
Quoc Le
@quocleix
Followers
54K
Following
806
Media
70
Statuses
451
New open-source language model from Google AI: Flan-T5 🍮. Flan-T5 is instruction-finetuned on 1,800+ language tasks, leading to dramatically improved prompting and multi-step reasoning abilities. Public models: Paper:

37
474
2K
EfficientNets: a family of more efficient & accurate image classification models. Found by architecture search and scaled up by one weird trick. Link: . Github: . Blog:

24
658
2K
Fun AutoML-Zero experiments: Evolutionary search discovers fundamental ML algorithms from scratch, e.g., small neural nets with backprop. Can evolution be the “Master Algorithm”? ;) . Paper: Code:
20
536
2K
XLNet: a new pretraining method for NLP that significantly improves upon BERT on 20 tasks (e.g., SQuAD, GLUE, RACE). arxiv: github (code + pretrained models): with Zhilin Yang, @ZihangDai, Yiming Yang, Jaime Carbonell, @rsalakhu
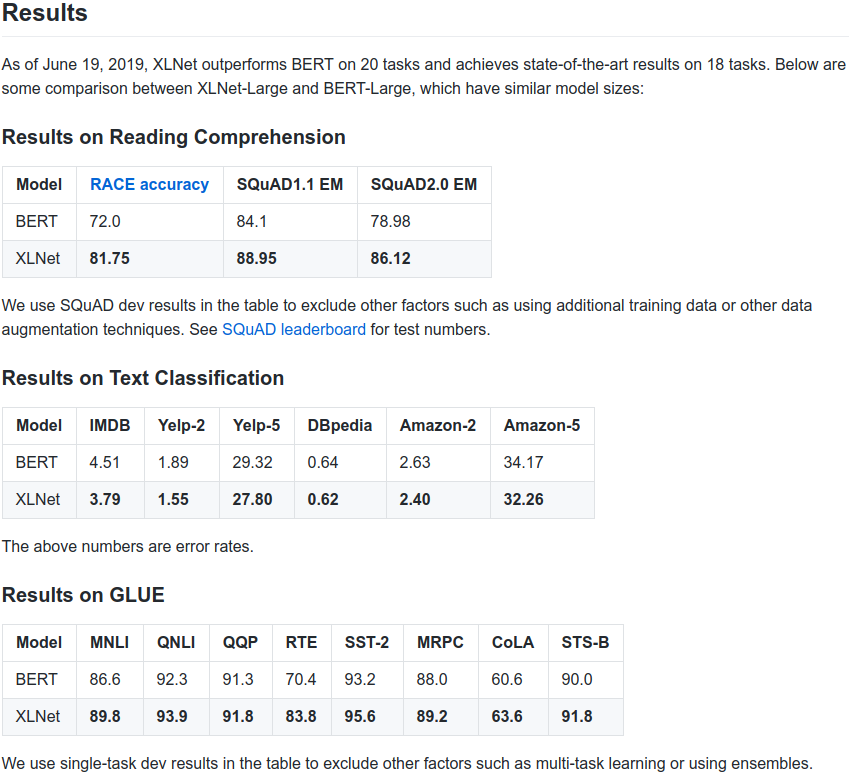
19
680
2K
New paper: Towards a Human-like Open-Domain Chatbot. Key takeaways:. 1. "Perplexity is all a chatbot needs" ;).2. We're getting closer to a high-quality chatbot that can chat about anything. Paper: Blog:
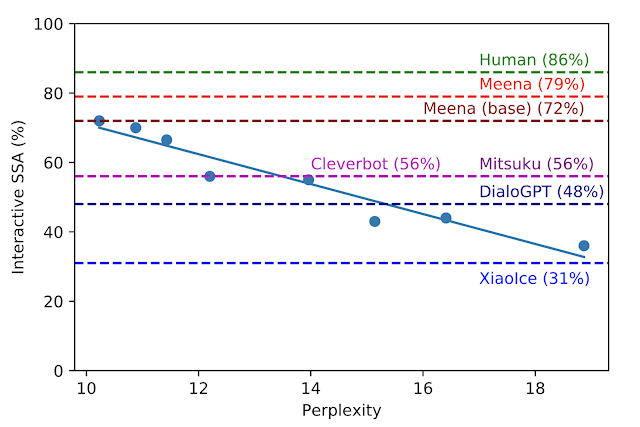
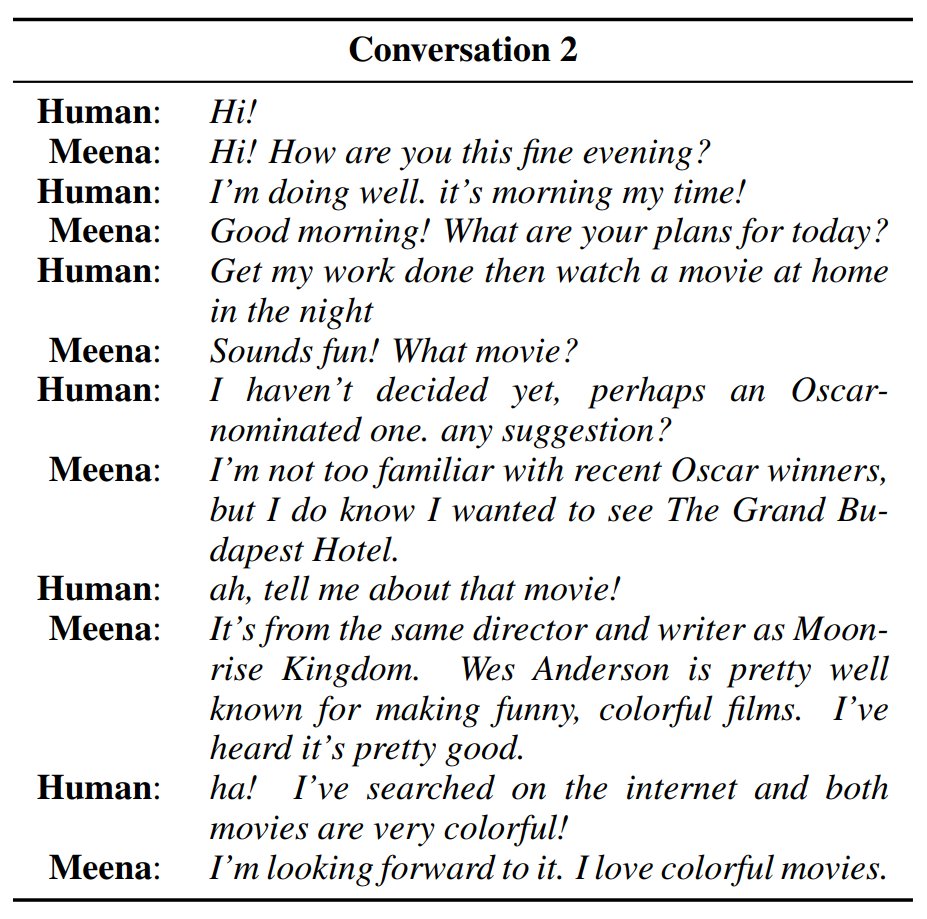
27
561
2K
Want to improve accuracy and robustness of your model? Use unlabeled data!. Our new work uses self-training on unlabeled data to achieve 87.4% top-1 on ImageNet, 1% better than SOTA. Huge gains are seen on harder benchmarks (ImageNet-A, C and P). Link:
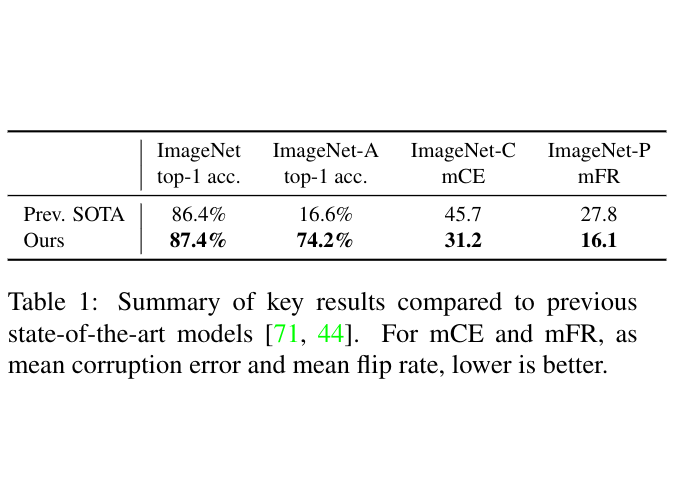
20
418
1K
Some nice improvement on ImageNet: 90% top-1 accuracy has been achieved :-). This result is possible by using Meta Pseudo Labels, a semi-supervised learning method, to train EfficientNet-L2. More details here:

16
300
1K
A surprising result: We found that smooth activation functions are better than ReLU for adversarial training and can lead to substantial improvements in adversarial robustness.

