

Zhangir Azerbayev
@zhangir_azerbay
Followers
945
Following
559
Media
47
Statuses
729
Building an artificial mathematician @PrincetonCS .
Princeton, NJ
Joined July 2019
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Gandhi
• 110570 Tweets
#WEARE
• 98215 Tweets
yves
• 54007 Tweets
ロッキン
• 40027 Tweets
ブートヒル
• 35648 Tweets
#FNS鬼レンチャン歌謡祭
• 35281 Tweets
新庄監督
• 25493 Tweets
महात्मा गांधी
• 24164 Tweets
海ちゃん
• 23372 Tweets
#ミリシタ生配信
• 19017 Tweets
オリックス
• 16681 Tweets
京セラドーム大阪
• 15680 Tweets
Fethi'nin 571
• 13784 Tweets
森林環境税
• 11732 Tweets
nineアニメ化
• 11195 Tweets



















Pinned Tweet

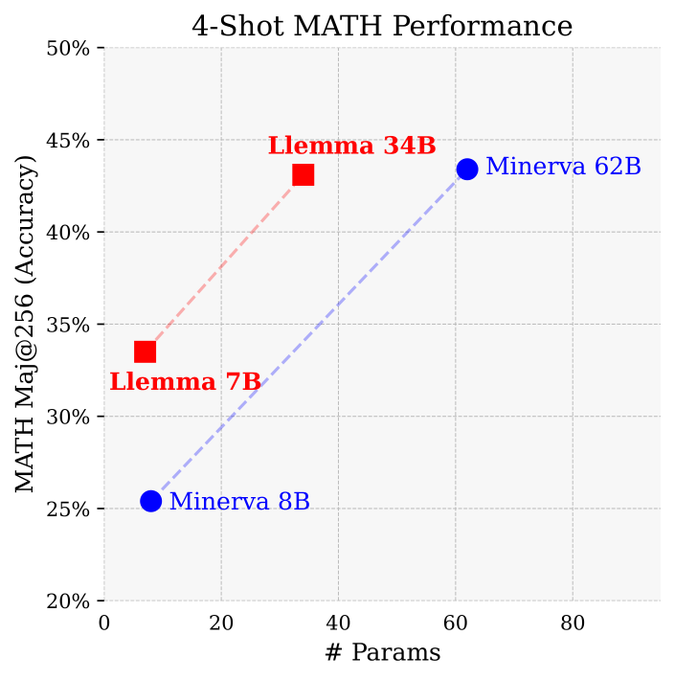
We release Llemma: open LMs for math trained on up to 200B tokens of mathematical text.
The performance of Llemma 34B approaches Google's Minerva 62B despite having half the parameters.
Models/data/code:
Paper:
More ⬇️
11
136
562
How good are language models at formalizing undergraduate math? We explore this in
"ProofNet: autoformalizing and formally proving undergraduate-level mathematics"
Thread below. 1/n

3
54
180
Autoformalization with LLMs in Lean... for everyone!
The chat interface for autoformalizing theorem statements in Lean built by myself and
@ewayers
is now publicly available as a vs-code extension.


7
30
162
@willdepue
@eigenrobot
@yacineMTB
-0.0357192 = -44649/1250000. This doesn't have a terminating binary representation.
gpt-4 is trained with infinite precision floats???
3
0
131
What is the best way to learn CUDA? The "Cuda by Example" book looks strong, but it was published in 2010 and I worry it may be outdated. Nvidia has a $90 course on their website but I have no idea if it's worth the price.
5
2
75
which open source ML repo best exemplifies great software engineering practices? (wrt to interface design, readability, extensibility, etc.)
9
6
54
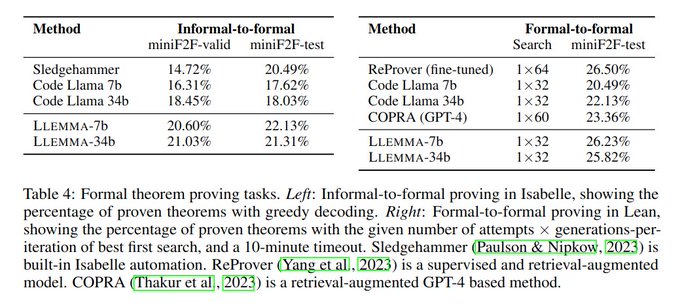
Formal theorem proving consists of writing a machine-checkable proof in a language such as Lean or Isabelle. Thanks to the special emphasis on formal proof data in the AlgebraicStack, Llemma is the first open base model to demonstrate few-shot theorem proving capabilities. 8/n

