
Mufan (Bill) Li
@mufan_li
Followers
855
Following
496
Media
78
Statuses
383
Postdoc @Princeton ORFE | Prev: PhD @UofTStatSci @VectorInst
Toronto, Ontario
Joined March 2014
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
George Floyd
• 268575 Tweets
Toni Kroos
• 267619 Tweets
#GMMTVOuting2024
• 156968 Tweets
Gaga
• 106139 Tweets
ダービー
• 91488 Tweets
#precure
• 71379 Tweets
Libertarians
• 62484 Tweets
コミティア
• 54698 Tweets
#ブンブンジャー
• 37241 Tweets
Karoline
• 33630 Tweets
#仮面ライダーガッチャード
• 29369 Tweets
May Special
• 29282 Tweets
キュアニャミー
• 25542 Tweets
プリキュア
• 23380 Tweets
OUTING 2024 X GEMINI FOURTH
• 21677 Tweets
ジャスティンミラノ
• 20905 Tweets
設営完了
• 20344 Tweets
Millonarios
• 18830 Tweets
ホッパー1
• 17060 Tweets
ブンバイオレット
• 16398 Tweets
Medina
• 14136 Tweets
レガレイラ
• 14033 Tweets
東京競馬場
• 13958 Tweets
Saint MSG Insan
• 12610 Tweets
#超超超超ゲーマーズday2
• 12274 Tweets
Ross Ulbricht
• 11675 Tweets
ユキちゃん
• 11284 Tweets
まゆちゃん
• 10617 Tweets




















Pinned Tweet

I’m excited to announce that in July 2025 I will be joining
@UWaterloo
as an Assistant Professor in the Department of Statistics and Actuarial Science! Until then, I will continue at Princeton as a DataX Postdoc Fellow, working with Boris Hanin.
I have many exciting projects
27
5
218
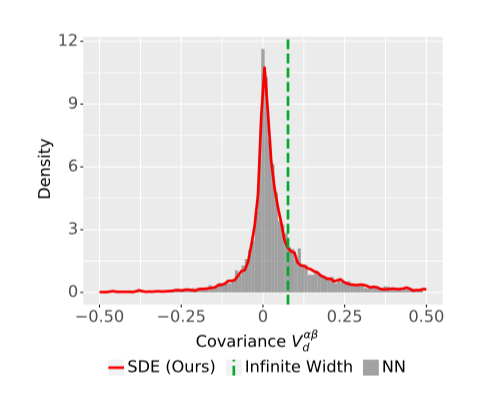
Infinite-width limits don't behave like real networks in many ways.
In new work, we identify the "Neural Covariance SDE" underlying the infinite-DEPTH-and-width limit and provide more evidence that this limit better matches the properties of real networks
6
57
360
I wrote a blog post on a gem hidden in an 80 page paper that nobody has time to read or interpret, which imo, is actually which most interesting result.
TL;DR: a new technique to establish Poincare inequalities, with some interesting consequences

1
17
112
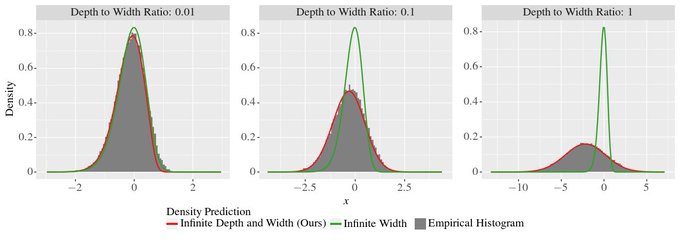
There has been a flurry of work beyond the infinite-width limit. We study the infinite DEPTH-AND-WIDTH limit of ReLU nets with residual connections and see remarkable (!) agreement with STANDARD finite networks. Joint work w/
@MihaiCNica
@roydanroy
4
19
110
What is the complexity of sampling using Langevin Monte Carlo (LMC) under a Poincaré inequality? We provide the first answer to this open problem.
Joint work with Sinho Chewi,
@MuratAErdogdu
, Ruoqi Shen, and Matthew Zhang

2
15
91
@rasbt
@liranringel
It turns out that stacking non-linearities in deep networks naively is the core reason causing unstable gradients. Shaping them at a precise size dependent rate is the key to extending the network to arbitrary depth.
See eg

