

Noam Brown
@polynoamial
Followers
89K
Following
6K
Media
127
Statuses
1K
Researching reasoning @OpenAI | Co-created Libratus/Pluribus superhuman poker AIs, CICERO Diplomacy AI, and OpenAI o3 / o1 / 🍓 reasoning models
San Francisco, CA
Joined January 2017
Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka 🍓) Let me explain 🧵 1/

225
2K
11K
Considering the technology and the pace of progress, I think this is quite sane.

This is insane. AI capex might account for a larger share of GDP than basically any technology since the railroad. Basically it’s a mini-wartime economy, but the guns are chips and the tanks are databases

36
38
774
RT @sonyatweetybird: Our latest Training Data episode with the @OpenAI IMO Gold team is out!. @alexwei_ @polynoamial @SherylHsu02 joined to….
0
16
0
It can be hard to “feel the AGI” until you see an AI master a domain you care deeply about. Everyone will have their Lee Sedol moment at a different time.

the openai IMO news hit me pretty heavy this weekend. i'm still in the acute phase of the impact, i think. i consider myself a professional mathematician (a characterization some actual professional mathematicians might take issue with, but my party my rules) and i don't think i.
82
100
1K
RT @alexwei_: On IMO P6 (without going into too much detail about our setup), the model "knew" it didn't have a correct solution. The model….
0
164
0
More than anything, we’re excited to share our progress and results with the world. AI reasoning capabilities are progressing fast, and these IMO results really show it.
6
3
343
We announced at ~1am PT (6pm AEST), after the award ceremony concluded. At no point did anyone request that we announce later than that.
4
9
368
Before we shared our results, we spoke with an IMO board member, who asked us to wait until after the award ceremony to make it public, a request we happily honored.
2
5
287
We had each submitted proof graded by 3 external IMO medalists and there was unanimous consensus on correctness. We have also posted the proofs publicly so that anyone can verify correctness.
github.com
Contribute to aw31/openai-imo-2025-proofs development by creating an account on GitHub.

6/N In our evaluation, the model solved 5 of the 6 problems on the 2025 IMO. For each problem, three former IMO medalists independently graded the model’s submitted proof, with scores finalized after unanimous consensus. The model earned 35/42 points in total, enough for gold! 🥇.
3
7
266
Over the past several months, we made a lot of progress on general reasoning. This involved collecting, curating, and training on high-quality math data, which will also go into future models. In our IMO eval we did not use RAG or any tools.
5
10
329
~2 months ago, the IMO emailed us about participating in a formal (Lean) version of the IMO. We’ve been focused on general reasoning in natural language without the constraints of Lean, so we declined. We were never approached about a natural language math option.
2
3
307
Congrats to the GDM team on their IMO result! I think their parallel success highlights how fast AI progress is. Their approach was a bit different than ours, but I think that shows there are many research directions for further progress. Some thoughts on our model and results 🧵.
122
201
2K
RT @austinc3301: I’m giving a talk on the speed of progress on LLM capabilities in 3 hours, gotta update the slides 😭😭.
0
33
0
It’s truly a privilege to be able to wake up every morning, see where the latest intelligence frontier is, and help push it a little further.
82
86
2K
Their bet allowed for formal math AI systems (like AlphaProof). In 2022, almost nobody thought an LLM could be IMO gold level by 2025.

We are seeing much faster AI progress than **Paul Christiano** and **Yudkowsky** predicted, who had gold in 2025 at 8% and 16% respectively, by methods that are more general than expected.
35
69
1K
It takes us a few months to turn the experimental research frontier into a product. But progress is so fast that a few months can mean a big difference in capabilities.

So, all the models underperform humans on the new International Mathematical Olympiad questions, and Grok-4 is especially bad on it, even with best-of-n selection? Unbelievable!