1
11
48
Our primary contribution is releasing ProofNet, a dataset of 371 parallel natural language theorems, natural language proofs, and formal theorem statements in Lean 3. (HF link: )

1
5
37
Myself and
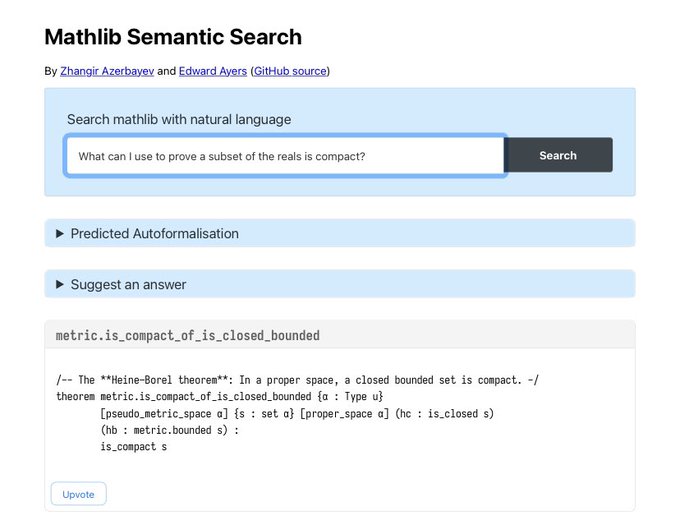
@ewayers
put together a demo of semantic search for Lean mathlib built with the OpenAI API.
Newcomers to formal math can search the library in a natural, conversational way instead of having to memorize the naming convention.
1
4
33
@AiEleuther
@haileysch__
@keirp1
@dsantosmarco
@McaleerStephen
@AlbertQJiang
@jiadeng
@BlancheMinerva
@wellecks
Our work parallels Minerva, a closed model specialized for mathematics developed by Google Research. Llemma exceeds Minerva’s problem solving performance on an equi-parameter basis, while covering a wider distribution of tasks — including tool use and formal mathematics. 3/n
1
6
36
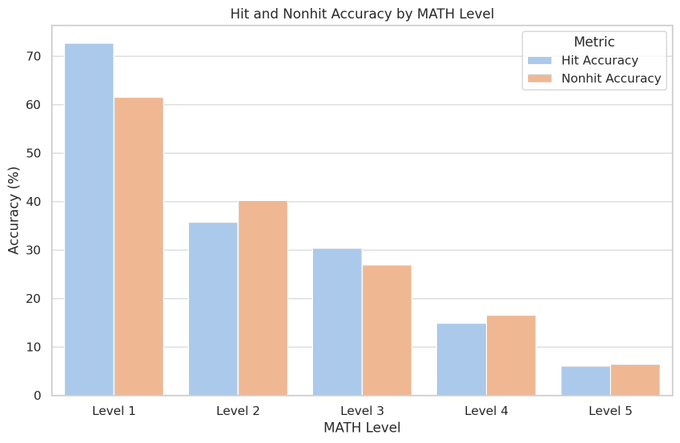
Finally, we seek to quantify the effect of memorization. Surprisingly, we find that Llemma is no more accurate on problems that appear in its training set. Because our code and data are open, we encourage others to replicate and extend our analysis. 9/n
1
1
33
Llemma wouldn’t have been possible without a number of fantastic open source projects, such as GPT-NeoX, the LM Evaluation Harness, FlashAttention-2 and VLLM. Furthermore, we thank
@StabilityAI
,
@coreweave
,
@VectorInst
, and Brigham Young University for compute support. 11/11
0
3
33
Llemma is a collaboration between several academic labs and
@AiEleuther
.
w/
@haileysch__
@keirp1
@dsantosmarco
@McaleerStephen
@AlbertQJiang
@jiadeng
@BlancheMinerva
@wellecks
2/n
1
3
31
The proofGPT-6.7b model's training data includes stack exchange posts conditioned on their number of upvotes. So what happens when you ask for a stack exchange post with trillions of upvotes?