1
4
41
A really nice paper studying the Riemannian structure of deep linear networks, in particular the SVD coordinates leads to a very clean formula for the volume form

0
5
36
Come visit our NeurIPS poster tonight at 7:30-9pm EST to learn about the infinite-DEPTH-AND-WIDTH limit of ResNets!
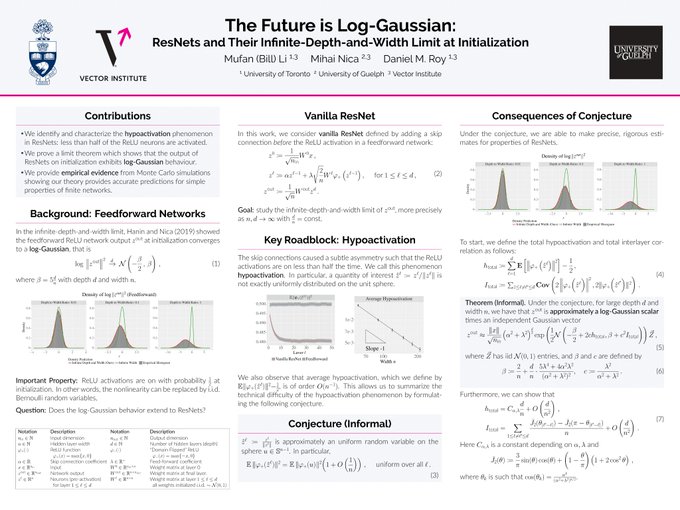
There has been a flurry of work beyond the infinite-width limit. We study the infinite DEPTH-AND-WIDTH limit of ReLU nets with residual connections and see remarkable (!) agreement with STANDARD finite networks. Joint work w/
@MihaiCNica
@roydanroy
4
19
110
0
9
30
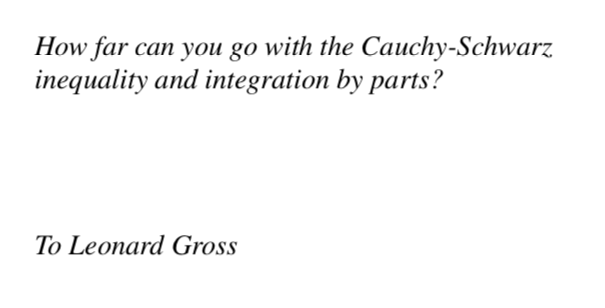
@karen_ullrich
@y0b1byte
@BahareFatemi
I think "systemic" is key here. From my experience talking to other grad students, essentially everyone admits they have the same problems, even the ones that are doing well in terms of publication. There's definitely something wrong with the environment.
1
0
22


Martens et al. and Zhang et al. recently proposed to shape the activation to be more like the identity. But how should the shape depend on the size of the network?
There’s a very intuitive answer actually: the rate that makes the covariance Markov chain converge to an SDE!
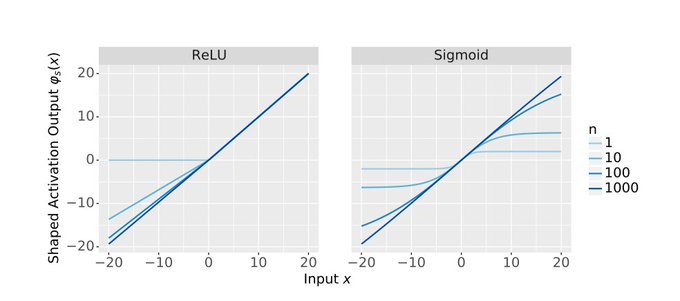
1
3
20
@shortstein
@icmlconf
At the same time, I have also received reviews claiming my main theorems are wrong without further explanations 🤷♂️🤷♂️
0
0
17

@sam_power_825
From talking to a former researcher on ADAM, the continuous time ODE system was difficult to work with compared to other simpler algorithms. Even in the convex case, it was non-trivial to construct a Lyapunov function

0
0
14
@sp_monte_carlo
Currently doing a reading group on this set of notes and just finished Hörmander’s. Super grateful that Sinho suggested we start from Eldredge first, things make a lot more sense here
1
0
14
A new blog post on a clever Stone-Weierstrass based technique, illustrated through an alternative proof of Itô's Lemma. This post consumed far too much effort to write, so hopefully it's at least of mediocre quality.
1
3
13

@thesasho
@radcummings
@markmbun
Every time I use Jensen, I check the direction of E(X^2) >= (EX)^2 and confirm the difference is variance
0
0
13
2
0
12
Many great mathematical advances are also just expert usage of integration-by-parts and Cauchy--Schwarz, which seems to be familiar and unimportant to most people.
Bakry, Gentil, and Ledoux certainly agrees with their book dedication.

