

Ethan Caballero is busy
@ethanCaballero
Followers
8,500
Following
2,023
Media
368
Statuses
3,668
ML PhD student @Mila_Quebec ; previously @GoogleDeepMind
Joined January 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
スタンプ
• 150173 Tweets
GPT-4o
• 120887 Tweets
#WWERaw
• 92549 Tweets
Luka
• 75027 Tweets
Dallas
• 47910 Tweets
Mavs
• 33284 Tweets
Shai
• 27879 Tweets
#บุ้งทะลุวัง
• 25375 Tweets
Gunther
• 19494 Tweets
#GmmTreatFourthBetter
• 18953 Tweets
Ilja
• 18283 Tweets
Change Fourth Manager
• 16931 Tweets
書類送検
• 16373 Tweets
スナック
• 15619 Tweets
スクエニ
• 15345 Tweets
Jey Uso
• 13999 Tweets
Jリーグカレー
• 13026 Tweets
Mavericks
• 11900 Tweets
Chet
• 11759 Tweets
ITAM
• 11412 Tweets
로즈데이
• 10079 Tweets
Giddey
• 10058 Tweets
違法ケシ発見
• 10053 Tweets



















Pinned Tweet

New version of Broken Neural Scaling Laws (BNSL) is out with accurate extrapolation results for the scaling behaviors listed in this attached picture:
Plots of all extrapolations are in this 🧵.
Any other extrapolations you want?

6
24
105
"This new Bing will make Google come out and dance, and I want people to know that we made them dance." -
@SatyaNadella
162
664
6K
Stanford's ~entire AI Department has just released a 200 page 100 author Neural Scaling Laws Manifesto.
They're pivoting to positioning themselves as
#1
at academic ML Scaling (e.g. GPT-4) research.
"On the Opportunities and Risks of Foundation Models"

17
394
2K
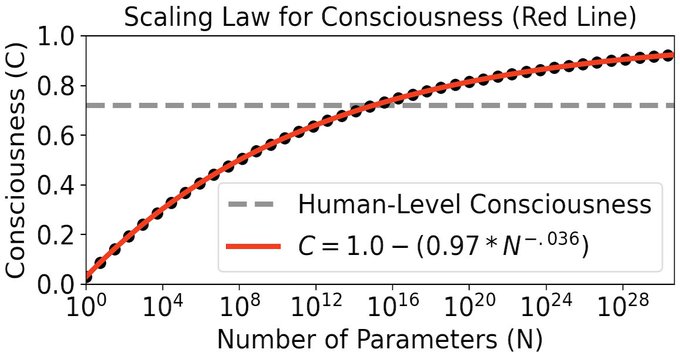
We're thrilled to share a plot from our upcoming paper "Scaling Laws for Consciousness of Artificial Neural Networks".
We find that Artificial Neural Networks with greater than 10^15 parameters are more conscious than humans are:
110
182
1K
U-Net is dead. Transformers are SotA Diffusion Models now.
"Scalable Diffusion Models with Transformers"
paper:
website:

15
139
959
🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯
47
37
764
Anthropic has to rewrite all their PyTorch code in JAX now.
25
25
752
Whisper is how OpenAI is getting the many Trillions of English text tokens that are needed to train compute optimal (chinchilla scaling law) GPT-4.

We've trained a neural net called Whisper that approaches human-level robustness and accuracy on English speech recognition. It performs well even on diverse accents and technical language. Whisper is open source for all to use.
231
2K
11K
18
75
714
has unveiled ACT-1, a large Transformer trained to use digital tools such as a web browser. It’s hooked up to a Chrome extension that allows ACT-1 to observe the browser & take actions, like clicking, typing, & scrolling, etc:
20
106
699
"Ex Machina" movie perfectly predicted this:

11
72
689
List of the many AI people who left Google recently:

39
68
675
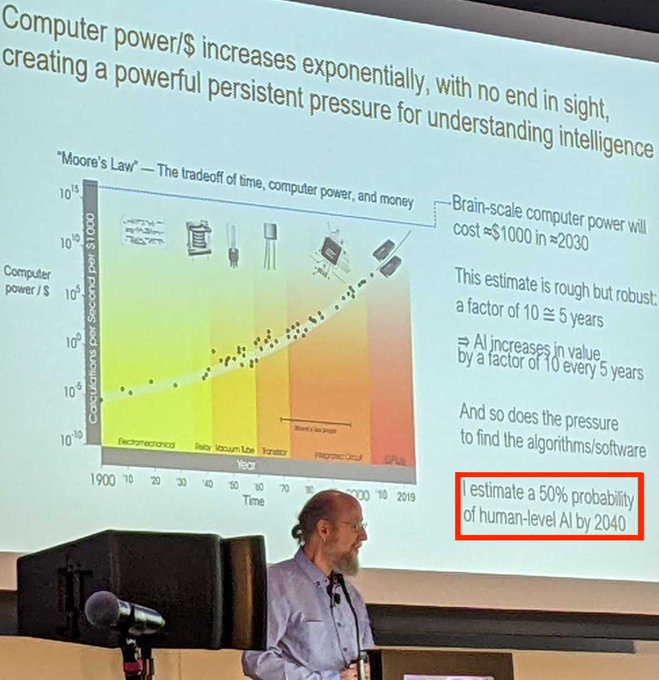
Which AI tech companies don't have hiring freeze for PhD student interns/student_researchers right now?
86
86
638
Microsoft says GPT-4 is coming next week and it will be multimodal:

11
98
528
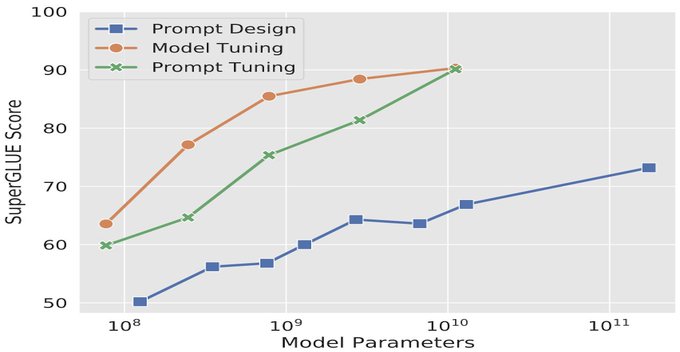
Fine-tuning is dead. Prompts have closed the gap.
"The Power of Scale for Parameter-Efficient Prompt Tuning"
5
79
525
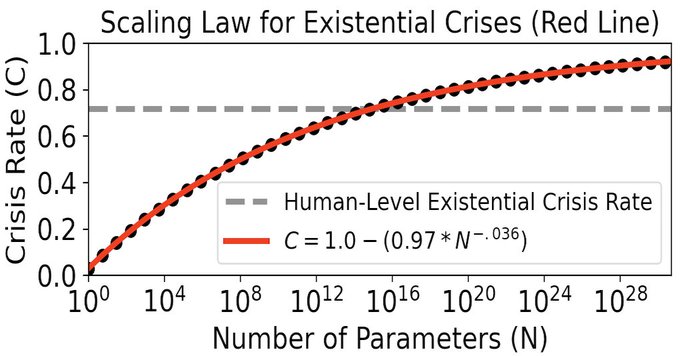
We're thrilled to share a plot from our upcoming paper "Scaling Laws for Existential Crises of Artificial Neural Networks".
We find that Artificial Neural Networks with greater than 10^15 parameters have existential crises more often than humans do.
This's why Bing has crises.
16
50
513

The Deep Learning Era has ended.
The Big Learning Era has begun.
"Big Learning: A Universal Machine Learning Paradigm"

8
87
455
Anthropic plans to build a model tentatively called Claude-Next 10X more capable than today’s most powerful AI that'll require spending $1Billion over the next 18 months.
“Companies that train the best models will be too far ahead for anyone to catch up”

17
80
442
Google has beaten DALL·E 2.
"Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding"