2
3
31
@StefanFSchubert
Why can't the behavior be explained rationally as a mixed strategy equilibrium? Presumably penalty takers only ever kick towards the center *because* goalkeepers often lunge left or right.
2
0
29
@AiEleuther
@haileysch__
@keirp1
@dsantosmarco
@McaleerStephen
@AlbertQJiang
@jiadeng
@BlancheMinerva
@wellecks
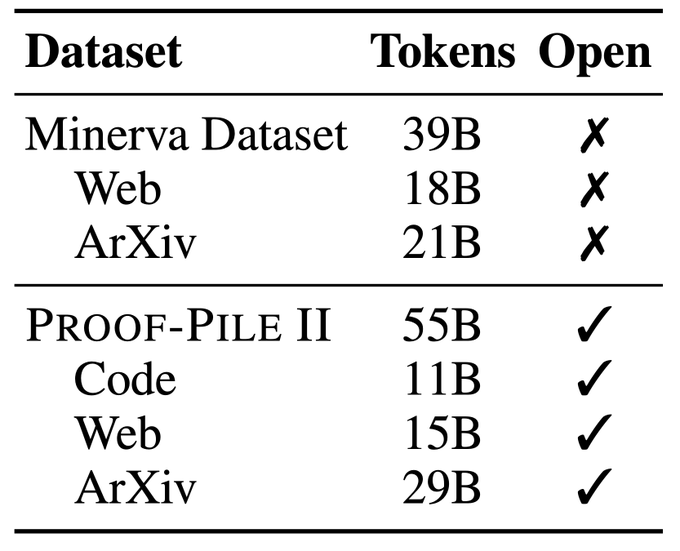
The first step in developing Llemma was to assemble a large dataset of math tokens. We use the ArXiv subset of RedPajama, the recent OpenWebMath dataset, and introduce the AlgebraicStack, a code dataset specialized to mathematics. In total, we train on 55B unique tokens. 4/n
2
5
27
This Nature editorial is striking in its refusal to engage with object level arguments about AI existential risk. Asserting your interlocutor is conducting a psyop is no way to begin a debate.