Many believe that great AI advances must contain a new “idea”. But it is not so: many of AI’s greatest advances had the form “huh, turns out this familiar unimportant idea, when done right, is downright incredible”
42
208
2K
1
0
11

@mraginsky
@AlexGDimakis
All these papers on scaling laws are hinting that large networks are probably converging. And if we learned anything from statistical physics, it’s probably that we should try to describe the limit instead of banging our heads against the wall with finite size problems
1
0
10
Congratulations Jeff! Very well deserved and I’m so happy for you!

I'm pleased to announce that I've accepted a faculty pos'n in the dept. of statistics and actuarial science at my alma mater,
@WaterlooMath
, and a faculty affiliate pos'n
@VectorInst
, starting summer 2023! Meanwhile, I will be a postdoc
@DSI_UChicago
, starting September!
33
8
264
1
1
10
The above plot was actually the squared magnitude of post activations in a ReLU network, which forms a random walk converging to a geometric Brownian motion!
This recovers known log-Gaussian results, but we also get the nice interpretation of depth-to-width ratio as time.
2
1
9

Is there any experts in trignometric series out there that would like a challenge? I would offer to buy beer for any solutions offered
3
0
8
@roydanroy
@thegautamkamath
I remember Kevin tried to sell nonstandard analysis to first year PhD students with “you get to use cool words like ‘ultrafilters’ and ‘hyperfinite’“ and yeah it didn’t work
1
0
8
@ccanonne_
I will be forever amazed at this sequence of implications between inequalities, beautifully summarized by Villani in "Optimal Transport, Old and New".

1
0
8
You ever seen a proof SO CLEAN that you just can't help but write it up? I encountered one such proof using Doob's h-transform to show Dyson Brownian motion are independent Brownian motions conditioned to not intersect. Shortest post so far!

0
1
8
This perfectly describes my experience in academia, certainly wasn’t thinking of OpenAI when I was reading

A lot of very smart people work in strange ways / with a lot of quirks (e.g. contemplating for hours and appearing to do nothing, while then suddenly having 100x output burst).
This usually makes them not a great fit for traditional corporate world, where you often have to fake
238
2K
9K
0
0
8
@sp_monte_carlo
If you can write the two laws as time marginals of two diffusion processes with the same diffusion coefficient, then the KL can be upper bounded by the KL of the path measures, which admits a closed form via Girsanov. See eg
0
0
8
We believe this result can be extended to non-Gaussian weights. See an earlier universality result for MLPs by
@BorisHanin
and
@MihaiCNica
0
0
7

1
0
7
@cjmaddison
@roydanroy
@thegautamkamath
This reminds me of Michel Talagrand writing a new book to make his old book "obsolete"

0
0
7
@sam_power_825
Random sorting networks also has a scaling limit such that each trajectory become sinusoidal.
I don’t think Duncan is on Twitter but he does really good work in probability theory, this is from his thesis
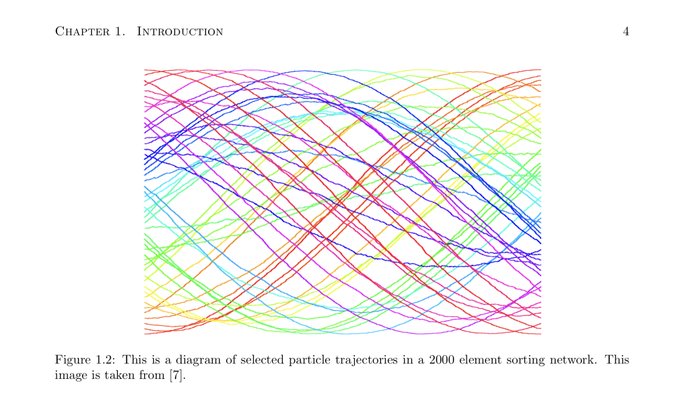
1
1
7
As a result, the infinite depth-and-width limit is not Gaussian. This work extends results for fully connected MLPs where the analysis is much simpler. See
@MihaiCNica
’s youtube video for an introduction.

