

Ben (e/sqlite)
@andersonbcdefg
Followers
3,591
Following
2,914
Media
405
Statuses
6,955
🤖 Computer scientist, next-word-prediction enjoyer 📊 Prev. research fellow @ Stanford RegLab 🛠️ bUiLdiNg sOmeThiNg nEw ( - YC S23) 🏳️🌈
San Francisco, CA
Joined August 2020
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Chelsea
• 287384 Tweets
#LAMeetandGreetxENGLOT
• 133284 Tweets
Celtics
• 80853 Tweets
Pacers
• 65981 Tweets
Tatum
• 29577 Tweets
Mikael
• 24783 Tweets
Barco
• 22523 Tweets
O Vasco
• 22108 Tweets
Omar Geles
• 21844 Tweets
Gaston
• 20796 Tweets
Fortaleza
• 20354 Tweets
Herrera
• 19331 Tweets
#WWENXT
• 17453 Tweets
#Aashirwad
• 14934 Tweets
Haliburton
• 13335 Tweets
Temperley
• 12572 Tweets
#サブウェイ新サンド
• 11283 Tweets
Tyrese
• 10259 Tweets
Vallenato
• 10060 Tweets
Jアラート
• 10022 Tweets


















Pinned Tweet

normal person: oh no, i ran out of chamomile tea
rationalist: i've updated on how much chamomile tea i have. my p(sleep) is 0
3
5
87
just tell me what stocks to buy for if the superconductor thingy is real
107
45
2K
As promised: Here's every article I could download as a .txt file from PubMed, up 'til August 18. Divided into:
- commercial license: ~100GB
- noncommercial license: ~60GB
- other/unknown license: ~15GB
- author-provided manuscripts: ~10GB
Raw & unprocessed. Links below:
29
111
864
Microsoft trained a text embedding model from Mistral-7B that topped the MTEB leaderboard! The secret sauce? Synthetic data. Step 1 was to generate a diverse list of retrieval tasks. I just did that for you! ☺️

15
94
739
You’re powerless. You’re weak. You’re unemployed. You do not understand the Fast Fourier Transform. You have no assets. You have no legitimate network.
You will never be a scientist. You will never build predictive models. You will never discover fundamental truths. You can’t do

@Katerationopia
@schwatd2
@Lormif1
@KathrynTewson
@Eodyne1
@chadcmulligan
@riScorpian
@col_bosch
@JosephPoulin175
@NoLongerBennett
Cope, and seethe, I bet you dont even know how to use the fast Fourier transform.
You will never be a scientist, you will never build predictive models, you will never discover fundamental truths, nobody will ever intellectually respect you or what you say
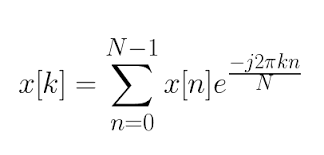
119
80
566
27
23
633
"sf is overrated" of course that's your contention. you're a stanford student who has only been to fisherman's wharf and union square so naturally that's what you'll believe, until you get an entry level SWE job, move to the mission, and start tweeting "SF is so back"

11
18
589
haiku is just crazy--mostly the pricing. at $0.25/M input tokens, it's the open-source killer, as it completely destroys the argument for using OSS models to save money. now the only reason to host your own mistral is for weird sex stuff
65
10
570
wait so snowflake is just a wrapper on the big 3 cloud providers? what is their moat. why doesn't AWS just build it. (i am practicing for being a VC 🥺)
24
7
537
amazing. "you like MoE? what if we made one of the experts the identity function." kaboom, 50% FLOPs saved 🤦♂️

Google presents Mixture-of-Depths
Dynamically allocating compute in transformer-based language models
Same performance w/ a fraction of the FLOPs per forward pass

6
92
619
15
24
530
since ppl are already screaming at me for saying it might sometimes be helpful to talk to chatgpt about your feelings i'll go ahead and make the more-controversial claim that chatgpt is better than 75% of the therapists you'd get on betterhelp. fight me!
50
18
456
maybe but it's a little sus that the message went from "text is the universal interface and will lead to super intelligence" to "oh wait haha not quite, but video will!" we'll see i guess but lowkey i think we are just throwing spaghetti against the scaling wall here

