
Jason Lee
@jasondeanlee
Followers
10,226
Following
2,908
Media
15
Statuses
1,330
Associate Professor at Princeton and Research Scientist at Google DeepMind. ML/AI Researcher working on foundations of LLMs and deep learning
Princeton. NJ
Joined October 2018
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
アイスの日
• 48299 Tweets
自動車税
• 46030 Tweets
Saka
• 45619 Tweets
Guinea
• 44722 Tweets
VISA
• 39553 Tweets
#素のまんま
• 31961 Tweets
Caramelo
• 30317 Tweets
LOREAL PARIS X ML
• 28983 Tweets
#モニタリング
• 27722 Tweets
Rodri
• 25159 Tweets
Foden
• 17986 Tweets
rock 'n' roll
• 15004 Tweets
ブレマイ
• 14570 Tweets
#Masterplan_BF_20M
• 14307 Tweets
Saliba
• 13623 Tweets
#THE夜会
• 11688 Tweets
Isak
• 11395 Tweets
Last Seen Profiles





















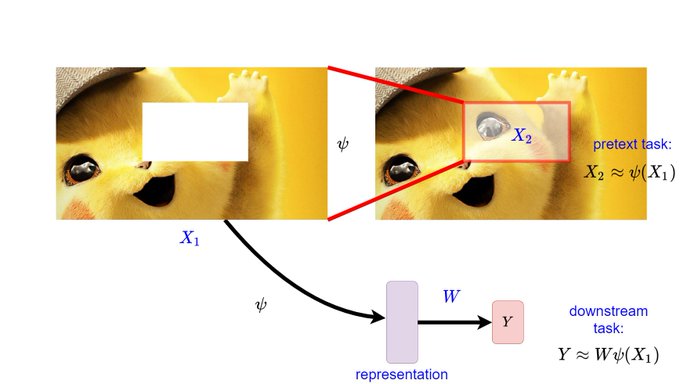
Predicting What You Already Know Helps: Provable Self-Supervised Learning
We analyze how predicting parts of the input from other parts (missing patch, missing word, etc.) helps to learn a representation that linearly separates the downstream task.
1/2
2
105
525
I didn't get this talk at all. Why does good compression, eg near kolmogorov complexity imply that it's a good learner??

There're few who can deliver both great AI research and charismatic talks. OpenAI Chief Scientist
@ilyasut
is one of them.
I watched Ilya's lecture at Simons Institute, where he delved into why unsupervised learning works through the lens of compression.
Sharing my notes:
-…
55
432
3K
40
18
276
Announcing our new result that 3-layer nets are conscious and 2-layer nets are provably not conscious.

6
14
253
Extremely happy with this result! Mechanistic Understanding of how Transformers Learn Causal Structure!

Causal self-attention encodes causal structure between tokens (eg. induction head, learning function class in-context, n-grams). But how do transformers learn this causal structure via gradient descent?
New paper with
@alex_damian_
@jasondeanlee
!
(1/10)

6
93
414
1
20
251
I strongly dislike the term inductive bias. It sounds like jargon to me, and whenever we use it like "the inductive bias allows it to learn well on domain X". Translation: we don't understand why it learns well on domain X, but it beats the competitors! Must be inductive bias!

“What is the inductive bias of XX” is a fancy way of asking “on which distributions/tasks does XX work well?”
1
0
26
14
19
210
I want to remind everyone that disabilities may also be invisible. Your colleagues, group members, students, postdocs, may be going through this. I am not an eloquent person, so WE NEED TO PAY MORE ATTENTION TO THE DISABLED AND THEIR ACCOMMODATION

Being a
#disabled
junior researcher in
#AI
comes at a massive price; when your disabilities flare, you are on your own: there is neither medical insurance nor salary for you during this difficult time
This is a very important aspect that needs our attention
#Academia
#Insecurity
0
15
120
1
31
203
Any suggestions for lecture notes /videos/short books on stochastic calculus or sdes? Looking for something operational, not rigorous
22
19
202
How do physicists learn stochastic calculus? There is no way they spend a month defining brownian motion /into integral.
Any suggestions for lecture notes /videos/short books on stochastic calculus or sdes? Looking for something operational, not rigorous
22
19
202
33
10
184
I won!!! Much of the proposal is based off work with
@AlexDamian
and
@tengyuma

20
0
154
Why are official announcements posted to medium? I click this link and can't read the article. Instead I get something about paying to subscribe to medium to read...

