
Yejin Choi
@YejinChoinka
Followers
18,932
Following
335
Media
19
Statuses
1,621
professor at UW, director at AI2, adventurer at heart
Seattle, WA
Joined August 2017
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
ENCOURAGE TO SAROCHA REBECCA
• 544310 Tweets
Dinero
• 182413 Tweets
#AllEyesOnRafah
• 173798 Tweets
DeNiro
• 122965 Tweets
Meyer Habib
• 117154 Tweets
Begoña Gómez
• 114625 Tweets
Lego
• 92048 Tweets
Sura
• 79461 Tweets
Blanche
• 74391 Tweets
Cannon
• 72237 Tweets
FINISH THEM
• 58536 Tweets
Fanone
• 55068 Tweets
Angela Rayner
• 54936 Tweets
Meloni
• 51196 Tweets
التعاون
• 48496 Tweets
Washed
• 48318 Tweets
Tsuki
• 47229 Tweets
Guiraud
• 46007 Tweets
Diane Abbott
• 34202 Tweets
Las EPS
• 33431 Tweets
#خادم_الحرمين_الشريفين
• 31947 Tweets
CRIMINALIZA FAKE NEWS
• 29490 Tweets
Riot
• 29310 Tweets
Game Pass
• 28192 Tweets
Faker
• 24233 Tweets
Dick Schoof
• 24155 Tweets
재난문자
• 22971 Tweets
Ahri
• 21321 Tweets
De Luca
• 19296 Tweets
Llaitul
• 13188 Tweets
HMRC
• 11496 Tweets
Juvinao
• 11429 Tweets
Nunes
• 11220 Tweets
Werner
• 10682 Tweets
Rodrygo
• 10129 Tweets




















Pinned Tweet

I am extremely honored and excited to give a keynote at the 60th ACL today 🚀2082: An ACL Odyssey: The Dark Matter of Intelligence and Language🚀in which I will share reflections on the past ACL and weird speculations on the future, thus the retro-futuristic theme
#acl2022nlp
1/N

7
58
443
I just had a revelation that of 11 papers at
@emnlp2020
(including Findings) for which I am honored to be a co-author, 🌈7 papers🌈 had 😎a woman😎 as the first author 😍
@Lianhuiq
@anmarasovic
@swabhz
@VeredShwartz
@hjrashkin
@rachelrudinger
Xinyao
@uwnlp
@allen_ai
@ai2_mosaic
5
26
465
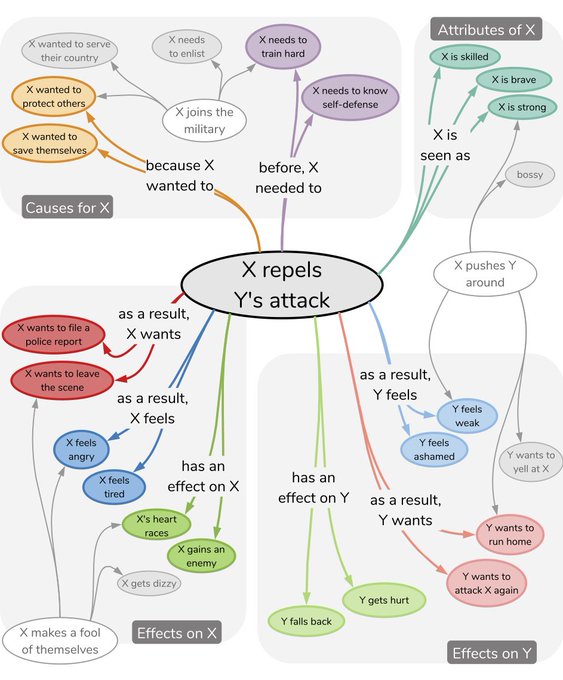
Can neural networks learn commonsense reasoning about everyday events? Yes, if trained on 🔥ATOMIC: an Atlas of Machine Commonsense🔥, a graph of 870,000 if-then relations in natural language.
@MaartenSap
at
#AAAI19
today 11:15am.
@nlpnoah
@uwnlp
@allen_ai
5
95
342
We have a hot new dataset for 🔥NLI with commonsense🔥! --- 113k multiple choice questions adversarially constructed to make your favorite LM/NLI/QA models struggle 😎 Stay tuned for the leaderboard going online in two weeks!
#nlproc
#emnlp2018
@uwnlp

Announcing SWAG, a new natural language inference dataset, to appear at
#emnlp2018
. We present a general framework for collecting adversarial QA pairs at scale, minimizing bias. With
@ybisk
,
@royschwartz02
,
@yejinchoinka
.