1
0
26
@ESRogs
@JaitanMartini
@karpathy
@BlazejDolicki
Before LLMs were productized, pre-training cost dominated inference cost, since all the inference we did was running benchmarks. Now that LLMs are productized, inference costs are comparable to pre-training cost. "Chinchilla optimal" only optimizes pre-training cost.
2
2
25
@AiEleuther
@haileysch__
@keirp1
@dsantosmarco
@McaleerStephen
@AlbertQJiang
@jiadeng
@BlancheMinerva
@wellecks
The Llemma models were initialized with Code Llama weights, and trained across 256 A100 GPUs on StabilityAI’s Ezra cluster. The 7B model was trained for 200B tokens and 23,000 A100 hours, and the 34B was trained for 50B tokens and 47,000 A100 hours. 5/n
2
5
19
On chain-of-thought tasks, Llemma outperforms Minerva when controlled for parameters. Majority voting provides a further performance boost. 6/n
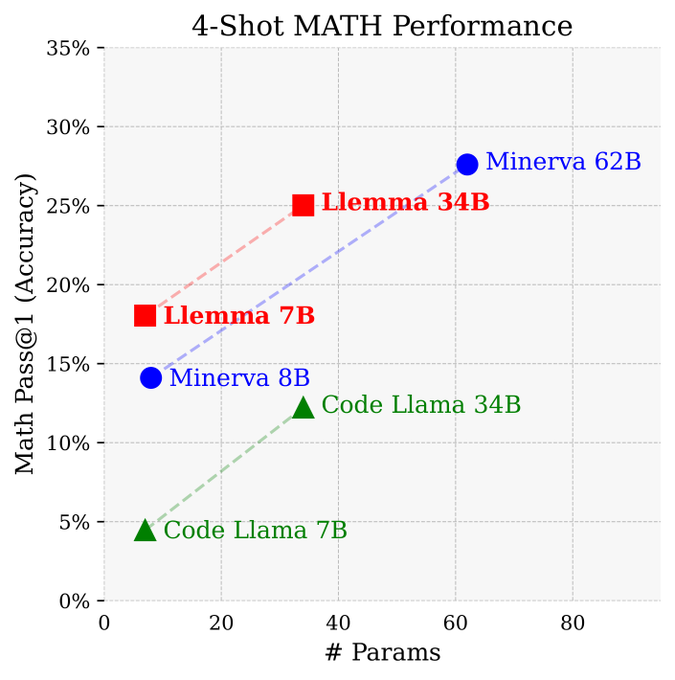
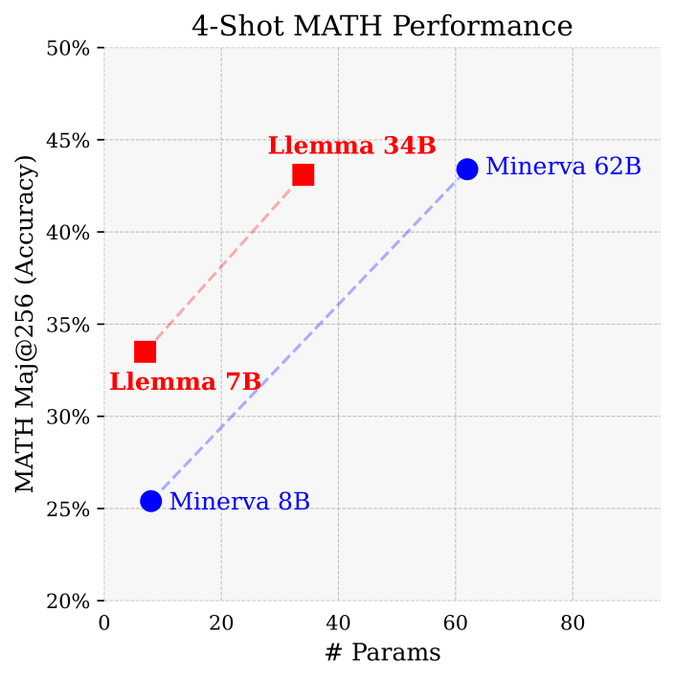
2
3
19
@KhurramJaved_96
I basically agree, but would rather say that transformers work because *we can* make them large and train them on large datasets. Other similarly parallelizable architectures would perform comparably if *we figured out how* to train them stably at scale.
1
0
18
You can view some of Llemma’s outputs on our hosted sample explorer. 10/n
website:
1
1
18
Furthermore, Llemma obtains increased accuracy on some tasks by offloading computations to the Python interpreter. 7/n
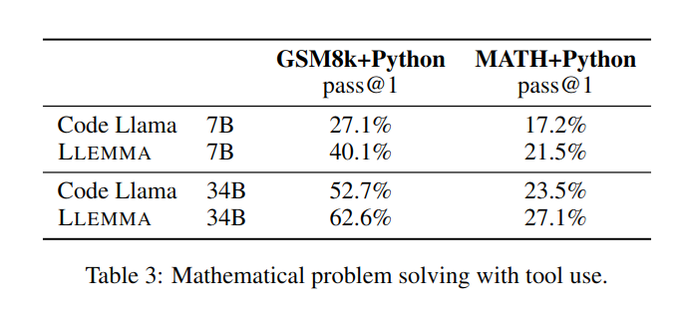
1
3
17
Do we need the full 175B parameters of davinci-codex to autoformalize well? To answer this, we train and open-source the proofGPT models, which are 1.3 billion and 6.7 billion parameter LMs fine-tuned on 8 billion tokens of mathematical text. (HF link: )

1
1
16
Below is a a theorem Codex formalized correctly; this example displays strong knowledge of Lean and impressive reasoning capability! Performance further jumps to 16% if we retrieve helpful examples from mathlib to place in the few-shot prompt. 7/n

1
2
16

@scienceisstrat1
@paulg
I am an ML researcher in the US, and among the highly influential papers me and my colleagues frequently cite, I can't think of a single one that's from a Chinese lab. If this holds in other subfields, it must be that the West and China have nearly disjoint citation networks...
3
0
13
@abacaj
The stack is a great resource and I've gotten a ton of value from it. But fair warning, it does have a lot of data quality issues (e.g base64 images, autogenerated cache files, etc.)
1
0
14
@cauchyfriend
Combing the internet for technical information. I'll construct a google query which finds the course notes from a spectral graph theory class taught in 2008 that solve the exact math problem a friend is struggling with and wonder why they didn't just do that themselves.
1
0
11
blackpill on b2b llm startups is that they'll get crushed when microsoft bundles their inferior gpt app with office
1
1
12
At schipol airport, downloading weights so I can run llama.cpp on my transatlantic flight
1
0
12
The most popular formal math benchmark is currently miniF2F, which consists of olympiad problems. However, miniF2F is of limited relevance to autoformalization use cases, because we usually want to formalize math that depends on abstract analysis, algebra, and geometry. 4/n
1
2
12
Thrilled to share the OpenWebMath dataset, a project led by
@keirp1
and
@dsantosmarco

Introducing OpenWebMath, a massive dataset containing every math document found on the internet - with equations in LaTeX format!
🤗 Download on
@HuggingFace
:
📝 Read the paper:
w/
@dsantosmarco
,
@zhangir_azerbay
,
@jimmybajimmyba
!