The
#NeurIPS2021
paper submission deadline has been extended by 48 hours. The new deadline is Friday, May 28 at 1pm PT (abstracts due Friday, May 21). Read the official announcement to learn more.
8
142
465
8
2
146
@tdietterich
How come this paper can be uploaded without tex source? Was it written in word? Asking because I always download source and change the font size to make it readable for my eyes.

9
9
116
We identified the third order effect in two algorithms, sgd and gd.

I think the reason why second-order methods keep underperforming relative to first-order methods in deep learning is that first-order methods are more powerful than the theory gives them credit for. First-order methods + large step sizes can implicitly access specific **third
3
19
159
3
5
94
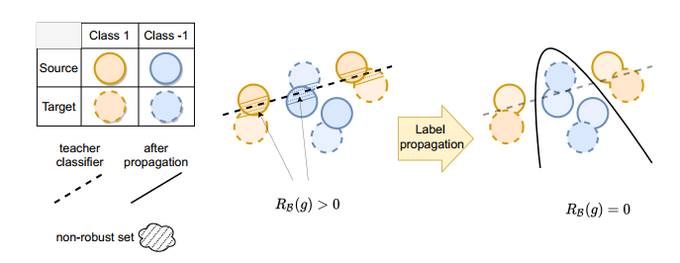
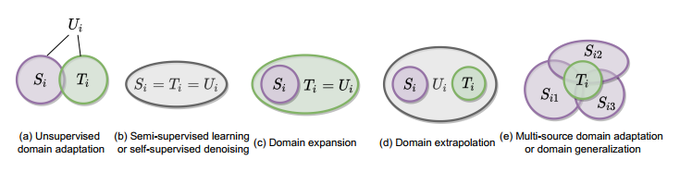
I strongly believe distribution shift is one of the major challenges in deploying ml systems. We take a step towards addressing subpopulation shift via a label propagation framework.

Subpopulation shift is a ubiquitous component of natural distribution shift. We propose a general theoretical framework of learning under subpopulation shift based on label propagation. And our insights can help to improve domain adaptation algorithms.

1
16
111
2
9
92
Oh god

NeurIPS 2024 will have a track for papers from high schoolers.

79
92
595
3
6
92
I have never seen a monograph (or book) with such an incomplete list of citations.

I'm delighted to share publicly "The Principles of Deep Learning Theory," co-written with
@ShoYaida
, and based on work also with
@BorisHanin
. It will appear on the
@arxiv
on Sunday and will be published by
@CambridgeUP
early next year:
1/
15
296
1K
5
5
83
@chrmanning
@strwbilly
Where does the Markov chain come from? It depends on all previous not just the immediate
4
0
82
I'm in good company!

0
3
80

1
9
57
TLDR: By moving further from initialization, you can provably learn a broad class of functions (low-rank polynomials) with less samples than any kernel method. Low-rank polynomials include networks with polynomial activation of bounded degree and analytic activation (approx).