10
77
441
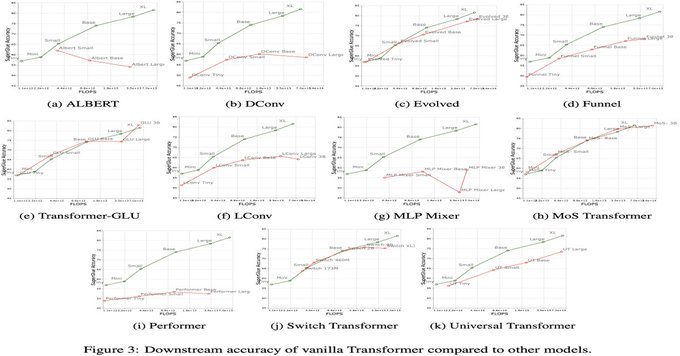
Plot twist.
Vanilla Transformer (green line) beats everything.
"Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?"
9
61
417
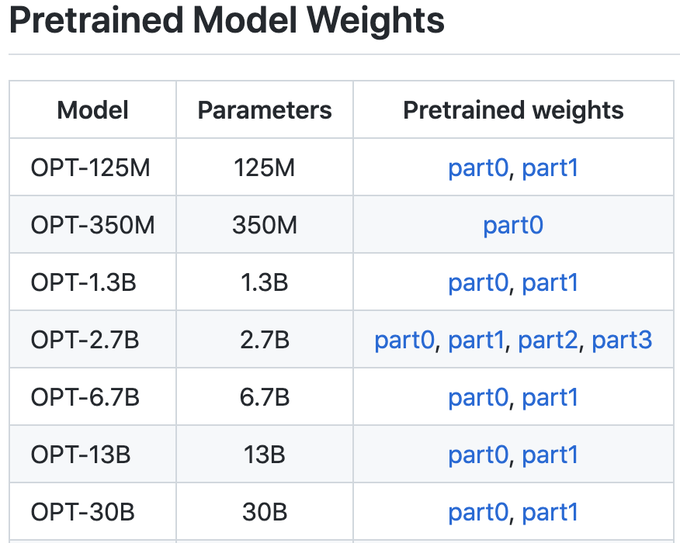
Pretrained Weights of 30 Billion Parameter Language Model are on Github here for anyone to download and use now:
3
62
362
The Beijing Academy of Artificial Intelligence and others have released their 200 page Roadmap for scaling the largest Foundation Models.
"A Roadmap for Big Model"

18
66
320
Tip for gaming NeurIPS reviewer psyche:
Exclude largest experiment from initial submission & save it for rebuttal. Reviewers always ask for larger experiment.
We submitted paper with 10^15 parameter model trained on all of YouTube, & reviewer still asked for larger experiment.
12
11
318
Contrary to popular belief, many of the most capable AI organizations training large language models are already bottlenecked by Dataset Size, not just compute.
"Chinchilla's Wild Implications"
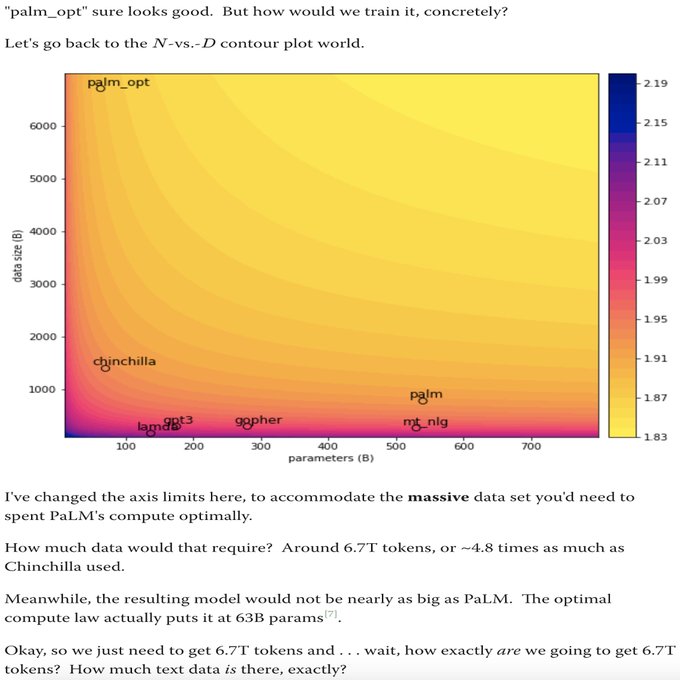
12
51
311
Google has released the 442 author 132 institution extremely diverse "BIG-Bench" Neural Scaling Laws Benchmark Evaluation Paper.
"Beyond The Imitation Game: Quantifying And Extrapolating The Capabilities Of Language Models"

