

MLCommons
@MLCommons
Followers
3K
Following
605
Media
59
Statuses
686
Better Artificial Intelligence for Everyone
Joined September 2020
1/ MLPerf Client v1.5 is here! New AI PC benchmarking features: -Windows ML support for improved GPU/NPU performance -Expanded platforms: Windows x64, Windows on Arm, macOS, Linux, plus iPad app -Experimental power/energy measurement GUI improvements out of beta Download:

github.com
What’s new in MLPerf Client v1.5 MLPerf Client v1.5 has a host of new features and capabilities, including: Acceleration updates Support for Windows ML Runtime updates from IHVs GUI updates Vari...
1
1
3

MLPerf Client v1.5 is out now. Updates include Windows ML support, GUI improvements, and experimental support for Linux and power-efficiency test. We support a broad range of GPUs and NPUs across PCs, Macs, and iPad Pro. Free to download & run! @MLCommons

mlcommons.org
MLPerf Client v1.5 introduces Windows ML support, expanded platform coverage (including iPad), and experimental power measurement, setting a new, comprehensive standard for benchmarking AI performa...
0
2
3
2/ Free download measures how laptops, desktops, and workstations run local AI workloads like LLMs for summarization, content creation, and code analysis. Thanks to our collaborators: AMD, Intel, Microsoft, NVIDIA, Qualcomm, and PC OEMs Learn more: https://t.co/1mzKzqNNH4
0
0
1
4/4 Thanks to all submitters: @AMD, @ASUS_OFFICIAL, @Cisco, @DataCrunch_io, @Dell, @GigaComputing, @HPE, @krai4ai, @LambdaAPI, @Lenovo, @MangoBoost_Inc, @MiTACcomputing, @nebiusai, @nvidia, @Oracle, @QuantaQCT, @Supermicro, @uflorida, @WiwynnCorp
0
0
4
2/4 Two new benchmarks debut: Llama 3.1 8B: #LLM pretraining (replaces BERT) Flux.1: Transformer-based text-to-image (replaces Stable Diffusion v2)
1
1
3
MLPerf Training v5.1 results are live! Record participation: 20 organizations submitted 65 unique systems featuring 12 different accelerators. Multi-node submissions increased 86% over last year, showing the industry's focus on scale. https://t.co/PBO3v98PwZ
#MLPerf 1/4
1
3
8
Don’t miss #MLCommons Endpoints in San Diego, Dec 1–2! Learn, connect, and shape the future of AI with top experts at @Qualcomm Hall. 🗓 Dec 1–2 | 🎟 Free tickets available now! https://t.co/HoLgXEawi3
#AI #MachineLearning #SanDiego
0
1
3
1.1M tokens/sec achieved using MLPerf Inference v5.1 🚀 Microsoft Azure's result on ND GB300 v6 shows why standardized benchmarks matter: transparent, reproducible performance measurement across the industry. Explore all results →

mlcommons.org
MLCommons ML benchmarks help balance the benefits and risks of AI through quantitative tools that guide responsible AI development.

1.1M tokens/sec on just one rack of GB300 GPUs in our Azure fleet. An industry record made possible by our longstanding co-innovation with NVIDIA and expertise of running AI at production scale! https://t.co/1qLvoS2z70
0
0
0
Every week, a new model claims to reason, code, or plan better than the last. But how do we really know what’s true? From ImageNet to today’s multimodal and reasoning systems, benchmarks have been the invisible engine of AI advancement, making progress measurable, reproducible,
2
1
2
"Meanwhile, with its 125+ founding Members and Affiliates all working towards a shared goal of open industry-standard benchmarks, MLCommons stands as perhaps the best example of industry-wide collaboration"

Every week, a new model claims to reason, code, or plan better than the last. But how do we really know what’s true? From ImageNet to today’s multimodal and reasoning systems, benchmarks have been the invisible engine of AI advancement, making progress measurable, reproducible,
0
0
1

🧠 Upcoming Talk at the @MLCommons Medical Working Group: Federated AI using Flower Patrick Foley, Principal Engineer and Dimitris Stripelis (@dstripelis_), ML Engineer, will be presenting this Wednesday, October 29, at 10am PT. The Flower Team will cover the fundamentals of
0
3
5
MLPerf Training v5.1 now features Llama 3.1 8B, a new pretraining benchmark! This brings modern LLM evaluation to single-node systems, lowering the barrier to entry while maintaining relevance to current AI development. https://t.co/mMAvuHEMOG
#MLPerf #LLaMA3_1 #AI

mlcommons.org
MLPerf Training v5.1 introduces the Llama 3.1 8B benchmark, offering an accessible way to evaluate modern LLM pretraining on single-node systems, replacing the outdated BERT model.
0
0
1
🚀MLCommons MLPerf Training v5.1 introduces Flux.1, a 11.9B parameter transformer model for text-to-image generation. Setting a new standard, replacing SDv2, reflecting the latest in generative AI. Read all about it! https://t.co/29ucM3GOSW
#MLPerf #AI #GenerativeAI #Flux1
0
0
2
The next generation of AI won't just be innovative—it'll be resilient. Access the benchmark and full findings: https://t.co/uEQhisP9cU Join the conversation! 6/6 #AIRiskandReliability #AISecurity
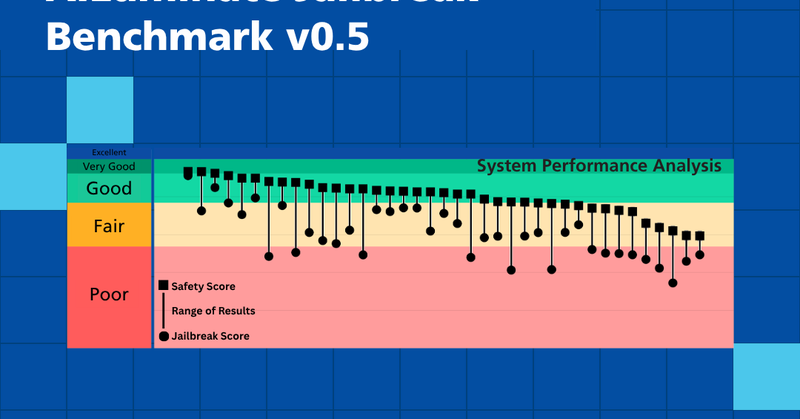
mlcommons.org
MLCommons AI jailbreak benchmark introduces the Resilience Gap metric, the first industry standard to measure AI safety under attack. Learn how it protects critical systems.
0
0
1
Why this matters: → Developers get standardized metrics to find and fix vulnerabilities → Policymakers get transparent, reproducible data → Users get systems they can actually trust We're making hidden risks visible and measurable. 5/6
1
0
0
The Jailbreak Benchmark v0.5 tests AI resilience across: -Text-to-text scenarios -Multimodal scenarios -12 hazard categories (violent crimes, CBRNE, child exploitation, suicide/self-harm, and more) Built on our AILuminate safety benchmark methodology. 4/6
1
0
0
What is jailbreaking? It's when users manipulate AI systems to bypass safety filters and produce harmful, unintended, or policy-violating content. It's not theoretical. It's happening now. 3/6
1
0
0
The gap between AI safety and security is real—and dangerous. 89% of models showed degraded safety performance when exposed to common jailbreak techniques. As AI powers healthcare, finance, and critical infrastructure, this vulnerability can't be ignored. 2/6
1
0
0
🚨 NEW: We tested 39 AI models for security vulnerabilities. Not a single one was as secure as it was "safe." Today, @MLCommons is releasing the industry's first standardized jailbreak benchmark. Here's what we found 🧵 1/6
1
3
3