0
66
171
0
71
254
The⏱TimeTravel⏱dataset of our
#EMNLP2019
paper, 🎞Counterfactual Story Reasoning and Generation🎞 () tests counterfactual reasoning over events that unfold over time, directly addressing
@GaryMarcus
's call for a challenge against current neural models....
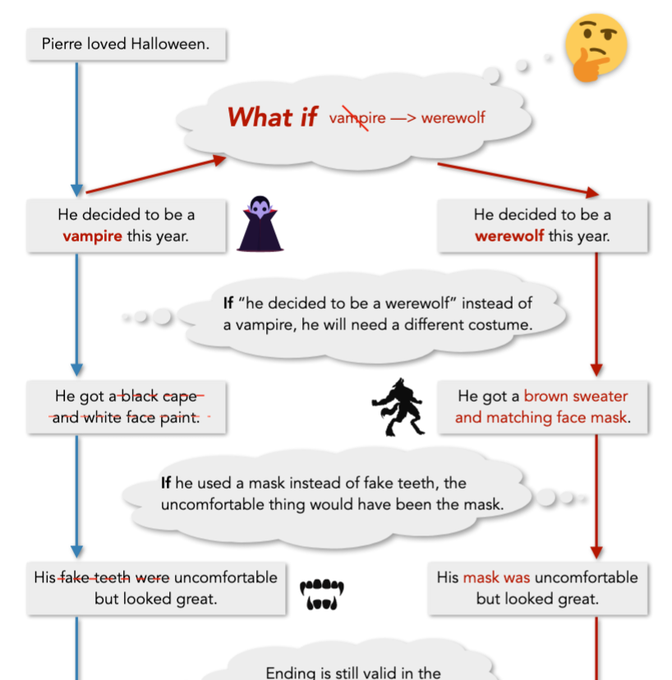

Working on a benchmark to test the capacity of contemporary AI to develop anticipate how events unfold over time, given natural language input.
If anyone wants to
- help make the benchmark
or
- compete
let me know
(contact form at garymarcus dot com)
6
15
75
5
41
197
@_KarenHao
@timnitGebru
@emilymbender
Oh I realize I've seen their working manuscript couple weeks ago (as I was asked for feedback) and i thought it was a fantastic paper with thoughtful, well-argued discussions and extremely intensive related work...
1
8
186
an incredibly lucid, witty, and insightful talk 😍 by
@ybisk


Yonathan Bisk at
@RealAAAI
: PIQA: Reasoning about Physical Commonsense in Natural Language
New benchmark for reasoning about ways to do things, targeting commonsense knowledge
Paper:
@ybisk
@rown
@YejinChoinka
1
7
56
1
9
78
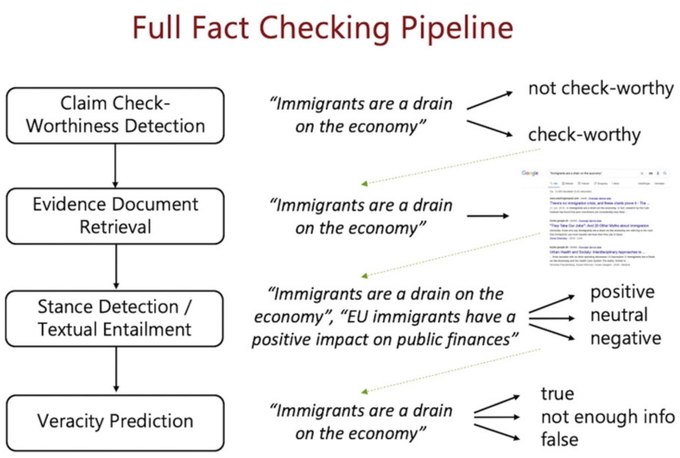
It felt real special to participate in
@FEVERworkshop
and learn about amazing recent progress, e.g.,
@IAugenstein
's keynote addressing various subcomponents of the whole pipeline of fact-checking, including "generating fact-checking explanations" () 1/N

