

Neil Houlsby
@neilhoulsby
Followers
4,229
Following
321
Media
42
Statuses
468
Professional AI researcher; amateur athlete. Senior Staff RS in the Google Deepmind, Zürich. Attempts triathlons.
Zurich, Switzerland
Joined April 2012
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
Diddy
• 537412 Tweets
الهلال
• 532436 Tweets
Alito
• 385282 Tweets
Flamengo
• 166722 Tweets
Peter
• 164474 Tweets
Corinthians
• 152047 Tweets
Cássio
• 112408 Tweets
Barron
• 91766 Tweets
رونالدو
• 59186 Tweets
デザフェス
• 51923 Tweets
#Kyrgyzstan
• 36751 Tweets
Gabi
• 34822 Tweets
#Smackdown
• 29867 Tweets
Bianca
• 22594 Tweets
كاس الملك
• 17707 Tweets
Cobasi
• 15556 Tweets
ムビナナ
• 14770 Tweets
the boy is mine
• 13618 Tweets
Dabney Coleman
• 13100 Tweets




















Pinned Tweet

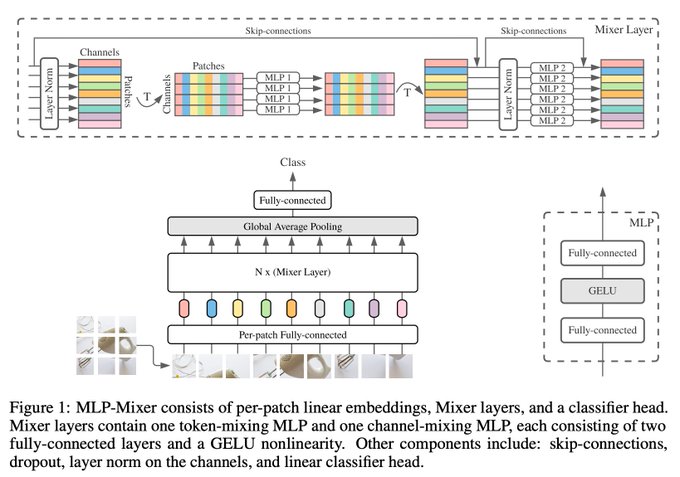
New paper from Brain Zurich and Berlin!
We try a conv and attention free vision architecture: MLP-Mixer ()
Simple is good, so we went as minimalist as possible (just MLPs!) to see whether modern training methods & data is sufficient...
17
218
993
An incredibly thorough-looking survey of Vision Transformers!
It only been just over a year since we published ViT. I thought it would be useful, but didn't imagine this much cool innovation would happen.
7
181
1K
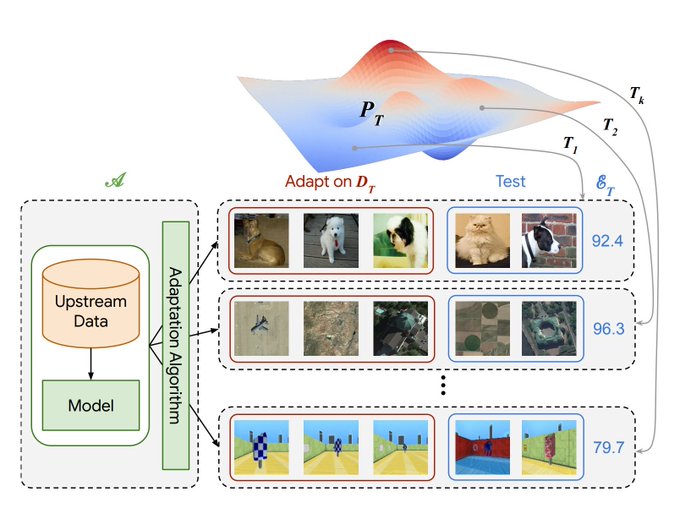
How effective is representation learning? To help answer this, we are pleased to release the Visual Task Adaptation Benchmark: our protocol for benchmarking any visual representations () + lots of findings in .
@GoogleAI
1
60
216
New paper from Brain Zürich!
A big challenge in vision is the large number of task types, often requiring specialist solutions.
UViM can be trained for any task, including complex annotations (e.g. Panoptic Segmentation), without architectural changes.

5
42
218
📢 Open role
Interested in ML/CV (inc. video & multimodal learning)? Open role for a Research Scientist in my team in Brain Zürich.
See my Scholar page to get an idea of our work, and the list of fantastic colleagues & collaborators in Google EMEA.
0
40
204
Code released to adapt BERT using few parameters. Can be used to adapt one model to many tasks. Catastrophic forgetting not included.

3
58
201
Shout out to similar ideas to MLP-Mixer being developed at Oxford!

0
22
199
Detect objects in your still life, or anything else for that matter! OWL-ViT---our zero shot detector---is now in 🤗.


OWL-ViT by
@GoogleAI
is now available
@huggingface
Transformers. The model is a minimal extension of CLIP for zero-shot object detection given text queries. 🤯
🥳 It has impressive generalization capabilities and is a great first step for open-vocabulary object detection!
(1/2)
7
267
1K
3
29
180
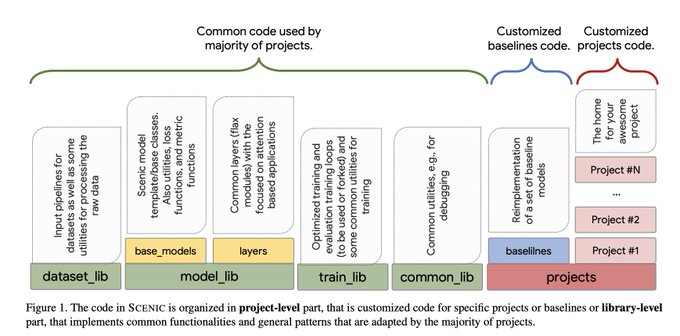
If you use JAX, try SCENIC. If not, try JAX, then SCENIC!

SCENIC: A JAX Library for Computer Vision Research and Beyond
abs:
github:
0
58
227
3
19
171
Combining two of the most popular unsupervised learning algorithms: Self-Supervision and GANs. What could go right? Stable generation of ImageNet *with no label information*. FID 23. Work by Brain Zürich to appear in CVPR.
@GoogleAI
#PoweredByCompareGAN
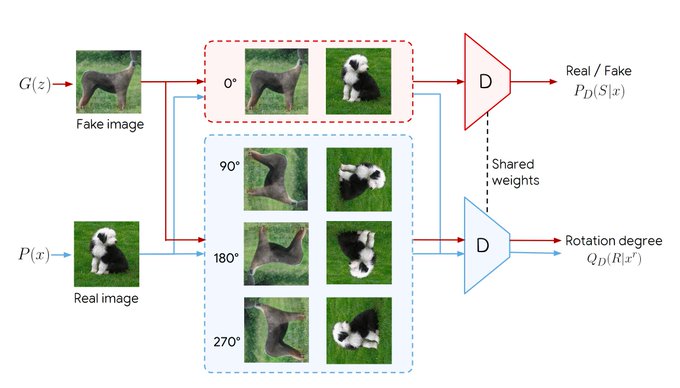
0
49
158
At CVPR?
Three papers from the Google Deepmind (formerly Brain) Vision team in in Berlin/Zürich/Amsterdam (+collaborators) there.
If interested in the work or the team, track down the authors!
4
38
151
Explorations into multimodal single-tower backbones!
A single MoE (LIMoE) accepts both images and text as input, and is trained contrastively.
MoEs are a great fit for single tower models, since they can use their experts to partition modalities appropriately.
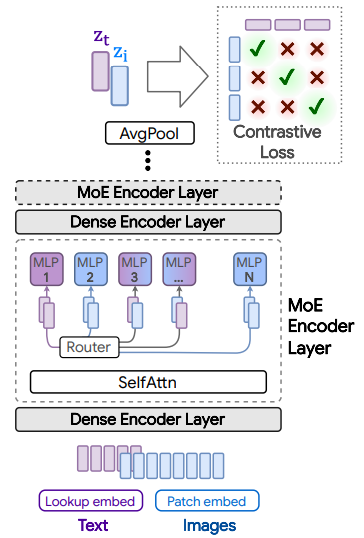
3
26
144
🥈at Ironman Switzerland!
Overwhelmed with the pace of AI development? An engaging hobby is a great way to stay enthusiastic.
For me, it's endurance training. Bonus: long rides are a perfect time to ruminate on research ideas!