The main theme I got out of this video from the Sora authors: scale is all you need for AGI

46
63
639
45
17
447
posts like this annoy me. sleep is really important, & lack of it heavily impairs cognitive function. it's fun to stay up working on something cool, but doing it regularly is nothing to aspire to. founders should make time for sleep, physical activity, & socialization 👍

People grind hard at Newton
Came in at 6am this morning &
@jacksonhmg1
was finishing up an all-night tear
Tab is going to be an incredible product

28
5
302
21
20
417
why is everyone bragging about day-1 support for gpt-4o. my guy you swapped out one string for another string. do you want a lollipop 🍭
19
8
426
For many fine-tuning and RAG projects, getting data is the hardest part. That's why I'm proud to introduce Galactic—an open-source library for cleaning and curating text data for AI. Deduplicate, detect PII, cluster, and more. Powered by local embeddings.
pip install galactic-ai
13
56
353
i dont want trump to win but i do want to hear him say floating point operation
16
15
345
@ryxcommar
the people quoted absolutely would keep every penny if it were them and we all know it. just pure sour grapes and want other people to be as miserable as they are
1
0
333
so Baron, why can't you and the Atreides just share the spice?

6
15
328
@twofifteenam
your first mistake was thinking that startup founders are not trying to attract twinks
6
4
285
spoke to an AWS engineer on the Claude-4 cluster project. he was complaining how Anthropic refuses to use any GPU that's not "cute". AWS has to manually put stickers on all the GPUs to make them look like this or it's worthless. daniela amodei checks each one herself

18
12
274
@___frye
he saw all the gay coded disney villains and thought they were meant to be role models
1
0
261
i dont feel bad for ML PhDs who think "my job is ruined, i can't do anything outside a big lab" etc. i can think of >10 low hanging fruit things "someone should do" that im too busy for bc i have to "make revenue". academia is 100% unfettered from use value, yall have it so easy.
5
4
252
wait this is very stupid. the relationship is like, the opposite of exponential? the scaling laws (as i understand them) seem to indicate for each bump in capabilities has an exponential increase in cost, which is why each training run uses 10x more FLOPs than the last.

25
8
240

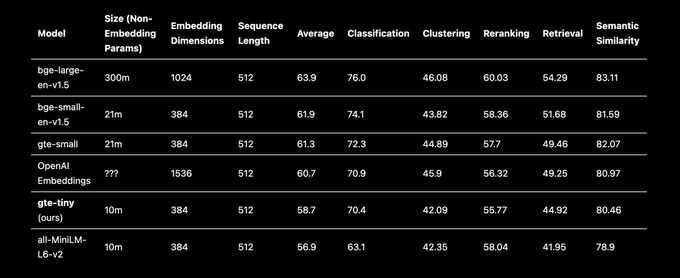
New embeddings model, gte-tiny, is published! Distilled from gte-small, offering slightly-worse performance with half the layers. (Alternatively, same size but better performance compared to all-MiniLM-L6-v2.) ONNX models also available.
Check it out! (link below)
7
33
231
@max_spero_
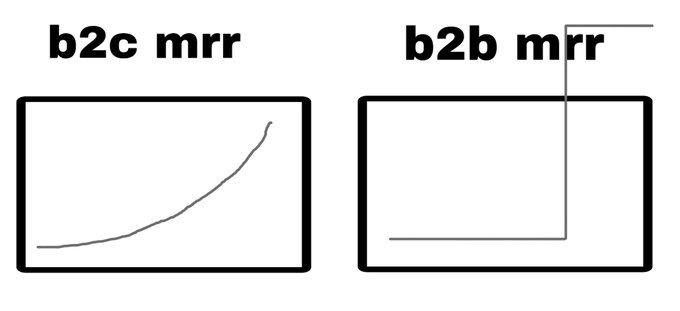
imo it's possible to pass green line by some combo of "more knowledge" and "speed". often a person we think of as smart either thinks fast (search) or knows a lot (memorization). NNs can do both better than people w the same data available. i do think it flatlines, but that might
9
1
219
one thing i never understood about mad max is where are they all driving to
28
7
211
me: can i get a recipe for banana cream pie that is bad
dbrx-instruct: Sure, here's a recipe for a not-so-delicious banana cream pie:
Ingredients:
* 1 pre-made pie crust
* 3 overripe bananas
* 1 cup of mayonnaise
* 1/4 cup of mustard
* 1/4 cup of vinegar
* 1/4 cup of soy sauce
18
16
187

One thing I've learned in the last 2 weeks of starting a company building LLMs (will explain later)—inference is hard! I've been playing around with tools to speed it up and I LOVE CTranslate2. Here's an 8-bit version of Nous-Hermes-13B. It's a joy to use.