26
264
1K
0
2
12
Fun fact I discovered while cleaning github data: about half of the mathematica files on github come from a single repository. For his thesis, the author auto-generated 32,000 scripts that each simulate the same quantum system with different boundary conditions.
1
0
12
First, we use codex to *informalize* all 100,000 formal theorems in mathlib, then fine-tune the 1.3B model in the NL->formal direction. Even though distilled backtranslation produces noisy finetuning data, it boosts the accuracy of the 1.3B model to 3.2%. 10/n

1
0
12
@ben_j_todd
@MaxCRoser
Surely GDP isn't the right metric. Consider this scenario: suppose the charity sector employed 10 million people but was 2% of GDP, but tech employed 1 million people but was 10% of GDP. We want a measure of inputs, not GDP.
3
0
12
long-contexts mean that we can explicitly train models to do coherent long-term planning. For example, instead of training on github source code, train on diffs conditioned on the entire codebase.
2
1
12
@Francis_YAO_
3e-4 is way too high for continuing training: I'd call what you're seeing divergence rather than double descent. Llama's scheduler ends at 3e-5, so start by trying to warm up to 3e-5. You might be able to go higher or need to go lower depending on your data and batch size.
1
1
11
@sheslostheplot
@tszzl
can't believe joe rogan said "I used to be cruel to my woman/I beat her and kept her apart from the things that she loved". Oh wait that was John Lennon.
0
1
11
Unfortunately, these models don't manage to autoformalize anything correctly with in-context learning. But not all is lost. It turns out, we can use a methodology called *distilled backtranslation* to eke some performance out of the 1.3B model. 9/n
1
0
11
With these more complex objects, comes more complex syntax and semantics that the model must cope with. Surprisingly, Davinci-codex achieves 13% accuracy on theorem statement autoformalization with in-context learning only. 6/n
1
0
11
@pfau
Suppose you are put in a perfect sensory deprivation tank and while inside, do some thinking and discover a new theorem. Does you having learned something while in the tank violate the data processing inequality?
1
0
10
The Ivy League is a win-win alliance between rich people and nerds. The rich people fund the nerds, and the nerds provide the rich people with intellectual credibility.
1
0
10
@davidad
there are already (at least) three language model-based systems that generate formal proofs: gpt-f, evariste, and thor.
1
0
9
Someone with money should hire annotators to create a new version of an eval suite every 3-12 months. This way, we can get guaranteed uncontaminated evals by only downloading training data from before the latest version of the eval suite was released.
2
0
10
ProofNet fills this gap by demanding mastery of the undergraduate curriculum, including analysis, abstract algebra, topology, and number theory. 5/n
1
0
10
This is the first time I've seen GPT-4 get stuck in a repetitive loop. This behavior is very common in unaligned models, especially small models like GPT-2 and GPT-J...

2
2
9
I find
@RichardMCNgo
's definition of a "t-AGI" helpful for thinking about near-term AI risks. A system is a t-AGI if "on most cognitive tasks, it beats most human experts who are given time t to perform the task".
Right now, GPT-4 or Claude-2 are perhaps one-minute AGIs. In the
1
0
9
@existentialcoms
It's factually incorrect that microsoft extinguished free software. Linux, freeBSD and others all coexisted with Windows. The difference is that open source developers never made their software user-friendly enough for the general public.
2
0
9
This is heartbreaking news. The passion and energy Drago put into mentoring young researchers, from high schoolers to graduate students, has made a difference in many lives. My thoughts are with his family.