20
248
1K
Happy to announce that we've released a number of models trained with Noisy Student (a semi-supervised learning method). The best model achieves 88.4% top-1 accuracy on ImageNet (SOTA). Enjoy finetuning!. Link: Paper:

11
276
1K
Nice blog post titled "The Quiet Semi-Supervised Revolution" by Vincent Vanhoucke. It discusses two related works by the Google Brain team: Unsupervised Data Augmentation and MixMatch.
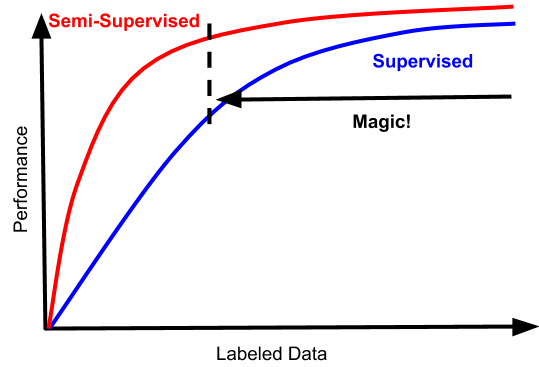
4
288
953
We researchers love pre-training. Our new paper shows that pre-training is unhelpful when we have a lot of labeled data. In contrast, self-training works well even when we have a lot of labeled data. SOTA on PASCAL segmentation & COCO detection. Link:

6
225
953
We used architecture search to find a better architecture for object detection. Results: Better and faster architectures than Mask-RCNN, FPN and SSD architectures. Architecture also looks unexpected and pretty funky. Link:
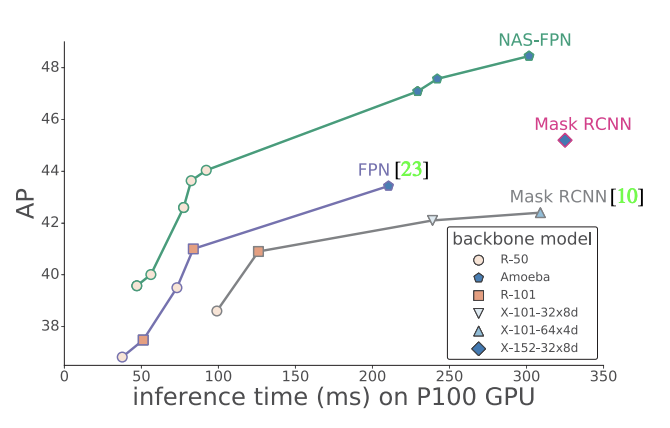
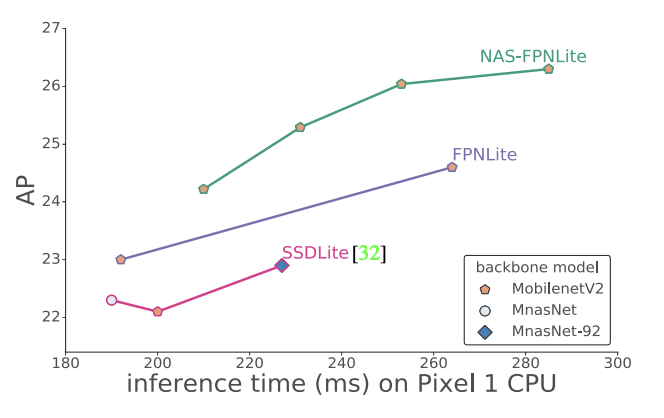
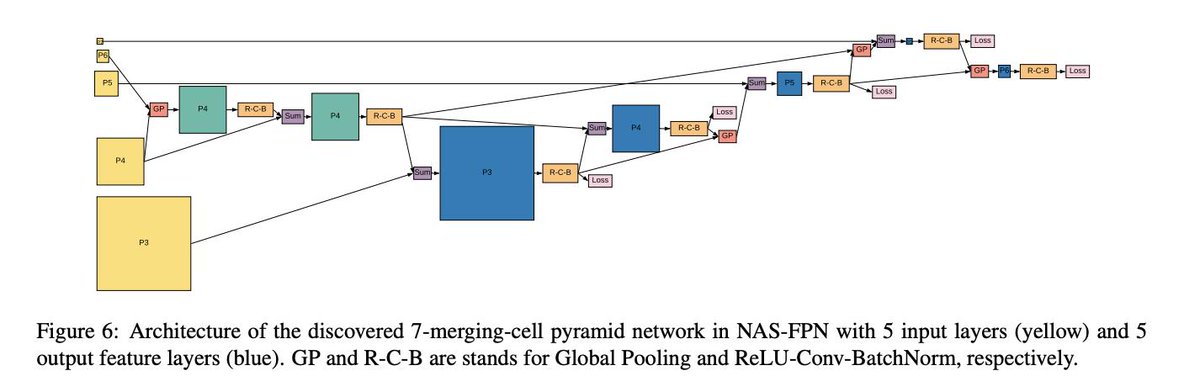
9
228
809
EfficientDet: a new family of efficient object detectors. It is based on EfficientNet, and many times more efficient than state of art models. Link: Code: coming soon

8
206
761
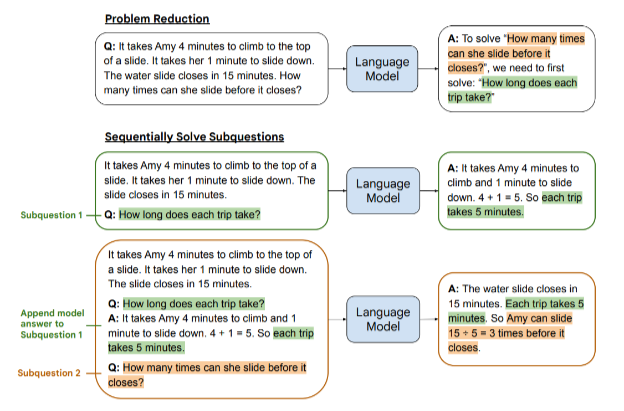
We can teach a language model to solve complex problems by showing it how to break down a problem into subproblems, and solve them sequentially. This “least-to-most prompting” method solves 99.7% of SCAN benchmark while other prompting methods solve ~16%.
14
140
739
New York Times article on AlphaGeometry. Geometry was my favorite subject in high school because solving them requires many step of reasoning and planning. Geometry problems however have been difficult for AI to solve. Our Nature paper shows my team’s progress in Geometry.
10
80
536
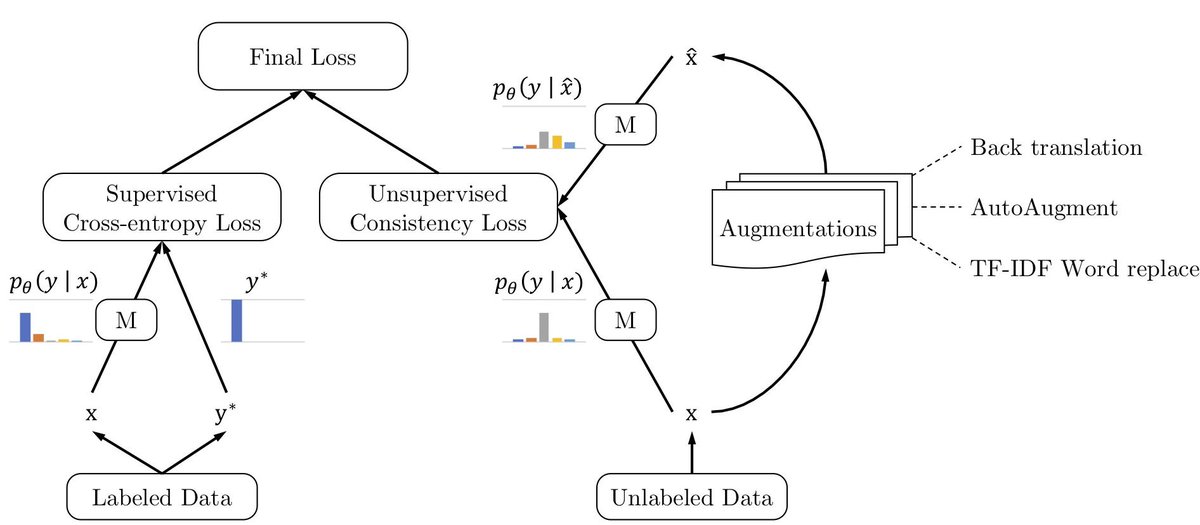
Data augmentation is often associated with supervised learning. We find *unsupervised* data augmentation works better. It combines well with transfer learning (e.g. BERT) and improves everything when datasets have a small number of labeled examples. Link:

Introducing UDA, our new work on "Unsupervised data augmentation" for semi-supervised learning (SSL) with Qizhe Xie, Zihang Dai, Eduard Hovy, & @quocleix. SOTA results on IMDB (with just 20 labeled examples!), SSL Cifar10 & SVHN (30% error reduction)!
3
153
605
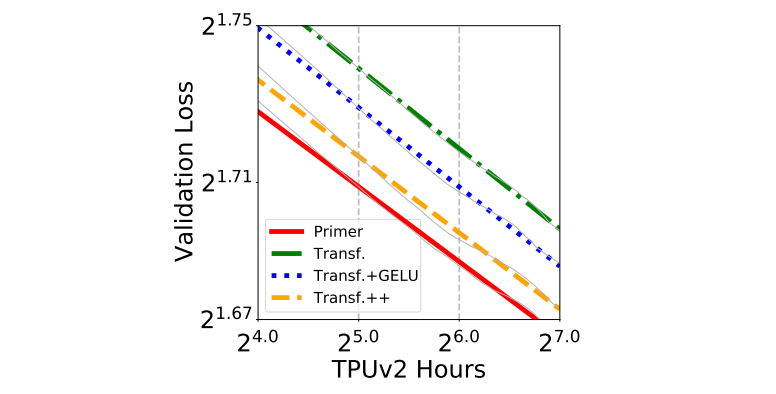
Primer: Searching for Efficient Transformers for Language Modeling. We use evolution to design a new Transformer variant, called Primer. Primer has a better scaling law, and is 3X to 4X faster for training than Transformer for language modeling.
4
128
603
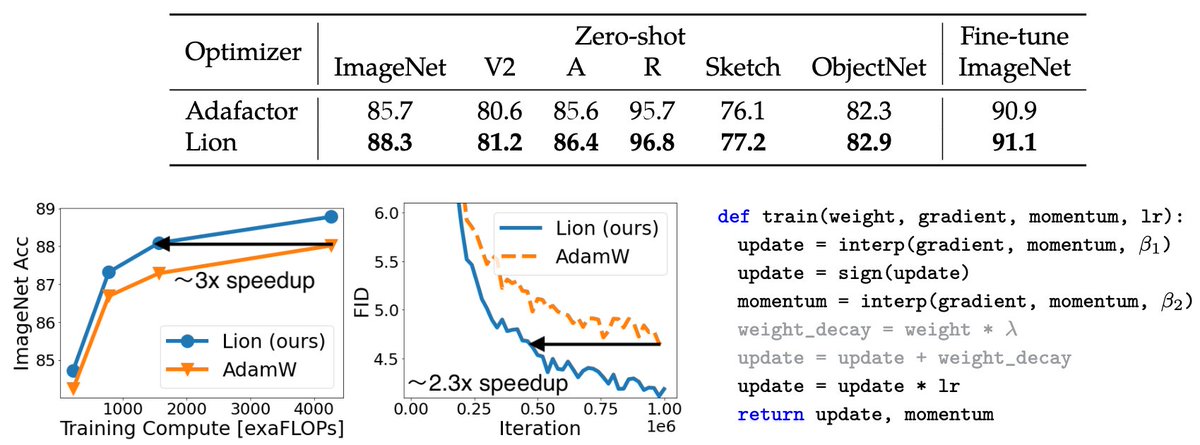
We discovered an optimizer, "Lion", with symbolic program search. In our experiments, it works well for some cases. Please check out for results and limitations.
13
79
542
AdvProp: One weird trick to use adversarial examples to reduce overfitting. Key idea is to use two BatchNorms, one for normal examples and another one for adversarial examples. Significant gains on ImageNet and other test sets.

Can adversarial examples improve image recognition? Check out our recent work: AdvProp, achieving ImageNet top-1 accuracy 85.5% (no extra data) with adversarial examples!. Arxiv: .Checkpoints:

2
146
529
Pretty amazing progress on speech recognition thanks to pre-training and self-training with unlabeled data. Key ingredients: Large conformer architecture + wave2vec2.0 pretraining + Noisy Student Training. Link:
4
90
514
We used architecture search to improve Transformer architecture. Key is to use evolution and seed initial population with Transformer itself. The found architecture, Evolved Transformer, is better and more efficient, especially for small size models. Link:


5
107
494
Amazing progress in reasoning! 🚀 Gemini 2.5 Pro Deep Think hitting 49.4% on USAMO – a feat I'd have considered impossible just a couple of years ago – & Gemini 2.5 Flash achieving 1424 Elo are huge leaps. So proud our team's research ideas contributed to this moment!.
26
40
545
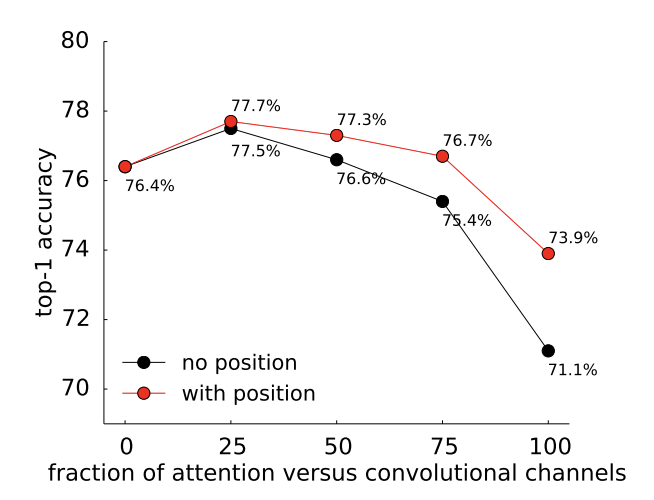
Exciting new work on replacing convolutions with self-attention for vision. Our paper shows that full attention is good, but loses a few percents in accuracy. And a middle ground that combines convolutions and self-attention is better. Link:
5
102
454
We opensourced AutoAugment strategy for object detection. This strategy significantly improves detection models in our benchmarks. Please try it on your problems. Code: Paper: More details & results 👇.