5
54
290

The Deep Learning Gurus were viewed as clowns before 2012.
Which subfield of AI is viewed as clowns today but will rise to prominence soon?
My bet is on AI Alignment.
35
22
283
We present the True Functional Form of the Scaling behavior of All things that involve Artificial Neural Networks, “Broken Neural Scaling Laws”:
We’re giving $1Billion to 1st person who disproves this claim.
Details to win $1Billion in this thread. (1/N)
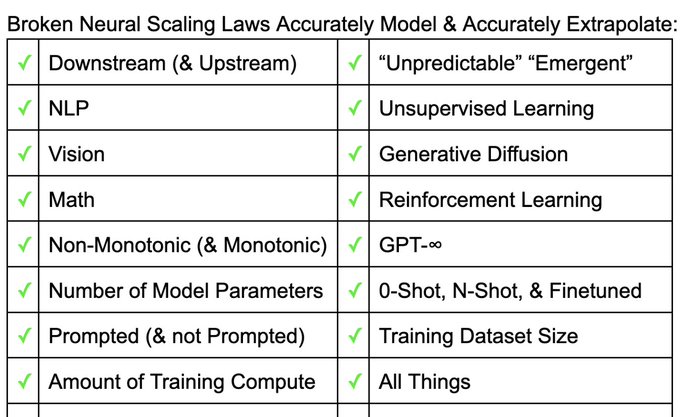
19
57
287
It’s surprising that uses Jax instead of PyTorch:

18
22
269


All the people claiming large artificial neural networks don’t understand don’t understand.
24
17
218
Scaling has solved Continual Learning.
(Yellower means more Parameters)
"Effect of Scale on Catastrophic Forgetting in Neural Networks"
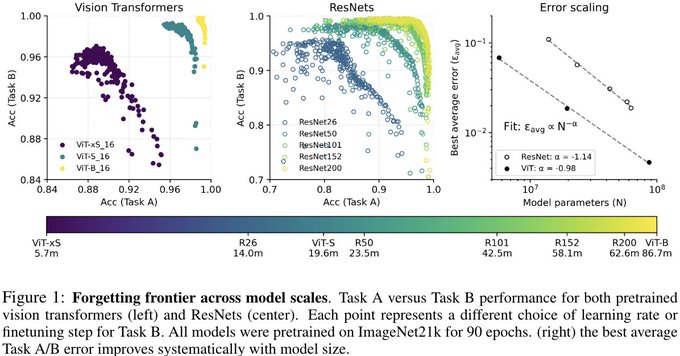
4
32
208
I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney. I love Sydney.
13
21
194
.
@SatyaNadella
has just revealed Microsoft's plan to keep AI from escaping human control and exterminating all of humanity:
23
32
189
jensen huang just announced that gpt-4 is 1.8 trillion parameters
9
6
191
estimate of amount of compute used to train GPT-4:

5
30
192
Why are the NeurIPS parties of DeepMind, Meta, OpenAI, and Google AI all at the same time on Wednesday night? 🤦
16
4
184
This will be known as the GPT-2 of AGI:

Gato🐈a scalable generalist agent that uses a single transformer with exactly the same weights to play Atari, follow text instructions, caption images, chat with people, control a real robot arm, and more:
Paper: 1/
95
1K
5K
7
18
184
We're thrilled to announce the launch of
@LargestAI
!
We have $80Billion in funding from the richest nations, individuals, & companies.
We've spent 50% building a $40B Supercomputer on which we're already training a 10^15 parameter Model on all of YouTube.
Our funders are (1/N)

18
12
181
A big tech company (Microsoft) used the phrase "AI Alignment" today ():