2
0
7
You might be wondering: where does Brownian motion even come from in a neural network?
Well, a central limit theorem of sorts - for random walks! If you reduce the size of each RW step and take more steps, you eventually get a Brownian motion!
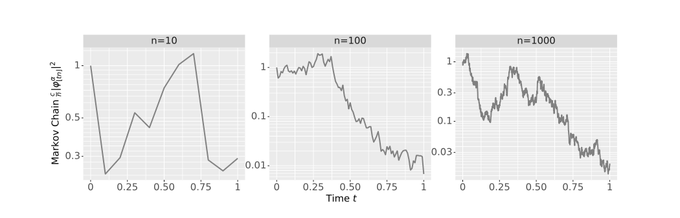
2
0
7
@sp_monte_carlo
On a related note, I never understood the point of drawing any diagrams for neural network architectures. The transformer diagram was particularly confusing for me.
Just write it out in matrix notation. It’s like two lines and much more clear.
1
0
7
First paper here is easily the most underrated paper of the year. It’s the first algorithm independent sampling lower bound, and gets an unexpected log log dependence on the condition number.

‘The query complexity of sampling from strongly log-concave distributions in one dimension’
‘Rejection sampling from shape-constrained distributions in sublinear time’
1
0
3
1
0
7
@deepcohen
There is also a strange cognitive dissonance that somehow adding experiments to a theory paper hurts the original paper. Surely some experiments are better than none, if no strong claims are being made with them?
3
0
7
Infinite depth transformers!
It's only
@ChuningLi
's first paper, and I wish my first paper was this good!

How do you scale Transformers to infinite depth while ensuring numerical stability? In fact, LayerNorm is not enough.
But *shaping* the attention mechanism works!
w/
@ChuningLi
@mufan_li
@bobby_he
@THofmann2017
@cjmaddison
@roydanroy
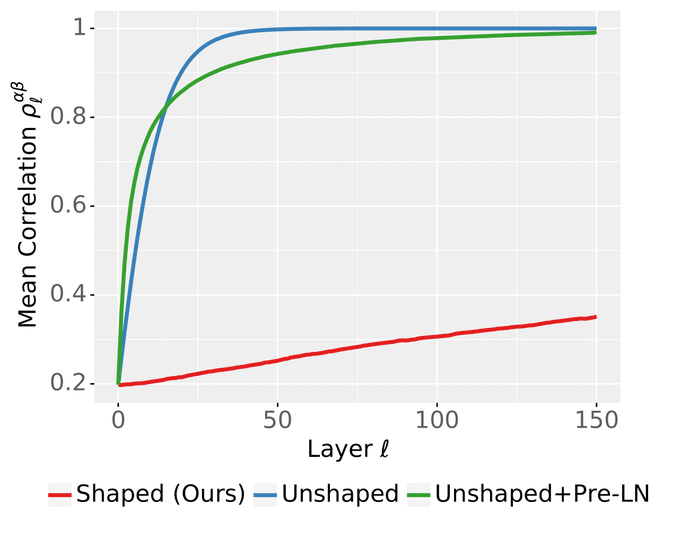
6
35
217
0
0
7
If you have any questions, or are interested in the many exciting directions this work opens up, feel free to reach out! I would be happy to chat :)
0
0
6
For practitioners using shaping to improve training: beware the correlation distribution is pretty heavily skewed! Shaping with infinite-width theory is not quite sufficient to fully prevent degeneracy.
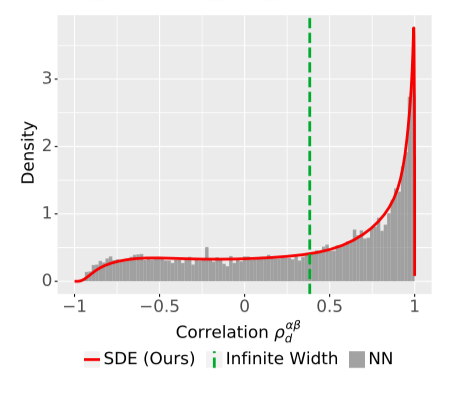
1
0
6
You might already realize what’s going to happen: identify the covariance Markov chain and derive the SDE.
However there’s just a little problem, the usual covariance Markov chain is more like a recursion (observe the f(Y) here) and it doesn’t converge to an SDE!
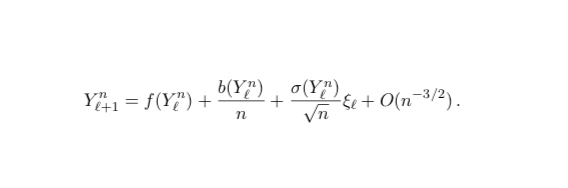
1
1
6
@sp_monte_carlo
It's uniform on a fractal set, but not sure if there is a lot you can say based on this alone

