
Daniel Haziza
@d_haziza
Followers
1K
Following
188
Media
49
Statuses
128
Research Engineer at Facebook AI Research Working on xformers, to make GPUs go Brrrr https://t.co/RMpoQat9Wj
Paris
Joined October 2022
We provide more details and ablations in the paper, with performance measurements demonstrating the feasibility of efficient kernels for both training and inference with 24 sparsity! https://t.co/eTbZFSbFOU
@CaiJesse will be presenting this paper at the SLLM workshop in ICLR

1
0
10
And this is hard because (2) consecutive tokens are more likely to activate the same features. We can have 10 consecutive tokens with the same feature activated. We work around this issue by shuffling/unshuffling tokens before/after the FFN

1
0
3
This is hard because (1) some individual features are not sparse (even tho the entire tensor is globally sparse). It's less than 5% of the features, so we disable sparsity for these very few features

1
0
2
We however hit some issues in the BW pass - we need to 2:4 sparsify activations in the *features* dimension

1
0
4
And it turns out we *can* put the activations in that format during training: 1 GEMM out of 2 is sparse in the FW pass, and 3 out of 4 in the BW pass!

1
0
4
In other words, we spend a loooot of flops multiplying zeros! Can't we avoid that? Recent GPUs have hardware support for sparsity in matrix multiplications! As long as your tensor is in the 2:4 sparsity format: 2 zero values for every 4 consecutive values

1
0
8
If you train a 7B model with srelu, you expect the activations post-relu to be 50% sparse. It's the case at initialization when all activations are normal/centered, but then the sparsity level skyrockets to 90%+ depending on the layer!

1
0
10
We just released method to accelerate transformers with 2:4 sparsity ... for activations! 🚀 The main trick is to use Squared-ReLU ("srelu") as the activation function in your FFN (instead of eg SwiGLU). This change does not affect your LLM loss/benchmarks at 1B/7B scales.

2
22
197
In the approach we tested and scaled (Memory Layers), 3 FFNs are replaced with a giant embedding lookup. A single token will only activate a small part of this embedding table (<1MB). In MoE, the first token to activate an expert adds ~GBs of activated parameters!

1
0
6
With MoE, if 8 experts are activated by a token in your batch, decoding becomes ~5x slower than a dense model, despite having ~5x less flops. MoEs are good in 2 scenarios: batch size 1 (without speculative decoding), or very high batch size (training or prefilling)

1
1
6
Autoregressive decoding is almost never compute-bound. It is memory bound: the time it takes to decode a token is the time it takes to read all the activated parameters.
1
0
4
I've been working on some alternative to Mixture of Experts (MoEs) for LLMs. In principle the same idea: same flops as dense, more parameters - not all activated. The difference? Much more efficient decoding, as MoEs are a nightmare for decoding workloads.

