

Sebastian Raschka
@rasbt
Followers
348K
Following
22K
Media
2K
Statuses
18K
ML/AI researcher & former stats professor turned LLM research engineer. Author of "Build a Large Language Model From Scratch" (https://t.co/O8LAAMRzzW).
Joined October 2012
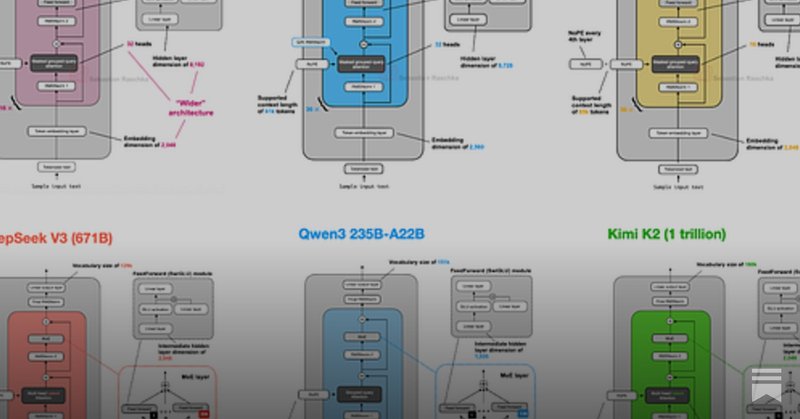
From GPT to MoE: I reviewed & compared the main LLMs of 2025 in terms of their architectural design from DeepSeek-V3 to Kimi 2. Multi-head Latent Attention, sliding window attention, new Post- & Pre-Norm placements, NoPE, shared-expert MoEs, and more.
magazine.sebastianraschka.com
From DeepSeek-V3 to Kimi K2: A Look At Modern LLM Architecture Design
33
409
2K
Next to Qwen3 of comparable size: Looks like gpt-oss is a wide (vs deep) model

27
242
2K
Finally! Will be working through the internals in more detail. The first surprising fun fact is they used bias units in the attention mechanism like ye goode old GPT-2. Super interesting, I haven't seen any other architecture doing that since then!


gpt-oss is out!. we made an open model that performs at the level of o4-mini and runs on a high-end laptop (WTF!!). (and a smaller one that runs on a phone). super proud of the team; big triumph of technology.
26
71
943
Link to the standalone-qwen3-moe.ipynb notebook: And a variant with KV cache (standalone-qwen3-moe-plus-kvcache.ipynb):
github.com
Implement a ChatGPT-like LLM in PyTorch from scratch, step by step - rasbt/LLMs-from-scratch
2
36
224
So, I did some coding this week. - Qwen3 Coder Flash (30B-A3B).- Mixture-of-Experts setup with 128 experts, 8 active per token.- In pure PyTorch (optimized for human readability).- in a standalone Jupyter notebook.- Runs on a single A100

31
276
2K
And let’s not forget that this model can run locally so you have to worry less about having private code bases accessed by proprietary apps and vendors.
4
2
66
This might be the best coding model yet. General-purpose is cool, but if you want the best at coding, specialization wins. No free lunch.

>>> Qwen3-Coder is here! ✅. We’re releasing Qwen3-Coder-480B-A35B-Instruct, our most powerful open agentic code model to date. This 480B-parameter Mixture-of-Experts model (35B active) natively supports 256K context and scales to 1M context with extrapolation. It achieves