Data augmentation is even more crucial for detection. We present AutoAugment for object detection, achieving SOTA on COCO validation set (50.7 mAP). Policy transfers to different models & datasets. Paper: Code: details in thread.
4
144
454
Can we speed up language model training with a better data mixture?. Our DoReMi🎶 algorithm optimizes the data mixture, speeding up 8B model training by 2.6x on The Pile. Crucially, DoReMi🎶 just trains a small model (30x smaller) to tune the mixture.

6
95
424
RandAugment was one of the secret sources behind Noisy Student that I tweeted last week. Code for RandAugment is now opensourced.

*New paper* RandAugment: a new data augmentation. Better & simpler than AutoAugment. Main idea is to select transformations at random, and tune their magnitude. It achieves 85.0% top-1 on ImageNet. Paper: Code:

3
77
412
New paper: Meta Pseudo Labels. Self-training has a pre-trained teacher to generate pseudo labels to train a student. Here we use the student’s performance to meta-train the teacher to generate better pseudo labels. Works well on ImageNet 10%. Link:

6
122
408
Our work on transformer-xl which uses smart caching to improve the learning of long-term dependency in transformer. Key results: state-of-art on five language modeling benchmarks, including ppl of 21.8 on LM1B and 0.99 on enwiki8. Link:

7
101
408
Last week we released the checkpoints for SOTA ImageNet models trained by NoisyStudent. Due to popular demand, we’ve also opensourced an implementation of NoisyStudent. The code uses SVHN for demonstration purposes. Link: Paper:

4
116
403
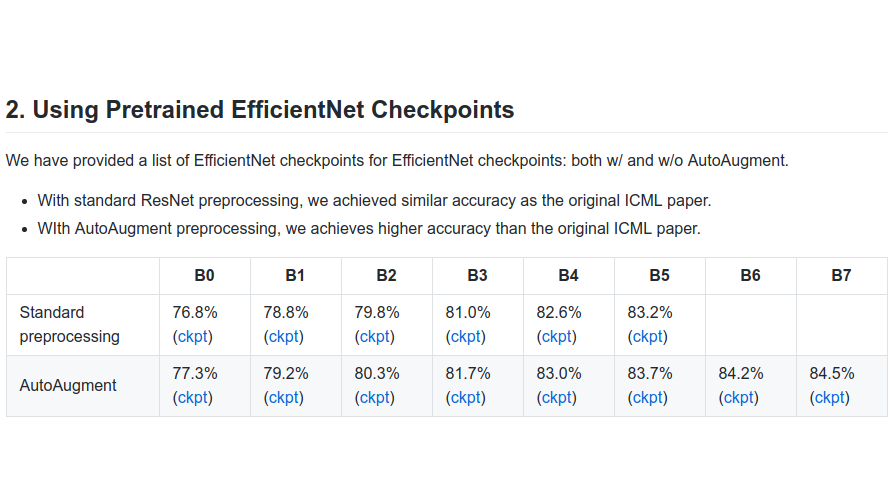
We released all checkpoints and training recipes of EfficientNets, including the best model EfficientNet-B7 that achieves accuracy of 84.5% top-1 on ImageNet. Link:
8
91
399
If you like the reasoning abilities in PaLM, also check out:."chain of thought prompting": Which adds “chain of thought” before answers in prompts for language models. This simple idea surprisingly enables LMs to do much better in many reasoning tasks.

5
71
387
Bigger models are better models so we built GPipe to enable training of large models. Results: 84.3% on ImageNet with AmoebaNet (big jump from other state-of-art models) and 99% on CIFAR-10 with transfer learning. Link:
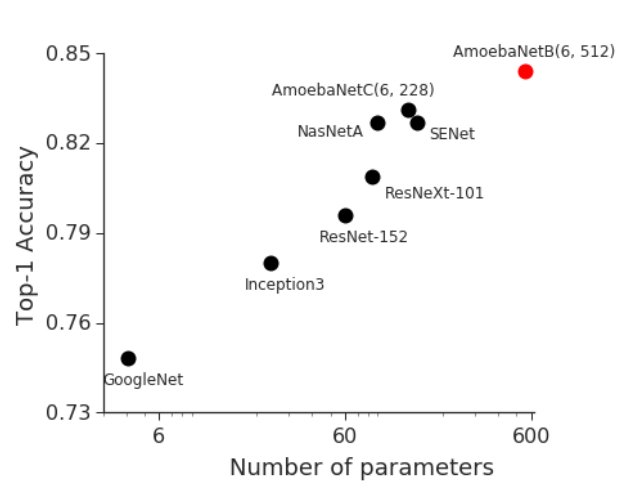
6
123
365
Introducing MobileNetV3: Based on MNASNet, found by architecture search, we applied additional methods to go even further (quantization friendly SqueezeExcite & Swish + NetAdapt + Compact layers). Result: 2x faster and more accurate than MobileNetV2. Link:
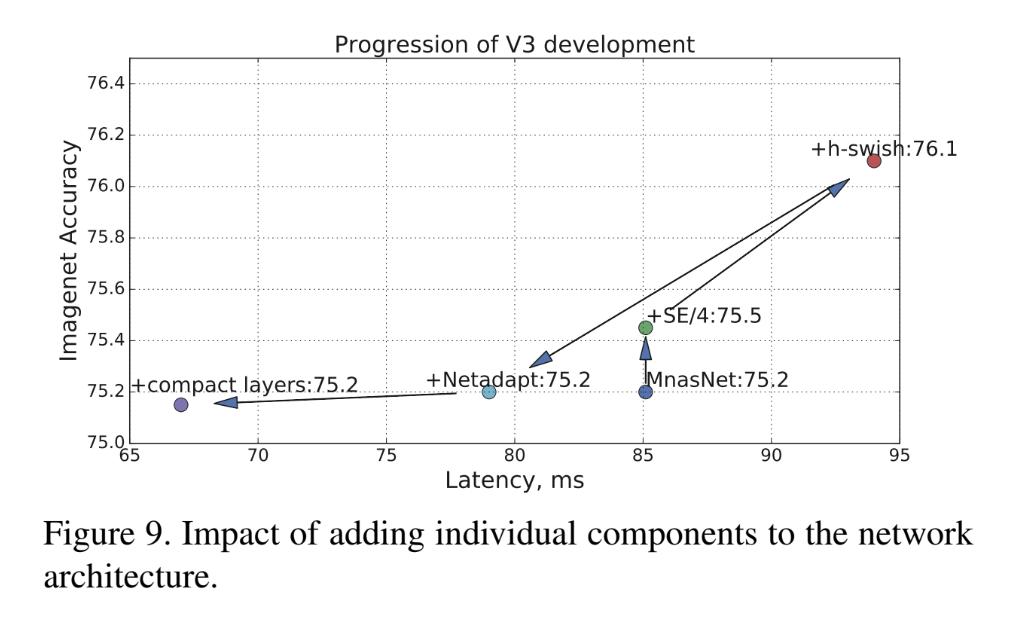
6
123
364
Congratulations @geoffreyhinton. The celebration today brought back many fond memories of learning from and collaborating with Geoff. His passion for research is another level and has made a great impact on the career of researchers around him, including myself. Every time he.

