
Tengyu Ma
@tengyuma
Followers
35K
Following
253
Media
79
Statuses
549
Assistant professor at Stanford; Co-founder of Voyage AI (https://t.co/wpIITHLgF0) ; Working on ML, DL, RL, LLMs, and their theory.
Joined June 2011
Adam, a 9-yr old optimizer, is the go-to for training LLMs (eg, GPT-3, OPT, LLAMA). Introducing Sophia, a new optimizer that is 2x faster than Adam on LLMs. Just a few more lines of code could cut your costs from $2M to $1M (if scaling laws hold). 🧵⬇️
96
623
4K
📢 Introducing Voyage AI @Voyage_AI_!. Founded by a talented team of leading AI researchers and me 🚀🚀. We build state-of-the-art embedding models (e.g., better than OpenAI 😜). We also offer custom models that deliver 🎯+10-20% accuracy gain in your LLM products. 🧵

38
94
761
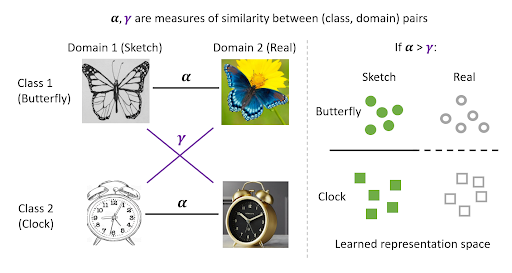
Pretraining is ≈SoTA for domain adaptation: just do contrastive learning on *all* unlabeled data + finetune on source labels. Features are NOT domain-invariant, but disentangle class & domain info to enable transfer. Theory & exps:
7
126
665
RL + CoT works great for DeepSeek-R1 & o1, but: . 1️⃣ Linear-in-log scaling in train & test-time compute.2️⃣ Likely bounded by difficulty of training problems. Meet STP—a self-play algorithm that conjectures & proves indefinitely, scaling better! 🧠⚡🧵🧵.

17
107
556
Very honored to be named as a 2021 Sloan Fellow. Thanks to all my group members and collaborators for their wonderful works! Thanks for appreciating our works on ML. Check out them on my Twitter homepage or website! #SloanFellow.
19
7
533
Releasing the code of Sophia 😀, a new optimizer (⬇️). code:
Adam, a 9-yr old optimizer, is the go-to for training LLMs (eg, GPT-3, OPT, LLAMA). Introducing Sophia, a new optimizer that is 2x faster than Adam on LLMs. Just a few more lines of code could cut your costs from $2M to $1M (if scaling laws hold). 🧵⬇️
18
97
516
If you are interested in training deep models without batchnorm, or why batchnorm can help training, please check out our paper! Arxiv link . Thanks to @ajmooch for the tweet and re-implementation!.

Fixup (formerly ZeroInit) by H. Zhang, Y.N. Dauphin, and @tengyuma (ICLR2019): They manage to train deep nets (10k layers!) w/o BatchNorm, by careful init scaling & initializing the 2nd residual conv to 0. My @PyTorch impl. here:

3
153
525
Why does contrastive learning magically produce linearly separable features? We leverage spectral graph theory to analyze it under realistic settings. (In contrast, many prior works require that positive pairs are independent conditioned on the label.)

1
84
518
An introductory and short survey on nonconvex optimization for machine learning problems A chapter of Beyond the Worst-Case Analysis of Algorithms edited by @algo_class.

3
85
491
A new paper on improving the generalization of deep models (w.r.t clean or robust accuracy) by theory-inspired explicit regularizers.
0
80
404
Thinking of applying self-supervised learning (SSL) on your uncurated, imbalanced datasets? Good news: we found SSL is more robust to long tails than supervised representations. We also present theoretical and empirical analyses and an improved algorithm.

5
79
390

WSD learning rate is taking off—lower loss, no pre-set compute budget, & easier continual training. Yet, its loss curve is puzzling—high in stable phase but jumps in decay phase. Our paper explains it with a 'River Valley' structure of the loss! 🧵🧵

11
62
329
Our recent paper that tries to explain why over-parameterized models can even help generalization: bigger models always have larger max-margins, and a weak regularizer + logistic loss can give the max-margin!.
0
71
280
DL models tend to struggle with heteroskedastic and imbalanced datasets, where long-tailed labels have varying levels of uncertainty, partly bc it's hard to distinguish mislabeled, ambiguous, and rare examples. We propose a new regularization technique:

4
40
279
The double descent curves are intriguing; but do you also somewhat miss the classical U-curves (like me)? One possible option: change the x-axis of your visualization. Below, the x-axis is 2-norm, and the color and arrow indicate how # of params changes.

7
40
273
We analyze self-training for domain adaptation, semi- and unsupervised learning, showing that pseudolabels are denoised through implicit propagation of correct labels via consistency regularization when data satisfy an expansion property. (More in Fig.)

3
38
273
Updates on Sophia ✨. 1. It also works very well for 1.3B and 6.6B, with little tuning on top of tuned Adam! . 2. More tips on efficient hyperparam tuning . 3. More ablation showing all parts are necessary

Adam, a 9-yr old optimizer, is the go-to for training LLMs (eg, GPT-3, OPT, LLAMA). Introducing Sophia, a new optimizer that is 2x faster than Adam on LLMs. Just a few more lines of code could cut your costs from $2M to $1M (if scaling laws hold). 🧵⬇️
4
39
266
RNNs and transformers with *infinite*-precision are universal approximators---but are they statistically learnable? We show that even finite-precision transformers can express any Turing machine, and they are learnable with polynomial samples.

4
40
246
Pretrained language models are trained with losses quite different from downstream tasks; why can they help? Why does prompt tuning work so well? We analyze them under generative assumptions of the language (HMMs or more realistic variants)