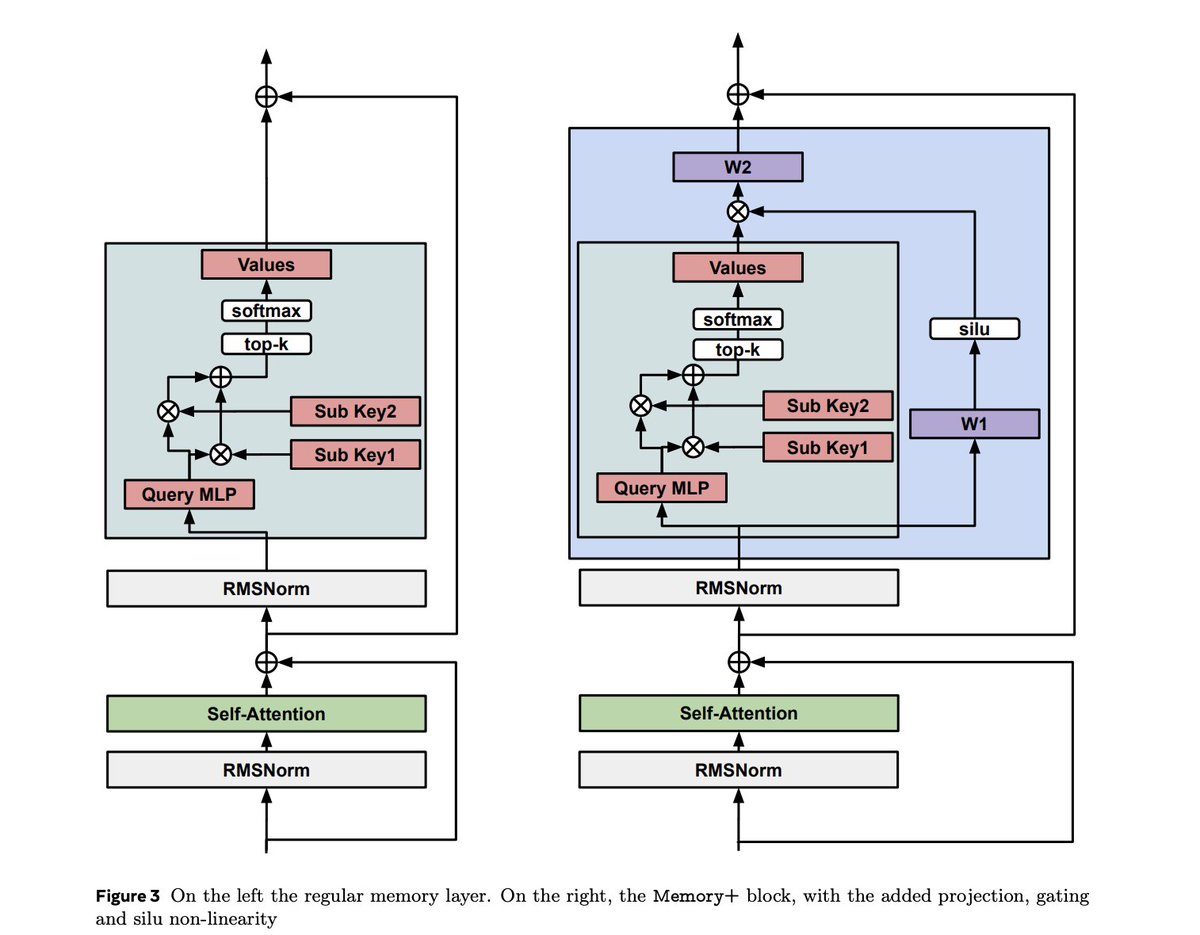
2
23
160
I'm in neurips! Reach out if you want to discuss xFormers, training/inference efficiency, CUDA kernels and more :) I'll spend some time at the Meta booth this week

0
0
12
I'll be at the #PyTorchConf in SF this Wednesday and Thursday - presenting the latest work from the xFormers team (poster)

0
0
7
You can find more details, from how we implemented this kernel, to the training recipe we used in this blogpost: https://t.co/MOcyAqDKwt
0
4
69
So we developed our own kernel for fast 2:4 sparsification, and it is an order of magnitude faster than alternatives. When sparsifying the weights, it makes linear layers 30% faster when considering the FW+BW passes!

2
3
59
For 2:4 sparse training to be efficient, the sparsification process + the sparse matrix multiplication must be faster than the dense matrix multiplication. This is *not* the case when using available primitives (eg from cuSparseLt).

1
1
22
2:4 sparsity is essentially meant for inference: the weight matrix no longer changes, and can be sparsified ahead of time. For training, it's more complicated.
1
0
22
These TensorCores can *only* do matrix multiplication, nothing more. But they have a special mode which is 2x faster: when the first operand is "2:4 sparse". A matrix is 2:4 sparse if every 4 values, at least 2 are zeros.

1
1
27
When training NNs, 99%+ of the compute comes from matrix multiplication (linear layers, attention etc…). NVIDIA GPUs have specialized hardware for matmuls (TensorCores), and they provide 95% of the flops of the device. So you want to be fast, you need to use these TensorCores.

1
1
27