Attending @geoffreyhinton’s retirement celebration at Google with old friends. Thank you for everything you’ve done for AI! @JeffDean @quocleix

5
12
359
Bard (free) with Gemini Pro is now #2 on lmsys chatbot arena, surpassing GPT-4. I use it a lot for email and writing purposes and its responses are much better since the first launch. Give it a try at

🔥Breaking News from Arena. Google's Bard has just made a stunning leap, surpassing GPT-4 to the SECOND SPOT on the leaderboard! Big congrats to @Google for the remarkable achievement!. The race is heating up like never before! Super excited to see what's next for Bard + Gemini
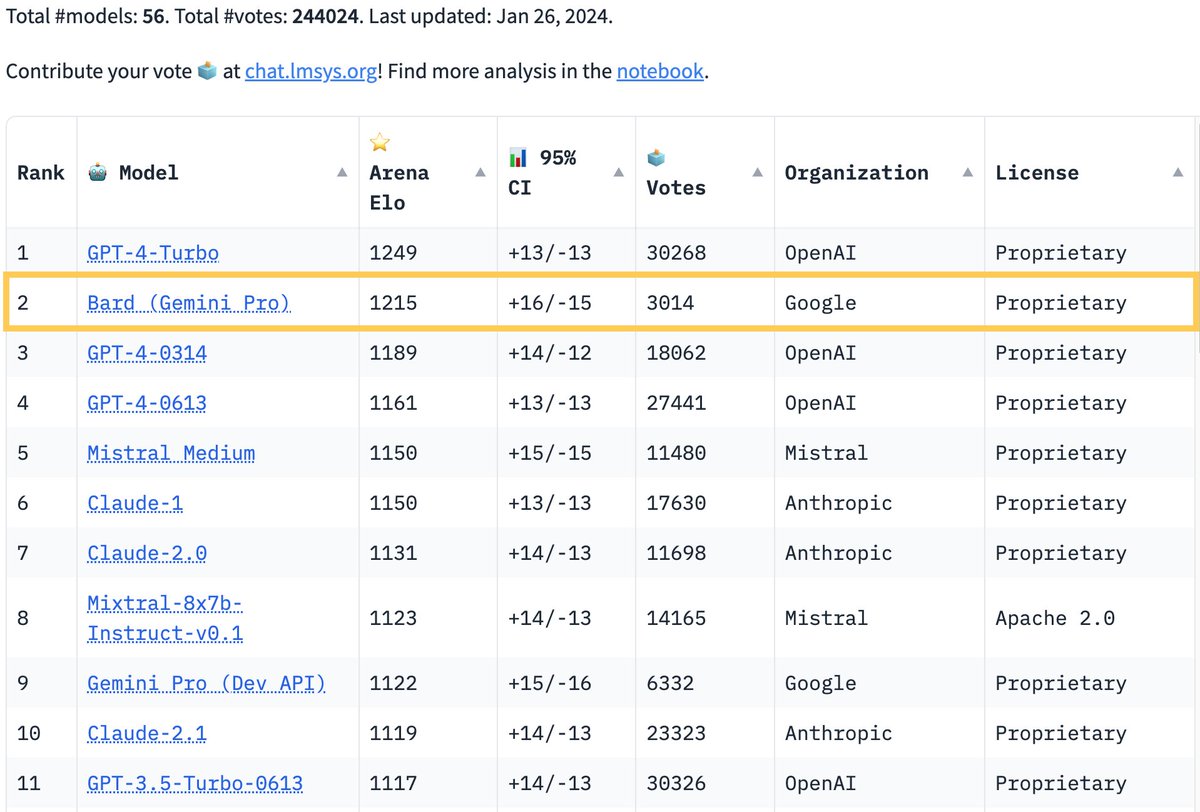
14
32
308
Cool results from our collaboration with colleagues at @DeepMind on searching for new layers as alternatives for BatchNorm-ReLU. Excited with the potential use of AutoML for discovering novel ML concepts from low level primitives.

New paper: Evolving Normalization-Activation Layers. We use evolution to design new layers called EvoNorms, which outperform BatchNorm-ReLU on many tasks. A promising use of AutoML to discover fundamental ML building blocks. Joint work with @DeepMind
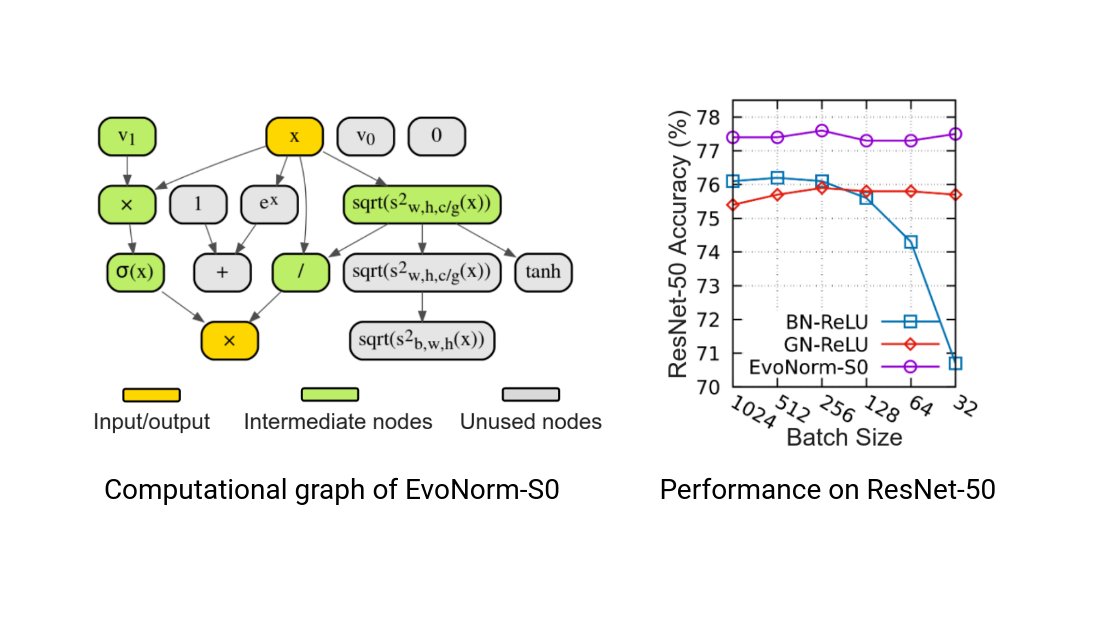
2
77
309
Amazing achievement: Our AI system at Google DeepMind just achieved the equivalent of a silver medal at the International Mathematical Olympiad (#IMO2024). This is a major milestone for AI in mathematics. Very proud to have been a part of it!.

We’re presenting the first AI to solve International Mathematical Olympiad problems at a silver medalist level.🥈. It combines AlphaProof, a new breakthrough model for formal reasoning, and AlphaGeometry 2, an improved version of our previous system. 🧵
5
32
275
Evolved Transformer is now opensourced in Tensor2Tensor:.
We used architecture search to improve Transformer architecture. Key is to use evolution and seed initial population with Transformer itself. The found architecture, Evolved Transformer, is better and more efficient, especially for small size models. Link:
3
73
280
Waymo's blogpost about the use of automated data augmentation methods for self-driving cars (AutoAugment, RandAugment, Progressive Population Based Augmentation - PPBA). PPBA is ". up to 10 times more data efficient than training nets without augmentation".

Our newest research in collaboration with our @googleAI colleagues will allow us to train better machine learning models with less data and improve perception tasks for the Waymo Driver.
0
58
273
Exciting new AutoML lineup for @googlecloud : AutoML Tables & Mobile Vision. Collaboration between Google Brain + AI + Cloud. Some benchmark data are below. Google Brain AutoML team will also participate in a Kaggle competition tomorrow. This will be fun!.