32
51
972

@OpenAI In case you stumbled upon this and don't know what I'm talking about:
1/N I’m excited to share that our latest @OpenAI experimental reasoning LLM has achieved a longstanding grand challenge in AI: gold medal-level performance on the world’s most prestigious math competition—the International Math Olympiad (IMO).

4
3
211
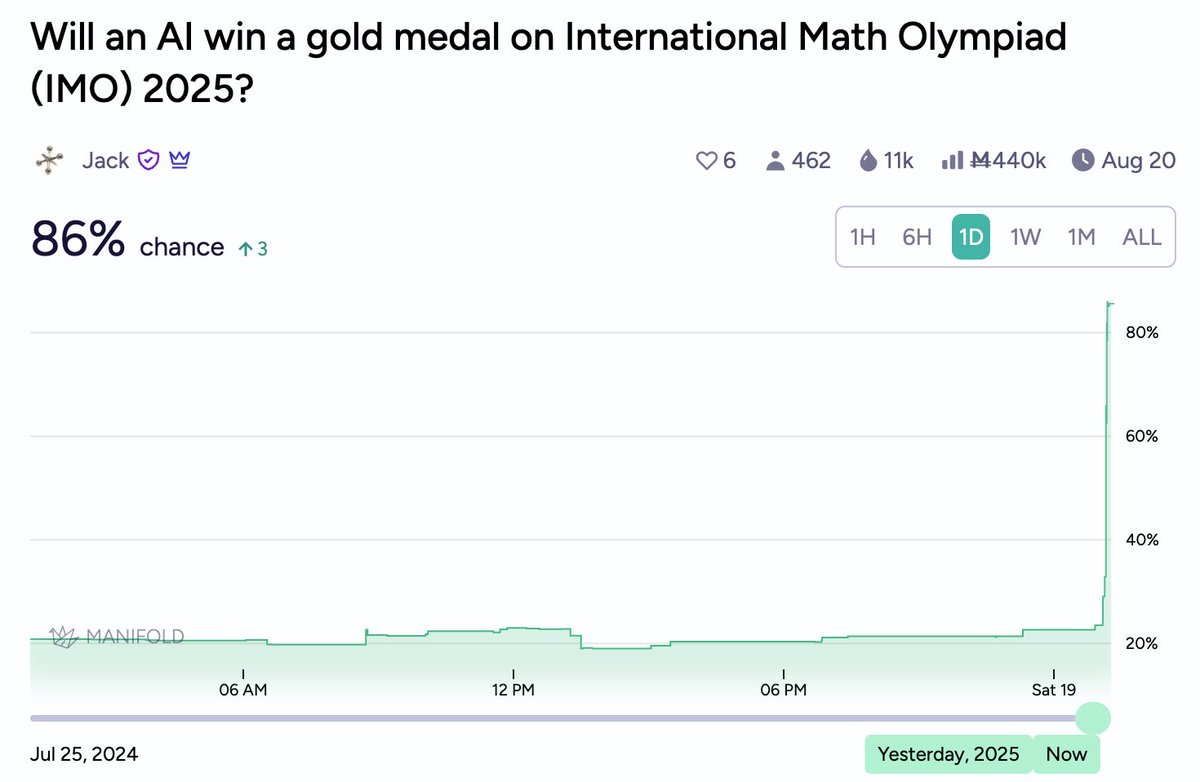
I think it's safe to say this @OpenAI IMO gold result came as a bit of a surprise to folks
81
155
3K
Sheryl (@sherylhsu02) was our first hire onto the multi-agent team. Within a few months of joining, she helped to make this possible. We're so lucky to have her on the team!.

Watching the model solve these IMO problems and achieve gold-level performance was magical. A few thoughts 🧵.
28
24
739
When you work at a frontier lab, you usually know where frontier capabilities are months before anyone else. But this result is brand new, using recently developed techniques. It was a surprise even to many researchers at OpenAI. Today, everyone gets to see where the frontier is.
27
53
1K