🚨 New blog post on Deep Learning Theory Beyond NTKs:
Salesforce research blog:
offconvex:
An exposition of "escaping the NTK ball with stronger learning guarantees".
Joint w/
@jasondeanlee
@MinshuoC
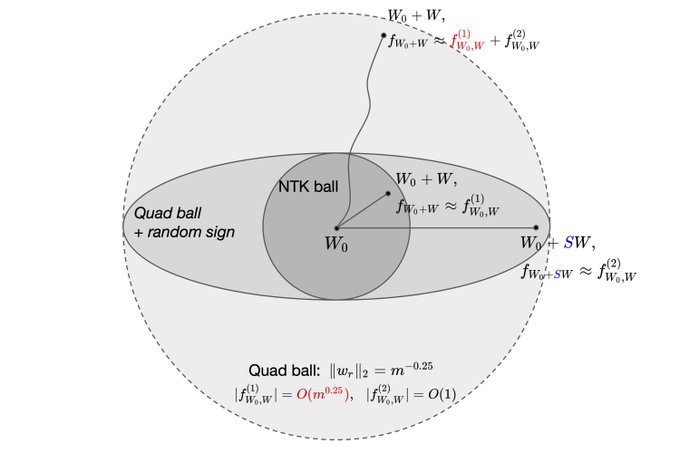
3
39
180
0
6
54
Now I know who took my slots!

Wow, all of our 6 submissions to ICML and COLT got accepted this year! Congrats to all my collaborators.
12
7
438
0
0
52
Downloaded the source of this one and tried to compile in Larger font to make it readable. The latex is completely obfuscated to make it hard to edit. What's the point of this? Make it inaccessible to low vision readers? Makes it near impossible to reformat to be read


4
4
52
What is the analog of ERM for offline RL? We propose primal dual regularized offline rl (PRO-RL), which has many of the properties that makes ERM so successful.
3
2
50
What to do when someone has their students ask your students to cite their irrelevant paper (and you know about this paper)?
19
1
47
Check out our work on sanity-checking pruning at initialization methods. It turns out these methods do not outperform data-independent pruning. Similar conclusions reached by
@jefrankle
@KDziugaite
@roydanroy
@mcarbin
Do existing pruning methods really exploit the info from data? Are the architectures of the pruned networks really matter for the performance? We propose sanity checks on pruning methods and find a great part of existing methods does not rely on these!
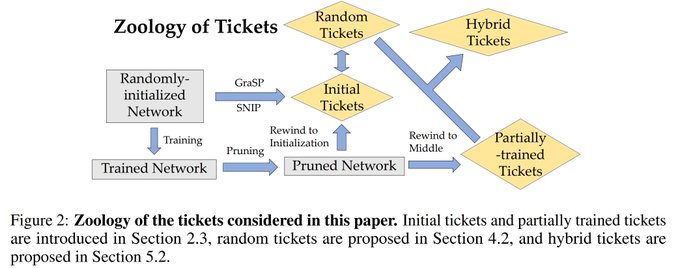

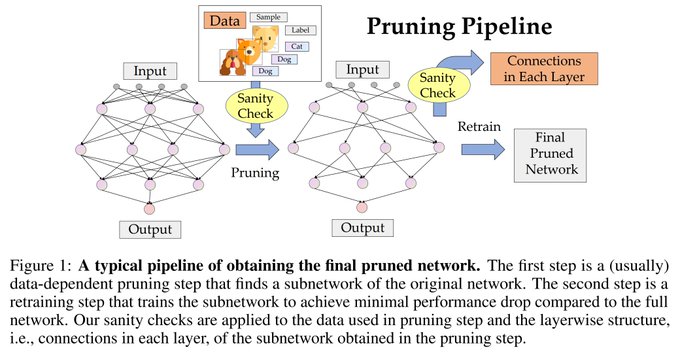
2
7
41
0
5
49

Learning Transformer Programs ( from Princeton NLP) -
This paper is neat. Modify transformer arch to be disentangled (concat not add, -residuals), anneal training to be discrete, convert to python code. Doesn't really scale yet but very fun.
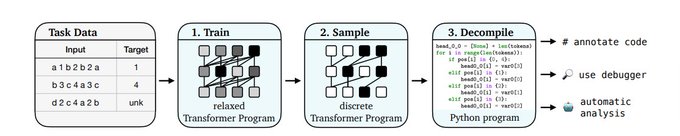
2
59
344
1
4
49
Surprisingly, the middle group of eigenvalues cause overfitting and simply not using them (use only the big ones and the smallest ones) allows you to move further and generalize better!
What happens “after NTK” in wide neural nets, and how does it improve over the NTK?
Excited to announce a new paper with
@yubai01
and
@jasondeanlee
!
A thread on the main takeaways below: (1/9)