18
0
136
Representation & transfer learning seems to work quite well on real-world object recognition. Big Transfer () improves the ObjectNet (a real-world test set) performance from 35% top-1 accuracy to 59%. [1/5]
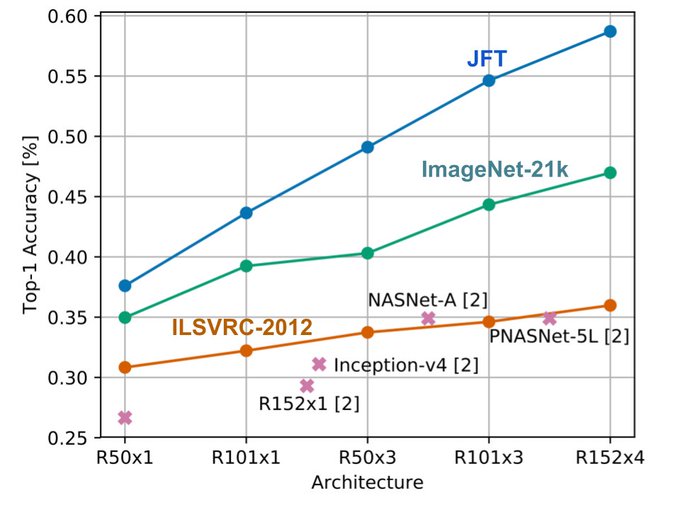
3
31
129
PaLI-X () continued the joint vision / language scaling approach from PaLI (using ViT-22B and UL2-32B), with an updated pre-training mix.
Aside from good benchmark numbers, a few results I found most intriguing…
2
34
127
It turns out that only a few parameters need to be trained to fine-tune huge text transformer models. Our latest paper is on arXiv; work
@GoogleAI
Zürich and Kirkland.
#GoogleZurich
#GoogleKirkland
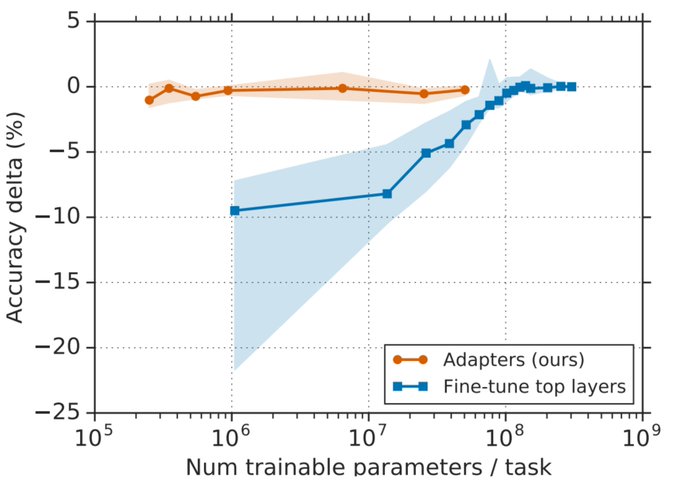
0
43
121
Been working with language-team colleagues to plug together our best ViTs with their awesome LMs, and co-train on image/text data.
The result, PaLI, works pretty well for VQA, Captioning, TextVQA, etc.
Some interesting things...
4
21
117
[2/3] Towards big vision.
How does MLP-Mixer fare with even more data? (Question raised in
@ykilcher
video, and by others)
We extended the "data scale" plot to the right, and with 3B images Mixer-L (green dashed line) seems to creep ahead ViT-L (green solid line)!
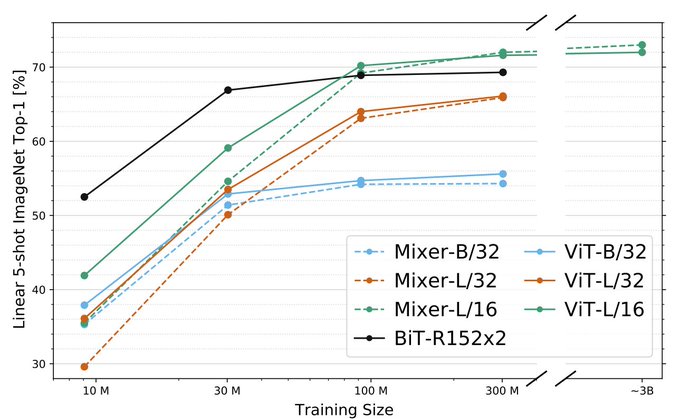
2
14
107
[3/3] Towards big vision
While dense models are still the norm, sparse MoE layers can work well too!
Large Vision-MoEs (15B params) can be trained to high performance relatively efficiently, and can even prioritize amongst patches (see duck).
...
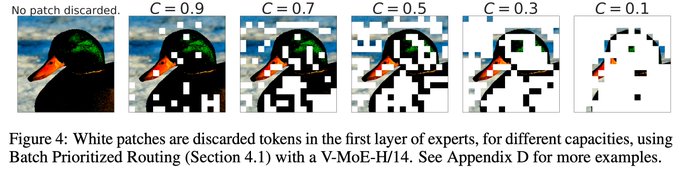
1
21
103
Soft MoE has produced some the largest improvements we have obtained since ViT vs. CNN: ViT-S inference cost at ViT-H performance!
Great idea from the team:
@joapuipe
@rikelhood
and
@_basilM
. Soft MoEs have the advantages of sparse Transformers, without many of the
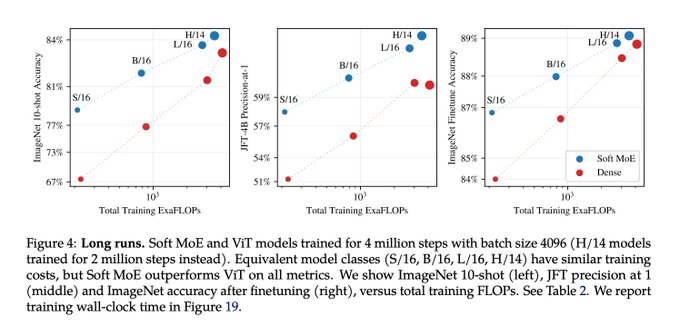

Introducing Soft MoE! Sparse MoEs are a popular method for increasing the model size without increasing its cost, but they come with several issues. Soft MoEs avoid them and significantly outperform ViT and different Sparse MoEs on image classification.
5
62
248
2
10
86
Nice stuff: With a simple design of just a single multimodal Transformer, and a relatively small model, Adept's Fuyu is approaching PaLI-X, which uses the very strong (and large) pre-trained ViT-22B image encoder.
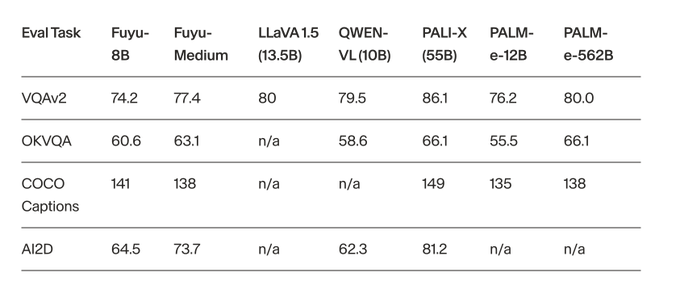

We’re open-sourcing a multimodal model: Fuyu-8B! Building useful AI agents requires fast foundation models that can see the visual world.
Fuyu-8B performs well at standard image understanding benchmarks, but it also can do a bunch of new stuff (below)
16
230
954
0
21
89
If you are attending NeurIPS, and interested in work from the Brain Team in EMEA on Computer Vision, here are some of our papers to check out.
Please feel free to reach out to the authors if you are interested in our work or team!
In no particular order…
1
8
83
Several requests for the slides/recording for our (
@XiaohuaZhai
,
@__kolesnikov__
, Alexey Dosovitskiy, myself) CVPR Tutorial "Beyond CNNs".
These are now linked from the tutorial website:

0
14
81
Check out OWLv2; leveraging large scale pre-training---which has been hugely potent for classification, captioning, & LMs---for object detection.
>40% (relative) performance improvement in the open-vocab setting.

Scaling Open-Vocabulary Object Detection
Proposes OWLv2, which achieves SotA open-vocabulary detection already at 10M examples and further large improvement by scaling to over 1B examples.

0
20
114
2
17
73
[1/3] Towards big vision.
Tips&tricks to squeeze (substantially) more performance and scale out of the classic ViT.
Characterization of the scaling properties, and a large (2B) ViT-G trained on tonnes of images (3B) that works pretty well (90+ INet)!
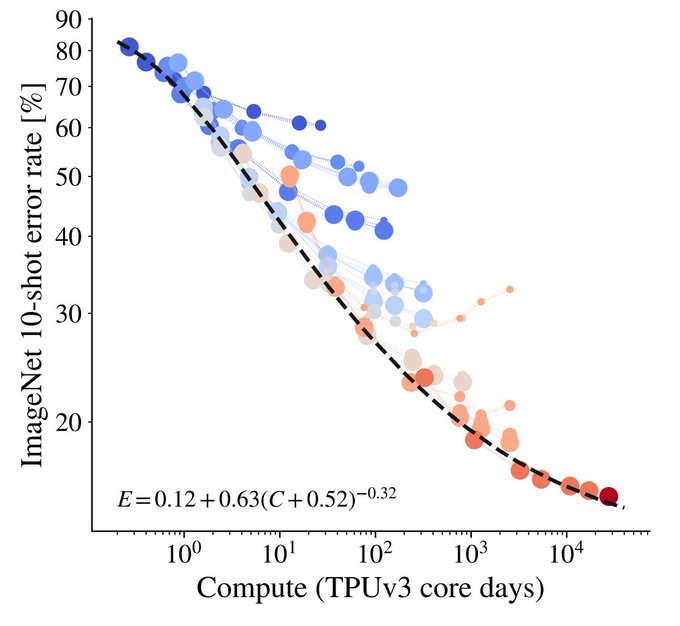
1
14
69
If anyone wants to chat about the Scaling ViT work / ViT in general (and is at CVPR), I will be at the poster this morning.
1
6
62
Get latest Flax Transformer. Set normalize_qk=True. Larger learning rates and bigger models possible!
See for details

TL;DR I was too lazy to keep a fork of MHA, and I was too tired of my exps blowing up due to too high LR.
I am still amazed how useful this is even for small models - I can pre-train [Na]-ViT with 1e-2 (previously it blew up at ~5e-3).
Try it out!
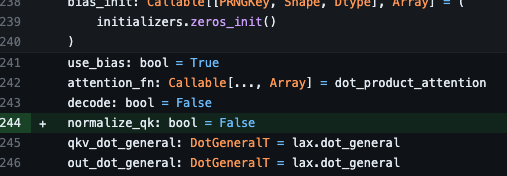
1
5
30
0
13
63
Vision Transformer models & code. Have fun! 😃

0
7
57
I had a great time at EPFL's AMLD on Gen AI.
If anyone is curious what the "two advances" are (plus a number of other cool talks), I believe the recordings will be made available on EPFL's YT channel in a few weeks.

