
Arvind Neelakantan
@arvind_io
Followers
6K
Following
6K
Media
22
Statuses
105
Research Scientist, @GoogleDeepMind Past: @AIatMeta , @OpenAI, @Google Brain PhD @UMassAmherst
Joined January 2012
thrilled to be back @Google in the @GoogleDeepMind team! The technical breadth and expertise across the whole stack (hardware->infra->deep learning->products) is truly mind-blowing. Great to see a lot of familiar faces and meet new friends. Look forward to learning a lot!.
34
30
1K
We explore a simple approach to task-oriented dialog. A single neural network consumes conversation history and external knowledge as input and generates the next turn text response along with the action (when necessary) as output. Paper: 1/4

3
57
229
We develop a non-autoregressive machine translation model whose accuracy almost matches a strong greedy autoregressive baseline Transformer, while being 3.3 times faster at inference. Joint work with @ashVaswani @nikiparmar09 Aurko Roy
1
50
204
A thread on how we evaluate our embedding models in OpenAI’s API. We achieve state-of-the-art results in linear probe classification, text search and code search. It’s not fine-tuned, so it works great in the real world — and our customers love it. 1/7.
6
29
157
Zero-shot results of OpenAI API’s embeddings on the FIQA search dataset. Evaluation script: We zero-shot evaluated on 14 text search datasets, our embeddings outperform keyword search and previous dense embedding methods on 11 of them!

In text search tasks, we obtain best zero-shot results in msmarco, triviaQA, and NQ and also the best transfer results on the BEIR benchmark. 5/7

0
15
68
look forward to working with @manohar_paluri, @Ahmad_Al_Dahle, @edunov and many others in the excellent @AIatMeta team! 2/2.
4
0
54
Thanks for a balanced take! Couple of comments that are also added to the video description now: 1/4.

🔥New Video🔥.OpenAI now offers embeddings for text similarity and search, but are they holding up? We look at the release, the paper, the criticism, and most important: the price! Are the embeddings worth it? Watch here to find out:.

4
9
53
Small models specifically fine-tuned on a dataset can do well on a narrow benchmark, but they far underperform in real-world settings, as many of our customers are discovering. This study from @FineTuneLearn shows our API performance. 7/7

2
14
48
OpenAI embeddings work on a very broad set of use cases. Here, Viable gets a 7.7% absolute improvement in clustering quality using OpenAI embeddings when compared to previous methods!.

We tested different embedding models and show the data behind why GPT-3 was the clear winner for our clustering needs.
0
3
43
The cost to run this experiment with text-search-ada, embedding both documents and queries, is ~$80. text-search-ada achieves a 62% relative improvement over keyword search here!.
Zero-shot results of OpenAI API’s embeddings on the FIQA search dataset. Evaluation script: We zero-shot evaluated on 14 text search datasets, our embeddings outperform keyword search and previous dense embedding methods on 11 of them!
1
7
39
We describe a simple technique to parallelize Scheduled Sampling across time that allows us to apply Scheduled Sampling for problems that involve generating very long sequences. We get better sample quality and train almost as fast as teacher-forcing.

2
5
35
@ylecun For the same reason a kind of unsupervised learning that people were always doing was branded as self-supervised learning 😉.
0
1
30
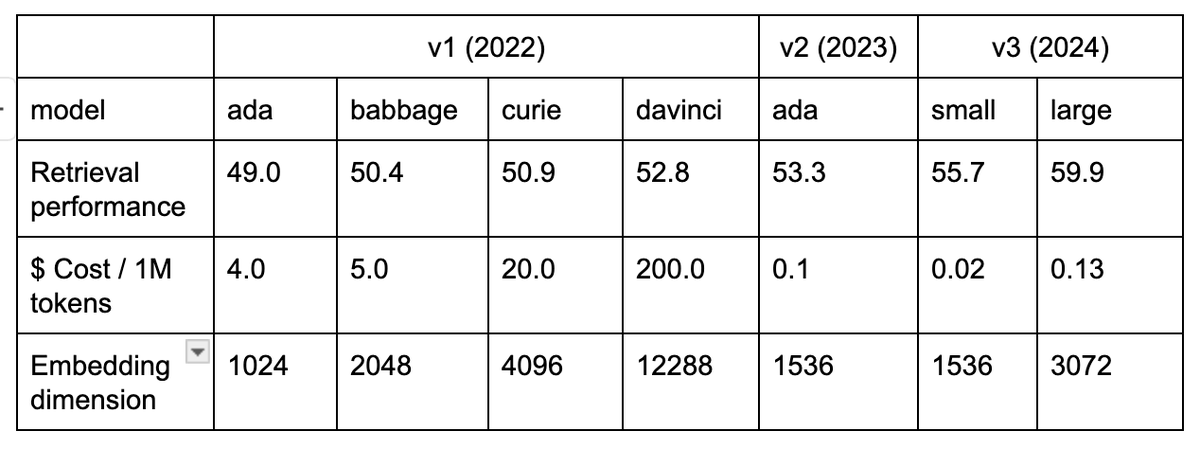
@OpenAI embeddings achieve better retrieval performance and are also lot cheaper!.Results taken from:


4
3
23
My team and I trained the model. We look at 33 datasets across four different categories: linear probe classification, sentence similarity, text search, and code search. All these results and figures were in our paper, released this week. 2/7.
2
0
23
In text search tasks, we obtain best zero-shot results in msmarco, triviaQA, and NQ and also the best transfer results on the BEIR benchmark. 5/7
3
0
21
OpenAI Embeddings helps you go beyond keyword search!




The code is actually extremely simple for a cool app like this - open sourced here:
0
0
19
TPU -> XLA -> JAX -> Transformer, MoE, Chinchilla, AlphaGo, . -> Gemini, Veo, . -> Search, YouTube, Waymo, . -> Chrome, Android, . 🤯🤯🤯.
0
0
19
We also achieve new state-of-the-art results on code search. 6/7

2
0
16
Check out our spotlight talk and poster describing the Neural Assistant work in the ConvAI workshop tomorrow @NeurIPSConf #neurips19 .

We explore a simple approach to task-oriented dialog. A single neural network consumes conversation history and external knowledge as input and generates the next turn text response along with the action (when necessary) as output. Paper: 1/4
0
1
14
In sentence similarity tasks, we perform worse than previous work. This was explained in our paper as well. 4/7

2
0
12
0
2
8
in case people are counting, I forgot to share the results for text search from 3 more datasets (apart from the 11 text search results already reported) 🙂

My team and I trained the model. We look at 33 datasets across four different categories: linear probe classification, sentence similarity, text search, and code search. All these results and figures were in our paper, released this week. 2/7.
0
0
7

We get good results on real-world question answering with neural semantic parsing/program induction. Code is here:

Learning a Natural Language Interface with Neural Programmer. (arXiv:1611.08945v1 [cs.CL])
0
2
6
In our experiments we find that: 1) our model was able to incorporate external knowledge and generate factual text response with weak supervision signal. 2) our model can incorporate medium-size knowledge bases with only 8K training examples over multiple verticals.

1
1
4
1
0
5
@jobergum our method actually zero-shot transfers better than bm25 to 11 search tasks on average as shown in the entire table. even our smallest models are better than bm25. while it is not the only way to exploit training data with bm25, we perform better than one such method docT5 query

1
0
4
@quocleix Agree! But, I think once widely used brown clusters (e.g., : should also be given credit. They use language model pre-training objective on unlabeled data and transfer the word clusters to supervised tasks. They are not "contextual" though.
0
0
4
1
0
3
We leave out 6 not 7 BEIR datasets.Results on MSMARCO, NQ, TriviaQA are in a separate table (Table 5 in the paper).NQ is part of BEIR too and we didn't want to repeat it.The 6 datasets we leave out are not readily available and it is common to leave them out in prior work too.3/4.
1
0
3
The code for FIQA experiments to reproduce the results in the paper using the API: . There's no discrepancy AFAIK. 2/4.
Zero-shot results of OpenAI API’s embeddings on the FIQA search dataset. Evaluation script: We zero-shot evaluated on 14 text search datasets, our embeddings outperform keyword search and previous dense embedding methods on 11 of them!
1
0
4
For example, see SPLADE v2 ( also evaluates on the same 12 BEIR datasets. Discussion from their paper: 4/4

1
0
4
@emnlp2019 Data: Work done with many awesome colleagues at Google Assistant team and.@GoogleAI along with student researcher Chinnadhurai Shankar.
0
0
3
@melvinjohnsonp @Google @GoogleDeepMind thank you, Melvin! look forward to working with you as well :).
0
0
2
and also impressive performance on text classification and search!


1
0
3
@earnmyturns @yoavgo Also, Inductive bias of Transformer makes it easier to skip words and learn long-range dependencies compared to RNNs . This paper has some supporting experiments.
0
0
3
we see massive improvement in code search using our models!

2
0
2
0
0
1
@julianharris The conversation is annotated with accept/reject. At test time we would want the third-party business to implement a boolean function that returns whether transaction can be completed.Neural Assistant will learn to work with the response as it has been annotated at training time.
1
0
1
0
0
0
0
0
1