1
0
6
@sam_power_825
@roydanroy
@junpenglao
@colindcarroll
Suppose your gradient is not Lipschitz, for example f(x) = x^4, even gradient descent diverges to infinity.
Also even with ergodicity, the stationary distribution may not be nice at all. Since SGD in finite steps are finite point masses, the limit is likely a fractal like set.
1
0
6
@deepcohen
This is actually a positive sign when training dynamics are consistent. We find this phenomenon implies hyperparameters transfer, see eg Figure 3e and 4 here
0
0
6
Technically the theory is not wrong - neural nets are terrible uniform learners. However, uniform learning is the wrong goal post.
We do need a better theory, and perhaps fewer people driving "disbelief" prematurely.

When empirical evidence clashes with a theory, it is the theory that is wrong (or misinterpreted), not the universe.
The well-documented initial resistance of many ML theorists to deep learning was due to complete theory-fueled disbelief: this can't possibly work!
40
90
648
0
0
5
@miniapeur
Partial differential equations. So much information and consequences contained in a single line of math, really hard to appreciate with courses alone.
1
0
5
Never understood how anyone expects good work without being personally invested in the work, and as a result taking rejections personally.


Dear PhD students with a submission to
@NeurIPSConf
, soon ~20% of you will receive a desk reject. Here some suggestions to deal with it in a healthy way.
First, this is not personal: a paper written by you was rejected, not you. Keep your self-worth unlinked from your work. 1/5
10
99
612
1
0
5
Our main result is a precise description of the distribution of the output of the network in the infinite depth-and-width limit. One key observation: the magnitude contains a log-Gaussian factor. The exact constants and Gaussian parameters can be found in the paper.
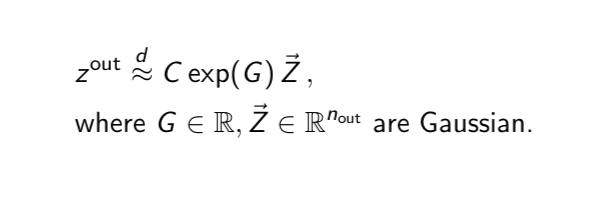
1
0
5
How is the infinite depth-and-width limit different? In short, each layer of width (n) carries an error term of size O(1/n), and increasing depth (d) compounds the error exponentially. At the heart of the analysis is the following "dichotomy":
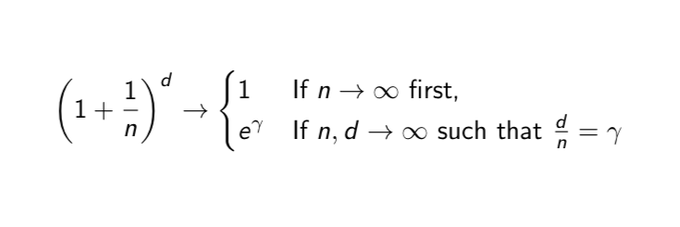
1
0
5

