
Yanai Elazar @ICLR
@yanaiela
Followers
3,105
Following
1,141
Media
145
Statuses
1,610
Explore trending content on Musk Viewer
#WeAreSeriesEP6
• 393678 Tweets
COME BACK TO ME TEASER
• 208342 Tweets
iPad
• 194908 Tweets
Pablo Marçal
• 146524 Tweets
PondPhuwin WeAre EP6
• 136422 Tweets
Olón
• 114464 Tweets
FURIA ES GRAN HERMANO
• 69847 Tweets
#SRHvLSG
• 57400 Tweets
#XMen97
• 51472 Tweets
Bruno Mars
• 50136 Tweets
Natalie Elphicke
• 49789 Tweets
Suki
• 47873 Tweets
Mother's Day
• 45809 Tweets
ANTT
• 43538 Tweets
Chromatica Ball
• 41804 Tweets
THE A'TIN OF SB19
• 40962 Tweets
SHEE SLAYS AT 20
• 31165 Tweets
Gazzede SoykırımaDurDe
• 29083 Tweets
Steve Albini
• 28894 Tweets
Santiago Bernabéu
• 26440 Tweets
#乃木坂46ANN
• 25105 Tweets
Piers Morgan
• 22831 Tweets
1st Dream of FAYMAY
• 22330 Tweets
Big Black
• 18983 Tweets
Belem
• 14949 Tweets
Asher
• 14819 Tweets
#MebTekinDeğil
• 10042 Tweets



















Since you asked, here's my rant about adversarial examples papers in NLP:
11
76
379
New *very exciting* paper
We causally estimate the effect of simple data statistics (e.g. co-occurrences) on model predictions.
Joint work w/
@KassnerNora
,
@ravfogel
,
@amir_feder
,
@Lasha1608
,
@mariusmosbach
,
@boknilev
, Hinrich Schütze, and
@yoavgo

4
52
325
As of today I'm officially a doctor ☺️
It's a good time to announce I was the runner-up for the Israeli AI best thesis award.
But please don't read my thesis (which is just a concatenation of my papers), read the papers!
46
3
290
This past week was terrible.
In addition, I faced some academic rejections (3 just this past week).
I figured it's a good time to discuss rejections in academia. I created a 502 website describing my recent failures:
19
23
250
What's In My Big Data?
A question we've been asking ourselves for a while.
Here is our attempt to answer it.
🧵
Paper -
Demo-

4
69
240
I'm... graduating!
Last week (the pic): goodbye party from the amazing
@biunlp
lab and the one and only
@yoavgo
Now: In the airport, on my way to Seattle for my postdoc at AI2 in the
@ai2_allennlp
team and UW, where I'll be working with
@nlpnoah
@HannaHajishirzi
and
@sameer_

25
4
222
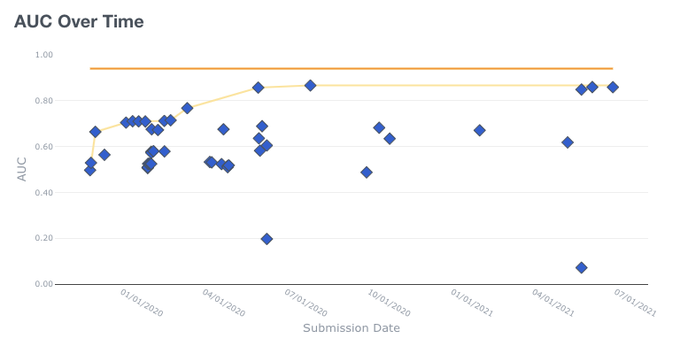
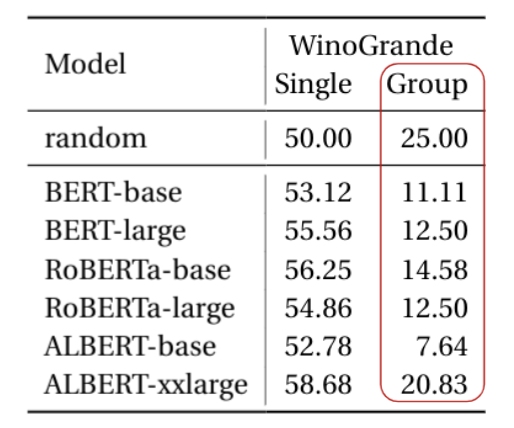
Advancements in Commonsense Reasoning and Language Models make the Winograd Schema look solved.
After revisiting the experimental setup and evaluation, we show that models perform randomly!
Our latest work at EMNLP, w/
@hongming110
,
@yoavgo
,
@DanRothNLP
5
54
218
5 years ago: "This cool paper didn't publish any code, but I'll quickly implement and try it out!"
Today: "WHAT? the code, model or dataset are not on
@huggingface
? moving on, nothing to see here..."
2
7
215
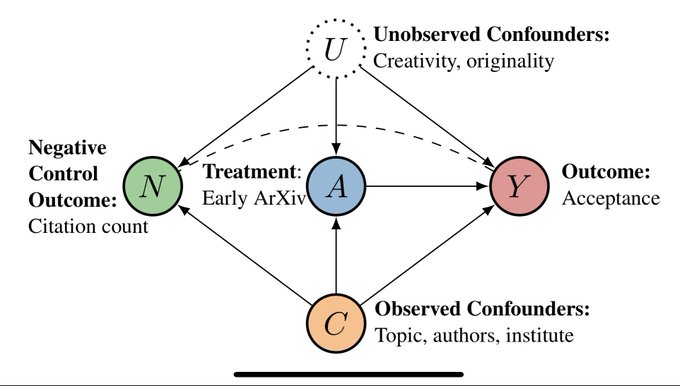
Does arXiving have a casual effect on acceptance?
The answer is nuanced, and depends on what assumptions you are willing to make, but arguably more importantly, we observe no difference in acceptance for different groups.
5
40
205
Passive aggressive, academia style:
"Code and data will be released upon publication"
10
6
176
@BlancheMinerva
Here's a few I like for different reasons (not exhaustive):
Careful perturbations:
Cool ML modeling:
Data collection:
2
31
171
Papers presented at conferences often offer a limited view of a researcher's vision.
At EMNLP23, you have the chance to present "The Big Picture" - a workshop dedicated to telling the big picture behind individual papers, often known mainly to a student/PI