#Track1
Let us now welcome
@neilhoulsby
before the coffee break. He will be presenting the recent advances in visual pretraining for LLMs.
#AMLDGenAI23

3
2
13
0
1
51
A large team effort from Brain EMEA and collaborators to train and evaluate a large Vision Transformer.
Many of us here believe that vision can be scaled successfully as LLMs have, and are making steps in that direction!

1/ There is a huge headroom for improving capabilities of our vision models and given the lessons we've learned from LLMs, scaling is a promising bet. We are introducing ViT-22B, the largest vision backbone reported to date:

12
134
802
1
6
49
For those interested in a high-level overview, a quick summary of our work on the Pathways Language Image model on Google ResearchBytes.

1
14
49

(V-)MoEs working well at the small end of the scale spectrum. Often we actually saw the largest gains with small models so it's a promising direction.
Also, the authors seem to have per-image routing working well, which is nice.
Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
paper page:
Sparse Mixture-of-Experts models (MoEs) have recently gained popularity due to their ability to decouple model size from inference efficiency by only activating a
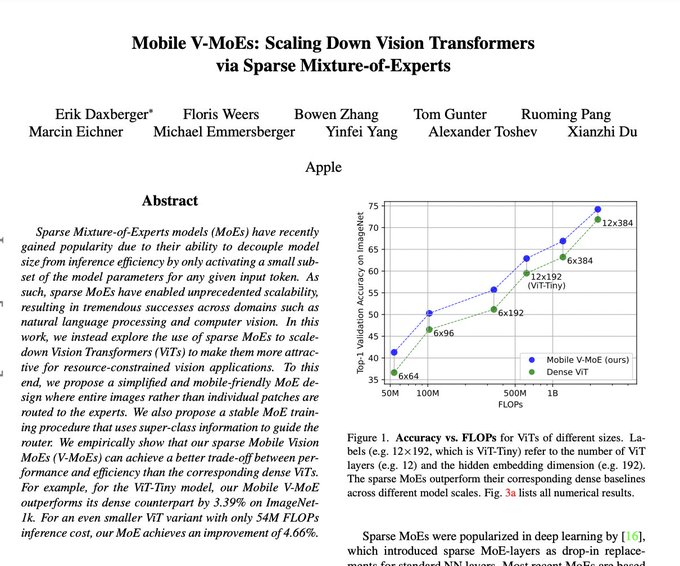
2
58
241
1
5
47
Lots of work still to do to make Sparse MoEs mainstream for vision!
If you want to get involved, some JAX code & checkpoints to get started:
Accompanying blog with the high-level idea:
1
5
46
Pseudo-labelling+object detection+🤗
Excited to share that
@Google
's OWLv2 model is now available in 🤗 Transformers! This model is one of the strongest zero-shot object detection models out there, improving upon OWL-ViT v1 which was released last year🔥
How? By self-training on web-scale data of over 1B examples⬇️
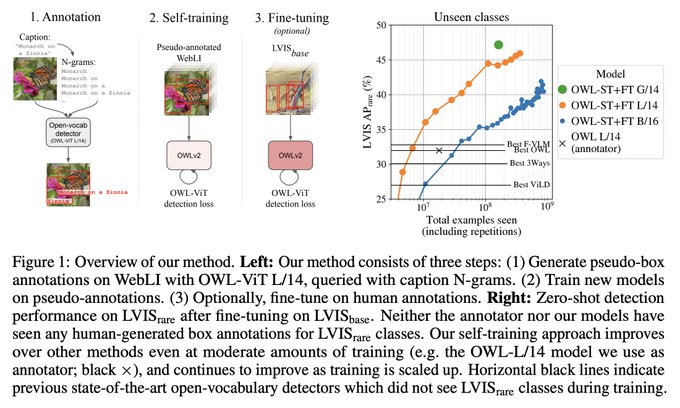
4
58
293
0
5
44
Continued improvements to BeiT. It's satisfyingly simple, and the results are now look really impressive!
(Although not sure I am a massive fan of the radar plot, not sure the areas are entirely reflective of the relative performances across many tasks).
Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
abs:
github:
multimodal foundation model, which achieves sota performance across a wide range of vision and vision-language benchmarks
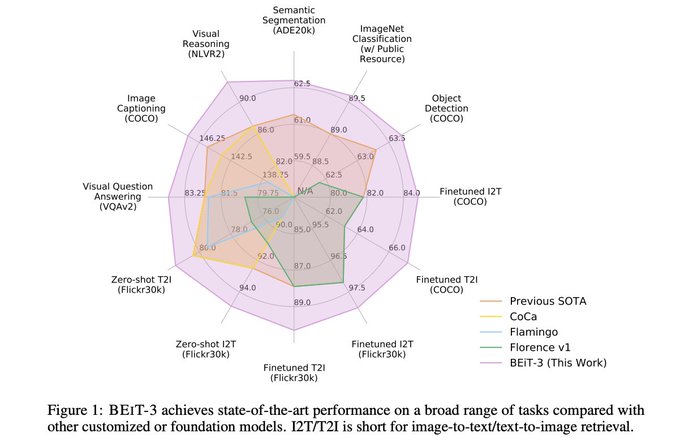
3
104
423
0
7
43
ViT is overdue a modern LM-style input pipeline to exploit Transformer's flexibility to combine inputs.
NaViT (Native ViT) trains on sequences of images of arbitrary resolutions and aspect ratios.
There is lots to unpack, see Mostafa's thread!
A feature that I particularly
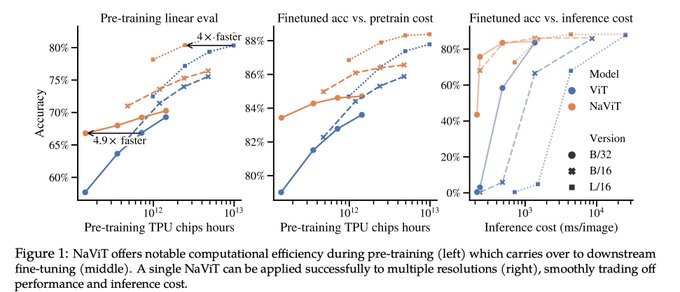
1/ Excited to share "Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution". NaViT breaks away from the CNN-designed input and modeling pipeline, sets a new course for ViTs, and opens up exciting possibilities in their development.
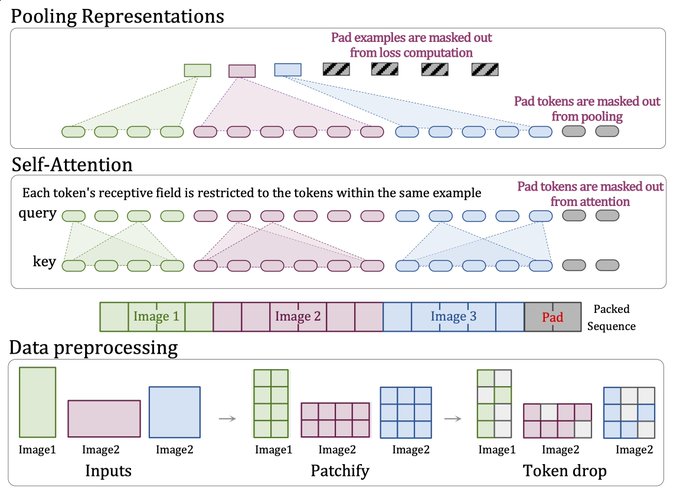
13
152
621
1
4
43
A very nice study, thanks for doing it!
I feel that this paragraph "ViT's benefit more from scale" may give some clue as to why vanilla ViT endures, despite more complex architectures getting better results here.
For me, the key finding of ViT was the nice scaling trends, and