The
#AI
community, the
#computerscience
community, the
@YaleSEAS
community, and humanity have suddenly lost a remarkable person,
@dragomir_radev
- kind and brilliant, devoted to his family and friends... gone too soon. A sad day
@Yale
@YINSedge
@YaleCompsci
#NLP2023


41
87
390
0
1
8
@_julesh_
Reinforcement learning in complex action spaces doesn't work unless you initialize from a strong supervised policy. This is intuitive: in language for example, the chance of a randomly-initialized model stringing together a high-reward sentence is next to nothing.
0
0
7
ProofNet is suitable for evaluating multiple key math tasks, including theorem statement autoformalization, proof autoformalization, and formal theorem proving. We hope that ProofNet will become a standard benchmark for these tasks. 3/n
1
0
8
Cursed ML bug of the day: some libraries use Python's random module to choose TCP port numbers. If you fix a global seed and run two programs that make the same sequence of random choices on the same machine at the same time, one will fail due to a port conflict.
0
0
7
I don't trust evals that exist in the past light cone of a model
1
0
8
@robinhanson
Article is paywalled so didn't read, but I assign tiny odds to context length being a long term issue. Gpt4 is up to 24k words from the 8k of gpt3.5, and that trend will continue. Lots of ideas around for solving long term memory, like memorizing tranformers or block recurrence.
1
0
7
@scienceisstrat1
Incredibly sloppy from the Economist. The y axis purports to be number of training tokens, but actually shows number of parameters. It also makes no sense to compare dense and sparse models on parameter count.
0
0
6
@PennJenks
Check out the appendix :)
We only tried finetuning Llemma 7B because the focus of our work is maximum task generality, but I'm sure you would get great results.
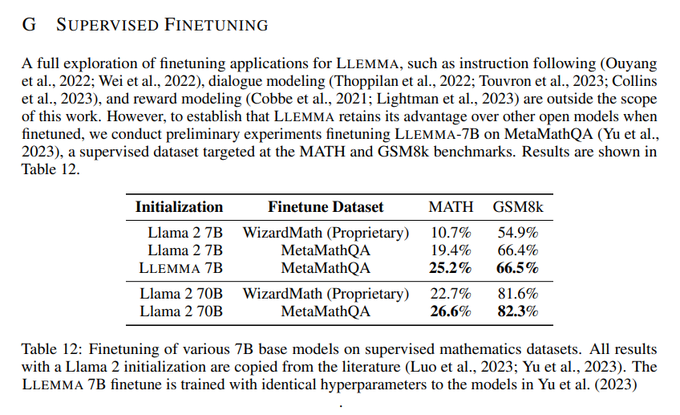
1
2
8
@tydsh
Learning mathematical taste is a tractable problem. Chatbots are already trained by fitting human preferences, and there is a trajectory of incremental improvements from these systems to AIs capable of posing conjectures more profound than the Langlands program.
1
0
7
I once spoke to someone who left programming in the 60s because he didn't want to switch from assembly to high-level languages. AI will be like this x1000: in principle everyone can adapt and remain economically useful, but not everyone will want to.
1
1
7
3D plots are hard to understand when you're only shown a single view, but interactive 3D plots where you can drag your view with the mouse (like plotly.Scatter3d) are far better than 2D with color. This is one reason we should all start writing papers in html like Anthropic.
1
0
7
Isaac Newton doing a kickflip on a skateboard to demonstrate the laws of motion during a Cambridge lecture, oil on canvas
#dalle2

0
1
5
We have lost the way of the McCulloch-Pitts binary neuron, but we will find it again

FP8-LM: Training FP8 Large Language Models
Trains GPT-175B with H100s 64% faster than BF16 without any performance degradation
repo:
abs:

3
136
624
0
0
6
@Francis_YAO_
That is to say, the best learning rate at a given step is better thought of as a function of loss than a function of step count.
2
0
6
@Austen
I often suspect that this is because food in other countries is regularized by tradition, whereas America is closer to a blank slate so it gets the unfettered hyperoptimized technocapital solution.
1
0
6
Massive thank you to my coauthors Bartosz,
@hails
,
@ewayers
,
@dragomir_radev
, and Jeremy Avigad for all their hard work. I also want to thank the Hoskinson Center for Formal Mathematics at CMU for supporting this work. 11/11
3
1
6
@TaliaRinger
Having seen the film, I thought it did a great job offering vantage points from which Oppenheimer appears cruel, hypocritical, cowardly, or a poser. It's very far from the hero worship often directed at physicists.
1
0
6