1
12
73
2
11
47
Actual tweet: We show an optimization-based depth separation: the indicator of the L2 ball cannot be learned by any two-layer net (one layer of nonlinearity) of polynomial-size,
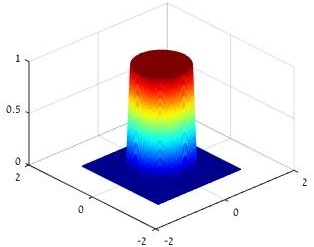
2
2
46
As an outsider to this parameter-free or no line search world, it seems there is just 3 settings: online, stochastic , and deterministic. . The overheads seem to be online (log) , stochastic (loglog), and deterministic (constant).

Interesting new parameter free accelerated gradient method from George Lan's group appeared on arXiv tonight.



2
16
120
2
4
44
I took Sina Farsiu's image processing class in my last year of undergrad. This was one of the classes that convinced me to work on 'math of data' stuff and eventually led me to ML, stats, and opt. I remember Sina covering many of these super res papers

The next couple of years, Sina Farsiu’s superb PhD thesis brought advancements in robustness, treatment of color/raw images, and video. 10 years too soon to be practical, it laid the foundation for what later became Super Res zoom in the Pixel phones. Sina is a Prof. at Duke now
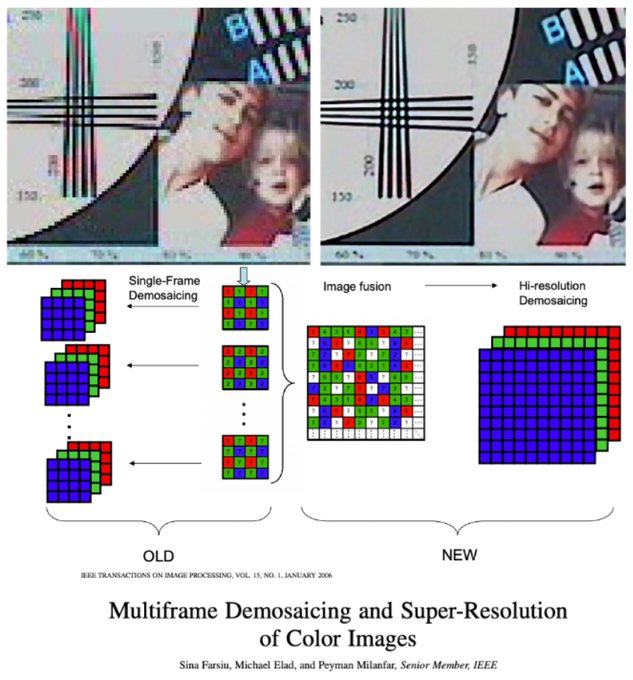
1
2
63
1
1
43
Definitely remember reading this as a grad student

"The Ph.D. Grind" is the book that every doctoral student must read. It is a memoir by Philip J. Guo, a university professor, but back then a graduate student navigating a Ph.D. program in computer science. This thread summarizes the main takeaways for you👇 [1/23]

7
97
525
1
6
40
To all phd students that need accommodations about to accept a faculty. Remember to meet with the accommodation staff at your future employer to make sure you get the help you need (visual, hearing, sign language interpreter etc)! Do this before you sign the offer
1
5
38

Wow! Luckily I spent my whole phd on linear regression. I must have already solved AGI then

The first pillar of artificial general intelligence is, of course, linear regression. This is why most Stats courses are centered around it and why many of our celebrated theoreticians spend their careers developing elaborations on it. You likely don't truly understand it. Sad.
8
3
131
3
0
39
@roydanroy
All of these show GD does something (with much better statistical error) than NTK (usually can lower bound ntk)
4
4
36
How do the new icml reviews work? We don't get to see the actual score, only the text?
8
1
35
Exciting new work from our groups at Princeton!