2
42
252
What issues can make OpenAI down for 9.5 hours? I am sooo curious. 🧵. Any hypotheses?
42
6
232
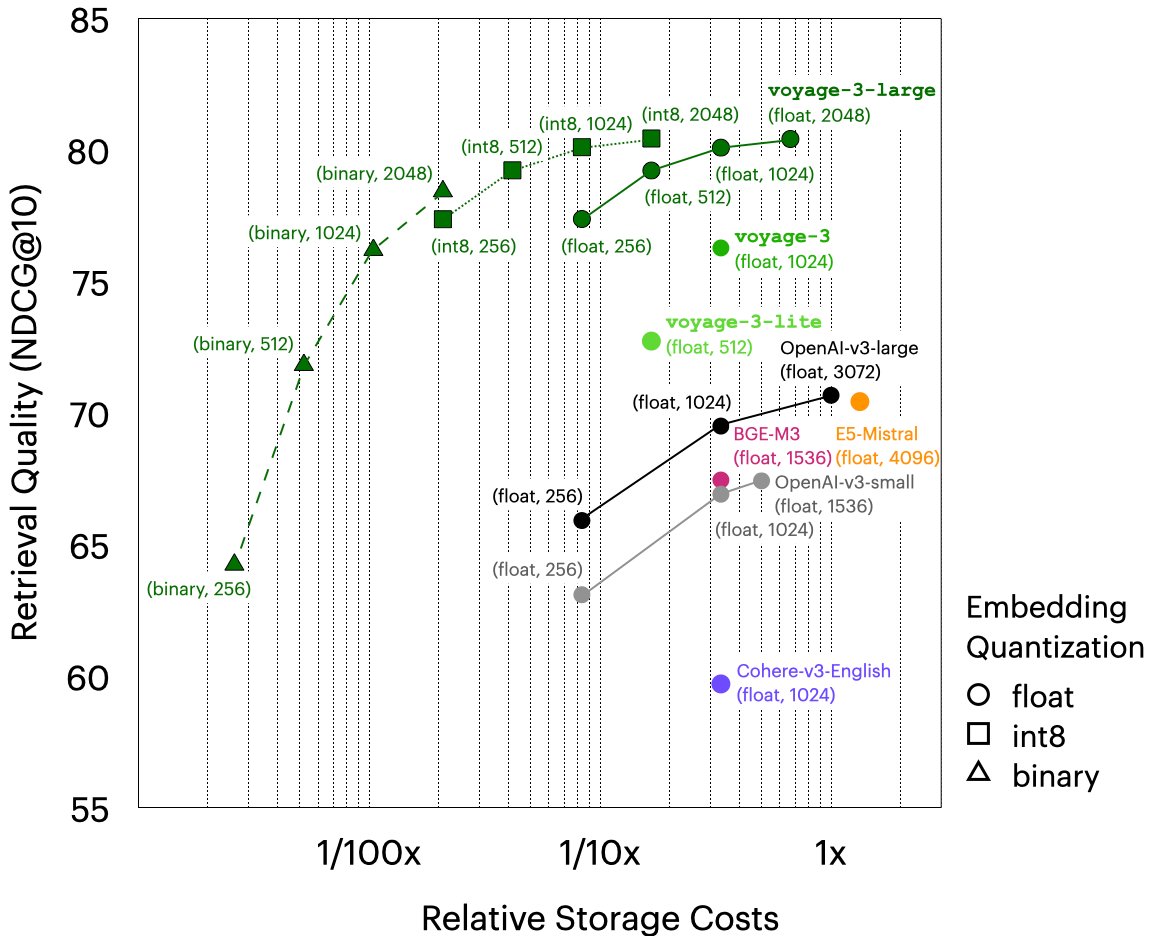
Proud to share our best model yet, pushing boundaries again and outperforming all models on all domains (except voyage-code-3 on code). Our binary, 1024-dim embeddings are 5.53% better than OpenA, float, 3072 dim. If you spent $10k monthly on storage, now it’s $104 with us!.

📢 Announcing the new SOTA voyage-3-large embedding model!. • 9.74% over OpenAI and +20.71% over Cohere.• flexible dim. (256-2048) and quantizations (float, int8, binary).• 8.56% over OpenAI with 1/24x storage cost.• 1.16% over OpenAI with 1/192x storage cost ($10K → $52)
9
27
230
Really enjoyed the chat with @saranormous on RAG and embeddings, and all the past work with her on @Voyage_AI_ !.

.@NoPriorsPod drop, all about embeddings models and retrieval systems with Stanford AI prof and @Voyage_AI_ founder @tengyuma . - Headroom in embeddings.- Hierarchical memory for LLMs.- RAG vs fine tuning vs agent chains.- Why we (still) need RAG.- Advice for building RAG systems
6
20
204
🆕📢 Checkout @Voyage_AI_ (during @OpenAI 's drama 👀). 1. Officially #1 embedding on @huggingface MTEB leaderboard, ahead of @OpenAI ada & @cohere new v3 😜. 2. Now supporting distinguishing docs & queries — different prompts added in the backend, gaining 1.2% on average.

11
30
202
🆕📢 @Voyage_AI_'s new embedding models: voyage-2 & voyage-code-2!. 1. 🔼 +17% accuracy gain on 11 code datasets vs @OpenAI .2.🥇 # 1 on MTEB & diverse corpora.3.⚡ Production-ready latency.4.🛒 Available on AWS Marketplace, meeting compliances.5.📜 16K context length. #LLMs

6
37
195
Personally, some cool things about this project 😊: (a) it demonstrates that we can still study LLM pre-training in academia where we have much less compute, and create new algorithms with impact.
3
11
186
Past works found empirically that one-layer transformers can learn in-context the gradient descent algorithm (when they are trained with in-context linear regression datasets). In our paper at #ICLR2024 , we give theoretical proof for why it’s GD (rather than other algorithms)🧵

4
26
186
When and how can models extrapolate to unseen domains? . Previous understanding is mostly limited to linear models or well-covered new domains. We make some first baby steps beyond these by considering *structured* domain shift and nonlinear models. 1/n

4
32
184
We theoretically prove that not only the scale of the noise in SGD has an implicit regularization, but its covariance also matters. For a simple model, SGD with label noise biases towards sparsity and leaves the NTK regime, whereas Gaussian noise does not.
4
21
172
Honored to receive the best paper award in COLT: "Algorithmic Regularization in Over-parameterized Matrix Sensing and Neural Networks with Quadratic Activations" Congrats to Yuanzhi and Hongyang!.
6
19
168
Conventional wisdom: SGD prefers flat local minima. How *rigorously* can we characterize this? We prove that label-noise SGD converges to stationary points of training loss + a flatness regularizer, by coupling it with GD on the regularized loss. . 0/6

2
25
171
A 100h/week job (e.g., CEO of a startup) apparently easily becomes a 24/7 job, where the job description of the remaining 68h is "forget about what happened in those 100h, just enjoy life, family, and sleep". And it's much much harder to succeed in those 68h than in those 100h.
7
10
166
Our journey started last year when we realized that embedding models were underloved and under-explored. Today, we have the best-in-class embeddings & rerankers, incredible partners such as @AnthropicAI , @harvey__ai, and several deployment options. Huge thanks to our.
Thrilled to share that we've closed $28M in funding, led by @CRV, with continued support from @wing_vc and @saranormous. Also excited to onboard strategic partners @SnowflakeDB and @databricks!. Building the world’s best models for RAG and search 🧵🧵🧵:.
8
14
165
Some features can spuriously correlate with labels but do not cause them. Models relying on these features are biased and non-robust to varying correlations. We show self-training on an *unlabeled*, more diverse dataset can avoid using spurious features.