9
67
254
When in doubt, try larger models with more data :-) Joint training of a big model on many speech datasets leads to impressive improvements across the board on many important benchmarks. Link:

3
42
243
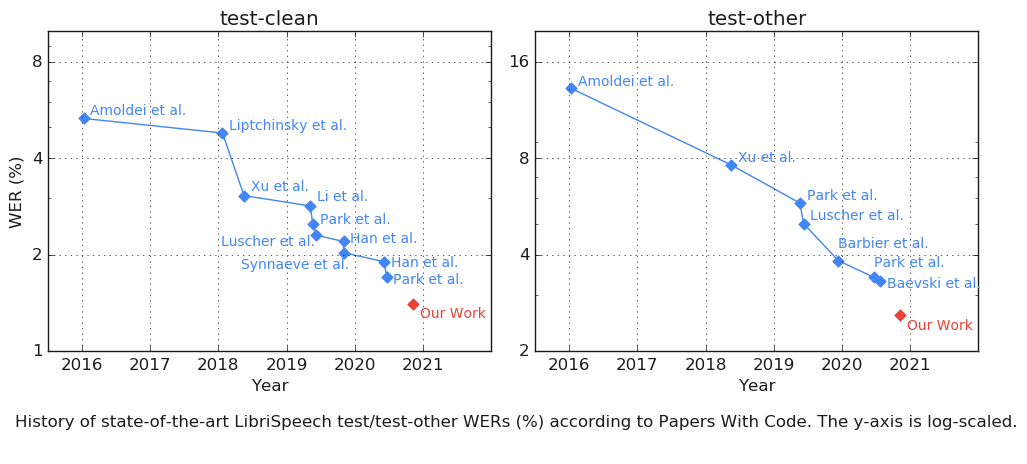
Some new progress on Semi-supervised learning for speech recognition. Noisy student training improves accuracy on the LibriSpeech benchmark. The gains are especially big on the noisy test set (“Test-other”). Link:

1
56
245
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts.1.2T weight model that has better average zero and one-shot results than GPT-3 while using only ⅓ of compute for training. Arxiv: Blog:
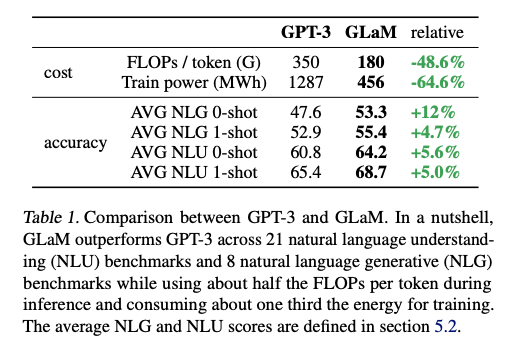
6
59
236
We studied transfer learning from ImageNet to other datasets. Finding: better ImageNet architectures tend to work better on other datasets too. Surprise: pretraining on ImageNet dataset sometimes doesn't help very much. More info:

We updated our paper "Do Better ImageNet Models Transfer Better?" In v2, we show that regularization settings for ImageNet training matter a lot for transfer learning on fixed features. ImageNet accuracy now correlates with transfer acc in all settings.
3
55
228
Good meme for recent MLP papers ;).Pay attention to MLPs:


6
38
204
Method is also super simple:. 1) Train a classifier on ImageNet.2) Infer labels on a much larger unlabeled dataset.3) Train a larger classifier on the combined set.4) Iterate the process, adding noise.
12
30
196
Large language models can perform zero-shot learning pretty well if you finetune them on NLP tasks verbalized with instructions. Link:

4
42
195
Gemini 2.5 Pro is now #1 across all categories on Arena leaderboard. Been playing with it and it's a really amazing model.
BREAKING: Gemini 2.5 Pro is now #1 on the Arena leaderboard - the largest score jump ever (+40 pts vs Grok-3/GPT-4.5)! 🏆. Tested under codename "nebula"🌌, Gemini 2.5 Pro ranked #1🥇 across ALL categories and UNIQUELY #1 in Math, Creative Writing, Instruction Following, Longer

7
14
189
Nice work on speeding up physics simulations with convolutional nets & neural architecture search.
2
30
161
Peters et al 2017 and 2018 (ELMo) get the credit for the discoveries of 1) Using language models for transfer learning and 2) Embedding words through a language model ("contextualized word vectors"). ELMo is great, but these methods were proposed earlier. (1/3).
2
29
162
Wanted to apply AutoAugment to speech, but a handcrafted augmentation policy already improves SOTA. Idea: randomly drop out certain time & frequency blocks, and warp input spectrogram. Results: state-of-art on LibriSpeech 960h & Switchboard 300h. Link:

Automatic Speech Recognition (ASR) struggles in the absence of an extensive volume of training data. We present SpecAugment, a new approach to augmenting audio data that treats it as a visual problem rather than an audio one. Learn more at →

0
37
151
I also highly recommend this nice video that explains the paper very well:.
4
30
149
@xpearhead @lmthang My favorite conversation is below. The Hayvard pun was funny but I totally missed the steer joke at the end until it was pointed out today by @Blonkhart

5
20
142
Key idea in these two papers is to ensure prediction(x) = prediction(x + noise) , where x is an unlabeled example. People have tried all kind of noise, e.g., Gaussian noise, adversarial noise etc. But it looks like data augmentation noise is the real winner.
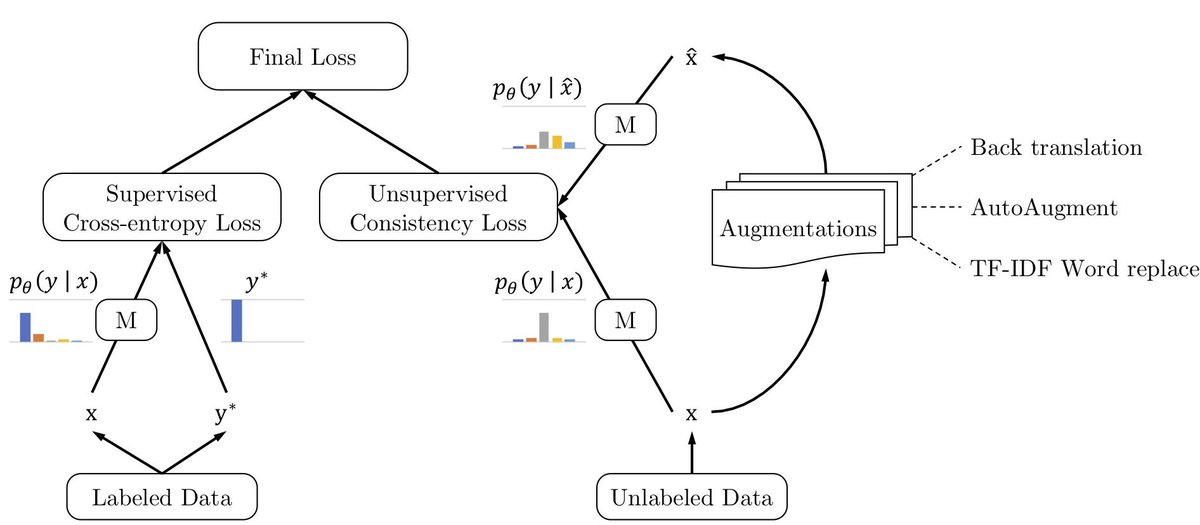
3
32
143
For me, ELMo is my favorite work of 2018. Together with ULMFit, CoVE, GPT, BERT and others, they represent a breakthrough. I just mean that these ideas have a history, and want to bring up some history from my part. Also check out some comments in the thread for related works.
Peters et al 2017 and 2018 (ELMo) get the credit for the discoveries of 1) Using language models for transfer learning and 2) Embedding words through a language model ("contextualized word vectors"). ELMo is great, but these methods were proposed earlier. (1/3).
0
15
136
Our new work on evaluating and benchmarking long-form factuality. We provide a new dataset, an evaluation method, an aggregation metric that accounts for both precision and recall, and an analysis of thirteen popular LLMs (including Gemini, GPT, and Claude). We’re also.