Introducing MeZO - a memory-efficient zeroth-order optimizer that can fine-tune large language models with forward passes while remaining performant. MeZO can train a 30B model on 1x 80GB A100 GPU.
Paper:
Code:
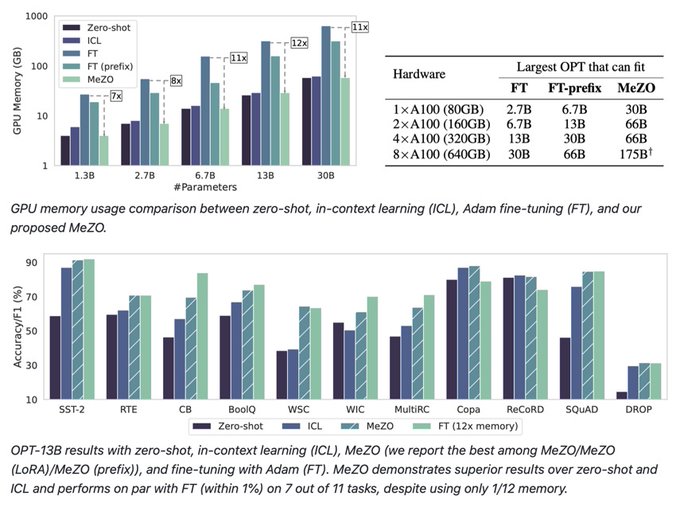
9
93
456
0
0
34
The situation is even worse for those with invisible disabilities that are stigmatized, and confronted with skepticism. Academia is an incredibly uninclusive environment for the disabled, where ableism is apparent in every metric (implicit and explicit).
1
1
34
10, duh
On a scale of 10, how important do you think is the knowledge of probability and statistics when it comes to learning/understanding machine learning and data science?
37
8
106
2
0
32
@roydanroy
Even more annoyed by super famous scholars at such institutions that repackage existing work and publish in top journals of a different field.
2
1
32
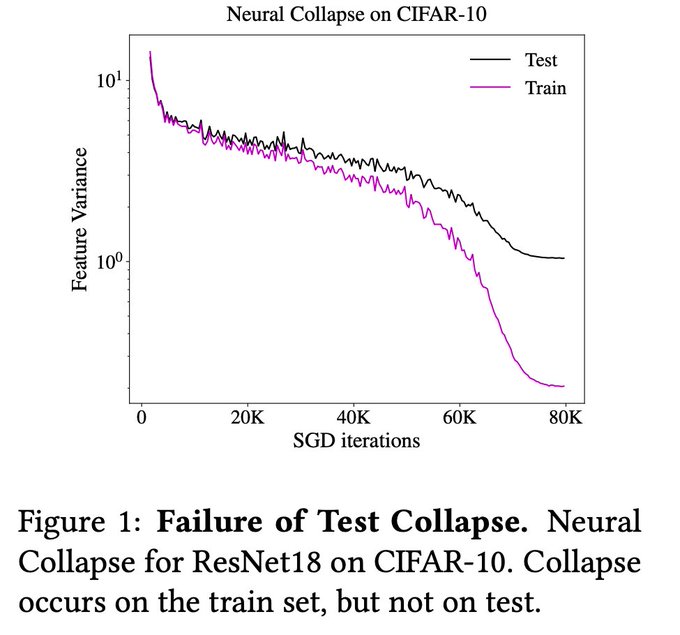
I completely agree with the sentiment in this paper. Neural collapse is a consequence of the implicit reg of the optimizer. Eg under directional convergence, it is implied by implicit regularization work (, matus or kaifengs work)
New paper, short and sweet:
"Limitations of Neural Collapse for Understanding Generalization in Deep Learning"
with Like Hui, Misha Belkin.
Neural collapse is often claimed to be, in some way, deeply relevant for generalization. But is it? 1/3
5
48
239
3
3
28
Why is neural collapse interesting (or why are there so many papers) ? Given all the work on implicit bias you should expect the representation collapse to roughly C dimensional asymptotically, where C =num classes.
2
2
28
When can we compete with the best policy? We show that PROVABLE can compete with the best m-step memory policy in a wide variety of function approximation settings. Joint work with Masatoshi Uehara,
@ayush_sekhari
,
@nathankallus
, and Wen Sun