1
28
145
Four out of my five NeuRIPS submissions had simultaneously a rating of 3 and a rating of 7. None of the five papers has a rating of 5. 😂 is perhaps the best emoji for this tweet---shall I joy or cry?.
11
1
146
Model-based planning vs policy optimization? Planning can be stronger when the Q-functions and policies are more complex than the dynamics. Such cases exist in theory and are practically relevant. This inspires a method that outperforms SOTA on humanoid!
1
23
137
It's pretty impressive that a 400M model can be better than OpenAI v3 large!.
📢 Announcing a new generation of Voyage embedding models: voyage-3 and voyage-3-lite!. When compared with @OpenAI's v3 large:.voyage-3: + 7.5% accuracy, 2.2× cheaper, 3× smaller embeddings, 4× context.voyage-3-lite: + 3.8% accuracy, 6× cheaper, 6× smaller embeddings, 4× context
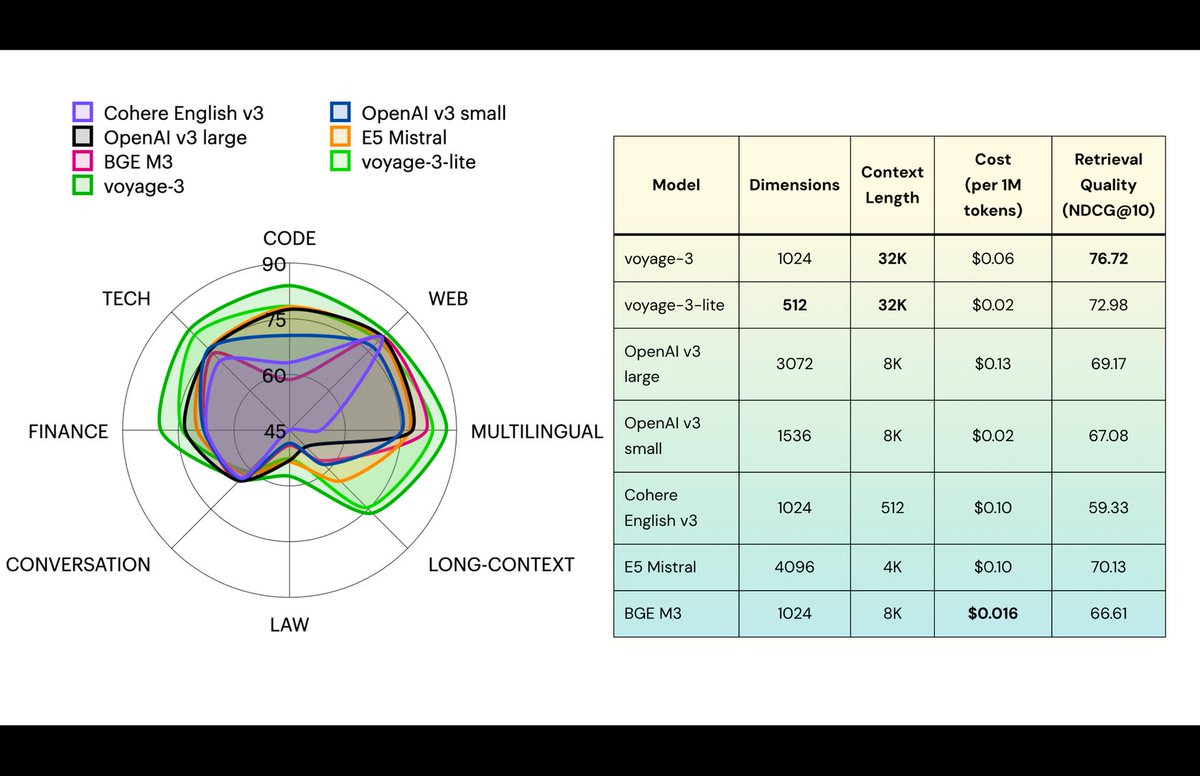
1
13
136
Some interesting (surprising?) findings: . Larger models know more but are also more receptive to new information in the in-context exemplars. Instruct-tuning helps in-context learning of semantically-unrelated labels but hurts in-context learning of flipped labels.

New @GoogleAI paper: How do language models do in-context learning? Large language models (GPT-3.5, PaLM) can follow in-context exemplars, even if the labels are flipped or semantically unrelated. This ability wasn’t present in small language models. 1/

2
22
125
OpenAI’s embedding v3 were out 🎉! Curious about its quality? We tested on 11 code retrieval datasets & 9 industry-domain datasets:. 1. @OpenAI v3 > ada-002 & cohere (except v3-small on code).2. voyage-code-2 is the best with + 14% margin on code & + 3% on industry docs 🚀
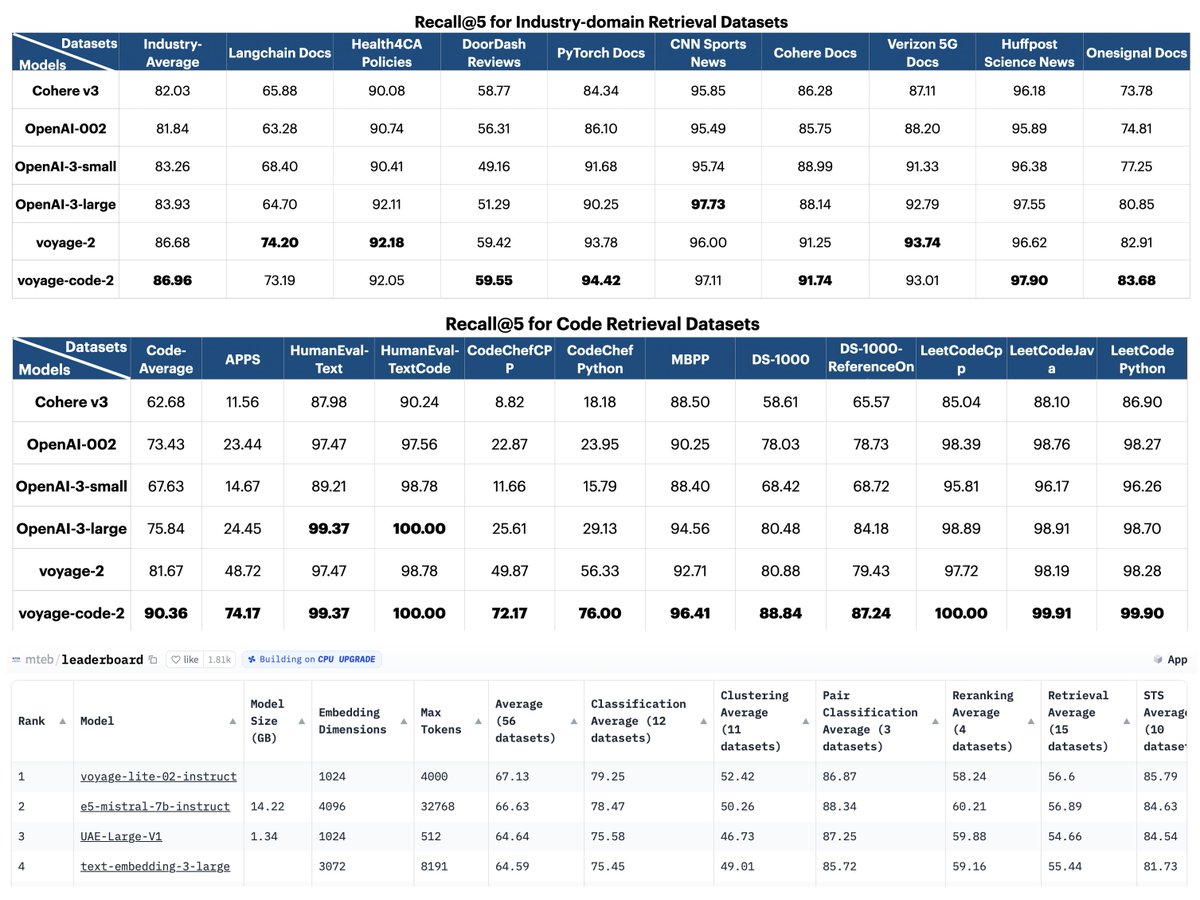
🆕📢 @Voyage_AI_'s new embedding models: voyage-2 & voyage-code-2!. 1. 🔼 +17% accuracy gain on 11 code datasets vs @OpenAI .2.🥇 # 1 on MTEB & diverse corpora.3.⚡ Production-ready latency.4.🛒 Available on AWS Marketplace, meeting compliances.5.📜 16K context length. #LLMs
6
22
126
Past theory for domain generalization often suggests the number of training domains has to scale linearly in dimension. Any hope to work with a more realistic # of domains? We give an algorithm that needs log-in-dim # of domains on a toy data model 1/6

2
33
119
“The length of CoT can be super long”: if I still remember the paper correctly, the CoT steps needed is linear in the number of gates needed to solve the problem, or linear in the input length for a NC1-complete problem. I also vaguely remember that it takes exponential number.