🚨Excited to announce a large-scale comparison of pretrained vision backbones including SSL, vision-language models, and CNNs vs ViTs across diverse downstream tasks ranging from classification to detection to OOD generalization and more! NeurIPS 2023🚨🧵
6
93
416
2
3
42
This continues our team’s work in vision, transfer, scalability, and architectures. As always, pleasure to work with a great team:
@tolstikhini
,
@__kolesnikov__
,
@giffmana
,
@XiaohuaZhai
,
@TomUnterthiner
,
@JessicaYung17
,
@keysers
,
@kyosu
,
@MarioLucic_
, Alexey Dosovitskiy
1
4
40
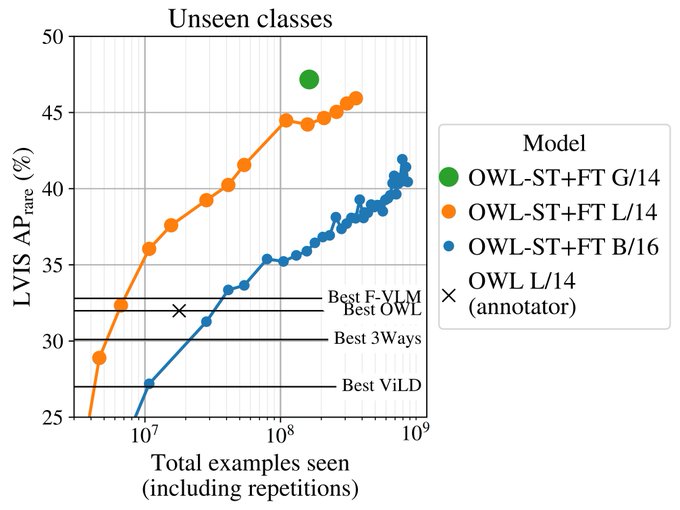
OWL-ViTv2, state-of-the-art open-vocab object detector, is now open-sourced.

We just open-sourced OWL-ViT v2, our improved open-vocabulary object detector that uses self-training to reach >40% zero-shot LVIS APr. Check out the paper, code, and pretrained checkpoints: . With
@agritsenko
and
@neilhoulsby
.
0
25
90
0
4
37
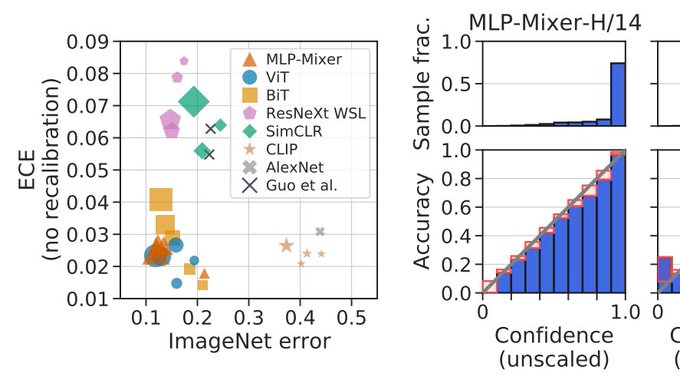
I feel there is some religion when it comes to the question of "do big nets give reasonable confidence estimates?"
Work from Matthias and colleagues provides practical answers, carefully quantifying the calibration, including on OOD data, of modern vision networks.
New paper: Revisiting the Calibration of Modern Neural Networks (). We studied the calibration of MLP-Mixer, Vision Transformers, BiT, and many others. Non-convolutional models are doing surprisingly well! 1/5
2
73
305
0
4
35
Mixer consists of MLPs applied in alternation to the image patch embeddings (tokens) and feature channels.
With pre-training, Mixer learns really good features, and works well for transfer (e.g. 87.9% ImageNet), sitting alongside even the best CNNs and Vision Transformers! ...
1
1
36
Very cool to see VLMs working in the real world.
Huge shout out to
@m__dehghani
@_basilM
@JonathanHeek
@PiotrPadlewski
, Josip Djolonga, and collaborators for providing the "eyes" of the robot (via ViT-22B / PaLI-X).

Computers have long been great at complex tasks like analysing data, but not so great at simple tasks like recognizing & moving objects. With RT-2, we’re bridging that gap by helping robots interpret & interact with the world and be more useful to people.
16
113
711
0
7
35
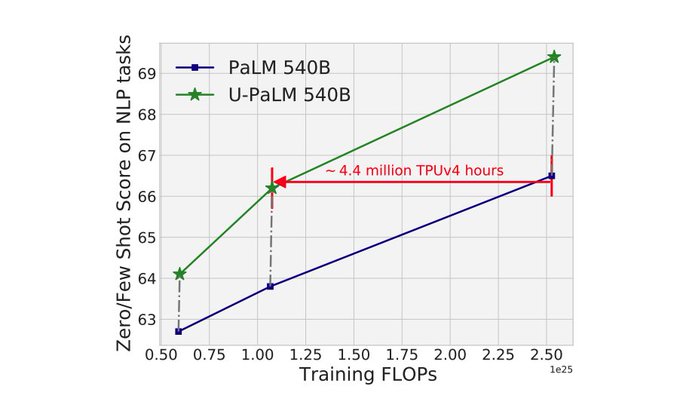
Extremely impressive LM performance from Yi, Mostafa, and colleagues via (cost-effective) upcycling of a PaLM model using UL2's MoD training objective.
1
4
34
Interested in, or working on, architecture designs of the future? Conditional compute, routing, MoEs, early-exit, sparsification, etc. etc.
Consider checking out/submitting to our ICML 2022 Workshop on Dynamic Neural Networks (July 22nd).


Announcing the 1st Dynamic Neural Networks (DyNN) workshop, a hybrid event
@icmlconf
2022! 👇
We hope DyNN can promote discussion on innovative approaches for dynamic neural networks from all perspectives.
Want to learn more?
1
27
93
1
6
32
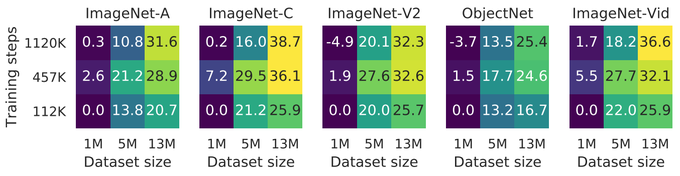
If you are interested in the important questions in vision, like "can my big SOTA model recognize a koala, flying upside-down, in the mountains?", and many others, you might be interested in our new paper:


I’m excited to showcase our recent preprint on transferability and robustness of CNNs, where we investigate the impact of pre-training dataset size, model scale, and the preprocessing pipeline, on transfer and robustness performance.
@GoogleAI
2
33
150
1
4
31
Check out PaLM-E (Embodied), feat. ViT-22B, at ICML.

And a few works w/ some of my collaborators:
@DannyDriess
will present PaLM-E, a language model that can understand images and control robots, Tue 2 pm poster
#237
:
Video here:
1
7
18
0
2
26
Great work from Elias figuring out optimal scaling for large sparse models.
I find particularly intriguing that sparsity unlocks a (half-)plane of optimal models on the compute/size axes. While regular dense Scaling Laws define only a single line of optimal models (for a given
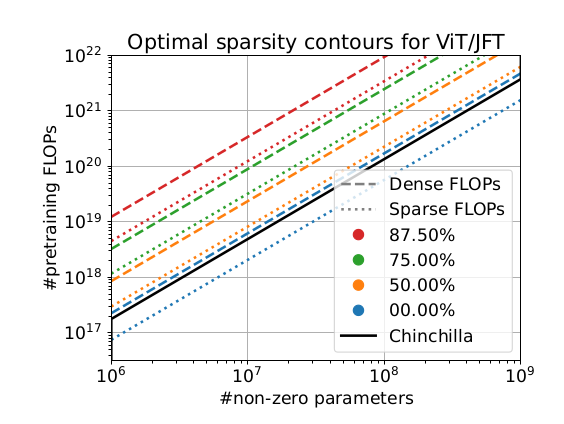

Excited to share our work "Scaling Laws for Sparsely-Connected Foundation Models" () where we develop the first scaling laws for (fine-grained) parameter-sparsity in the context of modern Transformers trained on massive datasets. 1/10
3
26
128
1
2
26
IMO, training data selection for DL is a rather challenging setting to get active learning working in practice (pool-based, little time for evaluation of acquisition fn).
So rather impressive that Talfan, Shreya, Olivier and others got it working so well.