1
4
26
What is the implicit regularization of label noise SGD? Turns out label noise SGD essentially minimizes a flatness minimizer subject to the training loss is near 0!

Conventional wisdom: SGD prefers flat local minima. How *rigorously* can we characterize this? We prove that label-noise SGD converges to stationary points of training loss + a flatness regularizer, by coupling it with GD on the regularized loss. . 0/6

2
25
176
1
4
26
Check out Tianle's work, one of our incoming students at Princeton.
Late updates: Three papers will appear at
#ICML2021
!
Theory of Label Propagation for Domain Adaptation
GraphNorm for Accelerating GNN Training
L_inf-dist Net for Certifying L_inf robustness
1
7
107
2
0
25
This paper is a very informative read!

LLM360: Towards Fully Transparent Open-Source LLMs
paper page:
@AurickQ
,
@willieneis
,
@HongyiWang10
,
@BowenTan8
,
@ZhitingHu
,
@preslav_nakov
,
@mbzuai
,
@PetuumInc
,
@Meta
@MistralAI
@huggingface
1
31
152
0
3
25
I knew I would be vindicated for studying quadratic activation nets! Polynomial activation nets are competitive!

Proud for our new
#ICLR2024
paper attempting to answer: Are activation functions required for all deep networks?
Can networks perform well on ImageNet recognition without activation functions, max pooling, etc? 🧐
Arxiv:
🧵1/n
10
49
338
1
0
24
IMO, best place in the world for dl theory and ml theory

🌶️Deep Learning Theory Postdoc
@Princeton
ORFE🌶️
🔥Let's do something groundbreaking together
App due 12/1
@danintheory
@shaunmmaguire
@ethansdyer
@guygr
@KrzakalaF
@zdeborova
@jasondeanlee
@prfsanjeevarora
@CPehlevan
@bneyshabur
@boazbaraktcs
#NSF
0
6
29
0
1
23
@DimitrisPapail
More broadly I think architecture design from a theory standpoint is completely open. Roughly speaking all architectures are universal and can approximate any signal. However (arch1, default_optimizer) >>(arch2, default_optimizer). Thus we have to study (Arch, optimizer) pairs!
4
0
22
Some new work on finetuning for improving representation learning!

Preprint:
Huge thanks to my co-authors,
@Qi_Lei_
and
@jasondeanlee
! Really appreciate their guidance during my first foray into theory-land 😀
4/4
0
2
11
0
1
21
@TheGregYang
Why is it surprising? If you use linear regression as the downstream classifier, it only uses first two moments.
2
1
21
Love this paper!