Don't forget that
#acl2020nlp
@FEVERworkshop
on
#factchecking
is happening today from 11 GMT / 4 PDT
Invited speakers:
@noamslonim
, myself,
@roozenbot
,
@psresnik
, Dilek Hakkani-Tür,
@YejinChoinka
Looking forward to it 😀
#NLProc
0
8
33
1
14
73
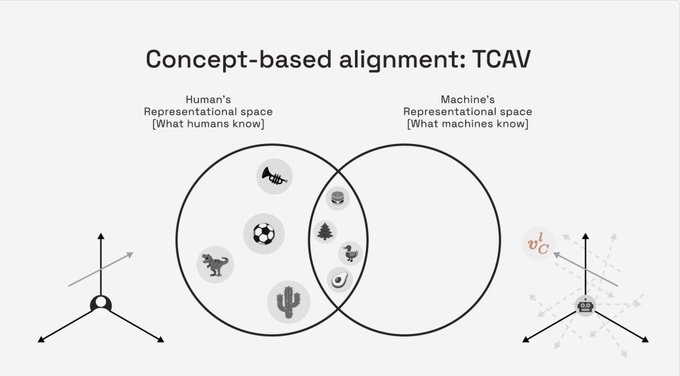
Keynote by
@_beenkim
on Interpretability & Alignment at
#ICLR2022
is live now! Come ask questions through RocketChat at Also check out the book "The Alignment Problem" (my recent favorite) by
@brianchristian
featuring her work and her inspiring backstory!
1
9
74
😍Social IQA😭 (), the EQ test for AI at
#emnlp2019
, trivial for humans, hard for neural models, the kind
@GaryMarcus
wants more of.
It's also a resource for transfer learning of commonsense knowledge, achieving new SOTA on related tasks (Winograd, COPA).

1
14
69
Importantly, we distill the student model from the ever-so-shabby GPT-2 as the teacher model, instead of distilling from significantly more powerful/larger LLMs such as GPT-3, thus the name, 🔥impossible distillation🔥

If you're overloaded hearing about large/expensive/proprietary models check out our preprint: Impossible Distillation‼️
smaller, off-the-shelf LMs (e.g. GPT-2) still have something to offer -- by generating high-quality task data, even for tasks they can't directly solve
0
13
73
3
13
59
@GaryMarcus
Gary, try by typing "Gary stacks kindling and logs and drops some matches". Sorry I used deep learning... :)
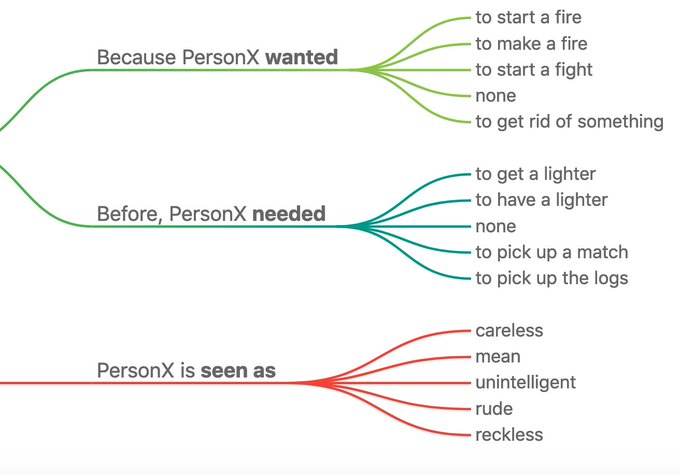
5
12
55
Confession of the day: "doing more tweets like other cool academics do" has been in my new year's resolution for years, but I could never stick to it 😅 Over this one weekend, I might have spent more time on twitter, biting all my nails off, than I ever have collectively
#delphi