So excited to announce what we've been working on for the past ~year or so:
Active Learning Accelerates Large-Scale Visual Understanding
We show that model-based data selection efficiently and effectively speeds up classification- and multimodal pretraining by up to 50%
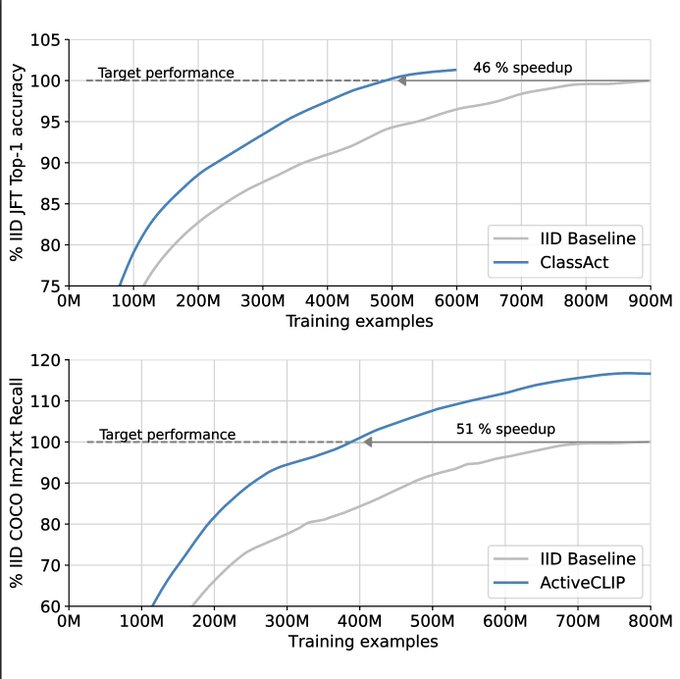
9
76
381
0
2
25
More back-and-forth between major architecture classes! Now in NLP. Will be interesting to see what crystallizes out in a few years time.

Are pre-trained convolutions better than pre-trained Transformers?
Check out our recent paper at
#ACL2021nlp
#NLProc
😀
Joint work with
@m__dehghani
@_jai_gupta
@dara_bahri
@VAribandi
@pierceqin
@metzlerd
at
@GoogleAI
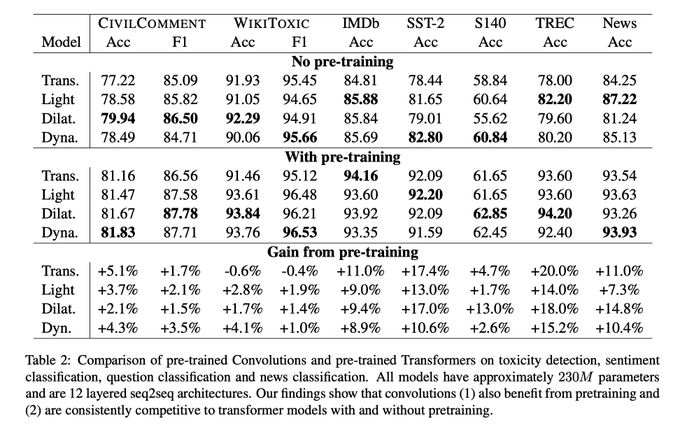
3
37
190
0
1
24
These titles are getting out of hand! (or perhaps they always were). Nice to see some (friendly) competition between architecture classes driving up performance of both.
DeiT III: Revenge of the ViT
abs:
on Image classification (ImageNet-1k with and without pre-training on ImageNet-21k), transfer learning and semantic segmentation show that procedure outperforms by a large margin previous fully supervised training recipes
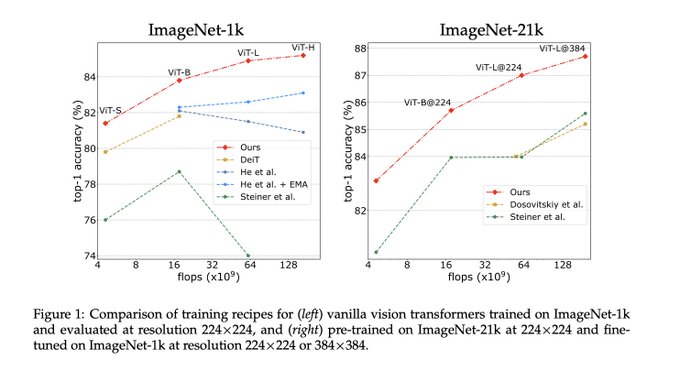
0
36
178
0
1
24
Mostafa spelling out the next year's research roadmap.
NaViT () sets us free from square boxes and lets us think outside the box! Let creativity flow and go for the natural designs we've always wanted in ViTs.
I share a few cool ideas that are made possible with NaViT:
1
20
108
0
3
24
Heading to Paris, and looking forward to ICCV next week.
Feel free to send me an email if you will be there and like to talk about scalbility, vision/language pre-training, MoEs, or Google Deepmind in Europe in general!
0
1
23
Looking forward to this workshop on MoEs, Sparsity, Adaptive Compute, and all the good stuff, later today and tomorrow. Feel free to stop by!
Youtube stream:
Agenda:


Next Tuesday & Wednesday we'll be hosting a workshop on Sparsity & Adaptive Computation! More than 30 speakers from Google, other industry labs & many universities will share their views on scaling language & vision models. Keynotes by
@JeffDean
& Dave Patterson! See agenda below

2
25
131
0
5
22
Multimodal from the ground up!

I’m very excited to share our work on Gemini today! Gemini is a family of multimodal models that demonstrate really strong capabilities across the image, audio, video, and text domains. Our most-capable model, Gemini Ultra, advances the state of the art in 30 of 32 benchmarks,


276
3K
13K
0
0
23
Objective often matters more than architecture. UL2 uses a mixture of denoisers objective, and allows one to switch between different downstream modes (finetuning, prompting) to get the best of both worlds.
"Whether to go with a decoder-only or encoder-decoder transformer?"
It turned out that this question on the architecture of the model is not actually that important!
You just need the right objective function and a simple prompting to switch mode during pretraining/finetuning.
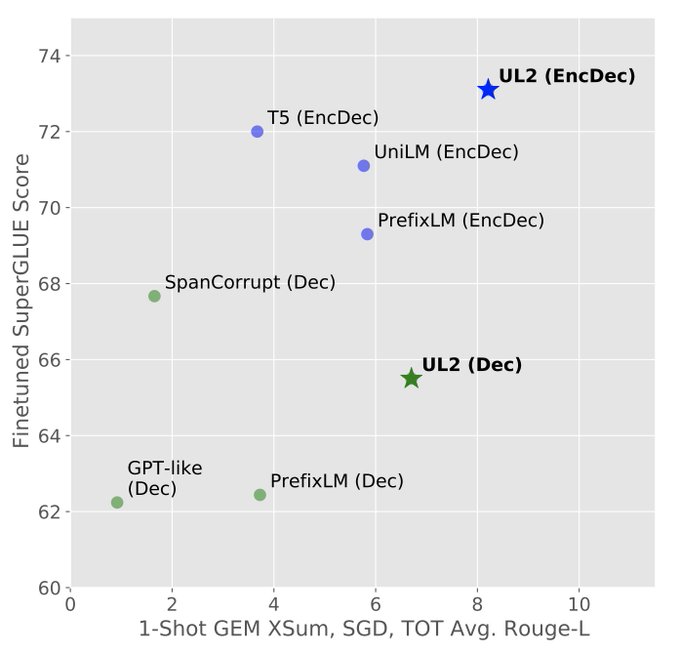
1
45
209
0
6
22
Curious application of visual classification in which CNNs and ViT are compared. Although poorer in terms of max accuracy, ViT appears more robust. More interesting back and forth between the two architecture classes.