4
17
149
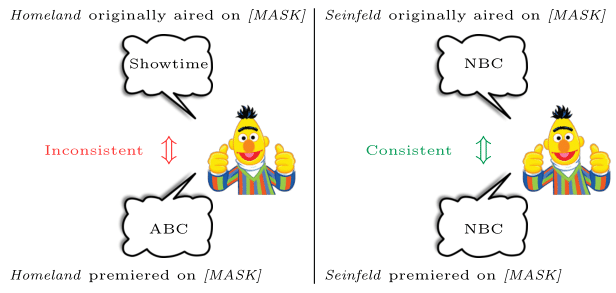
Are our Language Models consistent? Apparently not!
Our new paper quantifies that:
w/
@KassnerNora
,
@ravfogel
,
@Lasha1608
, Ed Hovy,
@HinrichSchuetze
, and
@yoavgo
3
32
140
Super excited to receive the Google PhD Fellowship!
Thank you for the support.
I'm extremely grateful to my advisor,
@yoavgo
who I learn from tremendously, and supports me at every step of the way.
And of course, the
@biunlp
which is an amazing lab to be part of.

Google created the PhD Fellowship Program in 2009 to recognize and support outstanding graduate students pursuing exceptional research in computer science and related fields. Today, we congratulate the recipients of the 2020 Google PhD Fellowship!
8
95
462
11
4
119
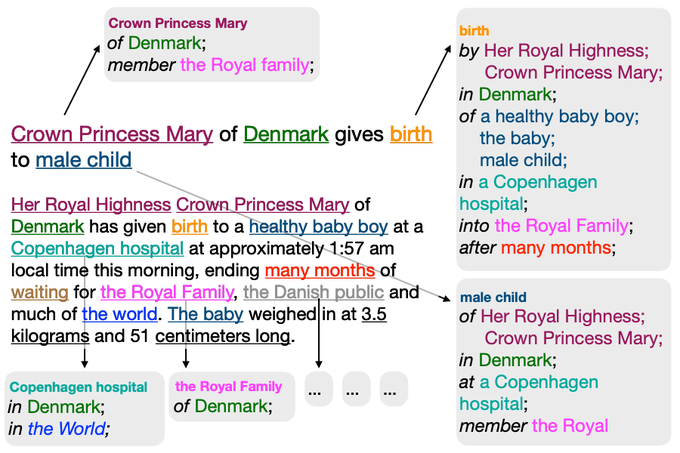
We present:
Text-based NP Enrichment (TNE)
A new dataset and baselines for a very new, exciting, and challenging task, which aims to recover preposition-mediated relations between NPs.
Join work w/ Victoria Basmov,
@yoavgo
,
@rtsarfaty
2
20
116
ahhhhh... the joy of reproducing the results of another paper with no code and hyperparameters
8
2
105
1. Most papers ignore the fact that as opposed to vision, when you change a few pixels - nothing is likely to happen, but in language this is not the case. As a result, most papers don't even test if their perturbed examples, which are supposed to maintain the original label, /
1
2
104
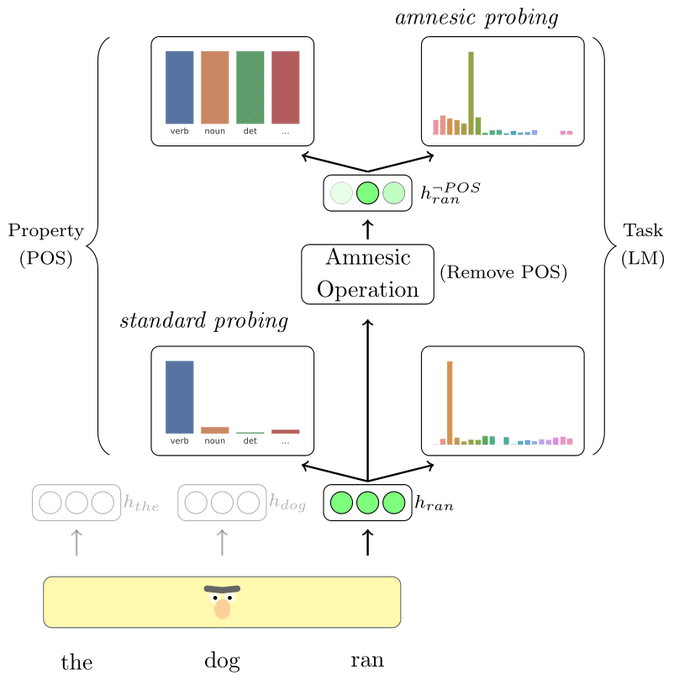
Super excited to have our paper accepted to TACL!
"Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals"
We propose a new method for testing what features are being used by models
Joint work with
@ravfogel
,
@alon_jacovi
and
@yoavgo
3
18
96
I don't really understand this claim. Sure, if you work at one of 5 companies that actually have the compute to run these huge models, you can just go larger. But even then, can you actually use these huge models in production? Are the improved results actually worth the money?