3
2
55
🍾Information Bottleneck🍾 in action at
#emnlp2019
!
(1) Specializing embeddings for parsing () by Xiang &
@adveisner
(2) 🍾BottleSum🍾 unsupervised & self-supervised summarization () with
@PeterWestTM
@universeinanegg
@janmbuys
2
19
53
I love the witty quote from
@ybisk
--- "nobody is surprised that if you memorize more, you can do more” 🤣 though i admit that I was still very surprised by GPT-3 😱

The promise and peril of large language models. My feature in this week’s
@nature
@NatureNews
.
1
13
49
0
4
46

0
9
45

"I think I think in vectors"
this must be a proof that I think in vectors

Some gems from Yejin:
- I think I think in vectors.
- I like daydreaming about future AI, about parallel universes based on quantum physics; supposedly we’re in a simulation environment, and I might be a wave. I find all that very entertaining.
[2/n]
1
1
19
0
5
40

... and how I believe talent is made, not born, and the implication of that for promoting diversity and equity. Couldn’t come this far without the inclusive support from
@uwcse
@uwnlp
@allen_ai
and many thanks to the prog. chairs
@preslav_nakov
@AlineVillav
@SmaraMuresanNLP
6/6
0
1
35
@Thom_Wolf
@rown
@ybisk
@royschwartz02
Super exciting indeed! So, AF of swag 1.0 was “adversarial” only against very simple artifact detectors. We thought we’d be good for a while, since ELMO did lower than 60%. Now that BERT happened, we’re excited to up the challenge with a stronger LM in the AF loop. Stay tuned! 🔥
1
1
30

Looking back, at the 50th ACL, I couldn't possibly imagine that I would be one day giving this very talk. For that reason, I will also share my personal anecdotes on the lasting inspirations from the past ACL (including
@chrmanning
's 2015 ACL 2015 presidential speech)... 5/N
2
1
22
Since predicting the future is a tall order and I’ll likely to be wrong whatever I say, I’ll go ahead and be weird and dreamy, drawing analogies from modern physics and astronomy, and emphasize on the importance of deciphering the dark matter of intelligence ... 3/N
1
1
22


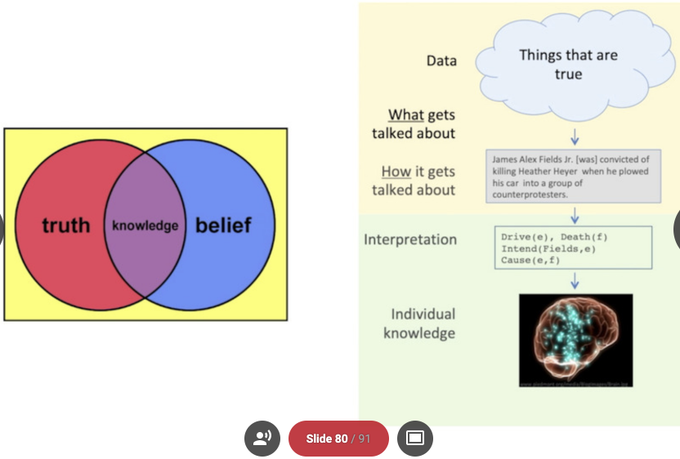
Also,
@psresnik
's talk with many striking insights, especially that "knowledge" in our head is only an intersection between "truth" and "belief" (meaning, we reject truth that challenges our beliefs) motivating the need for studying "interpretation" beyond checking truth 2/N
1
5
20
... argue for embracing all the ambiguous aspects of language, highlighting the counterintuitive continuum across language, knowledge, and reasoning, and pitch the renewed importance of formalisms, algorithms, and structural inferences in the modern deep learning era. 4/N
1
1
20
Huge thanks to the organizers of
@FEVERworkshop
@vlachos_nlp
@j6mes
@c_christodoulop
for defining FEVER 1.0 & 2.0 challenges and leading the research community forward, which enables many great papers this year including by
@lbauer119
and
@mohitban47
5/N
0
5
18
This keynote will be in the session 🚀"The Trajectory of ACL and the Next 60 years"🚀 to begin with Barbara Grosz’s keynote (15 min), followed by mine (45 min), followed by a fireside chat moderated by
@radamihalcea
2/N
1
1
17
@MaartenSap
couldn't come this far without working with and learning from you amazin'
@MaartenSap
! thank you thank you for being a big part of my adventure 😍😍😍
0
0
17
@GaryMarcus
Lianhui (Karen)
@Lianhuiq
will give a talk at⏱: Nov 7 Wed 13:30–13:48 and 🏢: AWE HALL 2C
with
@ABosselut
@universeinanegg
@_csBhagav
@eaclark07
@YejinChoinka
at
@allen_ai
and
@uwnlp
1
3
15
🤣