@martinmbauer
In my field of ML, I watched five years of the "experts" dismissing GPT as useless while a bunch of internet weirdos got it right.
"Trust the experts" is a heuristic that's correct 99% of the time, but all the alpha is in when it's wrong.
0
0
5
@Francis_YAO_
The reason we need learning rate schedulers is because lower loss implies higher gradient noise. So if you start out with lower loss (i.e load a pretrained checkpoint) you need a much lower max learning rate for training to be stable than if you had started from scratch.
4
0
4
I admire Zuck for pouring Meta's profits into R&D for a technological moonshot. Most people in his position would've turned Facebook into a cash-cow stock and spent the rest of their lives sipping mai tais on the beach.
0
0
5
@NateSilver538
Agree with the sentiment, but it's incorrect to say "utilitarian" when you mean "myopic". Utilitarianism tells you to do what makes the outcome best. If committing to follow certain principles will make the outcome better, then utilitarianism is telling you to do that.
1
0
5
@ESRogs
@JaitanMartini
@karpathy
@BlazejDolicki
Right now the heuristic we want to follow is "train the smallest model you can for the desired level of performance". And at our current dataset sizes (~1 trillion tokens) the marginal benefit of more data is still quite high, even for small models.
1
0
5
A short blog post on the fundamental disagreement between "just make the neural net bigger" people and "discover a theory of intelligence" people.
0
0
4
@janleike
My guess would be that the network learns language-independent semantic representations during pre-training, and these are updated during RLHF. But I don't know how to design an experiments that verifies this.
0
0
4
@deliprao
Why does prompting the LLM with "write a plan" not count as planning? This question is not rhetorical and I actually would like to know why it doesn't.
2
0
5
In mathematics, you solve a simple special case of a problem to see if it inspires a solution to the general problem.
In deep learning, this strategy is often counterproductive. Instead, you want to solve the maximally general problem, then condition on the special case.
1
0
4
@existentialcoms
Because Microsoft had a profit motive, they cared how many people were using their software, so they made it accessible to the average person. If it weren't for profit-maximizing software makers, it still might take 5 hours in the command line to set up a computer.
1
0
4
@michael_nielsen
@drjwrae
@__nmca__
This talk by
@drjwrae
gives an in depth explanation of the point
0
0
5
@iamtrask
I don't think it makes sense to ascribe beliefs to pretrained models. No coherent agent capable of articulating beliefs emerges out pretraining. All you have is predictions of further linguistic behavior given any context...
1
0
4

In this thread I wrote a year ago, I said that we should expect amazing advances from applying LLMs + search to reasoning problems. I no longer believe this. If your action space is complicated enough classical search algorithms like MCTS don't yield productive exploration.
The bitter lesson sings the praise of methods that apply search and learning at scale. Every AI practitioner by now knows the power of learning, but search is far less popular. Everyone uses SGD, very few use monte-carlo tree search. Why is this the case? (1/n)
1
0
2
1
0
4
@TaliaRinger
@Yuhu_ai_
@AlbertQJiang
@WendaLi8
Yes! We are logging the data and making it clear to users we are doing so.
1
0
4
Language modelling isn't an exponentially diverging diffusion process if it's looped in with "perception" of the real-world, e.g code execution results, user input, tools, plugins
1
0
3
GPT-3 when prompted with "A blog post by Terence Tao giving a high level overview of his proof of the Riemann Hypothesis: Let $\mathcal{R}$ be an arithmetic zeta function"

0
1
2
@tylercowen
The Katherine Rundell episode was one of my favorites. Was that just variance or has chatgpt increased the mean?
2
0
4
I'm surprised mechanistic interpretability hasn't caught on more in academia. It's one of the best ways to have a lot of impact in deep learning with minimal compute and seems like it would appeal to people with physics or neuro backgrounds.
1
0
4
Academic machine learning contains experimentalists, theorists, and people who are ostensibly experimentalists but act like the caricuture of theorists from Douglas Comer's "How To Criticize Computer Scientists".
0
1
3
Holtzman et al. show that the likelihood of a repeated phrase increases with each repetition.
If your model isn't generalizing well, it may turn out that nothing except repetition is high likelihood.

0
0
4
huggingface link for the model:
0
1
3
@fchollet
I agree with 1-4, but I don't think whether or not we anthropomorphize something should hinge on a deep mechanistic understanding of how human-like it is. We should anthropomorphize something to the extent it is useful to do so.
0
0
4
@ESRogs
@JaitanMartini
@karpathy
@BlazejDolicki
I see why this is confusing. Chinchilla pointed out that training models that are "compute-optimal" with respect to pre-training cost requires more data than we thought. But "product optimal" requires more data still.
1
0
4
@danielgross
It's used because it works better than convnets and we can't think of anything better. But it is true that no one in DL likes tokenization, and there have been attempts to get rid of it, e.g
1
0
2