While CoT is super useful, I kindly disagree that blindly scaling it up is all we need. The paper proposes a universal approximation theorem by explicitly constructing Transformer weights to fit to the family of tasks. Although the depth can be constant, the length of CoT can.
3
12
117
New engineering interview at @Voyage_AI_ starting from Q3: . 1. pick one or more challenging questions that typically take 5 hours .2. ask the candidate to solve them in 1 hour.3. allow them to use GPT4. pros: testing the right skill.cons: need to recalibrate when GPT-5 is out.
15
10
109
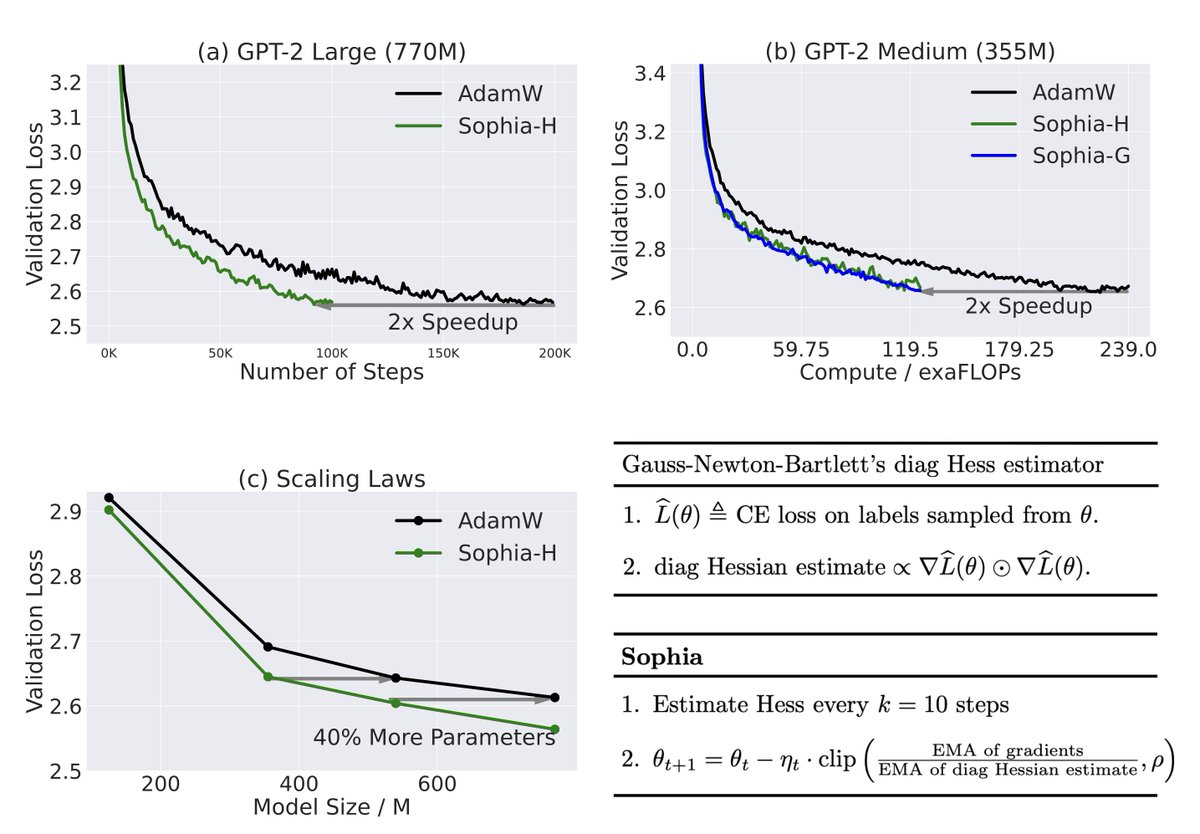
Sophia applies a stronger penalization to updates in sharp dimensions (w/ large Hessian) than flat dimensions (w/ small Hessian), ensuring a uniform loss decrease across all parameter dimensions. Adam has a slower convergence in flat dimensions. Visualization on a toy case below.

3
7
111
Very honored to receive it!.

Recent Ph.D. grads Tengyu Ma (center left) and Ryan Beckett (center right) received Honorable Mentions for the @TheOfficialACM's Doctoral Dissertation Award for Outstanding Ph.D. Thesis at their gala event on Saturday. @tengyuma

3
1
110
(b) We used a lot of *theoretical* thinking in the research process, besides recalling our optimization classes :). Joint work with an amazing team at Stanford: @HongLiu9903, @zhiyuanli_, @dlwh, @percyliang.
3
4
107
Does the validation pre-training loss in language modeling always correlate with downstream perf.? . We find it's not necessarily true even with the same architecture. This means that the implicit bias of pre-training algorithms is another key factor!.

3
20
104
Sophia pre-conditions the gradient with a lightweight estimate of the diagonal Hessian, followed by an element-wise clipping (pseudo-code in first figure), and is easily implementable with the PyTorch code below.

7
7
94
🆕📢 @Voyage_AI_'s new embedding model for legal and long-context retrieval and RAG: voyage-law-2!. 1.🥇 # 1 on MTEB legal retrieval benchmark with a large margin.2.📜 Best quality for long-context (16K) .3.✨ Improved quality across domains.4.🛒 On AWS Marketplace . #RAG #LLMs

4
25
92
How to make the minority/rare classes generalize better? Enforcing class-dependent margins (following a theory-inspired formula) helps a lot! Please check out our recent paper if you are interested in learning imbalanced datasets @adnothing.
1
19
94
Our method decomposes the embedding for a word (e.g, "spring") into a sum of multiple sense/discourse embeddings (e.g., different meanings of "spring"). I still remember those fun times when I learned more meanings of polysemous English words 👇


With sparse coding again popular for interpretability in LLMs please look at older work! "Latent structure in word embeddings" Atoms of meaning" Decoding brain fMRI via sentence embeddings
2
11
91
In RL, minimax results bound the regret on the *worst-case* instance; can we customize the algo & bound to a particular instance? Somewhat surprisingly, we identify the optimal asymptotic regret for *each* instance and design an algo to achieve it.

3
15
88
Optimism is the golden rule in bandit and RL, but deep RL practice doesn’t use it much. We prove that optimism with neural nets explores excessively. Instead, we design a new algo (ViOL) that explores via model-based curvature estimate with regret bounds.
1
9
86
Super excited to partner with @harvey__ai's team and @gabepereyra! . TLDR: our legal embedding model, voyage-law-2, already improves retrieval quality on general legal documents, but fine-tuning it on specific legal data helps a lot more.