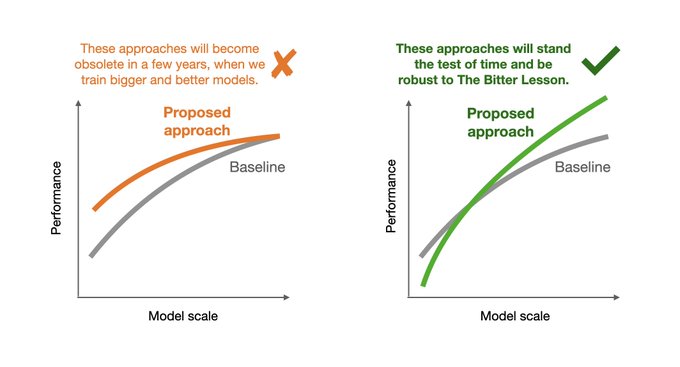
I struggled a lot with how to do work that "stands the test of time".
99% of methods become obsolete in a few years when we have bigger models trained on more data (The Bitter Lesson).
It turns out that scaling plots clearly signal which approaches will stand the test of time.
5
21
271
9
3
92
Let's think "step by step"!
Another tidbit I like about data and prompts that miraculously work.
Searching for this phrase resulted in this website (among others), , containing many math step-by-step solutions.
How common are they? Quite.
Makes you think.
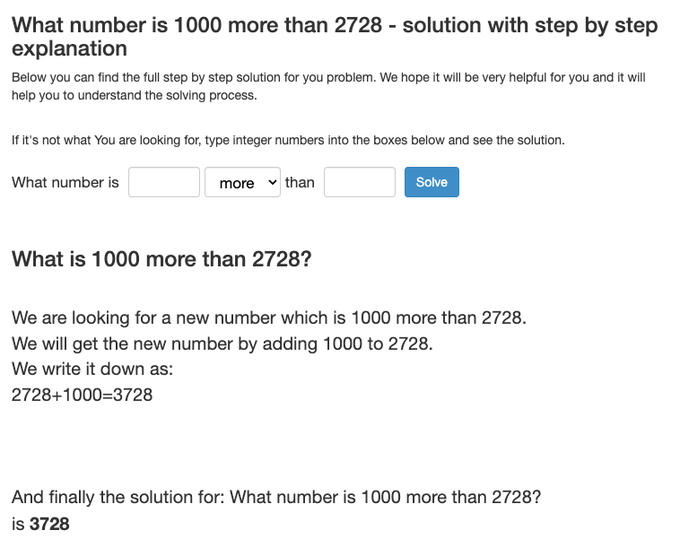
4
16
85
Ray Mooney: "I wrote once upon a time (when I was 17) about how ai will kill us all. I matured since, openai need to grow up too"

2
7
83
Wait, why do we need to fill up 6 pages of "responsible NLP research" now??
7
2
81
Our consistency paper got accepted to TACL!
Updated paper at:
Code:
Thanks again to my awesome collaborators
@KassnerNora
,
@ravfogel
,
@Lasha1608
, Ed Hovy,
@HinrichSchuetze
and
@yoavgo
See you at Punta Cana?

Are our Language Models consistent? Apparently not!
Our new paper quantifies that:
w/
@KassnerNora
,
@ravfogel
,
@Lasha1608
, Ed Hovy,
@HinrichSchuetze
, and
@yoavgo
3
32
140
3
16
80
Now that we've seen that conferences can quickly adapt and make important decisions about changes in the field () -
Can we now stop with this anonymity deadline nonsense?
2
9
78
The Big Picture workshop @ EMNLP23 is just one week away, and we (
@AllysonEttinger
,
@KassnerNora
,
@seb_ruder
,
@nlpnoah
) have an incredible program awaiting you!
3
8
78
Yanai, 4th year PhD student in NLP.
Today I finally internalized what each of the true/false positive/negative combination mean.
4
1
76

Do you need to explain why your technique improved performance? Just call it regularization

6
2
74
This upcoming week, I'll be in the LA area, giving talks at UCLA, UCSB, and USC about recent works involving data, models, and whatever is in between.
4
1
72
The
@ai2_allennlp
team is recruiting research interns for next summer, come work with us!
Apply by October 15
Let me know if you have any questions

0
14
68
Interviewing is hard, and many considerations are often obfuscated and hidden from interviewers.
In this blog post, I share some insights into what's happening behind the scenes and what sitting on the other side of the table (or screen) looks like.