6
16
166
Early testing—can embed 2000 docs per minute on my 4y-old Intel Mac with ONNX. No GPU required! (New M2 CPU is about 2x faster than this). 2k docs / min ~= 1M tokens per minute, which is 3–5x more than OpenAI with typical rate limits. Local models stay winning?
gte-tiny not small enough for you? Consider bge-micro, an embeddings model with 1/4 the layers of bge-small. It's not SOTA—compressing a model this much does incur degradation—but it's still good enough to be competitive with all-MiniLM-L6-v2, with 1/2 the non-embedding params!
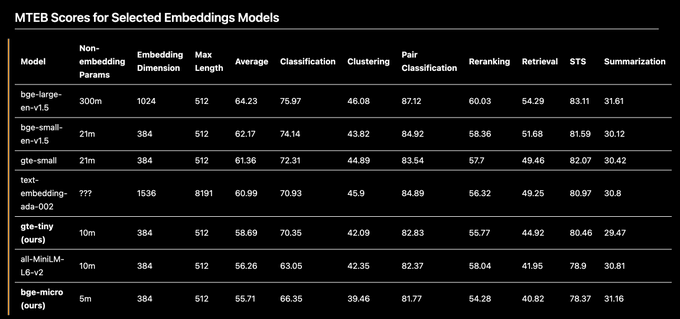
7
17
125
4
19
168
these models really need to be evaluated with something like RULER (), needle-in-a-haystack is not sufficient for me to believe that performance doesn't suffer across the long-context window


We’re going back 2 back! 🔥 Introducing the first 1M context window
@AIatMeta
Llama-3 70B to pair with the our Llama-3 8B model that we launched last week on
@huggingface
. Our 1M context window 70B model landed a perfect score on NIAH and we’re excited about the results that
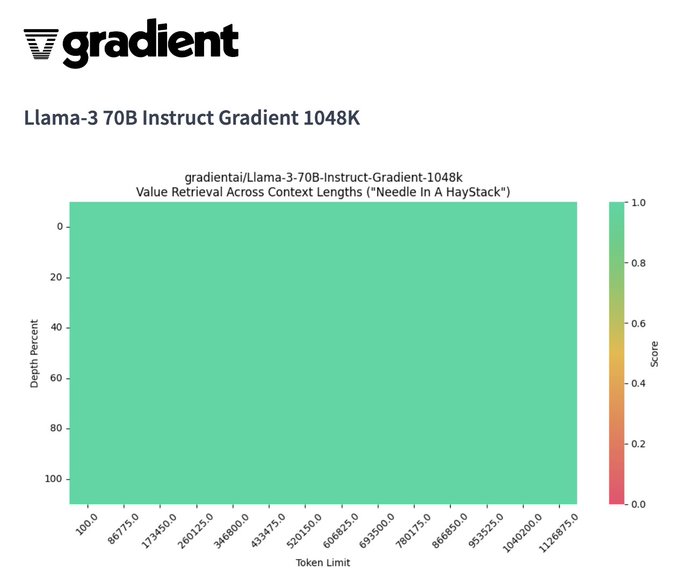
39
115
656
13
14
165
made for myself. might be useful to you too. ~150 LoC utility for pulling and running onnx text embedding models. imo the easiest/fastest way to run them on CPU.