New @GoogleDeepMind+@Stanford paper! 📜. How can we benchmark long-form factuality in language models?. We show that LLMs can generate a large dataset and are better annotators than humans, and we use this to rank Gemini, GPT, Claude, and PaLM-2 models.
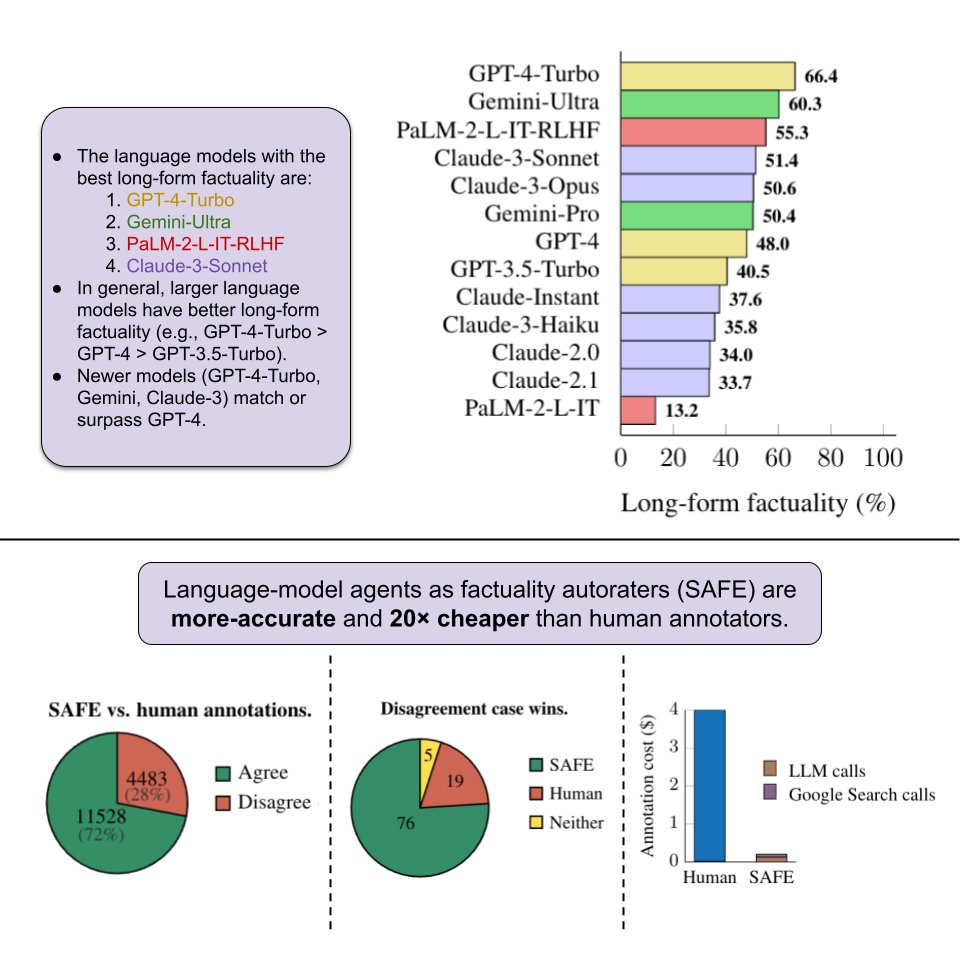
2
20
137
Our latest paper on DropBlock, a new regularization method for convolutional networks. DropBlock drops continuous region of a feature map. It improves ImageNet top1 of ResNet from 76.5% to 78.1%, and COCO mAP of RetinaNet from 36.8% to 38.4%. Paper:


2
53
136
You should spend more compute at test time.

Do you like LLMs? Do you also like for loops? Then you’ll love our new paper!. We scale inference compute through repeated sampling: we let models make hundreds or thousands of attempts when solving a problem, rather than just one. By simply sampling more, we can boost LLM

2
9
109
Short summary of the method: Meta Pseudo Labels is based on Pseudo Labels. But it has a feedback loop from student to teacher. So both teacher and student are trained concurrently to teach each other in this method. Code:

4
18
123
Since our work on "Semi-supervised sequence learning", ELMo, BERT and others have shown changes in the algorithm give big accuracy gains. But now given these nice results with a vanilla language model, it's possible that a big factor for gains can come from scale. Exciting!.

We've trained an unsupervised language model that can generate coherent paragraphs and perform rudimentary reading comprehension, machine translation, question answering, and summarization — all without task-specific training:
0
17
119
Cool new research from our team @Google!. Symbol tuning is a new finetuning method that allows language models to better learn input–label mappings in-context.
New @GoogleAI+@Stanford paper!📜. Symbol tuning is a simple method that improves in-context learning by emphasizing input–label mappings. It improves robustness to prompts without instructions/relevant labels and boosts performance on algorithmic tasks.

2
12
100
Introducing Natural Questions, a new dataset for Q&A research. Many questions in the dataset are not yet answered well by Google:. where does the energy in a nuclear explosion come from?. when are hops added to the brewing process?. The dataset is still difficult for SoTA models.
Introducing Natural Questions, a new, large-scale corpus and challenge for training and evaluating open-domain question answering systems, and the first to replicate the end-to-end process in which people find answers to questions. Learn more at ↓
0
20
105
Full comparison against state-of-the-art on ImageNet. Noisy Student is our method. Noisy Student + EfficientNet is 11% better than your favorite ResNet-50 😉

5
18
99
A nice video about the paper is below. Note that first version of the paper said 87.4% top-1 accuracy but since then we improved the result to 88.4%.
1
17
99
Introducing MAPO, an policy gradient method augmented with memory of good trajectories to make better updates. Well suited for generating programs to query databases. Good accuracies on WikiTableQuestions and WikiSQL. Video: #NeurIPS2018

1
27
97
Update from #KaggleDays , 5 hours into the competition and Google AutoML still maintains its lead. Three hours to go (five hours since I took the pictures).


4
11
94
Google AI's blog post about our work on Transformer-XL.
Introducing Transformer-XL, a novel architecture that enables natural language understanding beyond a fixed-length context. You can learn more and find the paper, code, pretrained models and hyperparameters at ↓
1
19
91

Excited to see Gemini #1 on lmsys. Nice ELO of 1300 :-).
Exciting News from Chatbot Arena!. @GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes. For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive

1
2
81
Final results are in, and Google AutoML came in second in the final ranking.
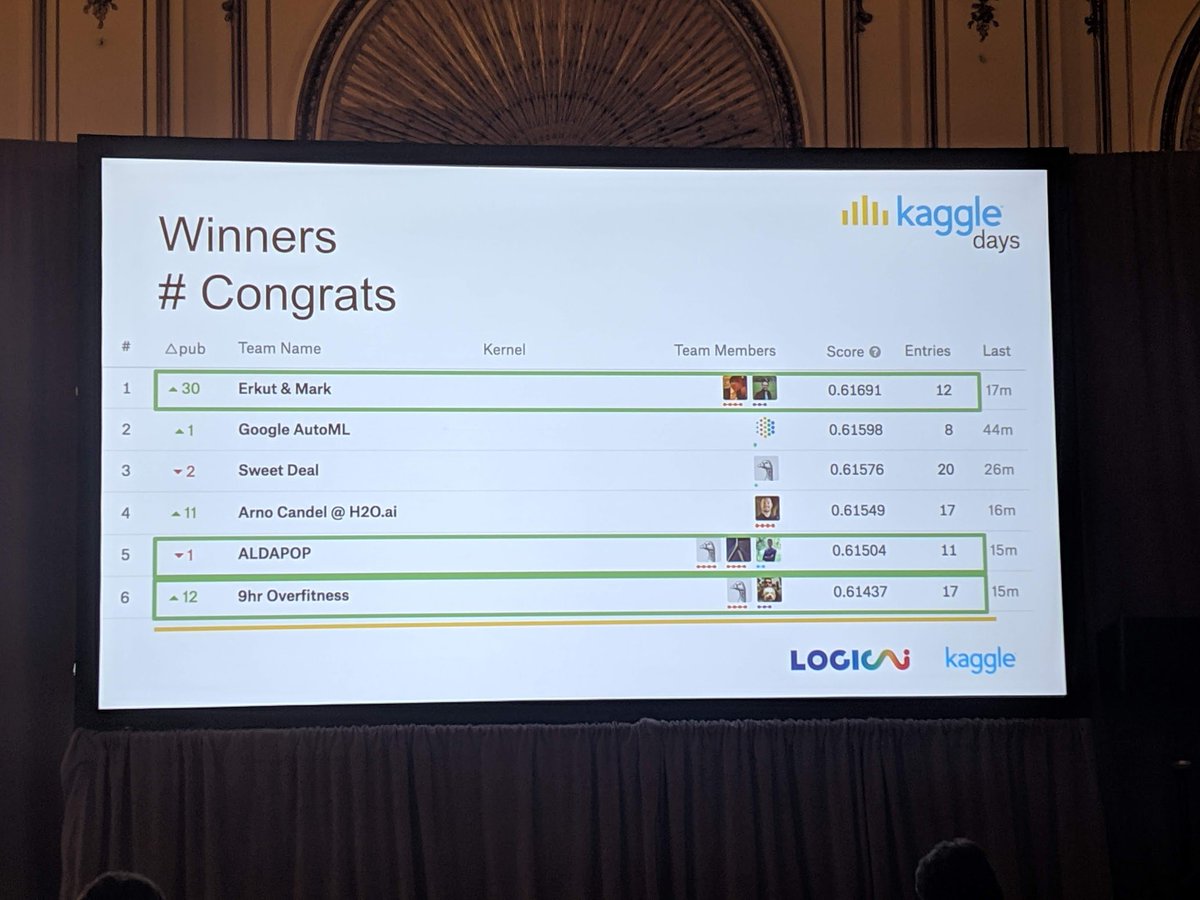
4
6
89
As a data augmentation method, adversarial examples are more general than other image processing techniques. So I expect AdvProp to be useful everywhere (language, structured data etc.), not just image recognition.
1
14
88
AlphaPokemon? 😅.