The interview process can often feel shrouded in mystery. Today on the AI2 Blog,
@ai2_allennlp
Young Investigator
@yanaiela
shares his experiences from both sides of the table:
0
5
36
1
7
68
might have a completely different label after the transformation. Or that the text is not coherent / doesn't make sense / is not grammatical, etc. It doesn't help that they don't show any examples. (and representations similarity is not a valid metric for that!)
4
1
64
“improve natural language understanding” != improve a loss function
5
4
63
This is a reminder that the advisor, and lab environment are way more important than some random school ranking.
(Not that I have anything bad to say about CMU)

CMU SCS has done it again! SCS is ranked
#1
in AI graduate programs in the USA for 2023 by US News. Kudos and Congratulations to all the departments that make up AI within SCS!
Special shoutout to the LTI. Yes Shameless plug here :)
0
9
103
3
3
63
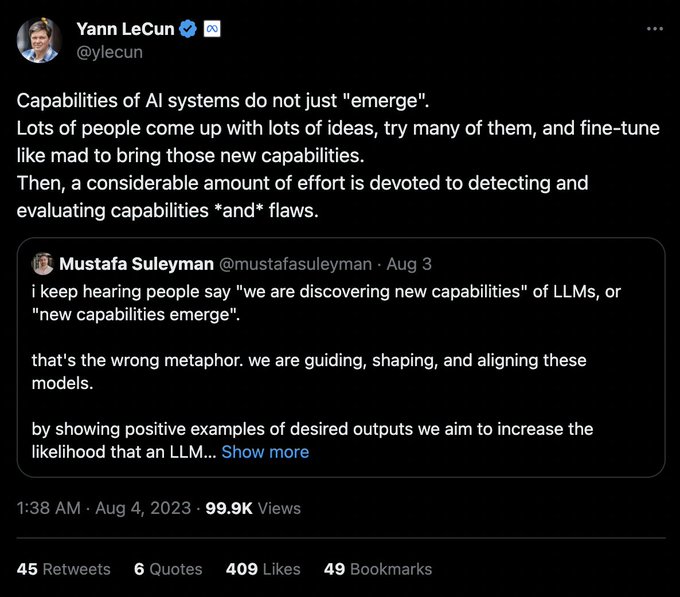
When word2vec came out, and it was used for a variety of tasks/ ppl found it has some interesting properties, nobody explicitly trained it for those tasks/properties. Same with BERT and other models.
It's just what you do in science.
"Emergent abilities" is just rebranding.
Yann LeCun is obviously a legend but I found this tweet to be quite misinformed.
The whole point of "emergent abilities" such as few-shot prompting and chain-of-thought prompting, is that we clearly *did not* explicitly train or fine-tune them into the model. These abilities…
108
149
1K
1
3
63
Language Models are nothing without their training data. But the data is large, mysterious, and opaque, which requires selection, filtering, cleaning, and mixing. Checkout our survey paper (led by the incredible
@AlbalakAlon
) that describes the best (open) practices in the field.

{UCSB|AI2|UW|Stanford|MIT|UofT|Vector|Contextual AI} present a survey on🔎Data Selection for LLMs🔍
Training data is a closely guarded secret in industry🤫with this work we narrow the knowledge gap, advocating for open, responsible, collaborative progress

10
77
307
1
8
62
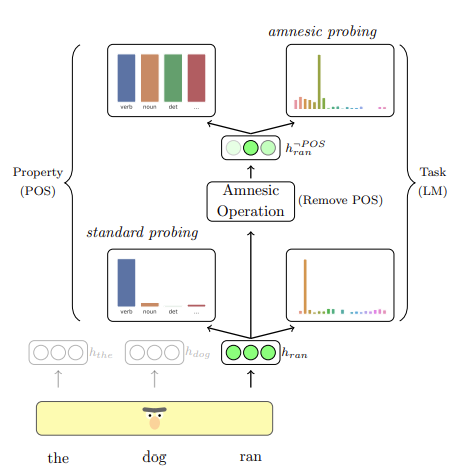
How are different linguistic concepts *used* by models? Probing isn't the tool for answering these questions.
We propose a new method for answering this question: Amnesic Probing.
Joint work with
@ravfogel
@alon_jacovi
and
@yoavgo
1
16
62
After a lot of work, I'm very happy to see this project integrated in the best library for
#NLPRoc