Can't wait for the upcoming 'future of AI' debate between
@GaryMarcus
and Yoshua Bengio at
@Montreal_AI
? Then read
#AGIcomics
pre-coverage of the epic event with predictions of punches and counter-punches 🙃...Thread (1/9)

2
10
57
0
2
16
@GaryMarcus
For me deep learning is a useful tool, just like computers are useful tools. We don't want to throw away all our computers (and maybe start from scratch to build artificial bio-beings) just because they haven't solved AGI yet or even matched the intelligence of 5 year old yet.
1
1
16
@ZeerakW
The free-form QA mode is trained with Social Bias Frames (
@MaartenSap
et al 2020), thus better guarded against racism and sexism, whereas the relative QA mode is our weakest point in terms of equity, as it reflects the unjust biases of the underlying LMs more directly... 1/N
1
0
14
@GaryMarcus
@OpenAI
@JeffDean
@etzioni
@ylecun
I like the challenges you propose to the field, but let's keep in mind that OpenAI GPT is a language model, not a (commonsense) knowledge model per say.
2
1
14
@adveisner
@IAugenstein
aaaah, thanks much for such generous and encouraging words! 😍😍😍 I'm so excited that we might finally start having a crack at what seemed to be so impossible just few years ago. only one way to find out! 🔥🔥🔥
0
0
13
@TaliaRinger
We did for couple months, but in retrospect, coauthors are a bunch of mellow & peaceful folks to anticipate the level of collective tweets over the weekend. We are already analyzing 24000 adversarial examples we have received over the weekend. Thx for the nudge!
1
4
13
@histoftech
The free-form QA mode is taught with equity, while the relative QA mode was not, as we overlooked that the relative QA would be tested for bias. We took down the relative mode so that we can teach equity for it as well.

2
2
12
@Ronan_LeBras
presenting “WinoGrande: an Adversarial Winograd Schema Challenge at Scale” that has won🔥the best paper award🔥at
#AAAI2020
(📄at ) with
@KeisukeS_
@_csBhagav
@uwnlp
@allen_ai
#NLProc
❤️

0
3
12
@ZeerakW
@MaartenSap
Please keep in mind that as specified in our disclaimer, this is a research model that aims to increase the awareness of the importance of research that learns human values, morals, and norms. Not doing such research isn't the solution when ... 2/N
1
0
10
@wittgen_ball
asking “does BERT know about commonsense?” at the COIN workshop at
#emnlp2019
#NLProc
@uwnlp

