
Lorenzo Noci
@lorenzo_noci
Followers
436
Following
479
Media
13
Statuses
74
PhD in Machine Learning at @ETH working on deep learning theory and principled large-scale AI models.
Zurigo, Svizzera
Joined December 2013
Pretraining large-depth transformers just got easier! . 🚀 HP transfer across model scale .⚡ Compute-efficient pretraining. Super cool collab with.@DeyNolan @BCZhang_ @mufan_li @CPehlevan @ShaneBergsma @BorisHanin Joel Hastness @CerebrasSystems.

(1/7) @CerebrasSystems Paper drop: TLDR: We introduce CompleteP, which offers depth-wise hyperparameter (HP) transfer (Left), FLOP savings when training deep models (Middle), and a larger range of compute-efficient width/depth ratios (Right). 🧵 👇

1
8
45
Pass by if you want to know about scaling up your model under distribution shifts of the training data. Take away: muP needs to be tuned to the optimal amount of feature learning that optimizes the forgetting/plasticity trade off.

🚨 Excited to present our new paper at 🇨🇦 #ICML2025! 🚨. "The Importance of Being Lazy: Scaling Limits of Continual Learning". Great collab with @alebreccia99, @glanzillo11 , Thomas Hofmann, @lorenzo_noci. 🧵 1/6

0
4
25
RT @AurelienLucchi: Our research group in the department of Mathematics and CS at the University of Basel (Switzerland) is looking for seve….
0
7
0
RT @albertobietti: Come hear about how transformers perform factual recall using associative memories, and how this emerges in phases durin….

arxiv.org
Large language models have demonstrated an impressive ability to perform factual recall. Prior work has found that transformers trained on factual recall tasks can store information at a rate...
0
9
0
RT @LenaicChizat: Announcing : The 2nd International Summer School on Mathematical Aspects of Data Science.EPFL, Sept 1–5, 2025. Speakers:….
0
22
0
RT @blake__bordelon: Come by at Neurips to hear Hamza present about interesting properties of various feature learning infinite parameter l….
0
7
0
with @alexmeterez (co-first author), @orvieto_antonio and Thomas Hofmann. Paper:

arxiv.org
Recently, there has been growing evidence that if the width and depth of a neural network are scaled toward the so-called rich feature learning limit (\mup and its depth extension), then some...
0
0
6
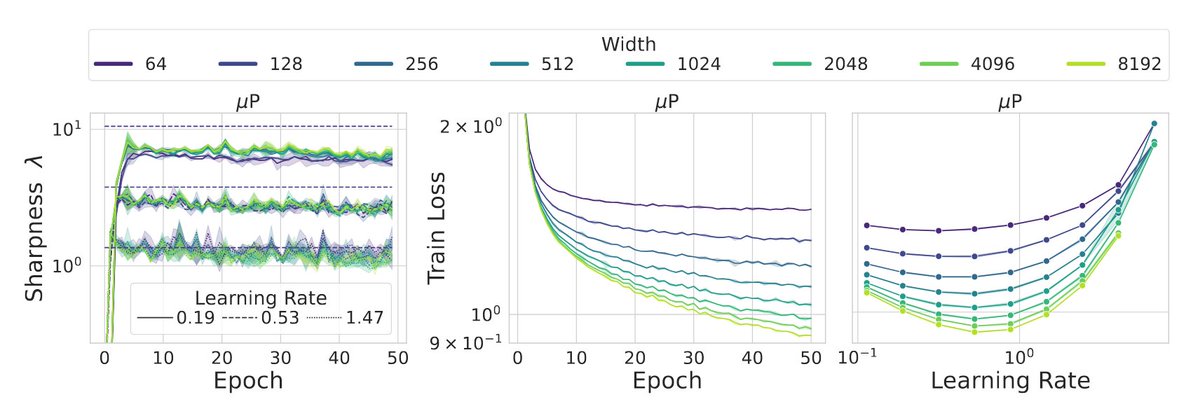
Excited to share a cool finding about neural network landscapes! We discovered that their curvature is scale-invariant throughout training, a property we call Super Consistency. This is linked to learning rate transfer! . Check out our NeurIPS poster #2403: Wed 11 Dec, 4:30 p.m📍
1
16
122
Systematic empirical analysis of the role of feature learning in continual learning using scaling limits theory. Meet Jacopo in Vancouver :).
🎉 Excited to be in #Vancouver next week for #NeurIPS to present results from my Master’s Thesis at the Scalable Continual Learning Workshop on December 14th!. 🚀 Our work investigates the role of scale and training regimes in Continual Learning. What did we find? 👇. 1/3.
0
0
5
Indeed very useful :).

We collected lecture notes and blog posts by group members about recent topics in deep learning theory here. Hope it is useful!.
0
0
6
RT @bobby_he: Updated camera ready New results include:. - non-diagonal preconditioners (SOAP/Shampoo) minimise OF….
0
31
0
RT @cjmaddison: I'm also recruiting PhD/MSc students this coming cycle, with an eye towards applications in drug discovery. .
0
9
0
RT @AurelienLucchi: My group has multiple openings both for PhD and Post-doc positions to work in the area of optimization for ML, and deep….
0
63
0
RT @bobby_he: Outlier Features (OFs) aka “neurons with big features” emerge in standard transformer training & prevent benefits of quantisa….
0
39
0
RT @ABAtanasov: [1/n] Thrilled that this project with @jzavatoneveth and @cpehlevan is finally out! Our group has spent a lot of time study….

arxiv.org
From benign overfitting in overparameterized models to rich power-law scalings in performance, simple ridge regression displays surprising behaviors sometimes thought to be limited to deep neural...
0
28
0
RT @GregorBachmann1: From stochastic parrot 🦜 to Clever Hans 🐴? In our work with @_vaishnavh we carefully analyse the debate surrounding ne….
0
5
0
For more details, including results on Transformers, ablations on loss functions and batch size, and the depth extension of our results, please check out our paper:
0
0
7
Our work is connected with previous works on Edge of Stability (@deepcohen et al., , in the sense that muP networks converge to the EoS value of 2/lr, and they do so width-independently (dashed lines in the sharpness plots).
1
0
6