
Ashish Vaswani
@ashVaswani
Followers
19,470
Following
1,567
Media
6
Statuses
70
Explore trending content on Musk Viewer
Rio Grande do Sul
• 201547 Tweets
Madonna
• 156305 Tweets
Bucks
• 74997 Tweets
Dame
• 58630 Tweets
Knicks
• 53496 Tweets
Racing
• 53112 Tweets
Pacers
• 45184 Tweets
Sixers
• 34213 Tweets
#911onABC
• 32151 Tweets
bruno mars
• 28205 Tweets
憲法改正
• 27325 Tweets
Pabllo
• 26750 Tweets
dua lipa
• 22312 Tweets
Giannis
• 21496 Tweets
Rony
• 20947 Tweets
Bruins
• 15629 Tweets
Anne Hathaway
• 15150 Tweets
Costas
• 14848 Tweets
Lillard
• 14237 Tweets
#SnowMan結成12周年
• 13473 Tweets
76ers
• 12529 Tweets
Arias
• 12285 Tweets
Estevão
• 11858 Tweets
#LeafsForever
• 11422 Tweets
Talleres
• 10575 Tweets




















Pinned Tweet

I'm thrilled to announce our company,
@essential_ai
. We believe that breakthroughs in AI will unlock the most profound tools for thought, advancing humanity's collective knowledge and capability.
105
117
2K
After 5+ wonderful years in Google Brain, working at the forefront of ML alongside inspiring colleagues, I'm excited to share my new adventure. We started Adept with the mission to build the future of human-computer collaboration. .
57
75
2K
We've taught Transformers to take actions in the digital world!

1/7 We built a new model! It’s called Action Transformer (ACT-1) and we taught it to use a bunch of software tools. In this first video, the user simply types a high-level request and ACT-1 does the rest. Read on to see more examples ⬇️
137
922
5K
19
62
698
We’re building the future of useful and intelligent machines. Our early neural networks can make plots, query databases and fetch internet data! If you’re excited to work on fundamental research like learning from human feedback and building sample efficient models, please apply!
We made a fun video of some of the earliest things our system can do! If you want to help us build useful general intelligence, please reach out -- we are hiring.
30
105
717
18
30
434
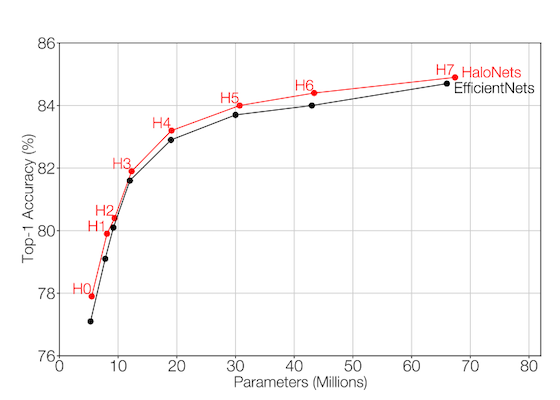
(1/5) In our recent CVPR paper, we develop a new family of parameter-efficient local self-attention models, HaloNets, that outperform EfficientNet in the parameter-accuracy tradeoff on ImageNet. .
2
44
261
Please reach out to me if you're interested in working with us!
14
4
88
Essential AI is dedicated to building technology that lowers the barrier to any enterprise workflow, time consuming or complex, that can be performed on a computer.
2
1
62
We believe that a small, focused team of motivated individuals can create outsized breakthroughs. If you want to work on some of the most important problems in AI, please apply here:
1
1
52
Excited to be on this journey with
@nikiparmar09
along with our incredible team
@mrinal_iyer_01
,
@ag_i_2211
,
@samcwl
,
@andrewhojel
and Varun Desai
3
1
48
We are thankful for the support from our angels:
@amasad
,
@altcap
,
@w_conviction
,
@eladgil
,
@fdesouza
, David H. Patraeus,
@GSapoznik
,
@jwmontgomery
, and Mei Zuo.
5
0
32
We are excited to partner with
@MarchCPs
,
@ThriveCapital
, with participation from
@amd
, Franklin Venture Partners (
@FTI_US
), Google, KB Investment,
@nvidia
.
1
0
20
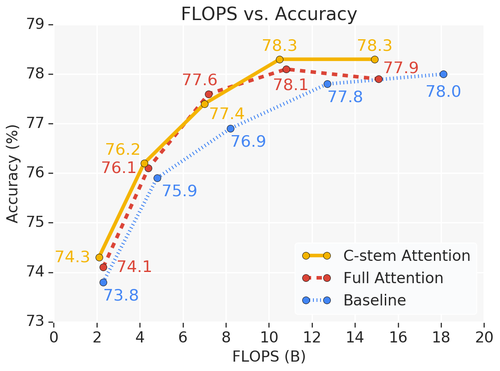
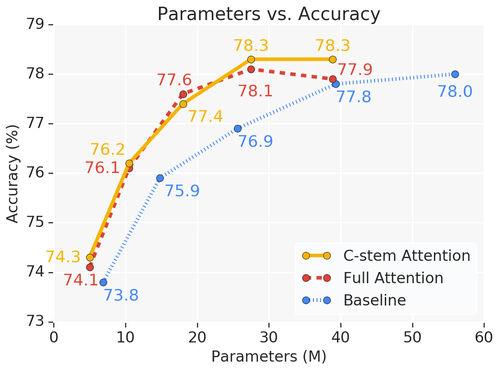
Pure content based interactions are competitive for vision models. Lot's of exciting work to be done in this research area.