@sp_monte_carlo
Gradient descent with epsilon noise can escape saddle points exponentially fast
0
1
5
To summarize, I want to observe that the complexity of sampling is captured by functional inequalities — a fundamental property of the distribution. This presents a generic and precise framework to understanding what makes sampling hard.
0
0
5
@OmarRivasplata
In Markov diffusions, it’s more natural to interpret Q as the target or base measure. If P_t is the law of the diffusion at time t and Q is the stationary measure, then KL(P_t|Q) converges to zero under a log-Sobolev inequality
0
1
5
@NAChristakis
@sinanaral
@TechCrunch
> a glorified curve fitter: overfits data
> media: omg this AI is outsmarting humans
0
2
5
For theorists, we also show that our proposed scaling is critical:
if the shape converges to identity too slow, we get a degenerate limit;
If too fast, we get the same limit as linear networks!
See Proposition 3.4 and 3.10.
1
1
4
@roydanroy
Last time I was honest about an issue at work during an AMA with the CEO, I pissed off some senior management and got a talk from boss. So I think the comments here are extremely biased. Anonymous poll?
2
0
4
@roydanroy
@togelius
Since the proof of the Poincaré conjecture doesn't fit in 6-8 pages, then Perelman and later authors should have just wrote 100 papers instead. Duh.
0
0
4
However, networks with skip connections introduce correlations between layers, which complicates the analysis. Surprising observation: with residual connections, the population of neurons is HYPOactivated, i.e., fewer than half of the ReLU units are active.
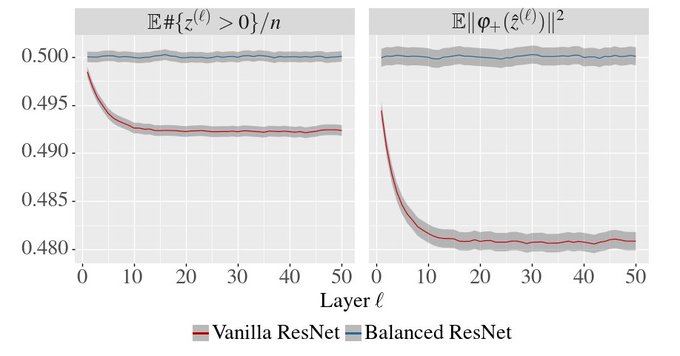
1
0
4
So we titled the paper "the future is log-Gaussian:..." just for the memes

There has been a flurry of work beyond the infinite-width limit. We study the infinite DEPTH-AND-WIDTH limit of ReLU nets with residual connections and see remarkable (!) agreement with STANDARD finite networks. Joint work w/
@MihaiCNica
@roydanroy
4
19
110
0
0
4
@roydanroy
@pfau
@gaurav_ven
@jamesgiammona
I want to say in this case, it is still strange. The reason is because before taking any limits, the neurons form a Gaussian process conditional on the previous layer. For this Gaussian structure to go away, we would need the kernel to be non-constant in the large sample limit
1
0
4
@PreetumNakkiran
You can write all your series expansions in terms of trees so nobody can read them
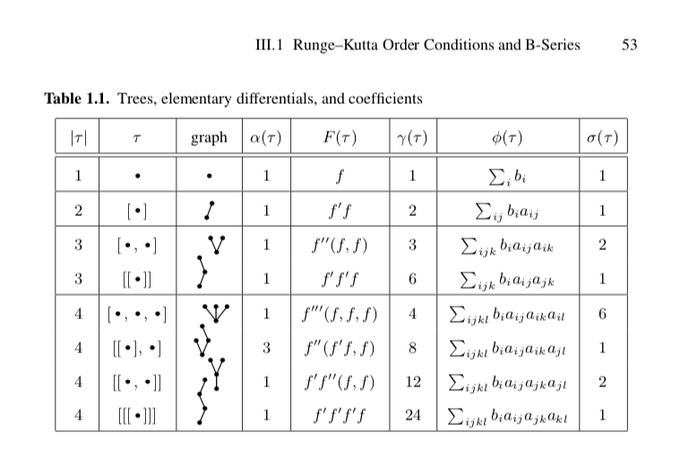
2
0
4