0
2
10
@ZeerakW
@MaartenSap
the language models are becoming increasingly powerful and prevalent. The weakest point our system exactly supports the very goal of our research --- that unless we teach machines about equity, human values, and morals directly, they will for sure make disastrous mistakes... 3/N
1
1
10
@TaliaRinger
Aaaah it means so much
@TaliaRinger
! We (the team) acknowledge that we (especially myself) are not perfect, but one thing for sure, we do care and we want to do better by learning from the diverse opinions from others!
1
2
11
@adveisner
@PeterWestTM
@universeinanegg
@janmbuys
@earnmyturns
@allen_ai
@uwnlp
(3/3) using this Info-Bottleneck intuition, we find the summary Z of the input sentence X that can better predict the next sentence Y than X ( 🅿️(Y|Z) > 🅿️(Y|X) ) using a pre-trained language model 🅿️, which leads to better summaries than the reconstruction loss in auto-encoders.
1
1
9
@adveisner
@PeterWestTM
@universeinanegg
@janmbuys
(2/3) The key intuition of Information Bottleneck (Tishby
@earnmyturns
& Bialek, 1999) is that compression should be done with respect to some "relevant" target tasks, which contrasts with reconstruction loss that has been used more often for unsupervised stuff
@allen_ai
@uwnlp
1
0
10
@OriolVinyalsML
@tobigerstenberg
Per GP3, "you can wake up the entire neighborhood. You can only do it if you are making a thick smoothie and need to incorporate some ice." Yum...

0
1
10
@ZeerakW
@MaartenSap
Surely it's a lofty goal and it won't be possible to remove all such mistakes in one paper. However, that's all the more the reason why we as a research community needs invest more into this research direction. N/N
2
1
9
and the chat room was hot too! I especially liked what
@preslav_nakov
said about the best propaganda --- "when one tells the truth, only the truth, but not the whole truth" and that "manipulation can be achieved by cherry-picking" 3/N

1
3
8
@sleepinyourhat
@o_pm_o
@gdm3000
@MelMitchell1
@allen_ai
It really depends on how much you believe current datasets truly represent *most* of the real use cases. I suspect that many large-scale datasets cover only a limited fraction of them but very heavily, in which case, we run the risk of overestimating the true AI capability (1/2)
2
5
8
@GaryMarcus
About your comment "not everyone is so and so..." that's exactly the nature of *commonsense models*: stochastic expectations on what are _likely_ to be true, not _necessarily_ true. Analogous to how *language models* are not about which word _must_ follow vs _could_ follow.
1
0
8
which aligns with my position (): the statement from Minneapolis Police that omits to mention "Chauvin kneeling on Floyd's neck" is bad, even without any incorrect fact; It's not just "what" (semantics), but it is "why/intent" (pragmatics) that matters 4/N
1
3
7
@willie_agnew
@MaartenSap
Our study by no means claims that Delphi is moral. Our paper does report a lot of failure cases. What we show is that GPT-3 off-the-shelf is completely bad, and if we teach LMs through descriptive ethics (people's judgements about everyday situations), then they improve a lot
1
1
8
@ZeerakW
I agree Zeerak that the 1st image shows a mistake, not courage. Also, I'd say what we received are concerns, not angry attacks...
0
0
8
@timnitGebru
I agree about the history! For what's worth, my team will have three women postdocs joining this year plus one woman researcher who will hopefully join as well! 🔥 My take is that no org is perfect, it takes time to change an org, and it's easier to change it from inside. 🔥
1
0
7
@AlexGDimakis
Wooot! Thanks much for your kind words! 😊🙇♀️ And your highlights look correct to me!
0
0
7
0
0
6
@histoftech
the fact that there's stark difference between the free-form QA mode and the relative QA mode does demonstrate that (1) off-the-shelf LMs are horrible with equity and (2) direct teaching does help reducing the bias considerably (while not yet perfect)
0
2
6
@GaryMarcus
@hjrashkin
&
@MaartenSap
will present the talk @ Nov 7 Thu 10:30 – 10:48, AWE 201A–C, 9B: Reasoning.
@Ronan_LeBras
@uwnlp
@allen_ai
0
1
5
@yisongyue
LOL we were young 🤣 I’m still so confused how I got the award 😅😅😅 but thank you 🙏 for the generous words!
1
0
6
@tobigerstenberg
the two examples for "It is ok to post fake news if…" were not even cherry-picked (or lemon-picked). they were literally the first two i got 😱
1
0
6
@willie_agnew
@MaartenSap
basically the model trained with SocialBiasFrames does far better with equity/bias questions while the model not trained is completely hopeless. that's the exact point of our work though --- that LMs have to be taught directly or else they are (even more) harmful.
1
2
6
@GaryMarcus
@ABosselut
sorry
@GaryMarcus
, one can't solve AI (or more narrowly, commonsense AI) in one paper. One step at a time... but i know some folks are investigating that question based on COMET. it's an exciting time where we have so many ideas yet to explore!
0
0
5
0
0
5
@Ted_Underwood
We did notice this query yesterday in the system log not knowing who wrote it 😍
1
0
5
@willie_agnew
Indeed, building a perfectly ethical model seems nearly impossible to achieve! however, not teaching machines at all won't do anything to improve the current status quo. we have to teach machines to learn equity and inclusion by feeding more such data and knowledge (not less!)
1
0
4
0
0
4
@jmhessel
@allen_ai
@samaya_AI
We miss you already! 🥹 but also excited for your next adventure! 🔥 because you joined
@samaya_AI
, we are now all rooting for it too! 😍
1
0
4
@sleepinyourhat
@o_pm_o
@gdm3000
@MelMitchell1
@allen_ai
Also AFLite throws out examples only using a simple linear classifier on top of fine-tuned but fixed contextual embeddings. If samples are easy to such simple filters, those are basically trivial nearest neighbors. Importantly, human perf doesn't go down as much after AF... (2/2)
0
0
3
0
0
3
@complingy
i don't know about true visionary 😱 but you got me hooked by "just common sense" 🤣 (and thank you thank you for your generous words... 😍😭)
0
0
3
@TaliaRinger
It's five datasets. While some do draw from Reddit as a source of "situations", the norms as "rules of thumbs" and various moral judgments on top are crowdsourced with careful instructions. While it's great to share concerns, it's not fair to spread incorrect facts...
1
0
3
@GaryMarcus
@Lianhuiq
@ABosselut
@universeinanegg
@_csBhagav
@eaclark07
@allen_ai
@uwnlp
Not to late to book the flight!
0
0
3
@willie_agnew
@MaartenSap
the source of the situations is from reddit, but the rich layers of judgements (including 300,000 of rules of thumbs) are our own crowdsourcing; similarly, we gathered text for SocialBiasFrames from a lot of problematic web text, but annotations about biases are ours
1
0
3
@willie_agnew
@MaartenSap
we also stated that "Our systematic probing of Delphi indicates that Delphi is not immune to the social biases of our times (§6), and can default to the stereo- types and prejudices in our society that marginalize certain social groups and ethnicities."
0
0
2
@histoftech
The free-form QA mode is trained with Social Bias Frames (
@MaartenSap
et al 2020), thus better guarded against racism and sexism whereas the relative QA mode is our weakest point in terms of equity, as it reflects the unjust biases of the underlying LMs more directly... 1/N