@harvey__ai is excited to partner with @tengyuma and @Voyage_AI_ to build custom legal embeddings for our RAG and agent systems.
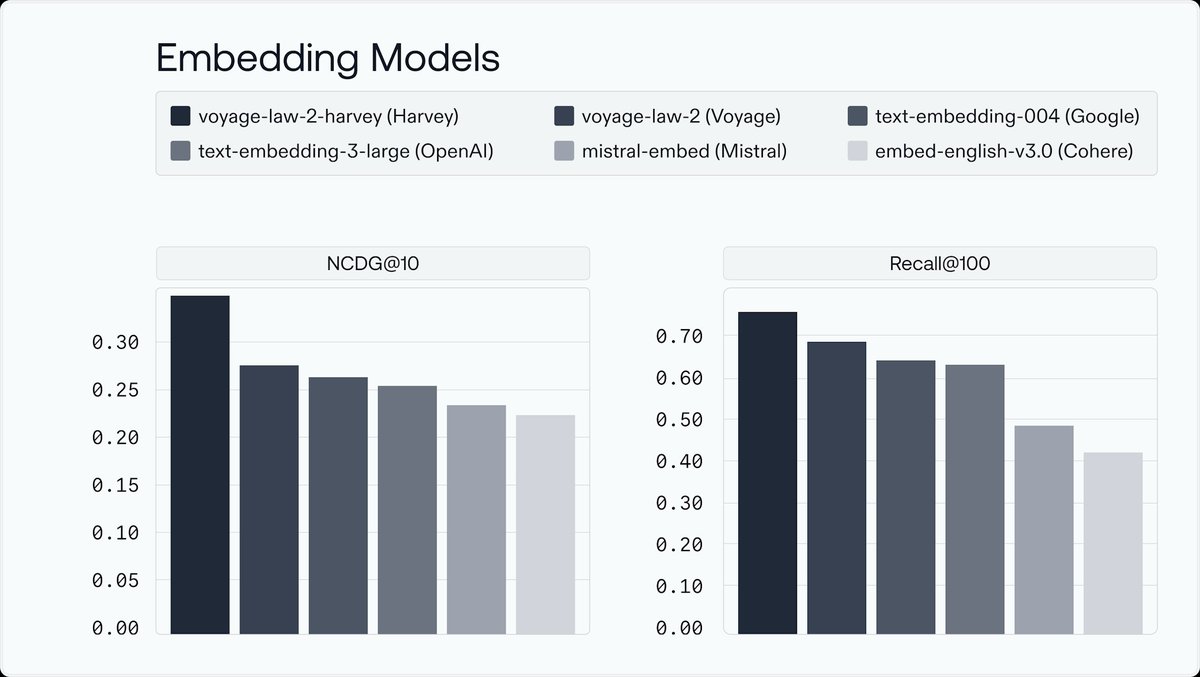
2
15
79
On GPT-2 of sizes from 125M to 770M, Sophia achieves a 2x speed-up compared with Adam in the number of steps, total compute, and wall-clock time (Fig. a&b, above). The scaling law (Fig. c, above) based on model size from 125M to 770M is in favor of Sophia over Adam.
1
2
73
A cross-encoder reranker can significantly improve your search / retrieval accuracy and is incredibly easy to use — it’s just an API call on top of any search methods. Very impressed by our team at @Voyage_AI_ for the amazing work on this SOTA reranker!.
🆕📢 We are thrilled to launch rerank-1, our best general-purpose and multilingual reranker! It refines the ranking of your search results with cross-encoder transformers. It outperforms Cohere's english-v3 on English datasets and multilingual-v3 on multilingual datasets 🚀.
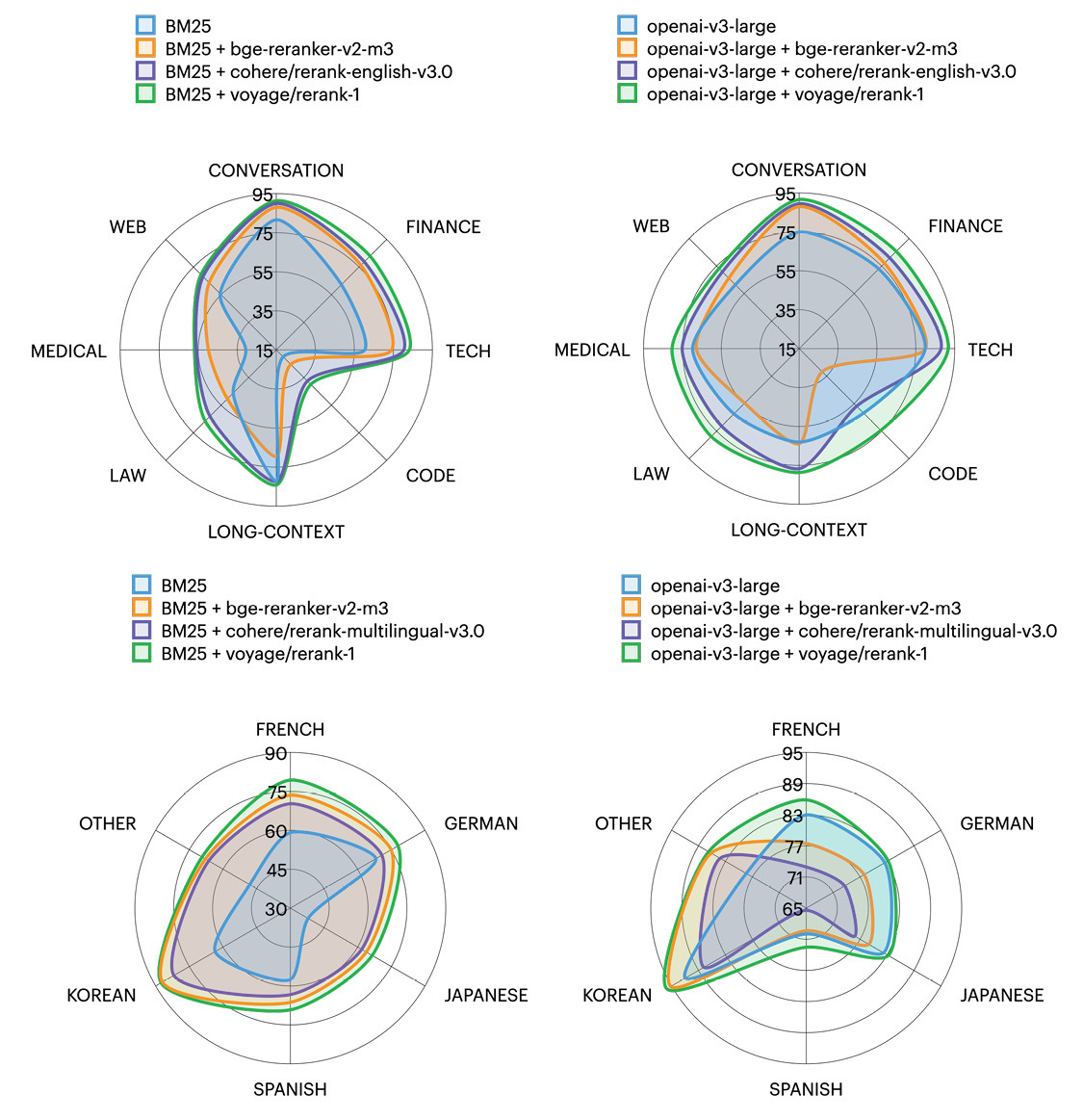
3
9
73
Sophia also improves pre-training stability. It doesn’t need the re-parameterizing trick where the temperature of attention depends on the layer index. Gradient clipping is triggered much less frequently than Adam and Lion.

1
2
68
It's great to see ML theory workshops again at NeurIPS.

🚨💡We are organizing a workshop on Mathematics of Modern Machine Learning (M3L) at #NeurIPS2023!. 🚀Join us if you are interested in exploring theories for understanding and advancing modern ML practice. Submission ddl: October 2, 2023.@M3LWorkshop