(1/7) Couldn’t make it to Kigali but would like to share our ICLR oral: Transformers solve multi-step algorithmic reasoning with surprisingly few layers – why? We study this via automata and show that o(T)-layer Transformers (aka. shortcuts) can represent T steps of reasoning.
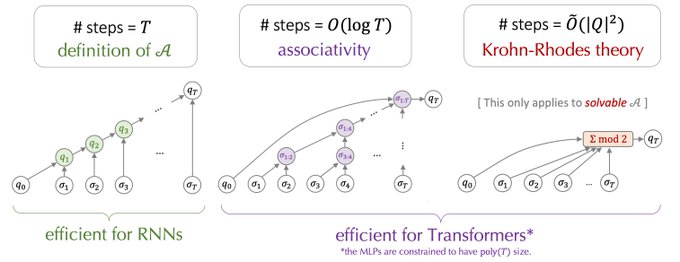
4
82
380
1
5
19
@roydanroy
This reminds me of when I moved from US to Taiwan in 2nd grade. I got wiped out in math. They memorize multiplication tables to like 30 x 30.
1
0
21
Disabled academics have to meet a high burden of proof, and even then their accommodation requests are frequently denied by university administrators. I personally spent about 15 months back and forth with my medical team and university administrators, and even after they
2
0
20
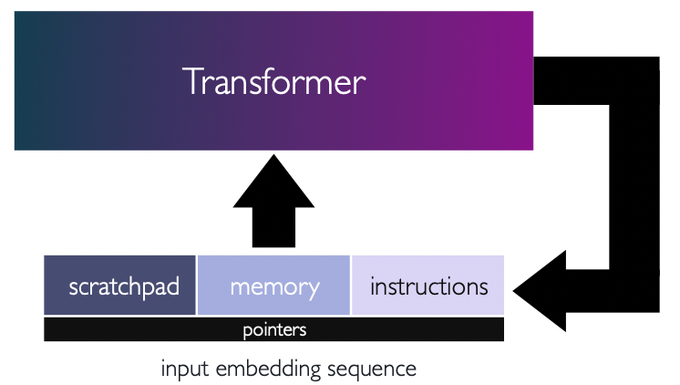
Transformers as computers and prompts are their punchcards!

Can transformers follow instructions? We explore this in:
"Looped Transformers as Programmable Computers"
led by Angeliki (
@AngelikiGiannou
) and Shashank (
@shashank_r12
) in collaboartion with the
@Kangwook_Lee
and
@jasondeanlee
Here is a 🧵
18
158
787
1
1
20
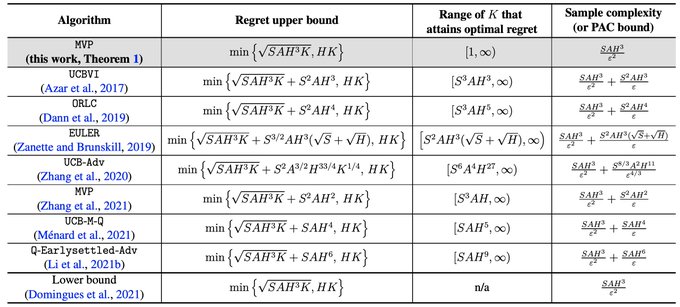
Technical tour de force by zihan

Excited to share our new paper on optimal sample complexity/regret guarantee for RL!
New techniques: statistically decouple value function from transition estimations.
Happy to chat more at
#ICML2023
arXiv:
with Zihan Zhang, Yuxin Chen,
@jasondeanlee
2
11
133
0
1
20
I agree.

My (potentially controversial) proposed policy on desk rejections for
#NeurIPS2020
: Allow papers to be desk rejected but only under the condition is that the ones making such a decision be required to disclose their names and be ready to publicly defend their decision.
4
0
64
0
0
19
Within 10 years unless they adapt the IMO

How long will it be before a computer can get a gold medal in the International Mathematical Olympiad? Now that there is a big prize at stake, maybe not as long as it would otherwise have been ...
18
37
260
3
0
20
Someone must have tried a recurrent Transformer? Does it just not train?
Prediction for the future of LLMs:
- GPT-X will be a *recurrent* Transformer, for X=4 or 5.
I can't see how TFs can become general purpose without simulating complex for-loops/GOTOs, without recurrence. Unless depth is linear or width becomes exponential in depth of recursion.
6
4
45
5
0
19
Zeyuan and yuanzhi have done some of the best work in this area.

An accessible presentation by
@ZeyuanAllenZhu
of his breakthrough discovery with Yuanzhi Li of the backward feature correction phenomenon (feature purification is also discussed in a second part). Interesting progress to explain the power of deep learning!
1
42
138
1
1
19
Why are abstracts in smaller font size than maintext? Seems it should be at least the same size. Always wondered this because I have terrible eyesight
1
0
20
Jamba juice!