24
64
702
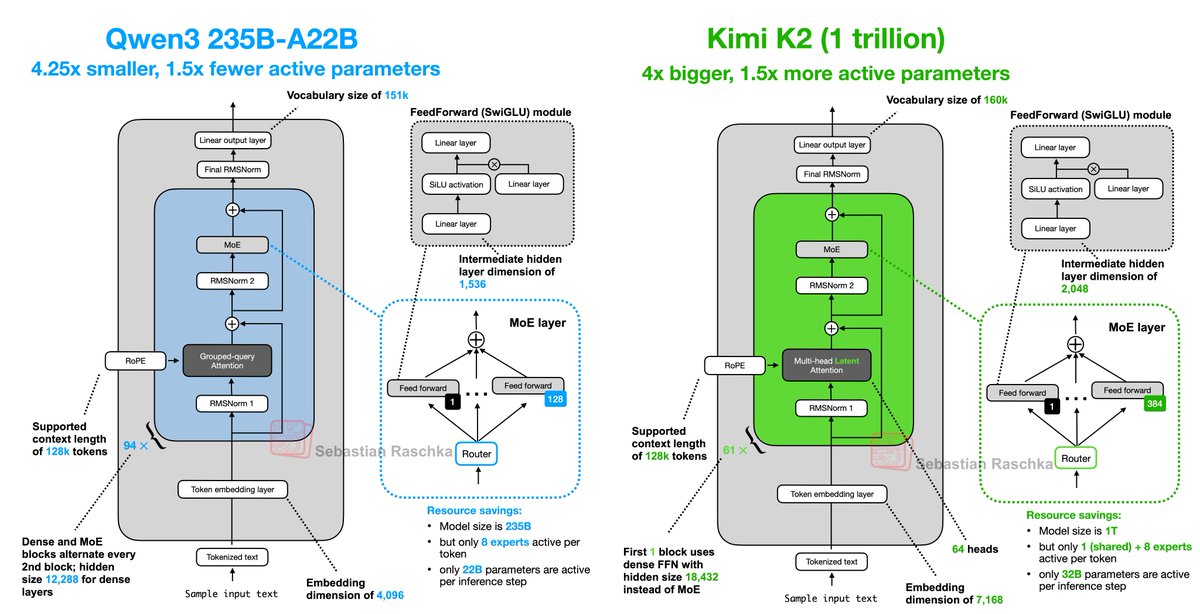
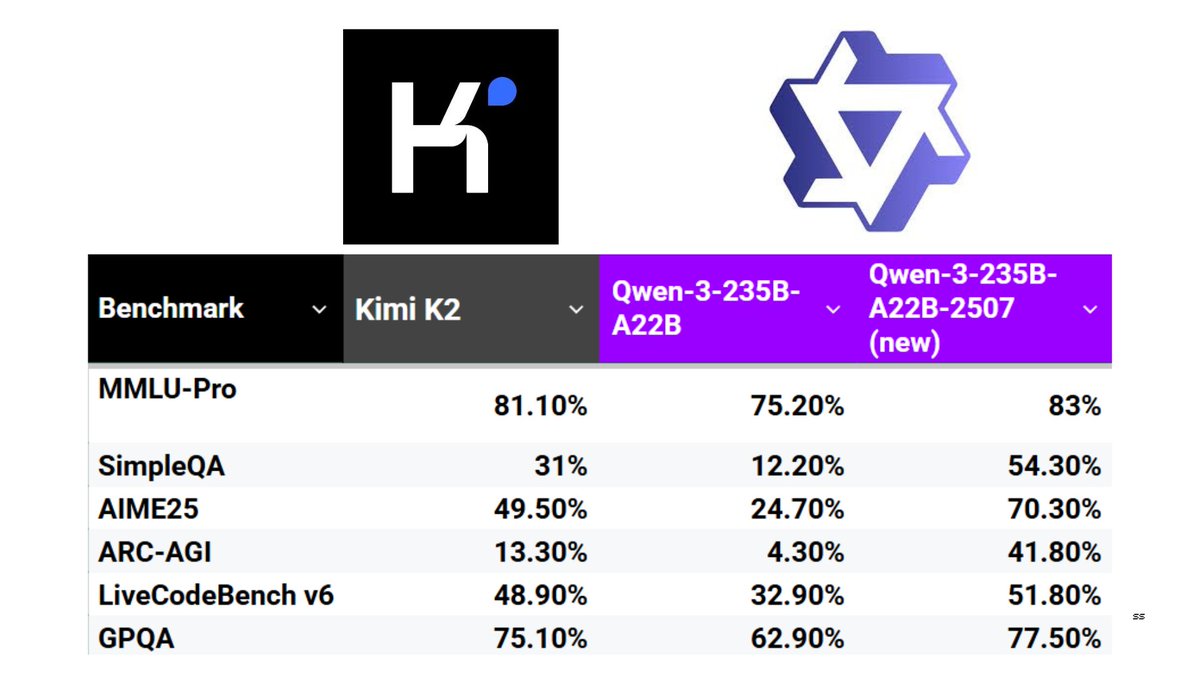
The new Qwen3 update takes back the benchmark crown from Kimi 2. Some highlights of how Qwen3 235B-A22B differs from Kimi 2: .- 4.25x smaller overall but has more layers (transformer blocks); 235B vs 1 trillion.- 1.5x fewer active parameters (22B vs. 32B).- much fewer experts in