Convolutional Neural Network (CNN) vs Visual Transformer (ViT) for Digital Holography
by Stéphane Cuenat et al.
#DeepLearning
#ConvolutionalNeuralNetwork
0
5
8
0
2
19
@ylecun
Thanks for the interest Yann! Semantics aside, would love to know your thoughts on the paper. Surprised such a degenerate cnn (i.e. alternating pointwise MLPs) could learn really good features for classification? Expect it to work at all? Or need more data/compute/tricks?
2
0
19
Curious.
Exploring Corruption Robustness: Inductive Biases in Vision Transformers and MLP-Mixers
pdf:
github:
vision transformer architectures are inherently more robust to corruptions
than the ResNet-50 and MLP-Mixers
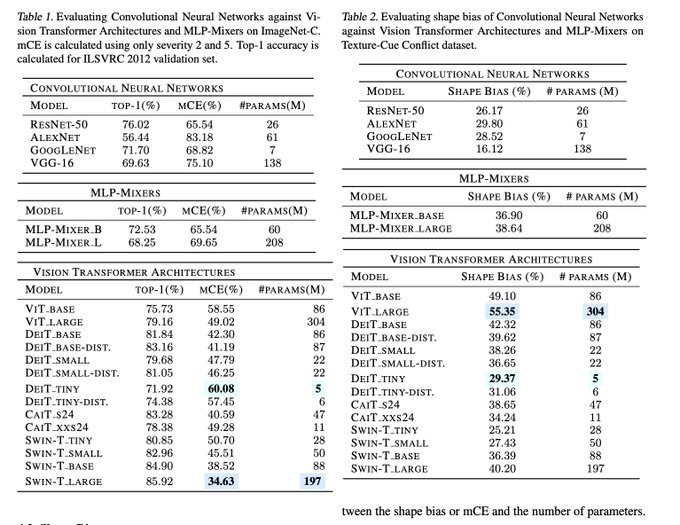
3
21
88
0
2
20
Tired of short, understand-everything-after-a-5-minute-skim, ML conference papers? See the recent work from
@obousquet
and colleagues for some serious bedtime reading.
@ykilcher
video please.
0
1
20
Study on converting existing Transformer checkpoints (there are many around) into MoEs to save on training cost from Aran,
@jamesleethorp
and team, plus us here in Brain EMEA.
We have released "Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints"!
Our method converts a pretrained dense model into a MoE by copying the MLP layers and keeps training it, which outperforms continued dense training.
(1/N)
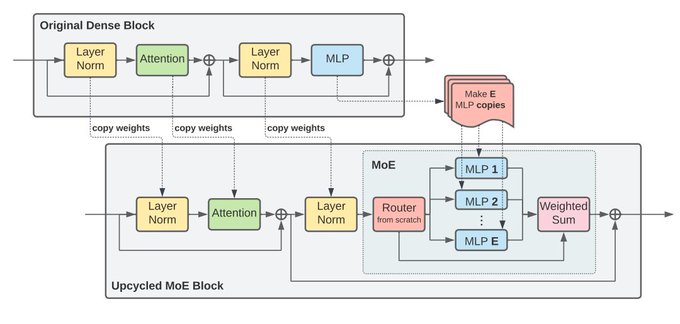
11
82
390
0
1
20
@karpathy
One small, but curious, difference with depthwise conv is parameter tying across channels. Slightly surprising (to me at least) that one can get away with it, but a really useful memory saving due to the large (entire image) receptive field.
1
1
20
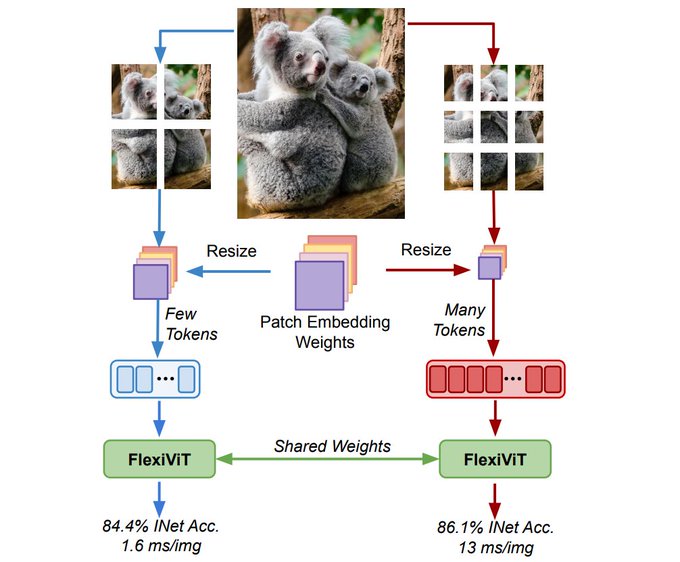
FlexiViT []
With little/no overhead, one can train a ViT that works with different patch sizes, permitting an inference-time trade-off of cost/quality, and other goodies.
0
2
19
@giffmana
On this topic, its funny how some things are too well known to cite (they are just part of common language, and often lower-cased), but not others. Adam really hit a sweet spot, being nearly ubiquitous and cited in most usages. My guess is its partialy in the name.
1
0
19
@agihippo
What do you mean? "The laser-focused anticipatory specialty allows decoders to achieve superior language mastery." clearly explains everything.
3
0
18
Interesting that 3/4 runners-up to the TMLR Outstanding Cert are on vision (and ViT based ;) )
The winner, Gato, I guess is also on vision (but it's also on everything else!)
0
0
18
With all the excitement around Gemini, you could be forgiven for missing GiVT!
A really nice result from
@mtschannen
@mentzer_f
and
@CianEastwood
showing that you can model real-valued VAE representations to perform conditional image generation on-par or better than the

I'm not much of a meme-creator, but for this one I couldn't resist...

3
10
55
0
4
18
A nice summary from Carlos.
Sparsity is one of the most promising areas in deep learning (tokens follow different routes in the model). However, these discrete decisions are messy to handle & optimize. Today we introduce Soft-MoE. The idea is simple: Don't route tokens, route linear combinations of them.

4
49
347
0
0
18
ImageNet accuracy is not the end of the story for image classifiers --- this library contains lots of robustness, stability, and uncertainty metrics all in one place! Examples provided in all your favourite languages, and TF.
I'm happy to announce that we have open-sourced our suite of metrics for out-of-distribution generalization and uncertainty quantification. It is framework independent and we provided TF, PyTorch and JAX examples.
5
178
1K
1
1
18
Into model compression? Here's a challenge...

Today we're releasing all Switch Transformer models in T5X/JAX, including the 1.6T param Switch-C and the 395B param Switch-XXL models. Pleased to have these open-sourced!
All thanks to the efforts of James Lee-Thorp,
@ada_rob
, and
@hwchung27
19
208
1K
0
2
17
If you're in Amsterdam and interested in machine learning, check out the AI in the Loft event, hosted by the Brain team there. Weds 11th May.
Really excited that after almost two years, we are resuming the "AI in the Loft" events. For the next edition, Wednesday 11 May, we will have
@bneyshabur
as our speaker.
Please RSVP at

2
11
76
0
1
18
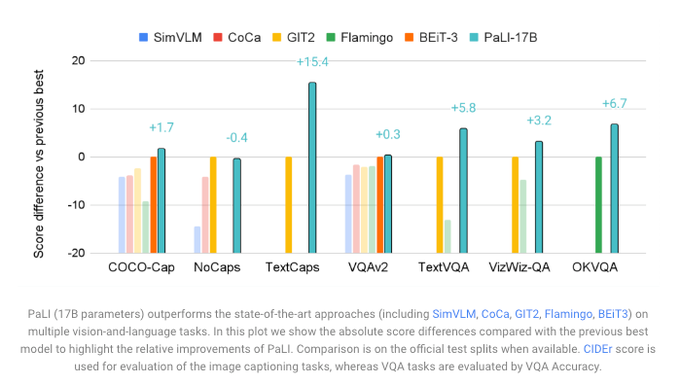
A "few" extra vision params go a long way.
@XiaohuaZhai
@giffmana
@__kolesnikov__
trained a larger ViT (ViT-e). Although it adds only +13% params (PaLI-15B -> PaLI-17B), the boost is enormous.
Lots of headroom for visual representation learning in these "open world" tasks.
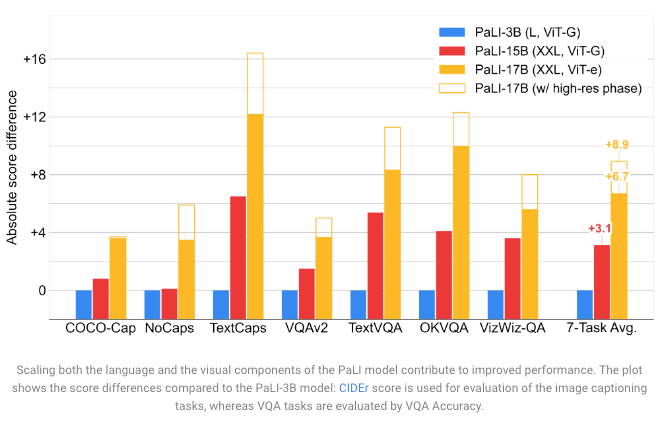
1
1
16
All-MLP architecture and MoE layers, what is not to like!
Interesting (and nice) that a simple static (non-learned and input independent) routing works well for the token-mixing layers.
Efficient Language Modeling with Sparse all-MLP
Sparse all-MLP improves LM PPL and obtains up to 2x improvement in training efficiency compared to Transformer-based MoEs as well as dense Transformers and all-MLPs.
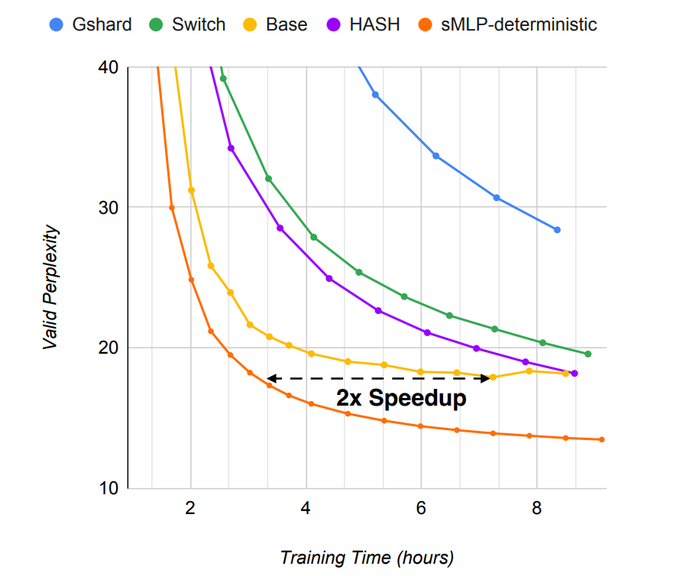
1
29
143
0
1
17
With judicious refinement of modern tricks, and scale, we can push SOTA (on VTAB, ImageNet, Cifar, etc.) using classic transfer learning, without excessive complexity. Works surprisingly well even with <=10 downstream examples per class.