New Paper:
Stand-Alone Self-Attention in Vision Models
Can attention work as a stand-alone primitive for vision models?
We develop a pure self-attention model by replacing the spatial convolutions in a ResNet by a simple, local self-attention layer.
15
112
449
1
1
20
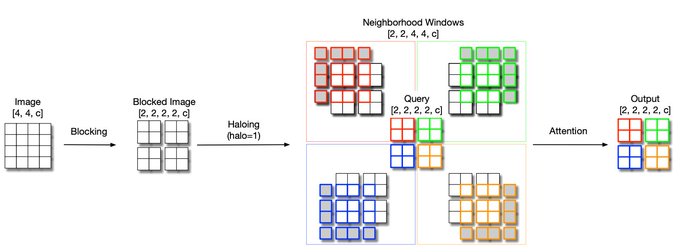
(3 / 5) In previous work (), we used pixel-centered windows, similar to convolutions. Here, we develop a block centered formulation for better efficiency on matrix accelerators.
1
1
15
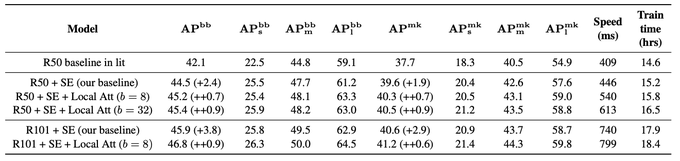
(4/5) When applied to detection and instance segmentation, our local self-attention improves on top of strong convolutional baselines. Interestingly, local self-attention with 14x14 receptive fields performs nearly as well as 35x35.
1
0
14
(5/5) Joint work with Prajit Ramachandran,
@AravSrinivas
,
@nikiparmar09
,
@BlakeHechtman
, and Jonathon Shlens.
1
1
13
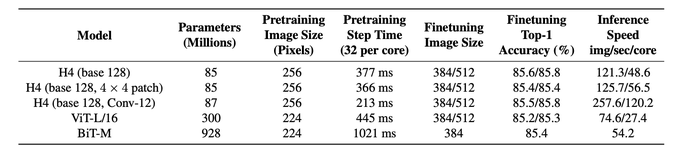
(2/5) In addition to strong results on ImageNet, we also see promising improvements (up to 4.4x inference speedups) over strong baselines when pretrained on ImageNet-21k with comparable settings.
1
0
12
Our self-attention model outperforms the Resnet baseline on ImageNet classification and matches RetinaNet on object detection with fewer FLOPS and parameters.
0
1
10
@jekbradbury
@arvind_io
@nikiparmar09
Thanks! We haven't inspected the latents as yet but that is probably the most exciting thing to do at this point. It's definitely on our TODO.
0
1
3
0
0
2
0
0
2
0
0
1
@arvind2505
Can be photoshopped in ? We can do this on Monday and pretend it was just post NIPS.
1
0
1