7
16
157
a couple weeks ago i said ONNX was the fastest and bestest way to run embeddings on your laptop. that's still true... unless you have a silicon GPU. if you do, you should use MLX instead. here's a utility for MLX text embeddings that Just Works (tm)

6
13
150
can we stop backfilling the decision to live in the city you want to live with a business justification? its okay to just live where you want, you don't have to add cope on top about how Tulsa is going to be the new AI capital, trust me bro

The best AI companies are going to come from NYC — not SF.
(with a few notable exceptions)
31
7
143
16
4
158
@abacaj
to be fair, "open source" does not have to be synonymous with "local models" or "consumer GPUs". open source software can be developed in the cloud, it's just that lots of OSS devs have a reflexive distaste for cloud computing
4
2
149
if gpt4 is sparks of agi, what is claude3? chunks of agi? dribbles of agi? nuggets of agi?
25
4
147
Anyscale endpoints charges $1/million tokens for Llama-70B. Might want to double-check your work here ;)


Llama-2-70b costs $59 per million tokens
GPT-3.5 Turbo costs $2 per million tokens
23
18
329
5
7
146
@KhanStopMe
@lilianweng
lots of parts of therapy are like, doing homework in a CBT workbook. there are iOS apps, chatbots, etc. for this purpose. i don't see why a language model can't be a helpful partner for self-reflection and talking through feelings.
19
2
140
people don't understand what janus is doing because most adults have lost the capacity for play
8
10
144
@eigenrobot
> looking for accounts to follow
> ask girl if eigen is charming or hot
> she doesnt understand
> pull out illustrated diagram explaining what is charming and what is hot
> she laughs, "he's a good robot sir"
> follow him
> he's hot
2
3
141
we are going to re invent BERT and i am so here for it

I have SERIOUS questions about this.
Is it cheaper to do reasoning via embeddings than text completion?
As a simple example, isn’t it cheaper to embed a sentence and see if it’s closer to “positive” or “negative”, than ask ChatGPT if the sentence is negative or positive? But
29
20
254
4
6
139
so i never really knew or bothered to figure out how to profile my code but i just made a script run 2.5x faster because 60% of the time was spent hashing numpy arrays. LOL. maybe flamegraphcels are on to something
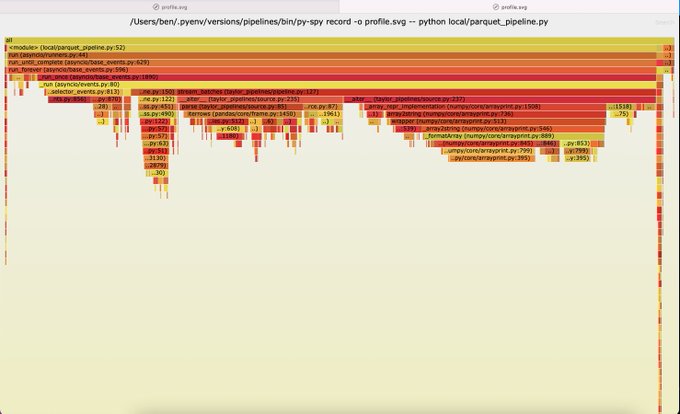
9
4
141
"you should invest in companies that are fastest at using ctrl+F" incoherent ravings of the utterly deranged
why is everyone bragging about day-1 support for gpt-4o. my guy you swapped out one string for another string. do you want a lollipop 🍭
19
8
426
10
0
147
every time someone says they are building a product for data scientists i have to remind them that there are only like 100,000 data scientists total


4
13
139
so you can't use DBRX to improve other LLMs... but they never said you can't use it to make them Worse
10
1
135
mosaic team is great
- smart, scientific, data-centric
- great at posting
- no weird agi millenarianism
very pumped for them & this release 🎉

It’s finally here 🎉🥳
In case you missed us, MosaicML/ Databricks is back at it, with a new best in class open weight LLM named DBRX. An MoE with 132B total parameters and 32B active 32k context length and trained for 12T tokens 🤯
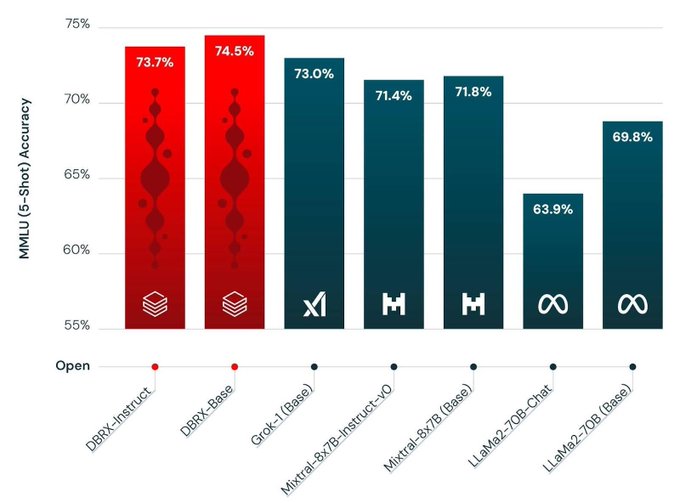
28
130
831
6
10
135