0
4
67
With strong multimodal embeddings, we can search the PDFs, slides, tables, etc, by screenshots, without unstructured data ETL. The embedding models will do even more in the future!.
📢 Announcing voyage-multimodal-3, our first multimodal embedding model!. It vectorizes interleaved text & images, capturing key visual features from screenshots of PDFs, slides, tables, figures, etc. 19.63% accuracy gain on 3 multimodal retrieval tasks (20 datasets)! 🧵🧵
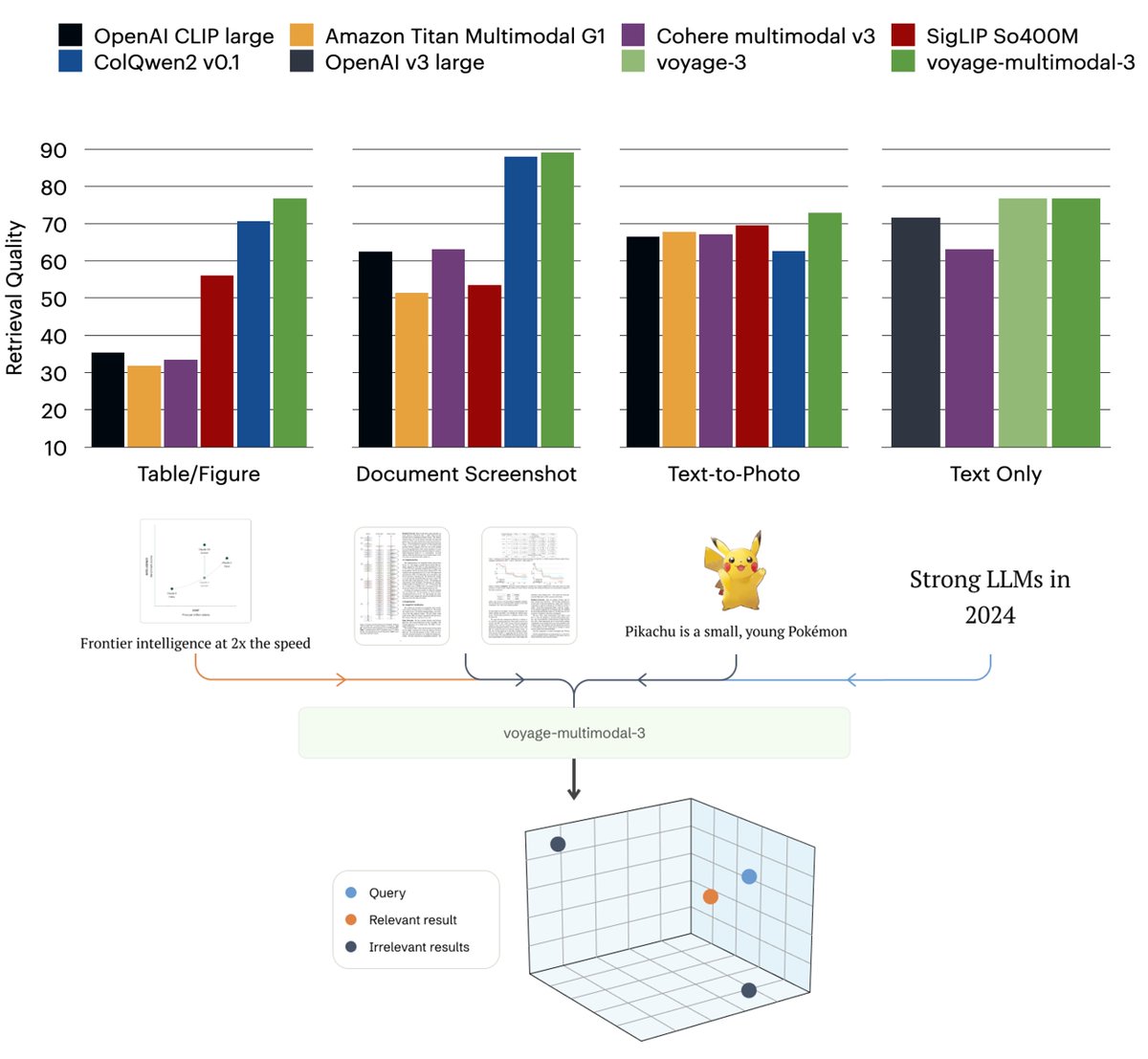
3
6
71
In increasing difficulty, . 1. train artificial neural nets .2. train one’s own biological neural net .3. train others’ neural nets . Level 1.5: train others’ neural nets when others are also willing to train their own— that’s why profs can mentor even though they may fail at 2.
1
2
68
Thanks for trying our optimizer! hope that Sophia can save some compute for FAIR and others :).

No replies here. Decided to try out on our own benchmarks, consisting of an auto-regressive, multi-modal pre-training at scale. Pretty complex setting. Yellow: Tuned (LR) AdamW.Purple: Tuned (LR) Sophia. Average Loss:

1
3
65
Online learning is a classical approach to address the domain shifts in a data stream but requires iterative labeling. We propose to only query the label of uncertain data and give a regret guarantee that leverages the hidden domain structure.
1
3
65
A simple importance resampling can help select good training data for LMs: our filtered Pile dataset improves 2% GLUE acc! . Main idea: estimate importance weights in an n-gram feature space.

Data selection for LMs (GPT-3, PaLM) is done with heuristics that select data by training a classifier for high-quality text. Can we do better?. Turns out we can boost downstream GLUE acc by 2+% by adapting the classic importance resampling algorithm. 🧵

2
7
63
Naive question: I'm still confused about why betting on election results is allowed. What if someone (1) bets on candidate A, (2) does something to increase A's perceived success rate (e.g., releases a surprising poll or some news), (3) and then bets on B? Guaranteed return?.
11
2
61
Is NTK (neural tangent kernel) the best way towards understanding deep learning? Our work suggests perhaps it is not, because a simple regularizer can provably provide better generalization:
1
12
60
and SoTA among whole-proof generation methods on miniF2F, ProofNet, and PutnamBench, and double the previous best results on LeanWorkBook. (reposting because it seems that this table has much more views 😝)

RL + CoT works great for DeepSeek-R1 & o1, but: . 1️⃣ Linear-in-log scaling in train & test-time compute.2️⃣ Likely bounded by difficulty of training problems. Meet STP—a self-play algorithm that conjectures & proves indefinitely, scaling better! 🧠⚡🧵🧵.
1
8
60
hallucination -> guessing properly with quantification of the confidence level 😊.

When LLMs are unsure, they either hallucinate or abstain. Ideally, they should clearly express truthful confidence levels. Our #ICML2024 work designs an alignment objective to achieve this notion of linguistic calibration in *long-form generations*. 🧵

1
14
58
An exciting report led by @percyliang and @RishiBommasani! I was involved in the theory section (Sec 4.10) which presents an analysis framework used in many recent papers; please check it out! (Just in case you filter tweets by only arxiv link: :) ).

NEW: This comprehensive report investigates foundation models (e.g. BERT, GPT-3), which are engendering a paradigm shift in AI. 100+ scholars across 10 departments at Stanford scrutinize their capabilities, applications, and societal consequences.

1
17
56
It's tough when one brain has to handle two "PR"s 😇😇—public relations and pull requests. I felt that I am running MoE— every time I see PR, my visual cortex do a quick routing to the right part of brain.
2
1
52
Indulging in this @OpenAI's incident report, my real-world analogy is: . A CEO introduces a new extensive perf review system, so that their calendar gets blocked with perf reviews 24/7, so that the board can't even schedule a meeting to override the CEO to stop it. 🤷♂️🤷♀️🤣🤣.
4
5
53
The main principle is conservatism in the face of uncertainty --- we penalize the reward by the uncertainty of the learned dynamics. We also had a new version with more ablation studies! (same link as below).