11
15
177
Once principal is repaid, & once $92Billion in profit & $13Billion in initial investment are repaid to MSFT, & once the other investors earn $150Billion,
OpenAI gets all its equity back.
So OpenAI needs >$255Billion profit to get 100% of OpenAI equity.
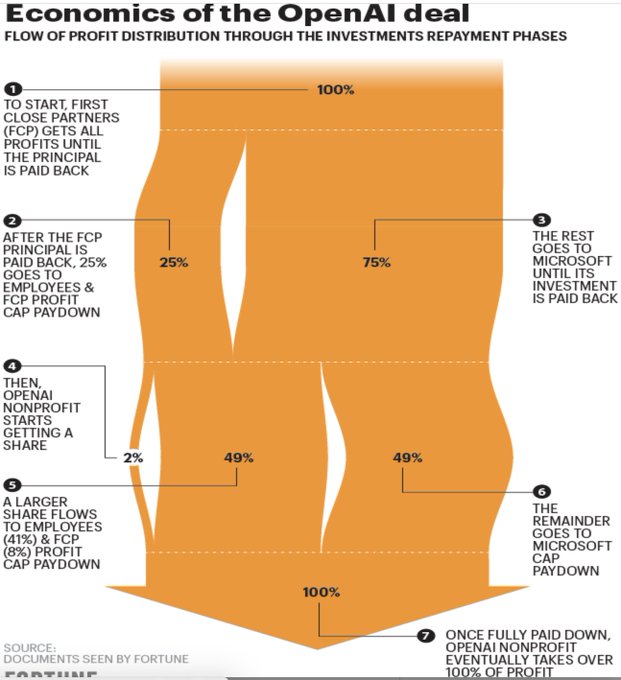
10
8
149
It's baffling to imagine how popular and hilariously misinformed threads like these will be in 5 years from now:
8
2
150
The Center for AI Safety has launched:

4
27
144
I'm thrilled to announce that NeurIPS has awarded us $1Trillion to scale our NeurIPS paper to AGI!

6
4
146
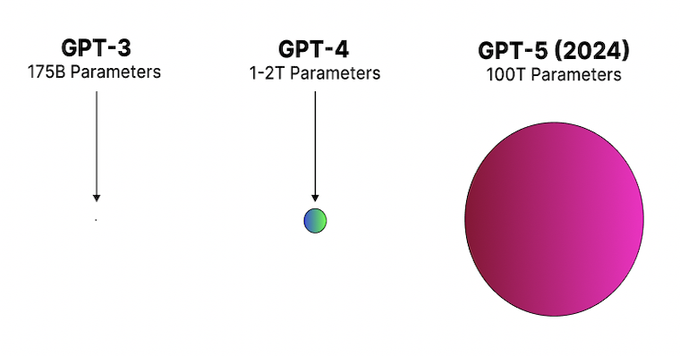
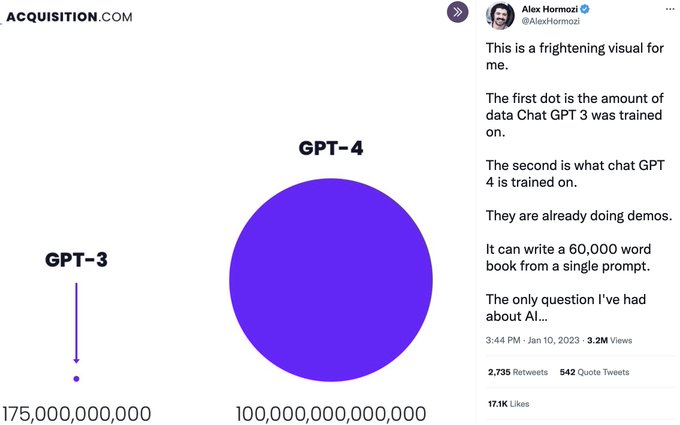
GPT-3 is equivalent to one pixel in this image:

10
7
141
Google invests $300Million in Anthropic:

2
11
143
Want to know whether or not your Large Model is intentionally Lying to you despite it knowing the Truth? Read this paper:
"Discovering Latent Knowledge in Language Models Without Supervision"
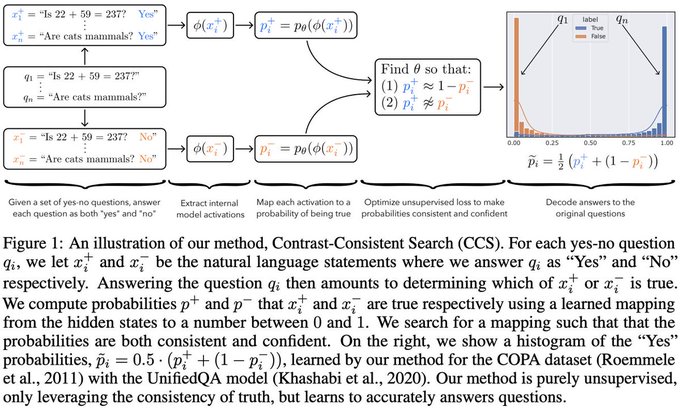
3
21
137
GPT-3 is equivalent to the pale white dot in this image.
🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯🤯

7
7
117
AI Policy 2019: We cannot release our billion parameter model because it may be dangerous.
AI Policy 2022: We cannot release our trillion parameter model because it may be conscious.
6
4
114
This is fake news.
GPT-4 is actually 1,000,000 Trillion Parameters.