gte-tiny not small enough for you? Consider bge-micro, an embeddings model with 1/4 the layers of bge-small. It's not SOTA—compressing a model this much does incur degradation—but it's still good enough to be competitive with all-MiniLM-L6-v2, with 1/2 the non-embedding params!
7
17
125
so basically i made a 1b llama model by ripping out the first 3 layers of llama 13b and it's probably going to be awful but let's see what happens. if you want to see more fun stuff like this pls (angel) invest in my startup so we can close our round and get back to work :)
5
6
124
it's also named after a dude called joseph pilates. it sounds like one of these stupid jokes but it's Actually Real


for the longest time i thought pilates was something like yoga then you find out it's something done on machinery that's clearly designed either for torture or the weirdest sex you've ever had and it changes your perspective on women forever

93
291
6K
1
5
120

Whenever you see ✨ in the product you know there’s about to be some latency
3
8
195
1
1
121
GCP's auth system actually makes me feel like i'm taking crazy pills. why do i have to install an entire CLI to send one (1) API request with curl?? i can only conclude that they do not actually want people to use GCP
19
1
121
me: im finally learning gpu programming. im going cuda mode. look isnt it cool
friend: you wrote a for loop in python
9
4
117
this one of those things ima let other people try for 5 years and see how it pans out for them

I’m about to do the Lumina treatment, a cure for dental cavities developed by Lantern Bioworks.
I figured I’d do an unboxing and let you come with me on this journey. Here’s the box:

247
848
11K
9
0
119
broke: dense models 🙄
woke: mixture of experts 🤩
bespoke: 🤯🤯🤯

4
4
115
you will never get more reps or learn faster than by quitting your job and starting a company 💪
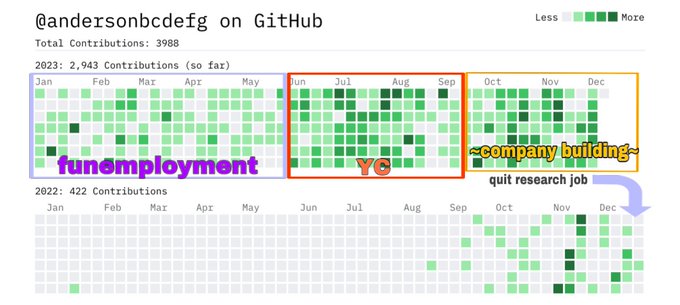
3
2
112

so quick recap on GCP Vertex AI:
- gemini 1.0 is horse shit
- gemini 1.5 is expensive af for mid quality
- they refuse to let you do more than 60RPM with claude haiku
what in the ever living fuck am i meant to spend 100k in credits on? DO NOT say bigquery
18
3
113
@somewheresy
spending the last 18 months laughing at the AI because it "can't do hands" and then getting mogged by it is peak tragic downfall
4
1
109


Unfortunately , too few people understand the distinction between memorization and understanding. It's not some lofty question like "does the system have an internal world model?", it's a very pragmatic behavior distinction: "is the system capable of broad generalization, or is
96
541
4K
9
5
108
OpenAI is building Her but cohere is building Him (for enterprise)

in oxford theres a place called Jesus College. u can touch the grass here it’s allowed. an intern told me they were doing a big push for their students to study AI. feel relieved because we gonna need all the help we can get to build Him (for enterprise)




5
3
83
9
6
113
want to label 1.4 million data points with an LLM?
- openai: "lmao got 5 hours?"
- anthropic: "lol kys"
- vertex ai: "haha we are impossible to use on purpose"
- modal labs: "i gotchu king 🥺"
3
3
108
who would win: nerd snipe galaxy brain subquadratic architecture
OR
one brute force circley boi