Introducing Jamba, our groundbreaking SSM-Transformer open model!
As the first production-grade model based on Mamba architecture, Jamba achieves an unprecedented 3X throughput and fits 140K context on a single GPU.
🥂Meet Jamba
🔨Build on
@huggingface

37
258
1K
2
0
20
A necessary step is to understand first.

Start to see quite a few "theoretical" papers on analyzing diffusion models. Folks, a good theory is supposed to lead and project, not to always trail as hindsight...
2
6
99
0
1
19
yet gradient descent on a three-layer net (with two layers of nonlinearity) can learn it in polynomial-time and sample complexity. As opposed to previous depth separations, this shows an optimization-based separation.
1
0
18
The issue extend beyond the university and to the grant agencies, which makes it incredibly difficult for the disabled to travel with their needed accommodations. I wish I had the stamina and courage to fight for all the disabled in academia, but I have been just worn down.
1
0
18
Thank you to cra and nsf for making this possible

Very happy to announce that I've been selected as a 2020 CIFellow, and will work with
@jasondeanlee
as a postdoc at Princeton EE. Thank you
@CRAtweets
for the incredible opportunity.
17
0
92
0
0
19
By one of the leaders in data science about predictability, computability and stability!

My co-author
@rlbarter
and I are thrilled to announce the online release of our MIT Press book "Veridical Data Science: The Practice of Responsible Data Analysis and Decision Making" (), an essential source for producing trustworthy data-driven results.
7
66
199
1
1
19
Great opportunity to work with Song!

My group at Berkeley Stats and EECS has a postdoc opening in the theoretical (e.g., scaling laws, watermark) and empirical aspects (e.g., efficiency, safety, alignment) of LLMs or diffusion models. Send me an email with your CV if interested!
0
23
97
0
0
18
Coming to new Orleans tomorrow! Will be speaking at the Optml workshop
0
0
17
The situation for students is a lot better off than for employees. As a student, I had a much easier process with receiving the accommodations I needed.
0
0
16
@skoularidou
and
@AiDisability
have done their best to fight for us, but its an uphill battle and I honestly feel the fight for inclusivity of the disabled in academia looks bleak.
1
0
16
@thegautamkamath
I think we should have like 3 year paper awards, 7 year and the test of time
1
0
15
As the most minor example, I have completely given up on trying to read off the screen at talks. I just sit in the very front row and take a photo, postprocess on the phone, and view it that way.
1
1
15
accepted it was sufficient medical evidence, the university still did not provide the needed accommodations with reasons such as space issues/city regulations/university regulations on appearance of office buildings (how is this important???).
1
0
15
@maosbot
If you include fibro, me/cfs, crps/rsd, it is a huge proportion I would bet. And almost no studies on it or drug development or effective treatments
1
2
14
Nice blogpost on our work!
Understanding Few-Shot Multi-Task Representation Learning Theory
Bouniot, Quentin; Redko, Ievgen
24/24
0
8
20
0
1
15
Mango shaved ice!

Taiwan fruits are the best. They are one of the main reasons we love Taiwan and have decided to stay in Taiwan for the long term.
Check out our Taiwan fruit guide here:
Check out our Taiwan food guide here:

7
9
129
0
1
14
This could be easily fixed if it were streamed on zoom (easily use ocr or txt2audio/ image processing) to make it readable at no cost. However, many opposed because zoom reduces attendance.
1
0
14
I have recently noticed theory papers are more likely to have algorithm boxes + formal descriptions. Why is this? It seems even more important for empirical papers.
2
0
14
I could go on about the slew of accommodations I needed in my case (parking, flight&parking, appropriate office space, appropriate classrooms) and how the university agreed they were necessary, but due to various excuses I did not receive effective help (see above).
1
0
14