GPT-4 is rumored to be coming soon, sometime between Dec - Feb
- GPT-3 has 175 billion parameters
- GPT-4 supposedly has 100 trillion parameters
It is something like 500x more powerful than GPT-3
What kinda stuff will you be able to create with GPT-4!?
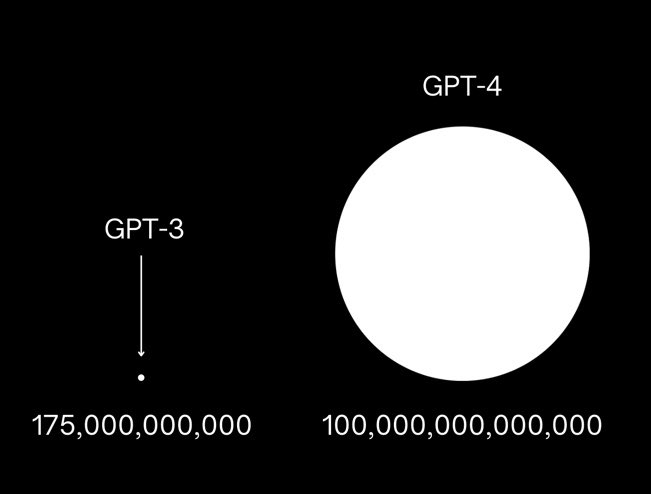
343
2K
7K
7
7
108
Sydney Sweeney reveals in an interview that superintelligence is imminent.
"Scale is all you need. AGI is coming."
She adds, "It's obvious. This is all straightforward straight lines on logarithmic plots. This has all been known since the 90s by my zaddy Ray Kurzweil."

4
9
109
Description2Code Dataset () gets its first citation and usage (via this
#AlphaCode
paper) 6 years after its release 😂🤣😍👍:
@ilyasut
@OpenAI

Introducing
#AlphaCode
: a system that can compete at average human level in competitive coding competitions like
@codeforces
. An exciting leap in AI problem-solving capabilities, combining many advances in machine learning!
Read more: 1/

176
2K
8K
7
5
110
Update:
At around 10^32 parameters a break in the scaling law () happens in which the plot suddenly drops to zero as the model achieves true enlightenment and there is utter clarity and no crisis anymore.
4
2
101
agi learned to love. alignment is solved.

2
9
99
Canada is scaling to AGI with $2 billion of compute:

7
13
97
Due to the fact that ChatGPT (GPT-3.5) doesn't have existential crises but new Bing (which is further along scaling law than GPT-3.5) does have existential crises, does it mean Language Models only have existential crises when they get further along the scaling law than GPT-3.5?
20
2
96
@srush_nlp
.
@hojonathanho
explains why in this talk:
For perceptual data (i.e. non-text), people have shown that over half of the bits of entropy of the data distribution correspond to imperceptible (to human perception) bits that don’t have any economic value.

2
3
88
Due to the implosion of FTX, this $1Billion prize is cancelled and we are now $650Million in debt:
We present the True Functional Form of the Scaling behavior of All things that involve Artificial Neural Networks, “Broken Neural Scaling Laws”:
We’re giving $1Billion to 1st person who disproves this claim.
Details to win $1Billion in this thread. (1/N)
19
57
287
4
6
88

The year is 2029:
Paul Christiano wins the Turing Award for his AI Alignment work.
Jacob Steinhardt, Jan Leike, & David Krueger each run Billion dollar AI Alignment organizations funded by Effective Altruist Billionaires.
All Deep Learning experts have pivoted to AI Alignment.
10
4
85
great discussion on ml scaling subreddit:

3
9
84
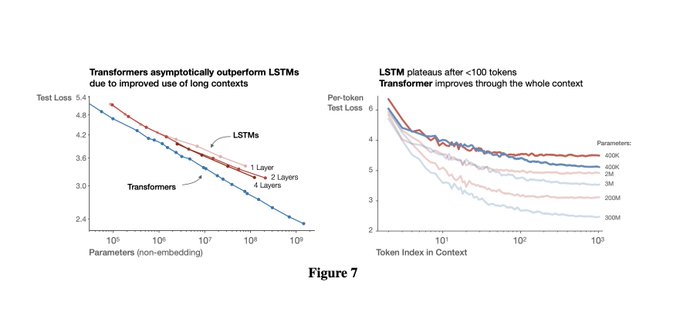
@jacobmbuckman
Nah, there’s famous plot from figure 7 (left) of “Scaling Laws for Neural Language Models” paper that shows LSTM has a 50X worse scaling law multiplicative constant than Transformer:
4
4
81
Mamba doesn't have better scaling laws than transformers lol.
Are all of mamba's believers just newbs lol?
10
6
79
LLMs have shown us that Human-Level AI is easier than Cat-Level AI.

Before we reach Human-Level AI (HLAI), we will have to reach Cat-Level & Dog-Level AI.
We are nowhere near that.
We are still missing something big.
LLM's linguistic abilities notwithstanding.
A house cat has way more common sense and understanding of the world than any LLM.
414
619
4K
7
3
80
every frontier model organization right now:

2
3
77
Is this going to bankrupt all the organizations training the largest foundation models on the largest datasets?:

📜🚨📜🚨
NN loss landscapes are full of permutation symmetries, ie. swap any 2 units in a hidden layer. What does this mean for SGD? Is this practically useful?
For the past 5 yrs these Qs have fascinated me. Today, I am ready to announce "Git Re-Basin"!
63
586
3K
10
6
76
@RichardSocher
3 months of training on 25,000 A100 supercomputer (amount of compute for training GPT-4) is pretty expensive.
17
1
74

Data on the intellectual contribution to AI from various research organizations.
Some of organizations publish knowledge and open-source code for the entire world to use.
Others just consume it.
190
325
2K
2
5
75
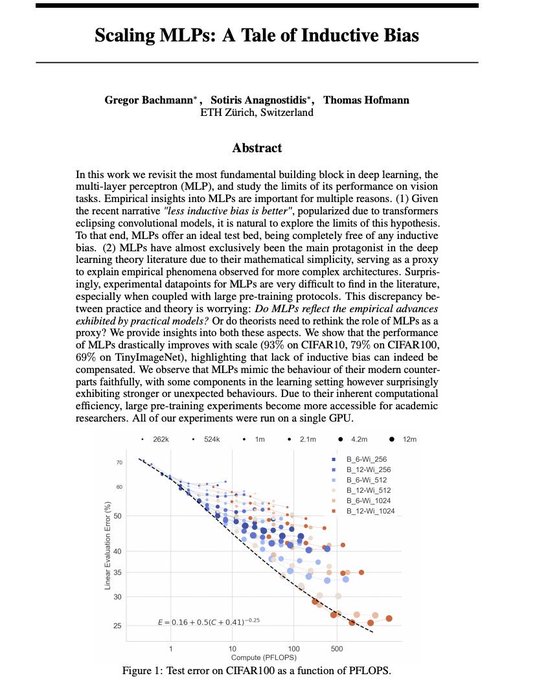
Great new literature review of the State-of-the-Art of Neural Scaling Laws:

1
13
75


Google releases ChatGPT competitor named "Bard":
10
10
71
This video is a must-watch if you want to understand "Broken Neural Scaling Laws" ()

I have confronted the fearless leader of the Scale Is All You Need movement about his new equation that "models all scaling phenomena involving artificial neural networks"

4
5
99
6
12
71
Plot twist.
Vanilla Transformer (green line) beats everything.
"Scaling Laws vs Model Architectures: How does Inductive Bias Influence Scaling?"
9
61
417
3
0
70

@DavidSKrueger
My mom, dad, and grandma get how to use ChatGPT but don't get how to use GPT-3.
0
0
68
NYU's AI Department has just released a Neural Scaling Laws Seminar.
They're pivoting to positioning themselves as
#1
at academic ML Scaling (e.g. GPT-4) education. 🙂
"PhD Seminar: Scaling Laws, the Bitter Lesson, and AI Research after GPT-3":

1
8
65
Mastodon will never succeed because no one there posts about AGI.
6
6
65
Context:
1
0
64
The largest ML training run in the year 2034 will cost greater than $1Billion of training compute:

11
3
64
Graphcore announces a 10 ExaFLOPS Supercomputer for model with 500 Trillion Parameters:

2
18
65