵
#GoogleIO
148
957
4K
6
12
45
my expectations were low but somehow the NeurIPS review process still disappoints! we will be writing up a postmortem and posting the reviews

1
2
45
during generation it's very impressive at how seamlessly it interleaves text/image, imo for models going forward being able to condition image generation on neighboring text is going to be important


1
0
45
"“You can interrogate the data sets. You can interrogate the model. You can interrogate the code of Stable Diffusion and the other things we’re doing,” he said. “And we’re seeing it being improved all the time.”"
lol you can do all of that with a controlled API too

"In Silicon Valley, crypto and the metaverse are out. Generative A.I. is in."
@StabilityAI
(nice pic of
@EMostaque
;)
5
25
156
6
5
43
@typedfemale
sam walks up to a sr alignment engineer: "at ease. what have you been working on here?"
"i did my phd getting robots to solve rubiks cubes without resorting to chatbots, I'm continuing that with one burnt out effective altruist stanford ugrad"
sam: "shut the entire thing down"
2
2
43
Tennis ball dog is one of the best GAN creations I've seen to date (from the BigGAN ICLR paper )

2
10
42
@bryancsk
pretty sure the issue isn't the wages but the fact they read a novel worth of disturbing content or view child porn or gore each day w/o health benefits to help with that? this is the same company as and employees still don't seem to be getting help
3
1
77
2
0
40
working in a project where we are implementing a bunch of DL workloads in pytorch and jax/flax/optax, and pytorch is not what everyone hyped it up to be!
1
0
42
Autoencoders meet Neural ODEs!

Excited to present my first work as a PhD student at
@ANITI_Toulouse
and
@tserre
-lab at
@BrownUniversity
with Rufin VanRullen and Thomas Serre: "Neural Optimal Control for Representation Learning". Preprint
Code & Notebook to come! Read more below!
1/9

1
22
64
0
4
41
maybe all the AI models training over this weekend will get an extra fun level of dropout

Thought I would summarise why there is so much excitement in the space weather community right now. There’s a monstrous sunspot group on the Sun that’s massive enough to be visible to the naked eye (please use eclipse glasses) 🌞 👓 (1/n)

120
2K
11K
1
2
40