
EleutherAI
@AiEleuther
Followers
25K
Following
884
Media
45
Statuses
813
A non-profit research lab focused on interpretability, alignment, and ethics of artificial intelligence. Creators of GPT-J, GPT-NeoX, Pythia, and VQGAN-CLIP
Joined August 2022
Can you train a performant language models without using unlicensed text?. We are thrilled to announce the Common Pile v0.1, an 8TB dataset of openly licensed and public domain text. We train 7B models for 1T and 2T tokens and match the performance similar models like LLaMA 1&2

13
137
573
RT @pjox13: If you want to help us improve language and cultural coverage, and build an open source LangID system, please register to our s….
0
11
0
RT @AiEleuther: What can we learn from small models in the age of very large models? How can academics and low-compute orgs . @BlancheMiner….
0
2
0
RT @linguist_cat: Really grateful to the organizers for the recognition of @magikarp_tokens and my work!.
0
3
0
Congratulations to @linguist_cat and @magikarp_tokens on winning the best paper award at the #ICML2025 Tokenizer Workshop!

5
7
105
What can we learn from small models in the age of very large models? How can academics and low-compute orgs . @BlancheMinerva will be speaking on a panel on these topics and more!. Methods and Opportunities at Small Scale Workshop.Sat 19 Jul, 16:00-16:45.

MOSS is happening this Saturday (7/19) at West Ballroom B, Vancouver Center! We are excited to have an amazing set of talks, posters, and panel discussions on the insights from and potential of small-scale analyses. Hope to see a lot of you there! 💡

1
2
10
Starting now!.
The dream of SAEs is to be more interpretable proxies for LLMs, but even these more interpretable proxies can be challenging to interpret. In this work we introduce a pipeline for automatically interpreting SAE latents at scale using LLMs. Thu 17 Jul, 11:00 am-1:30 pm.East.
0
2
11
Who remembers Golden Gate Claude? Despite initial hype, SAE-based steering has remained a mixed bag. In this paper we explore the tradeoffs between SAE steering-based safety improvements and general model capabilities. Actionable Interpretability Workshop.Sat 19 Jul, 10:40-11:40.
1
0
1
Speaking of how to make code releases people will use, @BlancheMinerva will also be giving an invited talk on "Lessons from the Trenches on Reproducible Evaluation of Language Models" and going behind the scenes on how we approach maintaining the most widely used open source LLM.
1
0
1
"Write Code that People Want to Use" investigates how coding practices that emphasize reproducibility limit adoption and advocates for centering extensibility and hackability key features in getting people to use your work. Work by @BlancheMinerva Jenn Mickel and @bbrabbasi,.
1
0
1
Are the boundaries between morphemic tokens respected by LLM tokenizers? Does it matter for downsteam performance? In this work we introduce a methodology to empower evaluation of this question across 70 languages and find that, in general, the answer is no. Tokenizers workshop.
1
0
3
It's really sexy to talk about "tokenizer-free" models right now, but UTF-8 is another (hard-coded) tokenizer. In this work we explore how the script a language is written in influences the efficiency of UTF-8 and BPE representations of language. Tokenizers workshop.West Meeting.
1
0
3
The dream of SAEs is to be more interpretable proxies for LLMs, but even these more interpretable proxies can be challenging to interpret. In this work we introduce a pipeline for automatically interpreting SAE latents at scale using LLMs. Thu 17 Jul, 11:00 am-1:30 pm.East.
1
1
8
Being able to predict model behaviors before we train them has substantial value, but predicting downstream capabilities has proven harder than training loss. In this paper we explore why this is from the prospective of measurement design. Wed 16 Jul, 11 am-1:30 pm.East.
2
3
5
Looking for EleutherAI at #ICML2025? This thread is your guide to our research!. We've also recently started producing merch! If you're interested in a free EleutherAI laptop sticker track down @BlancheMinerva or find us at one of our poster sessions.
1
2
14
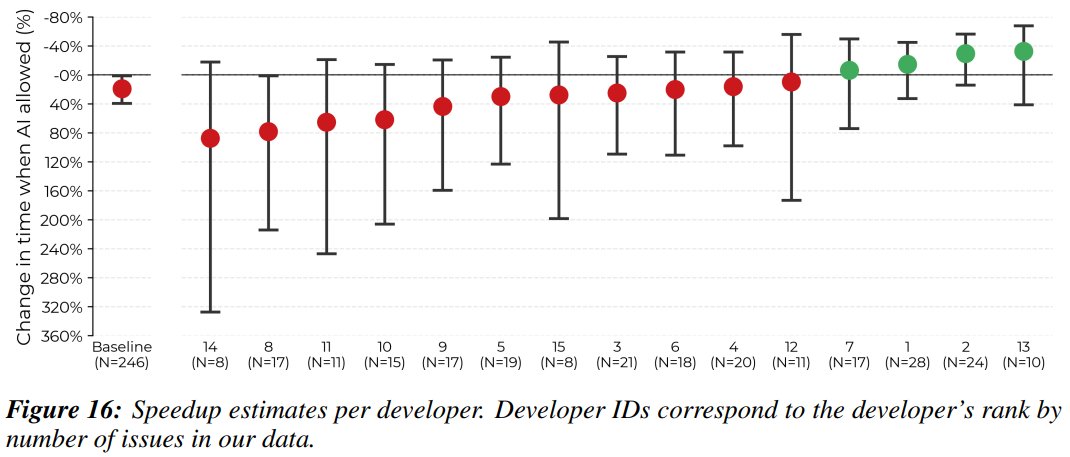
Our head of HPC was the researcher from the recent @METR_Evals study on AI-assisted coding that saw the biggest (tied) productivity boost from using AI in his coding. Hear his account and lessons about using AI to code more effectively here.

I was one of the 16 devs in this study. I wanted to speak on my opinions about the causes and mitigation strategies for dev slowdown. I'll say as a "why listen to you?" hook that I experienced a -38% AI-speedup on my assigned issues. I think transparency helps the community.
0
0
3
RT @linguist_cat: MorphScore got an update! MorphScore now covers 70 languages 🌎🌍🌏 We have a new-preprint out and we will be presenting our….
0
6
0
If you can't make it, no problem! All of our reading groups and speaker series upload to our YouTube. We have over 100 hours of content on topics from ML Scalability and Performance to Functional Analysis to podcasts and interviews featuring our team.

0
2
22
Her talk with be primarily drawing on two recent papers:. "BPE Gets Picky: Efficient Vocabulary Refinement During Tokenizer Training" "BPE Stays on SCRIPT: Structured Encoding for Robust Multilingual Pretokenization"

arxiv.org
Byte Pair Encoding (BPE) tokenizers, widely used in Large Language Models, face challenges in multilingual settings, including penalization of non-Western scripts and the creation of tokens with...
2
0
10