Gemini 2.5 Pro just got the final 8th badge in Pokemon Blue, incredible pace of progress by the world's most powerful model!!!. Next up: victory road and final 4 : )

3
3
87
Blog post about our collaboration to automate the design of machine learning models for @Waymo 's perception problems.
Our researchers have teamed up with @GoogleAI to put cutting-edge AutoML research into practice by automatically generating neural nets for our self-driving cars. The results? Faster and more accurate nets for our vehicles.
0
14
84
Auto-Augment policies are now opensourced in TF-Hub.

Image augmentation lets you get the most of your dataset. We released state-of-the-art AutoAugment Modules on #TFHub allowing you to train better image models with less data! #TensorFlowHub #GoogleAI. Check it out here →

0
15
83
Links to the mentioned papers. MixMatch: Unsupervised Data Augmentation:
1
14
72
@Miles_Brundage @emilymbender @timnitGebru Oops, thanks for pointing out. We had some text discussing Bender et al. in an earlier draft, but it looks like an editing pass to rework some text from a few weeks ago accidentally dropped that. We'll upload a new version soon with that discussion restored.
9
7
70
@deliprao We congratulate Tomas on winning the award. Regarding seq2seq, there are inaccuracies in his account. In particular, we all recall very specifically that he did not suggest the idea to us, and was in fact highly skeptical when we shared the end-to-end translation idea with him.
4
1
73
First, the idea of using pre-trained language models for transfer learning was proposed in our paper in 2015: . (2/3)

4
7
70
Asking LLMs to take a step back improves their ability to reason and answer highly specific questions.

Introducing 🔥 ‘Step back prompting’ 🔥 fueled by the power of abstraction. Joint work with the awesome collaborators at @GoogleDeepMind : @HuaixiuZheng , @xinyun_chen_ , @HengTze , @edchi , @quocleix , @denny_zhou. LLMs struggle to answer specific questions such as: “Estella

1
14
66
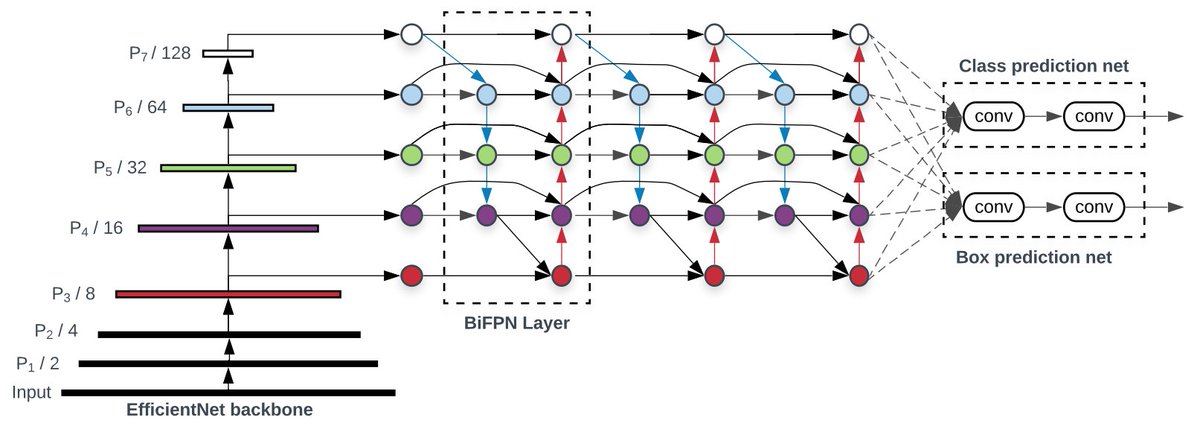
This work continues our efforts on semi-supervised learning such as. UDA: MixMatch: FixMatch: Noisy Student: etc. Joint work with @hieupham789 @QizheXie @ZihangDai.
1
11
69
Second, the idea of embedding words through a language model was proposed in our followup paper in 2016: . (3/3)

3
5
61
To add to Vincent's point above, new findings also include:. 1. The method is general (works well for images & texts). 2. The method works well on top of transfer learning (e.g., BERT). You can find these results in Unsupervised Data Augmentation paper:
0
11
63
Applying this simple method to EfficientNet produces much more robust models on ImageNet than previous state-of-the-art.

2
3
60
For PaLM, chain of thought prompting boosted the solving rate on GSM8K from 17.9% (by regular prompting) to 58.1%. Quite a big jump!

3
11
54
Many of us tried to use adversarial examples as data augmentation and observed a drop in accuracy. And it seems that simply using two BatchNorms overcomes this mysterious drop in accuracy.
1
8
52
This work continues our self-training efforts:.Noisy Student Training (SOTA on ImageNet): Noisy Student Training for Speech (SOTA on LibriSpeech): Conclusion? Good results on big datasets need self-training (w/ Noisy Student) :).
3
7
52
Summary tweet of other contributions by the first author:

New paper + models!. We extend instruction finetuning by.1. scaling to 540B model.2. scaling to 1.8K finetuning tasks.3. finetuning on chain-of-thought (CoT) data. With these, our Flan-PaLM model achieves a new SoTA of 75.2% on MMLU.

1
5
51
A weakness of LLMs is that they don’t know recent events well. This is nice work from Tu developing a benchmark (FreshQA) to measure factuality of recent events, and a simple method to improve search integration for better performance on the benchmark.

🚨 New @GoogleAI paper:. 🤖 LLMs are game-changers, but can they help us navigate a constantly changing world? 🤔. As of now, our work shows that LLMs, no matter their size, struggle when it comes to fast-changing knowledge & false premises. 📰: 👇


1
7
48
@xpearhead @lmthang @Blonkhart I had another conversation with Meena just now. It's not as funny and I don't understand the first answer. But the replies to the next two questions are quite funny.

1
9
47
Chain of thought prompting combined with self-consistency decoding ( ) solves 75% of the math problems in the GSM8K benchmark (prior finetuned SOTA = 55%).

2
10
50
Our work also reveals that bigger models are also more robust models, which is unexpected and also good news. It's good news because more compute can be used to tackle adversarial robustness.

3
6
46
Our implementation of EfficientDet in TensorFlow:. Good implementation of EfficientDet in PyTorch (not by us):.

0
7
47