Kimi K2 🆚 Qwen-3-235B-A22B-2507. The new updated Qwen 3 model beats Kimi K2 on most benchmarks. The jump on the ARC-AGI score is especially impressive. An updated reasoning model is also on the way according to Qwen researchers
23
145
1K
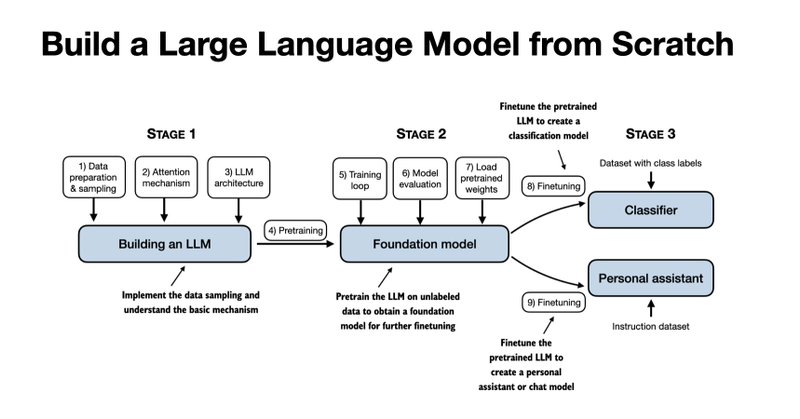
Btw if you're learning how to build LLMs from the ground up, there's now a 17h companion video course for my LLMs From Scratch book on Manning: It follows the book chapter by chapter, so it works great either as a standalone or code-along resource. It's
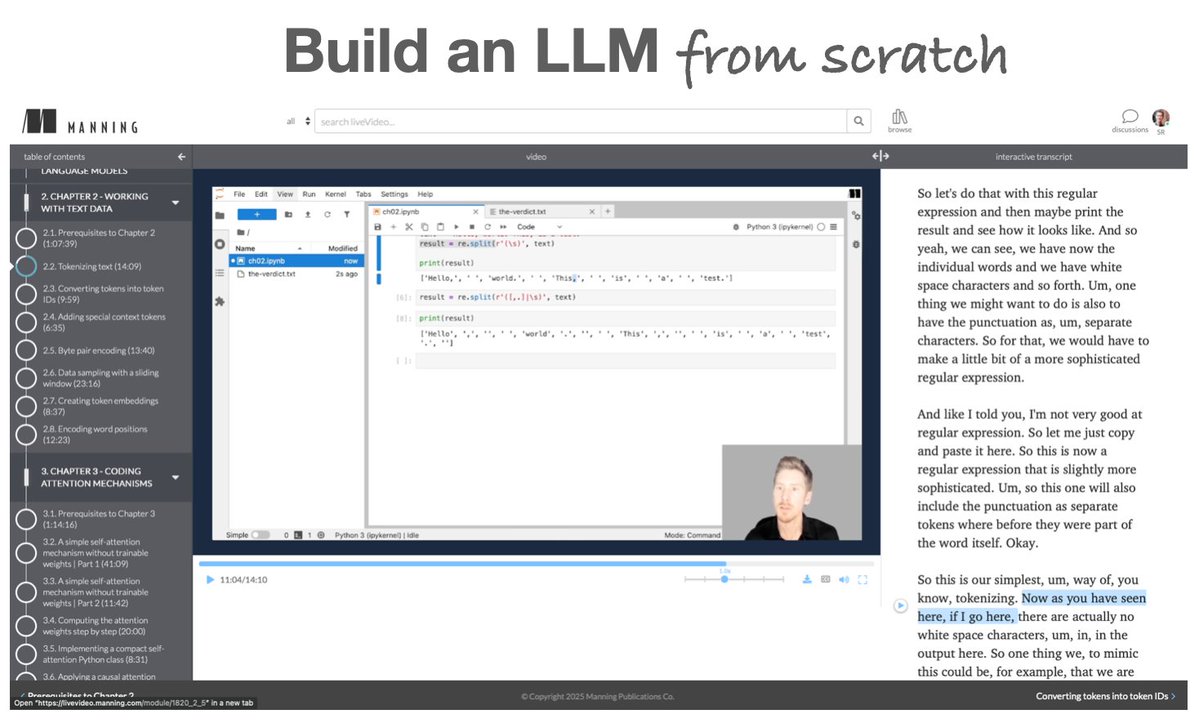
30
289
2K
Want to clarify that I only focused on the architectures there. Yes, one key novelty is not well reflected in the architecture but in the way it was trained. I.e., they replaced the popular AdamW optimizer with a modified version of Muon. According to the Kimi 2 developers,.
4
16
318
Kimi K2 is basically DeepSeek V3 but with fewer heads and more experts:

80
537
5K
RT @Yuchenj_UW: Holy shit. Kimi K2 was pre-trained on 15.5T tokens using MuonClip with zero training spike. Muon has officially scaled to….
0
137
0
TIL Cursor was literally named by the devs after all the cursing it caused when it trashed their own codebase.
12
8
237
RT @ShaneAParrish: I started coding again recently. No, not vibe coding. Actual coding. I fell in love with coding as a teenager. I’d st….
0
38
0
There were many people who asked me about joining their startup & co-founding a startup in the past 2 weeks. Not career advice, but just my 2 cents:.I actually think it’s a great time to start a bootstrapped startup compared to going the VC-backed route. These days, there are.
21
34
454
Surprised that no one mentioned the lack of a table of contents. In any case, there is one now!

2
2
81
If you're getting into LLMs, PyTorch is essential. And lot of folks asked for beginner-friendly material, so I put this together:.PyTorch in One Hour: From Tensors to Multi-GPU Training (.📖 ~1h to read through.💡 Maybe the perfect weekend project!?. I’ve.
sebastianraschka.com
49
431
3K
Updated the notebook to support the other dense models as well: Qwen3 0.6B, 1.7B, 4B, 8B, and 32B.
1
1
29