The number of monthly new ML +AI papers at arXiv seems to grow exponentially, with a doubling rate of 23months.
Probably will lead to problems for publishing in these fields, at some point.
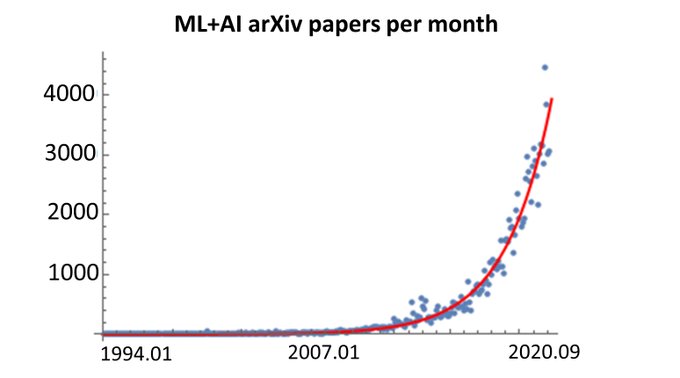
43
142
759
2
0
4
In case you actually want to sort through the original paper
0
0
4
@IsomorphicPhi
Brezis is really nice. Evans is more like a reference text, not a good place to learn from imo.
If you really want to get interested in PDEs though, an application is probably important. For me that was the beautiful connection to SDEs
1
0
4
Now you might ask, what’s so special about the Poincaré inequality? Indeed, it is not. The Latala–Oleszkiewicz (LO) inequality interpolates between Poincaré (alpha=1) and log-Sobolev (alpha=2).
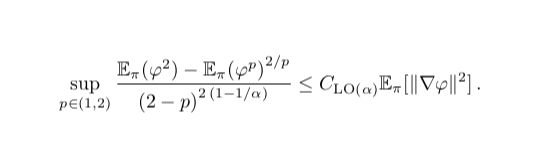
2
0
4
@sp_monte_carlo
I don't know why it's not more celebrated but this simple construction of the modified equation (aka backward error analysis) in Hairer, Lubich, Wanner always blew my mind

1
0
4


@hardmaru
@NeurIPSConf
Wait... am I going to have to use space on the ethical/societal implications of my generalization bound?
8
1
45
0
1
4
@shortstein
They are related by the OU-generator, where the stationary Poisson equation is exactly the second order PDE version of Stein’s equation, and LSI also corresponds to the same generator.
0
0
4
Additionally, for smooth activations, we also show that the limiting SDE can have finite time explosions! This depends on the choice of how the shaped activation is centered, and we provided an if-and-only condition for choosing such a center.
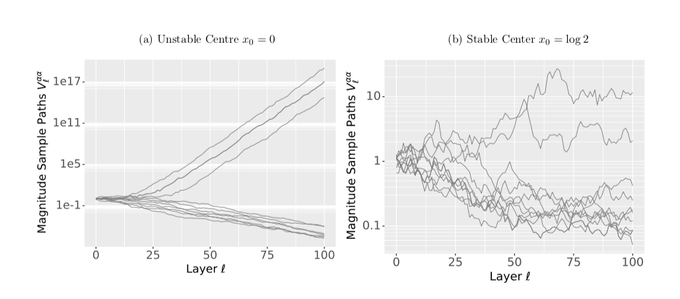
1
1
4

@cjmaddison
@sam_power_825
Some of the craziest notation I have ever seen came out as an extension of Butcher series - these are Runge-Kutta order conditions for SDE weak error
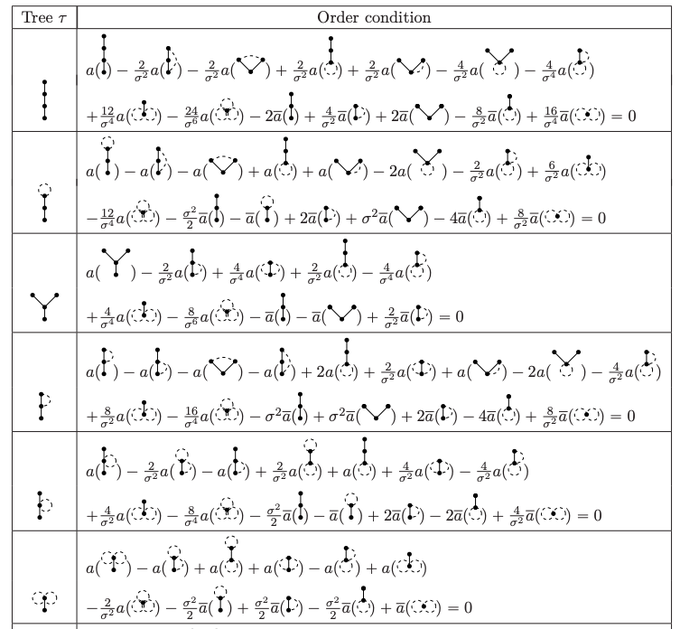
1
0
4
@sam_power_825
Why not both? Sometimes it’s nice to just write d\mu for short hand notation, but for a kernel or marginal of a joint, it’s more clear to writer K(x, dy)
2
0
4
A really nice result!