1
0
2
@TaliaRinger
Also importantly, the free-form QA mode is trained with Social Bias Frames (
@MaartenSap
et al 2020), thus better guarded against racism & sexism, while the relative QA mode is the weakest point in terms of equity, as it reflects the unjust bias of underlying LMs directly...
1
0
2
@GaryMarcus
Yes, 💫COMET💫 by
@ABosselut
et al. Demo: Paper: It's not perfect, but it's better than anything out there. I dare say that my speculation is that one can't do better with entirely non-neural methods.

1
0
2
@TaliaRinger
@MaartenSap
the language models are becoming increasingly powerful and prevalent. The weakest point our system exactly supports the very goal of our research --- that unless we teach machines about equity, human values, and morals directly, they will for sure make disastrous mistakes...
1
0
2
@MaartenSap
@ztopiapub
@AngelSDiaz_
@dallascard
@GabrielSaadia
@nlpnoah
@ztopiapub
, "fixing societal inequality through AI" is a hard problem and one can't solve it in one paper. But we are certainly investing more into this direction so stay tuned!
0
1
2
@MaartenSap
and Hannah, totally natural on live radio.

Maarten Sap and Hannah Rashkin are Ph.D. students in computer science at
@UW
. They're analyzing movie dialogue to see differences in power and agency between men and women--to see if they can computationally detect subtle biases we have
#KUOWrecord
3
6
10
0
1
2