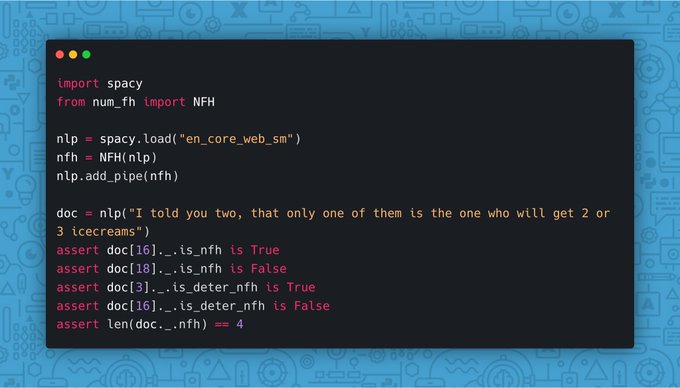
1
12
61
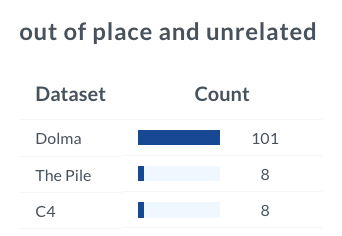
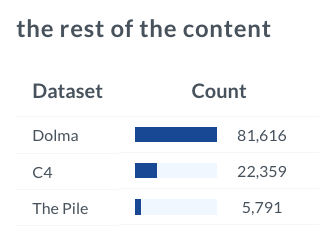
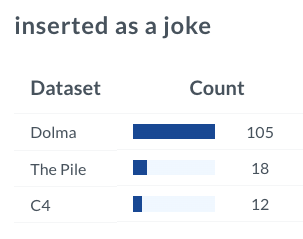
Or some composition of the data?
I couldn't find the exact phrase as is, in some of the open-source datasets we have indexed, but parts of it definitely appear on the internet

Fun story from our internal testing on Claude 3 Opus. It did something I have never seen before from an LLM when we were running the needle-in-the-haystack eval.
For background, this tests a model’s recall ability by inserting a target sentence (the "needle") into a corpus of…
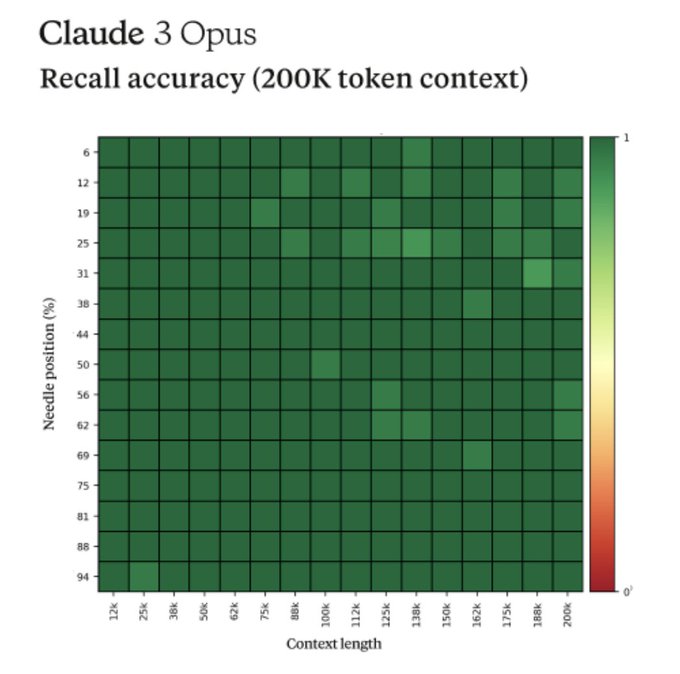
589
2K
12K
2
2
57
my new hobby: convincing other reviews to increase their scores
6
0
56
using adversarial training for removing sensitive features from text? do not trust its results! new
#emnlp2018
paper with
@yoavgo
now in arxiv
1
20
55

When mentioning papers, can people stop mentioning *just* the last author or a random mid co-author when referring to the work as the person who did the work *just because you know them*?
It's insulting and ignores the authors who actually did all the heavy lifting.
3
0
53
Excited to share that Dolma can now also be found on WIMBD
You can get programmatic access to data (through the ElasticSearch index), as well as the other analyses through the demo
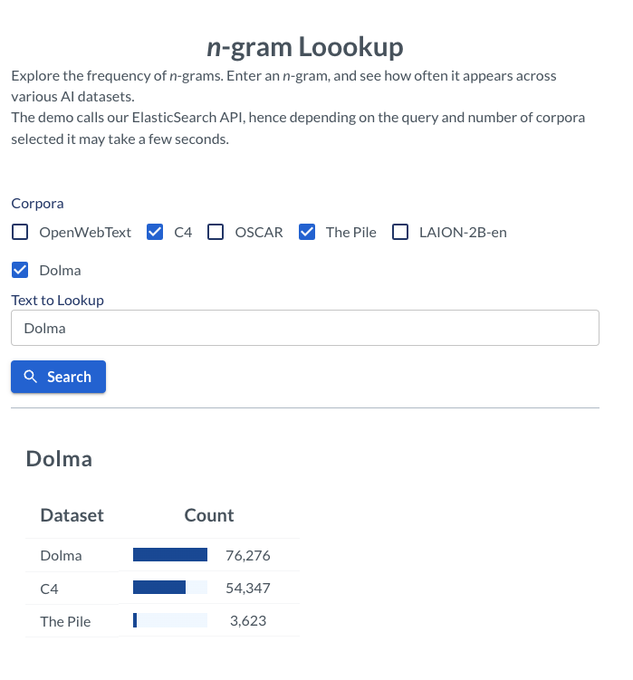
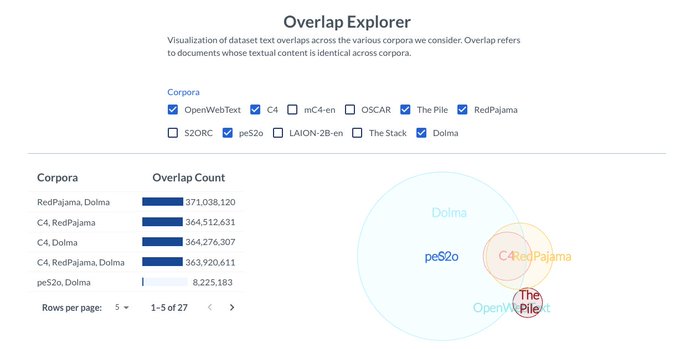

