

Niels Rogge
@NielsRogge
Followers
16K
Following
2K
Media
505
Statuses
2K
ML Engineer @ML6team, part-time at @huggingface. @KU_Leuven grad. General interest in machine learning, deep learning. Making AI more accessible for everyone!
Belgium
Joined April 2010
Today my Transformers-Tutorials repo hit 2,000 stars on @github! 🤩 . Very greatful :) the repo contains many tutorial notebooks on inference + fine-tuning with custom data for Transformers on all kinds of data; text, images, scanned PDFs, videos ⭐.
github.com
This repository contains demos I made with the Transformers library by HuggingFace. - NielsRogge/Transformers-Tutorials
38
249
2K
RT @AdinaYakup: Came back from vacation to find the Chinese AI community dropped all these SOTA models in just 2 weeks 🤯🚀. But looks like p….
0
4
0
Ok ngl this is cool! The end of LoRa's??. Powered by @FAL as inference provider. Try it out below!


🚀 Excited to introduce Qwen-Image-Edit!.Built on 20B Qwen-Image, it brings precise bilingual text editing (Chinese & English) while preserving style, and supports both semantic and appearance-level editing. ✨ Key Features.✅ Accurate text editing with bilingual support.✅
0
2
22
SAM 2 uses a "memory bank" which allows it store previous predictions. Key to the model's performance is the dataset: SA-V, 4.5x larger + ~53x more annotations than the existing largest one. Checkpoints: Demo:

huggingface.co
0
0
14
SAM 2 by @AIatMeta has finally been integrated into @huggingface Transformers! 🔥. It's a generalization of SAM 1 to video, allowing you to segment and track something you care about across a sequence of frames. SOTA performance, Apache 2.0 license
7
53
396
I really don’t get why Sebastian is focusing on architectural details here. Whether you use RMSNorm or LayerNorm, 4 or 16 attention heads, pre or post norm it really doesn’t matter at all lmao. Any Transformer can learn it at scale.

Gemma 3 270M! Great to see another awesome, small open-weight LLM for local tinkering. Here's a side-by-side comparison with Qwen3. Biggest surprise that it only has 4 attention heads!

4
8
103
The world of AI is crazy right now cause you can just claim to have extracted the base model from GPT-OSS while effectively you’ve just trained a lora on Fineweb lol.

the world of AI is crazy right now because an intern will be like "sorry, let me double-check the numbers on that tonight" and then spin up an experiment with the power of 10,000 washing machines.
2
6
244
LLMDet leverages an LLM to densely annotate 1M images on which a Grounding DINO variant gets trained. Models: Zero-shot arena for you to compare against OWL-ViT, Grounding DINO:

huggingface.co
0
5
17
Awesome week for computer vision @huggingface🔥. Besides DINOv3 we added support for LLMDet, the SOTA for zero-shot object detection (@CVPR '25 highlight). Detect instances in scenes just via prompting, no training involved.
9
94
764
RT @BaldassarreFe: Say hello to DINOv3 🦖🦖🦖. A major release that raises the bar of self-supervised vision foundation models. With stunning….
0
272
0

Looks like Claude models are in a league of their own when it comes to tool calling. Curious where the recent Kimi-K2 and GLM-4.5 models land


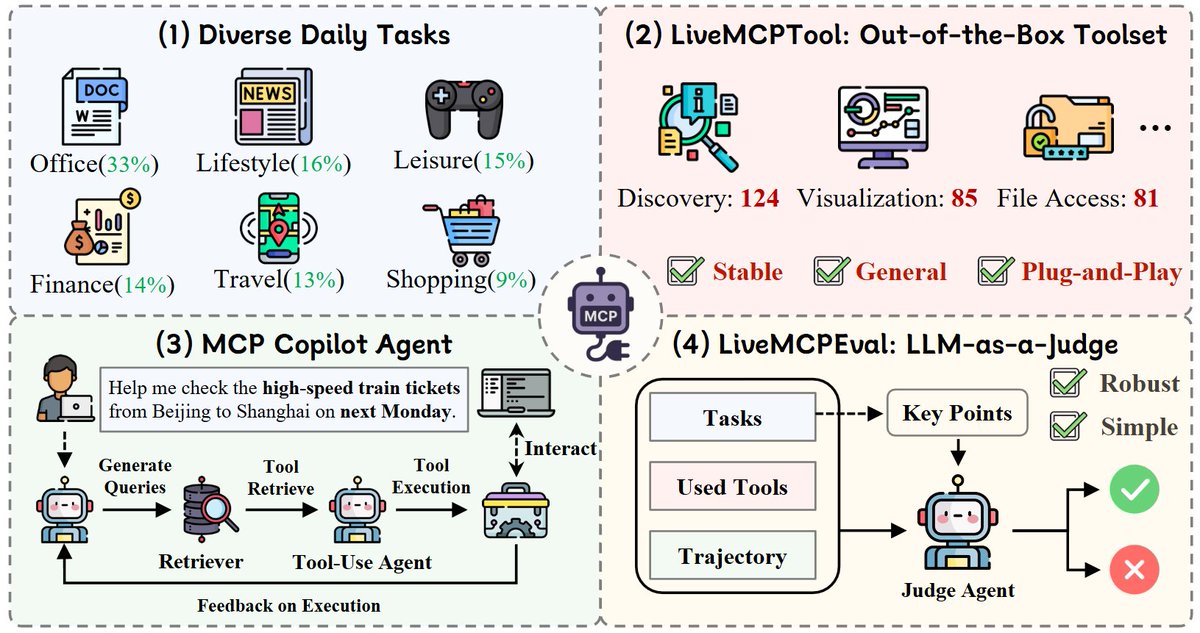
New benchmark alert!. LiveMCPBench challenges LLM agents to navigate the complexities of Model Context Protocol (MCP) tools. Tests real-world scenarios with 95 tasks, 70 MCP servers, and 527 tools!
33
39
478
RT @ylecun: I don't wanna say "I told you so", but I told you so. Quote: "Ilya Sutskever, co-founder of AI labs Safe Superintelligence (SS….
0
614
0
Pretty cool new RL framework by @Microsoft 👀

Microsoft just released Agent Lightning on Hugging Face. Train ANY AI agents with Reinforcement Learning with almost ZERO code change!. A flexible and extensible framework that fully decouples agents from RL training.

2
8
51
Wow you just have to read to see how mad OpenAI customers are . Looks like they messed up. I recommend just trying @lmstudio for free with an open @huggingface model! No one is going to steal your weights.
reddit.com
Subreddit to discuss ChatGPT and AI. Not affiliated with OpenAI. Thanks, Nat!
1
1
7

Why I'm bullish on @GoogleDeepMind ?. Unlike OpenAI's GPT-5, they already have a unified model that handles everything. Both 2.5 Pro and Flash perform "dynamic thinking" by default, which means that the model decides when and how much to think. No router involved

2
1
14
Interesting, so this is a router issue. It should learn that queries like this require thinking. Would the router be a BERT-like model? An LLM?.


3
1
20
As LLM performance starts to plateau, we will finally enter a new era where AI research will be about finding novel architectures, new training paradigms again. The recent hierarchical reasoning model (HRM), JEPA are cool examples of that

3
2
40

Let’s all laugh at this terrible take by former Stability AI CEO

3
1
24