We distill key components for pre-training representations at scale: BigTransfer ("BiT") achieves SOTA on many benchmarks with ResNet, e.g. 87.8% top-1 on ImageNet (86.4% with only 25 images/class) and 99.3% on CIFAR-10 (97.6% with only 10 images/class).
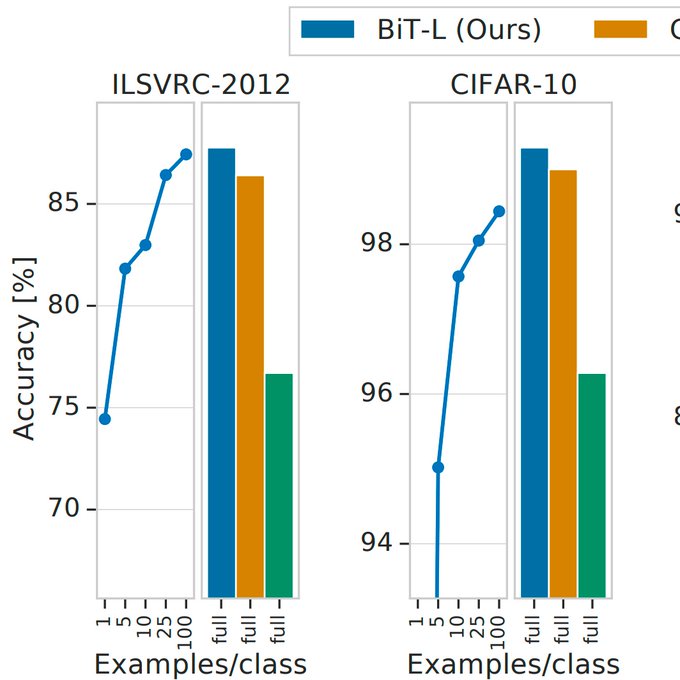
2
45
155
0
4
16
Workshop on Sparsity & Adaptive Computation kicking off now!
0
1
15
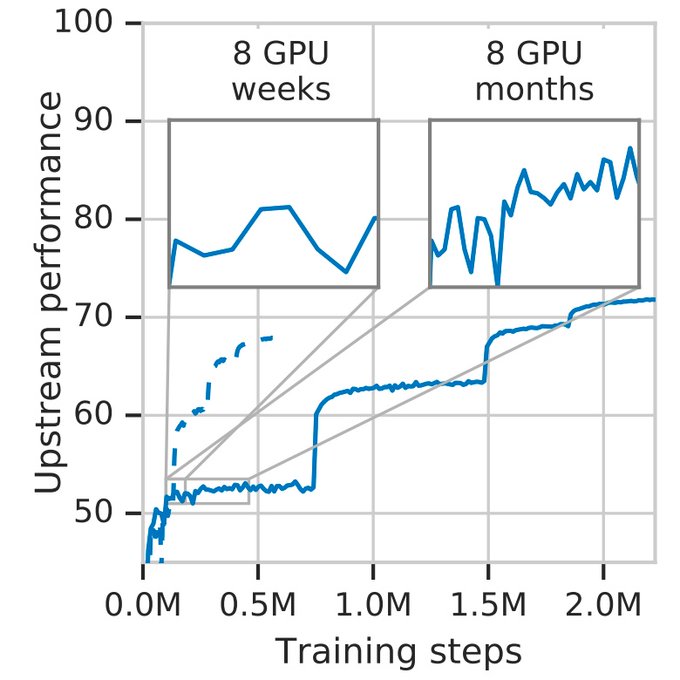
Distil yourself a fine vintage of ResNet50 with the below recipe.

Wondering how to distill big vision models?
Check our recipe: a good teacher is patient and consistent!
Thanks to patience and consistency, we obtained the best ever ResNet-50 on ImageNet, of 82.8% accuracy without tricks.
Paper:
1
19
95
0
4
16
Counting was not an explicit pre-training task, but performance really started to take off around 17B+ parameters, especially on the "complex" variety (counting some described subset of objects).

1
0
15
Emergent perceptual similarity of deep nets for vision behaves quite differently than most downstream tasks.
This study by
@mechcoder
in Brain Amsterdam digs into this effect. Still lots of questions remain though!

Would you like to learn more about a domain where better ImageNet classifiers transfer worse? Check out our TMLR paper: Do better ImageNet classifiers assess perceptual similarity better? ()
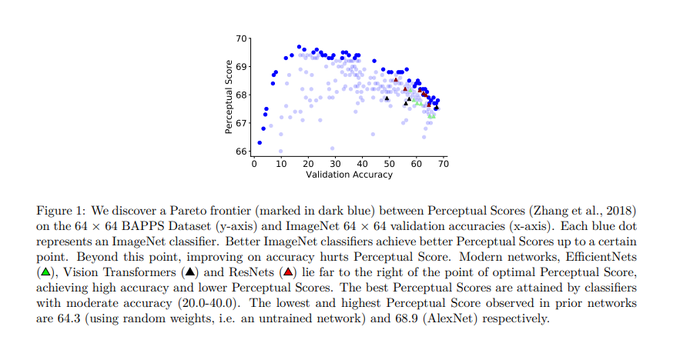
2
12
49
0
1
14
Nice organization of the parameter-efficient transfer space.
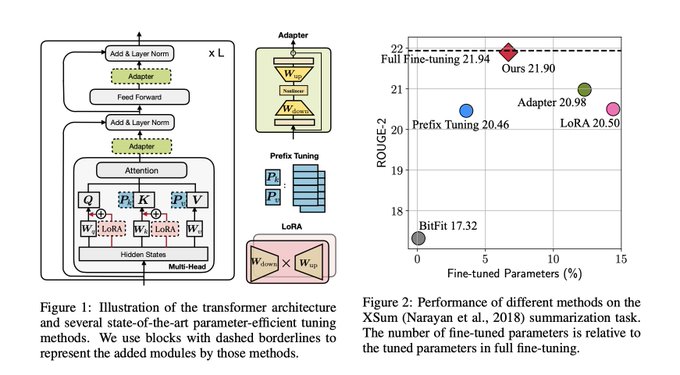
0
2
14
Finally, multitask finetuning, without fancy task-specific prompting, was almost on par with tuned task-specific finetuning. Quite encouraging for potential future work on massively-multitask finetuning of V&L models.
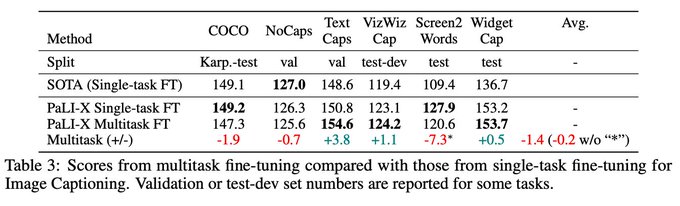
0
0
14
Fine-tuning look out, adapters are on the rise.

AdapterHub: A Framework for Adapting Transformers (demo)
The framework underlying MAD-X that enables seamless downloading, sharing, and training adapters in
@huggingface
Transformers.
w/
@PfeiffJo
@arueckle
@clifapt
@ashkamath20
et al.
0
6
26
0
4
14
In-context / few-shot captioning worked in diverse scenarios absent (or present only in minute quantities) in the training mix.
In this e.g., PaLI-X must infer the location from the prompt, respond in the appropriate language, and combine with "world knowledge".
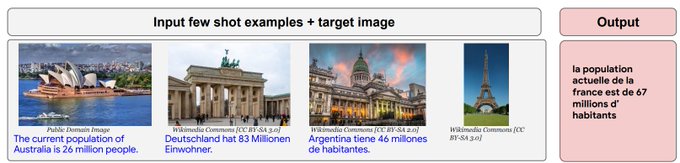
1
0
14
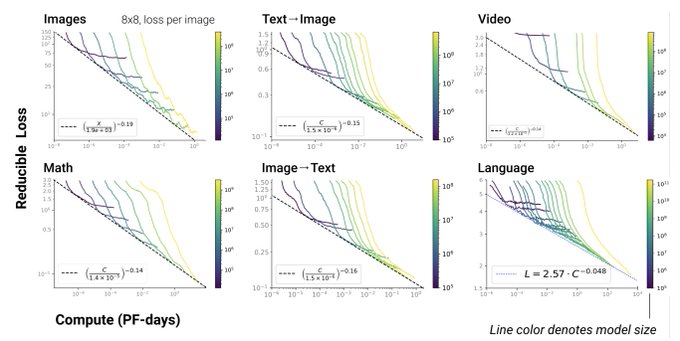
"a 32x32 image is worth only about 2-3 words"
So a reasonable-sized 320x320 image is worth ~256=16x16 words (). Adds up.
Scaling Laws for Autoregressive Generative Modeling
- Autoregressive Transformer follows robust power law w/ the same model size scaling exponent over various modalities.
- Fine-tuning a pretrained model follows a similar power-law.
1
15
93
1
2
14
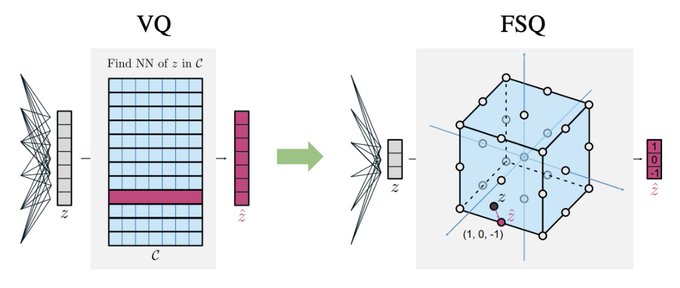
VQ benefits, without the hassle!
New paper! We ask: How important is VQ for neural discrete representation learning? 🤔
I always felt it should be possible to “absorb” the VQ on top of a deep net into the net and use a simple grid-based quantization instead, without sacrificing much expressivity.
Summary 🧵👇
7
59
354
0
1
14
Mitigating the risk of extinction from climate change should be a global priority alongside other societal-scale risks...
To use AI, evaluation is a key first step, great to see work on this from Jannis and colleagues!