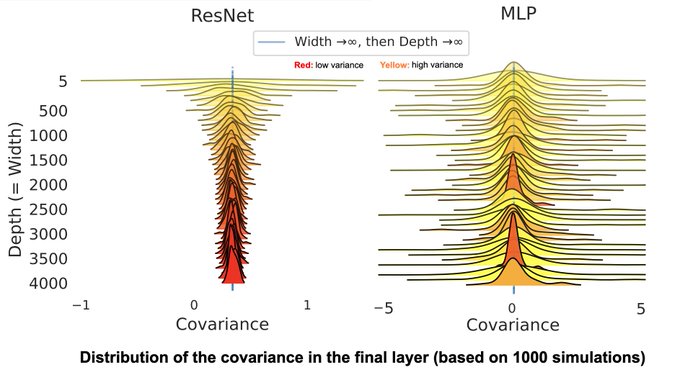
Q: What happens to the neural covariance when both Width and Depth are taken to infinity?
A: it **depends** how you take that limit.
However, for ResNets, we show (joint work with
@TheGregYang
) that you always get the same covariance structure..
Link:
3
29
154
0
0
4
More generally, appropriately scaled Markov chains converge to solutions of SDEs - this the main technique we use in this work.
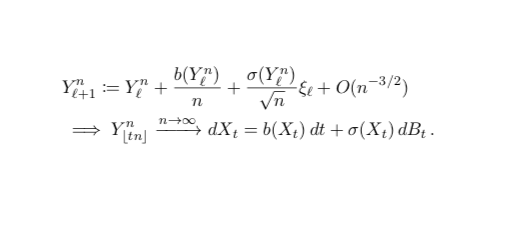
1
0
4
@ccanonne_
Yes, these are from an older version of Dmitry Panchenko's excellent lecture notes on probability theory. Here's the most updated version posted on his website, Strassen's Theorem is in Section 4.3
1
0
4
After some simplifications, our main result implies the following runtime complexity in terms of Rényi divergence under Poincaré
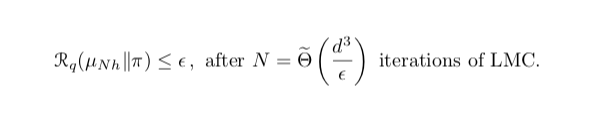
2
0
4
Obviously this can only mean compression algorithms are sentient

I think it's reasonable at this stage to call for a moratorium on the use of gzip and to nuke any datacenters we suspect of using illicit compression technology.
10
36
443
1
0
3
@roydanroy
For a lot of exercises like compound lifts, if you can’t breathe fully, then it’s hard to get the full exercise. Having to breathe through a mask in between squat/deadlift sets also feels terrible :/
I’d rather not go if I have to wear a mask
0
0
3
@fentpot
@miniapeur
That’s the beauty of it. Even without an analytical solution, the PDE characterizes a ton of properties of the solution. Usefulness depends on whether a PDE naturally arises in your work.
0
0
3
@wgrathwohl
Imagine making a career out of making incremental changes to other people's methods, adding a ridiculous amount of trial and error, just to show it to a room full of other nerds like you after you beat some SOTA score with pure luck.
Yes I'm talking about speed running.
0
0
3
@Karthikvaz
@sp_monte_carlo
It’s helpful to think of probability distributions as manifolds, equipped with the Wasserstein metric, and the potential is KL divergence.
Then LSI is the PL inequality, which is equivalent to exponential decay of KL. Strong convexity is equivalent to exponential decay of W2.
1
0
3
@moskitos_bite
I really enjoyed Villani’s topics in optimal transportation as an intro. Many proofs had a short special case, which is sufficient as a first read.
1
0
3


@PreetumNakkiran
I actually think it’s because OT is the most natural language to study probability and stochastic processes. Wasserstein metric naturally induces a Riemannian manifold structure on the space of probability distributions, and this fact is incredibly underrated
1
0
3
0
0
2
@shortstein
Isn't it just the total variation (of general signed measures) of the difference for two probability measures?
2
0
3