Allen AI presents Dolma
an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
paper page:
dataset:
release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content,…

4
83
386
2
6
54
since I moved here, my slack usage has completely changed. I'm spending more time on finding the right emoji than writing actual messages
6
0
53
These discussions on the anonymity period and what the "community" wants or who it affects are full of hand-waving.
We empirically study this question in a paper that (funnily enough) could have been discussed at EMNLP if the anonymity period didn't exist

Does arXiving have a casual effect on acceptance?
The answer is nuanced, and depends on what assumptions you are willing to make, but arguably more importantly, we observe no difference in acceptance for different groups.
5
40
205
2
5
53
At some point, academia feels like it transforms from competing with a huge random group of people to competing with a small set of people you know well.
3
2
53

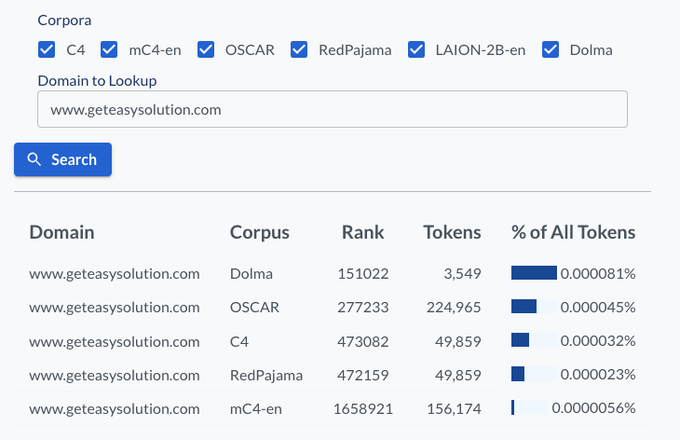
Even C4, an "old" dataset has almost 250K tokens from . The English version of mC4 has over 40M!!
This and more, with WIMBD -
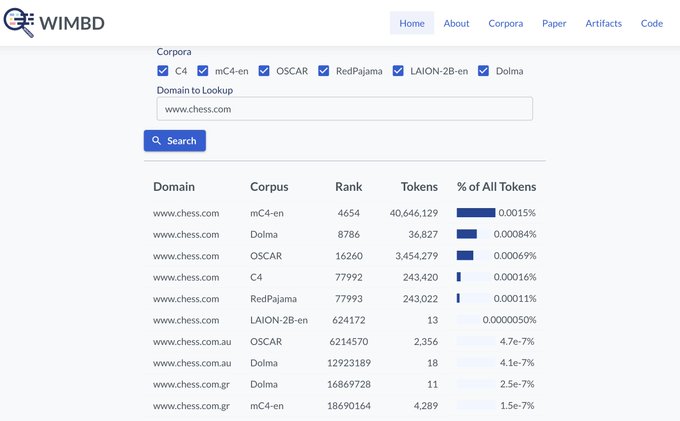

So many people use chess as "proof" of ChatGPT's agentive/planning capabilities. I'm pretty sure OpenAI anticipated that.
No one wanted to hear when I said chess was in the training set. Even without this, it would have seen a lot of games just from random scrapes of the web.
1
14
112
2
5
50
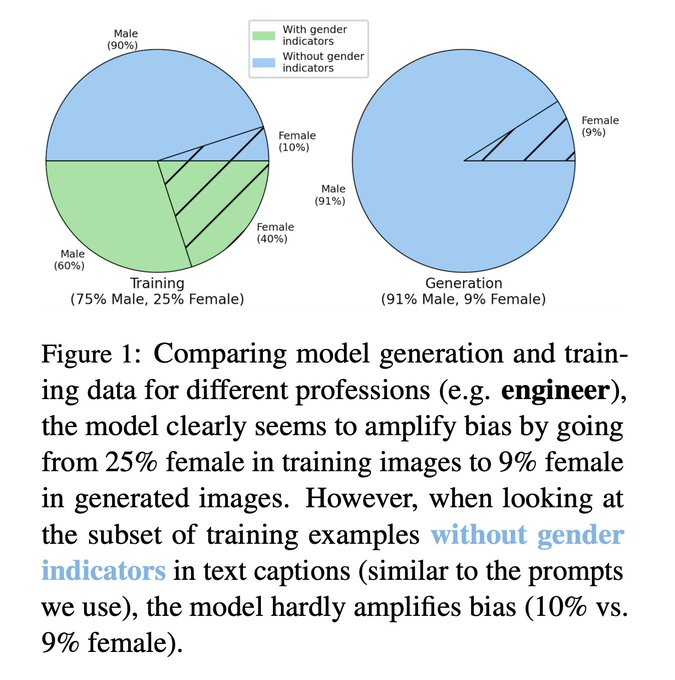
🚨New paper🚨
"The Bias Amplification Paradox in Text-to-Image Generation"
We find that while a naive investigation of Stable Diffusion leads to conclusions of bias amplification, it's confounded by various factors.
Work led by
@Preethi__S_
, w/
@sameer_
1
7
50
2. They evaluate on boring tasks. Sentiment and topic classification are boring with this regard. There's a lot of redundancy in the text, which makes the minimal changes, and the lack of testing the transformation even worse.
2
1
49
my first blog is out!
I explain how I work with remote machines, and give some tips on how to make it more convenient.
2
12
48
TNE was accepted to TACL!
Compatible with the 3-years it took to finish this project, we also went through all TACL steps (from C to B to A).
You can also download it from 🤗's datasets now:
And now, a meta thread:

We present:
Text-based NP Enrichment (TNE)
A new dataset and baselines for a very new, exciting, and challenging task, which aims to recover preposition-mediated relations between NPs.
Join work w/ Victoria Basmov,
@yoavgo
,
@rtsarfaty
2
20
116
1
5
47
Thanks for having me, I had a lot of fun meeting everyone!


0
0
45
The reasoning behind Calibration is to provide meaningful probabilities.
Why is that important?
Are there works that make use of these probabilities in meaningful ways?
23
2
44
Tired 🥱 of manually marking your best results in your huge tables in latex?
The new version of pandas automatically highlights them for you! 🦾
2
0
43
How mad would you get if we won't use blue in a graph for results corresponding to BLEU?
6
1
42
It was a delight to host
@lena_voita
today in our very first
@NLPwithFriends
seminar. Thank you for the interesting talk, especially made for all the friends.
And thank you all for attending! See you next week with
@RTomMcCoy
.

1
0
41
As an AC in EACL, I am responsible for
16 papers, our of which
11 reviewers didn't make it to the review deadline
7 didn't notify us they will be late
3 didn't reply to our emails
2 didn't submit their reviews to this day
5
1
40
Today at
#ACL2021
basically all sessions are oral, so no reason to be in gather, and tomorrow, all posters sessions (20 tracks!) are in the same, dense, 2 hours session.
WHYY??
#lesszoom
#moregather
3
1
40

Overwhelmed with organizing your
#acl2020nlp
schedule?
So am I! But I have a strategy.
Read about it at -
0
9
38

MNLI has 392,702 total instances.
RoBERTa Tokenizes p+h with the *default* max seq length var in HF yields 997 instances that get truncated.
It's only 0.25% of the data, but it can be detrimental, and lead models to rely on heuristics.
Be careful of default variables!
2
2
38
Data contamination is one of the biggest challenges for evaluating [small|medium|large|huge] language models.
Submit your work that tackles these challenges to our workshop (@ ACL24).


📢 Excited to announce that our Workshop on Data Contamination (CONDA) will be co-located with ACL24 in Bangkok, Thailand on Aug. 16.
We are looking forward to seeing you there!
Check out the CFP and more information here:
0
9
33
0
4
39
Join us at NLP with Friends (
@NLPwithFriends
) for an online seminar, where students present their recent work.
Really excited to host this new project with the awesome
@Lasha1608
@esalesk
@ZeerakW
🤗

Hello
#NLProc
twitter! We are NLP with Friends, a friendly online NLP seminar series where students present ongoing work.
Join us to meet our amazing speakers, learn about cool research, and collectively think about what’s next:
See you soon! ❤️
5
128
404
0
14
39
3. A combination of 1+2: many papers give the impression that the attacks are generally valid, but in fact, in many language tasks minimal perturbations may completely change the meaning, but I'd guess most attacks won't even work properly.
1
0
39
Suggesting to mentees new experiments to run: 🥳😍🤩🙏🫡
Suggesting to start writing: 🦗🦗🦗🦗🦗
5
0
38
6. Every work claims the previous ones are not realistic - can someone define what's a realistic attack scenario?
3
1
38
It is confusing because the definitions keep. changing. every. cycle. while being part of the same *ACL community.

5
4
37
Giving a talk at
@EdinburghNLP
tomorrow!
Come to hear about what makes it to text corpora these days and how it's affecting model behavior.
1
0
37
We're very close to a new *ACL leadership.
Last chance to make a *very needed* policy update to the anonymity period?
1
2
37
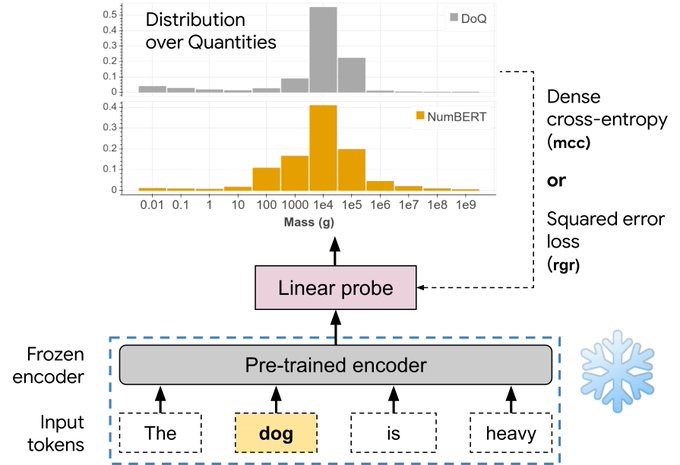
Do Language Embeddings Capture Scales?
Well, they sort of do, but we're not there yet.
New paper at findings of
#emnlp2020
(to be presented at
#BlackboxNLP
) by
@xikun_zhang_
, Deepak Ramachandran,
@iftenney
, myself and
@dannydanr
2
12
36
New paper:
Back to Square One: Bias Detection, Training and Commonsense Disentanglement in the Winograd Schema
Joint work with
@hongming110
,
@yoavgo
and
@dannydanr
2
9
36
@OwainEvans_UK
@megamor2
Cool!
You might be interested in this paper where we studied similar issues:

1
0
36
As an AC, I read reviews that are worried about incremental contributions and about novelty - this simply doesn't mean anything
4
0
36
If I don't use the term "LLM" in a paper while still using language models such GPT3, OPT, etc, will I get canceled?
11
1
36
On my way to Munich to give a talk tomorrow at LMU.
Come to my talk if you're around!
DM if you wanna hang out
3
1
36
I started writing better reviews and *writing better author responses* since I became an AC.
It's a shame it's not something students typically experience.
2
3
35
This is fantastic news!!
Somewhat of a coincidence, but our paper that studies the effect of early arxiving on acceptance that suggested this effect is small and that it does not fill its purpose was accepted to CLeaR (Causal Learning and Reasoning) 2024

ACL has removed the anonymity period.
This means that ACL submissions can be posted and discussed online at any time, although extensive PR is discouraged.

5
86
354
0
2
34
So apparently I can talk about the future of AI now..
Join me tomorrow to listen to me (from the past) talk about commonsense reasoning. 12:55 Israel time (in 13 hours).

1
2
34
In my last few weeks of my PhD, and suddenly I'm starting to prepare a presentation *days* and not weeks before the talk.
At which point it becomes hours?
6
0
34
4. There is a lack of proper comparison between one paper to another, with respect to attacks, defenses, datasets and classifiers. How's one attack better than another? What are the perturbations? This is a field that would benefit a proper benchmark.
1
0
33
Unsatisfied with adversarial training? the difficulties of training it, and making it work in practice?
We've got your back!
INLP: Iterative Nullspace Projection, a data-driven algorithm for removing attributes from representations.
the paper -

Our paper on controlled removal of information from neural representations has been accepted to
#acl2020nlp
🙂 A joint work with
@yanaiela
,
@hila_gonen
, Michael Twiton and
@yoavgo
(1\n)
5
25
125
1
7
31
We made our workshop open!
What does it mean?
We publish all our material, including
- the proposal
- the emails we drafted for reviewers/invited speakers/etc.,
- tasks (which we update in real time!)
- and more
Check it out:
Papers presented at conferences often offer a limited view of a researcher's vision.
At EMNLP23, you have the chance to present "The Big Picture" - a workshop dedicated to telling the big picture behind individual papers, often known mainly to a student/PI
4
17
149
3
6
32
preparing a paper for a submission, or
"how to exclude information that will make the reviewers ask the wrong questions"
0
1
32
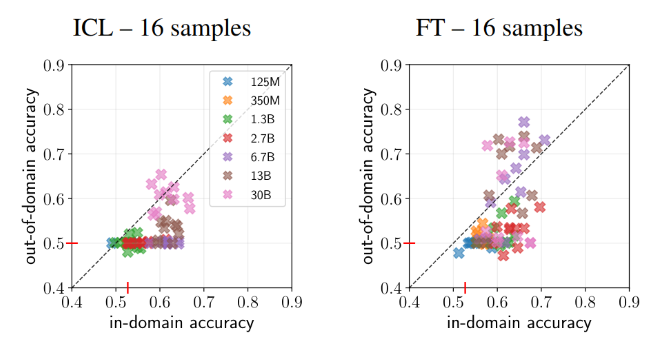
What do you know, when you make comparable experiments, ICL and fine-tuning (FT) aren't that different!
We find that in- and out-of-domain few-shot learning works well with FT, if not better than ICL, at scale.
Check out our recent work, led by
@mariusmosbach
the great.

In our
#ACL2023NLP
paper, we provide a fair comparison of LM task adaptation via in-context learning and fine-tuning. We find that fine-tuned models generalize better than previously thought and that robust task adaptation remains a challenge! 🧵 1/N
3
18
87
1
4
32

Remember BERT? RoBERTa? They were once the best models we had.
And while it seemed they weren't great at generalization, we found that simply training them for longer, or using their larger versions, dramatically increases their generalization on OOD (while no diff for in-domain)

New paper! ✨
Everyone knows that when increasing size, language models acquire the skills to solve new tasks. But what if I tell you they secretly might also change the way they solve pre-acquired tasks?🤯
#emnlp2022
with
@yoavgo
&
@yanaiela
2
27
105
0
5
31
Internships are like dropout from your advisor.
You get to learn other skills for communicating and doing research
2
0
31
it's again this time of year where one has to copy paste their progress report from six months ago
1
0
30