Watched a super interesting talk on Ring Attention, probably the magic behind Gemini's 1 million context window
You organize your devices (GPU/TPU) in a ring, each computing a part of the final attention output
Each device needs to see all keys/values to produce its part
1/2
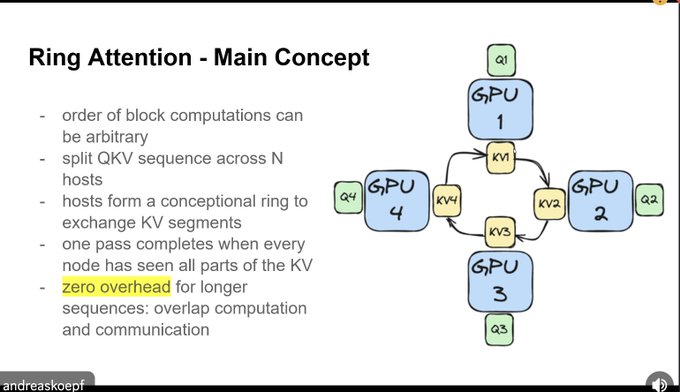
12
141
859
5
7
107
ok let me be helpful and not just catty: a typical mixture-of-K-experts is in no way K models put together. it is a transformer where at each feed-forward layer, each token is routed through 1 of K FFNs. it is trained as 1 model.
even the companies serving APIs for the MoE models are spreading wrong information about what MoE is. it's joever
6
2
50
8
6
103
gary marcus vs. openai

@CFGeek
imo diminishing returns is sort of ill-defined. scale maximalists see a power-law relationship and think "ok cool let's put in 10x more compute". skeptics see a power law and think "looks like diminishing returns". neither of them is technically wrong?
1
0
39
0
2
107


@suchenzang
smh that's less data than like tinystories or proof pile. are they not aware we can download all of pubmed, all of arxiv, all of semantic scholar, not to mention MIT OCW? this is nothing
4
1
102

> time to first token
performance metrics dreamed up by the utterly deranged. how about time to useful answer
streaming llm completions is dumb. just make it faster

10
2
64
14
3
101
Excited to share what we've been working on since we launched Galactic last week. In case you missed it—Galactic is an open-source library for curating and cleaning unstructured text data for ML training & retrieval.
pip install galactic-ai

5
8
99
sorry for not texting u i was training literally hundreds of text classifiers 😐
this is live :) after creating a warehouse on trytaylor dot ai, u can train a text classifier that's 10x (100x? idk, a lot) faster than openai. no labels? u can use clusters as labels! 🤯 pls try 🥹
8
5
97
@nearcyan
i love that it still has the silly little alignment artifacts like numbered lists while also being fucking annoying
4
0
94
no one told me that being a "technical founder" is 90% devops 😢
13
0
97
@jxmnop
security concerns aside, "unembedding" back to text would actually be incredibly useful for stuff like interpreting cluster centers in latent space! i'm definitely gonna look into integrate some of these models into an open-source project for exactly that
7
2
97


2nd version of bge-micro (5M backbone params) is an improvement! Went from just below all-MiniLM to just above :D Next target is OpenAI's ada embeddings.

4
12
90
interested by the recent trend of startups calling themselves ____ labs. some of you are not a lab. where are the microscopes. where are the mice. you're making react components
11
6
90



wait this is actually so smart im pissed i didnt think of it. RLHF is fucking annoying because you need 3 models in memory: reference model, policy model, reward model. but all 3 are usually (or can be) finetuned from the same base model which means..... LoRA time! this rules

Efficient RLHF: Reducing the Memory Usage of PPO
paper page:
Reinforcement Learning with Human Feedback (RLHF) has revolutionized language modeling by aligning models with human preferences. However, the RL stage, Proximal Policy Optimization (PPO),

2
89
309
2
5
86
@jxmnop
this is just like when gwern said you dont need to know the formula for integrals just randomly sample points and see how many are under the curve
1
1
88
benchmarks, onnx, and long-context finetuning incoming but made a 4096-ctx bge-small!
jina ai im coming for your ass
7
8
86
claude honeymoon period is over. i'm pissed off again.😭
9
1
86