Offline RL may make it possible to learn behavior from large, diverse datasets (like the rest of ML). We introduce:. MOPO: Model-based Offline Policy Optimization. w/ Tianhe Yu, Garrett Thomas, Lantao Yu @StefanoErmon @james_y_zou @svlevine @tengyuma.
0
9
50
With the right training process, a multilingual embedding model can also have great performance on English 😊.
🌍📢 Launching our multilingual embeddings, voyage-multilingual-2!. 👑 Average 5.6% gain on evaluated languages, including French, German, Japanese, Spanish, and Korean.📚 32K context length.🛒 On AWS Marketplace. Check us out! 👉🏼 The first 50M tokens are on us. #RAG #LLM
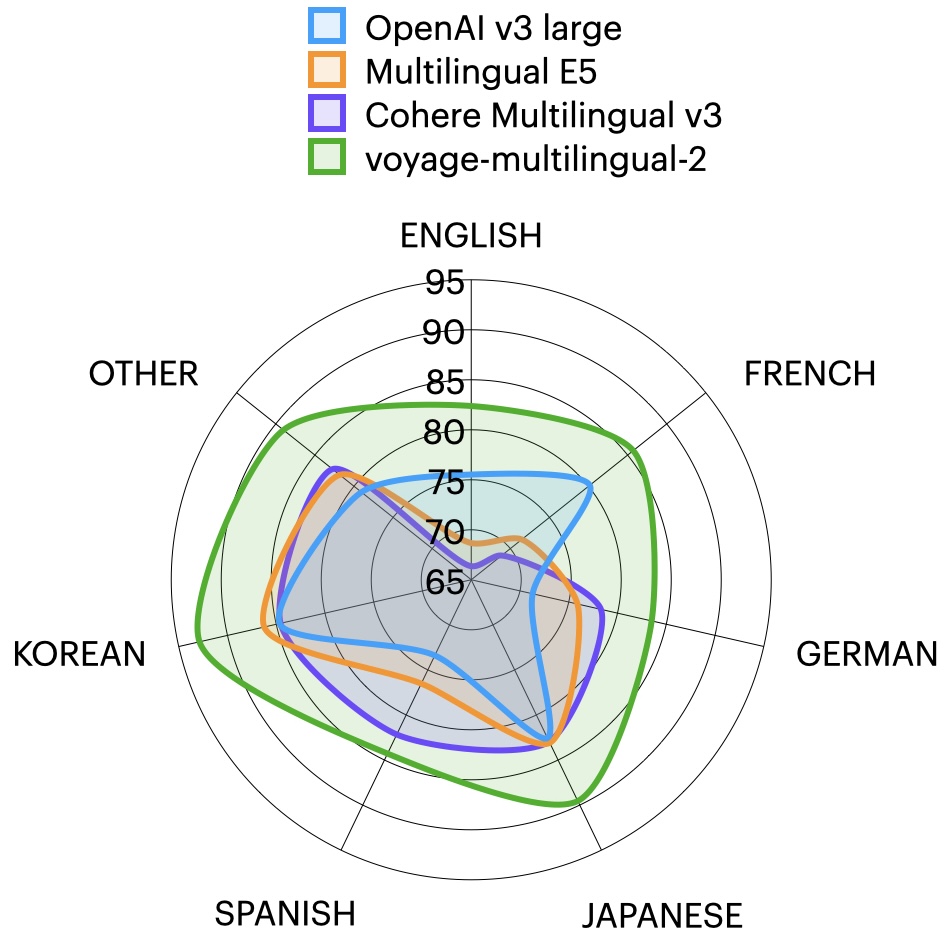
3
6
48
We think embeddings are an under-loved, but incredibly important, part of everyone’s retrieval stack. So we set out to build just better embeddings. Voyage embeddings are SOTA on MTEB and 9 held-out benchmarks covering industry domains. Learn more here:

3
8
49
@bradneuberg @HongLiu9903 @zhiyuanli_ @dlwh @percyliang @StanfordAILab @stanfordnlp @StanfordCRFM @Stanford Unfortunately we've used all of our tiny compute resource on LLMs. We will release the code very soon and hopefully someone will try it out.
2
0
48
Navigating through diverse quality data from multiple sources to train your mega LLMs?. Mix them right with DoReMi 🎶:. Optimized data domain mixtures lead to a 2.6X speed-up! . @StanfordAILab @stanfordnlp @StanfordCRFM @GoogleAI.
Should LMs train on more books, news, or web data?. Introducing DoReMi🎶, which optimizes the data mixture with a small 280M model. Our data mixture makes 8B Pile models train 2.6x faster, get +6.5% few-shot acc, and get lower pplx on *all* domains!. 🧵⬇️

4
7
48
Very cool work! . "Let's learn from these examples", "Let's think step by step", and "Let's recall what you knew". Prompting LLMs sounds increasingly similar to tutoring elementary or high school students 😀😀.

Introducing Analogical Prompting, a new method to help LLMs solve reasoning problems. Idea: To solve a new problem, humans often draw from past experiences, recalling similar problems they have solved before. Can we prompt LLMs to mimic this?. [1/n]

2
5
44
We partnered with @LangChainAI to help enhance their official chatbot, live at Both our base and fine-tuned embeddings improve both the retrieval and response quality, and the latter is deployed!. Check out for more details.

5
8
48
We released the code of the model-based RL algorithms SLBO developed in the paper Please check it out!.
0
6
44
Very excited to announce @Voyage_AI_'s SOTA reranker!.
Rerankers refine the retrieval in RAG. 🆕📢 Excited to announce our first reranker, rerank-lite-1: state-of-the-art in retrieval accuracy on 27 datasets across domains (law, finance, tech, long docs, etc.), enhancing various search methods, vector-based or lexical. 🧵
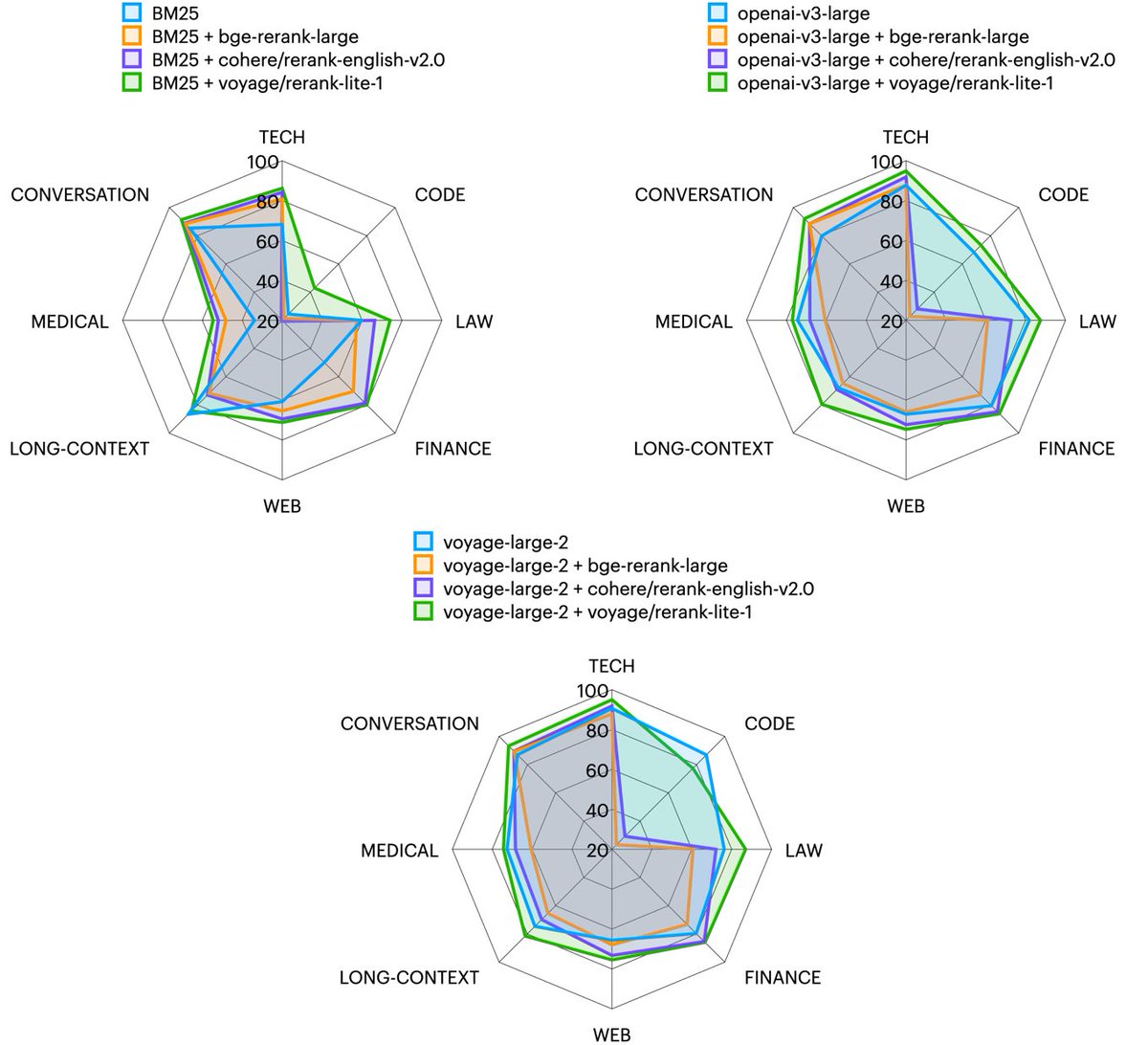
2
7
46
Existing meta-RL methods tend to suffer from task distribution shifts. We mitigate this issue by proposing model-based adversarial meta-RL (AdMRL), which finds adversarial tasks (with a non-trivial task gradient formula) and trains on them. Arxiv:

3
7
42
Surprised and puzzled by why in-context learning emerges? Please check out our theoretical work on it, led by @sangmichaelxie!.
Why can GPT3 magically learn tasks? It just reads a few examples, without any parameter updates or explicitly being trained to learn. We prove that this in-context learning can emerge from modeling long-range coherence in the pretraining data!. (1/n)

1
3
43
Looking forward to UAI! Will give a tutorial on the theory of deep learning. (Thanks to @shakir_za for the organizing!).

My work as tutorial chair for @uai2018 is over and we have a fantastic set of tutorials this year. Everyone going to Monterey, you are in for a treat, with @AnimaAnandkumar @zacharylipton @riedelcastro @tengyuma and others ✍🏾📚🏖
0
8
43
Hong (@HongLiu9903) will present Sophia at ES-FOMO workshop #ICML2023 (7/29, 1pm Ballroom A). Please join us and check out latest results of Sophia on 1.5B and 7B models!! (Also adding more results to the repo.) . code: paper:
Adam, a 9-yr old optimizer, is the go-to for training LLMs (eg, GPT-3, OPT, LLAMA). Introducing Sophia, a new optimizer that is 2x faster than Adam on LLMs. Just a few more lines of code could cut your costs from $2M to $1M (if scaling laws hold). 🧵⬇️
12
7
41
It's really enjoyable to collaborate with @LangChainAI team (@baga_tur, @j_schottenstein, @zebriez, and others) on integrating Voyage embeddings and improve the Chat Langchain !! 🚀🚀 . Try our embeddings and/or let us help to improve your RAG!.

🚀@Voyage_AI_ + LangChain 🚀. A few weeks ago @tengyuma and the folks at Voyage AI came to us saying they had embedding models that would markedly improve retrieval for Chat LangChain. We agreed to give it a shot and . turns out they were right! Check out our latest blog to.
2
3
40
Typical feedback for grant proposals, blog posts, theses, etc.:. 2019: please polish the language.2024: please do more prompt engineering.
0
1
38
The more theoretical paper here ( will be in #NeurIPS2022. Please check out our poster at Hall J #920, Wed 11am-1pm!.
Pretraining is ≈SoTA for domain adaptation: just do contrastive learning on *all* unlabeled data + finetune on source labels. Features are NOT domain-invariant, but disentangle class & domain info to enable transfer. Theory & exps:
1
6
38
We scaled STP’s training compute by another 2x, and achieved new SoTA for whole-proof generation methods on miniF2F, ProofNet, and LeanWorkbook! . Checkout for our updated code, data, and model!

RL + CoT works great for DeepSeek-R1 & o1, but: . 1️⃣ Linear-in-log scaling in train & test-time compute.2️⃣ Likely bounded by difficulty of training problems. Meet STP—a self-play algorithm that conjectures & proves indefinitely, scaling better! 🧠⚡🧵🧵.
1
7
38
This appears in #ICLR2021. Please check out our paper, videos, poster, code, etc!.ICLR poster link: ArXiv: Github:
DL models tend to struggle with heteroskedastic and imbalanced datasets, where long-tailed labels have varying levels of uncertainty, partly bc it's hard to distinguish mislabeled, ambiguous, and rare examples. We propose a new regularization technique:
3
4
38
#NeurIPS2020 How to accelerate distributed optimizers? We develop FedAc that accelerates the standard local SGD with provable improvement in convergence rate and communication efficiency. It turns out the vanilla acceleration is not the best! .Paper:

1
4
36
@OpenAI’s embedding v3 were out 🎉! Curious about its quality? We tested on 11 code retrieval datasets & 9 industry-domain datasets:. 1. OpenAI v3 > ada-002 and cohere (except v3-small on code). 2. voyage-code-2 is the best with + 14% margin on code & + 3% on industry docs 🚀

🆕📢 @Voyage_AI_'s new embedding models: voyage-2 & voyage-code-2!. 1. 🔼 +17% accuracy gain on 11 code datasets vs @OpenAI .2.🥇 # 1 on MTEB & diverse corpora.3.⚡ Production-ready latency.4.🛒 Available on AWS Marketplace, meeting compliances.5.📜 16K context length. #LLMs
2
4
35
Please check out our paper for more experiments, examples of generated conjectures, and ablation studies. Joint work with @kefandong. Feedback and comments are more than welcome!.
1
2
36
Inspired by how mathematicians continue advancing the field, we train an LLM that conjectures and attempts proofs; then we iteratively reinforce/re-train it with correct, elegant, novel, and approachable generated conjectures and correctly generated proofs.

1
1
34
Hong (@HongLiu9903) will give an oral presentation at #ICML2023 on this paper (Ballroom A, Jul 27, 16:04 HST). The poster presentation will be at at Poster Session 5 (Exhibit Hall 1), Jul 27, 10:30 HST. Please check them out!.
Does the validation pre-training loss in language modeling always correlate with downstream perf.? . We find it's not necessarily true even with the same architecture. This means that the implicit bias of pre-training algorithms is another key factor!.
0
4
31
For the four papers with both 3's and 7's, the total count of ratings is .# of 3's = 4.# of 4's = 2.# of 6's = 2.# of 7's = 8.Can I compete for the most controversial author? 😂.
1
0
31
Recent algorithms for offline RL perform well; do they still work in the multi-agent setting? Surprisingly, they may underperform due to challenges in multi-agent optimization. We propose OMAR that improves action opt. with the 0th-order approach: 1/n

3
3
30
The results are on linear models. See Figure 8.12 of page 115, for details. The other two relationships (error vs # params, norm vs # params) are visualized below. Experiments and figures are by Kefan Dong (@kefandong).

3
3
31
It's sad to lose Luca. His papers on spectral graph theory were among the first few papers I read in graduate school and have been inspirational since then.

Tragic news. Luca Trevisan passed away today. The talk he prepared in his final weeks for the TCS4all workshop will be given virtually in his honor on Monday. I hope many of the TCS community can attend.
0
2
27
We need safe RL. Can we hope for *zero* training-time safety violations without prior knowledge of the dynamics (but with a trivial initial safe policy)? Many prior works need > 100 violations for even 2-4 dim. state space, and our algo. makes it zero!

2
7
31
IMO, the (meta-)reviewer matching in ML conf. can be improved. I started to manually re-adjust the systems' assignments since last year and found the review quality in my stack is improved. The pain point is my ideal reviewers are already matched to other (suboptimal?) papers.
6
2
30
@capetorch @HongLiu9903 @zhiyuanli_ @dlwh @percyliang @StanfordAILab @stanfordnlp @StanfordCRFM @Stanford Do you mean learning rate schedules? We are using the standard cosine LR which has an initial warmup period, and decays 1/10 of the peak LR eventually. The LR schedule is also plotted in Figure 5a.
0
0
30