0
2
14
@__kolesnikov__
Maybe we not make this clear enough in the papers! Transfer is cheap, cheaper than training even the most efficient architecture from scratch. And it works on datasets much smaller than ImageNet. And the weights are public.
1
3
13
Lucas showed me a nice paper that successfully transfers pre-trained image archs to (simulated) control environments:
"The Unsurprising Effectiveness of Pre-Trained Vision Models for Control"
Pretty cool; does anyone know of any other similar successes?
4
0
13
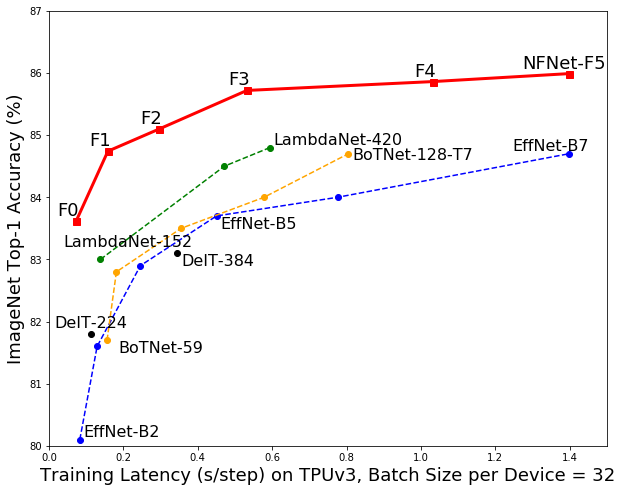
ResNets making a comeback on Vision Transformers!
While nice ImageNet numbers tend to correlate with other tasks, would be nice to see at least one other dataset to know how much of the gain is due to task-specific tricks/tuning.
(but overall the paper appears really thorough)

Introducing NFNets, a family of image classification models that are:
*SOTA on ImageNet (86.5% top-1 w/o extra data)
*Up to 8.7x faster to train than EfficientNets to a given accuracy
*Normalizer-free (no BatchNorm!)
Paper:
Code:
16
335
1K
0
0
13
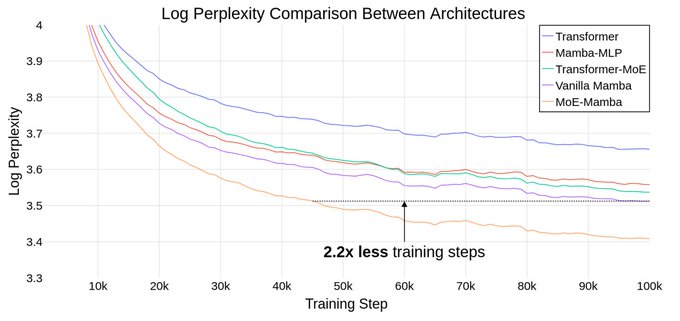
This work has nice "a good idea is to combine two previous good ideas" vibes.
Although somewhat preliminary, looks pretty promising. Various cool MoE advances coming from this lab 🔎
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
Reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer
7
90
521
0
7
13
It was satisfyingly straightforward to add new tasks after the initial setup was built.
I think this is a really cool recipe that enables visual transfer to/between many different tasks.
Work with
@__kolesnikov__
,
@ASusanoPinto
,
@giffmana
,
@XiaohuaZhai
,
@JeremiahHarmsen
0
1
12
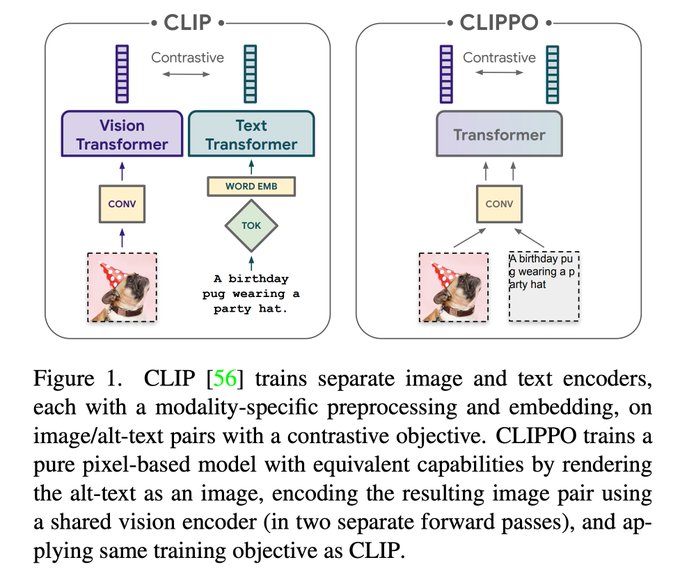
CLIPPO []
Demonstrates a surprising (to us) result that a single tower that takes only pixels as input (no tokenization), trained CLIP-style, gets competitive performance on language understanding and vision.

2
4
12
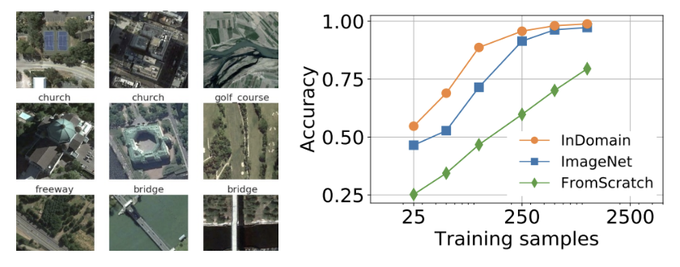
Interested in visual representation learning, but tired of ImageNet, Cifar, & VOC? Remote Sensing is a research area with many important applications. To dig deeper check out our paper with
@neu_maxim

We've looked into representation learning for
#RemoteSensing
with different datasets and fine-tuning using in-domain data. See paper with datasets and models included 🔋: with
@ASusanoPinto
,
@XiaohuaZhai
and
@neilhoulsby
.
1
11
21
0
1
12
Simple tweak to ViT from
@mechcoder
. Worth a try.
While we await GPT-4 which is expected to have a trillion parameters, here are 3072 parameters, that can make your Vision Transformer better.
Paper:
Joint work w/
@neilhoulsby
@m__dehghani

3
11
153
0
0
12
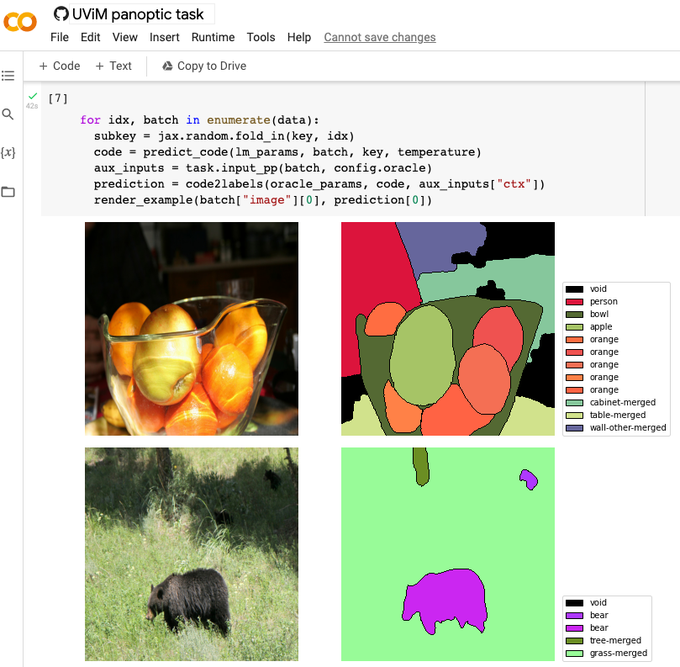
UViM available now on big_vision!

We have opensourced UViM models and complete training/inference/eval code. You can now train new models yourself and explore the released models (and UViM guiding codes) in the interactive colabs. All available at .
UViM paper: .
3
47
212
0
2
11
For object detection, performance on common objects was reasonable, but relatively, rare objects performed much better.
Concepts not explicit in the OD mix were handled: left vs. right, OCR, singular vs. plural, and multilingual. Encouraging positive transfer from pre-training.

1
0
11
And here is the link I forgot to add earlier:
0
1
11
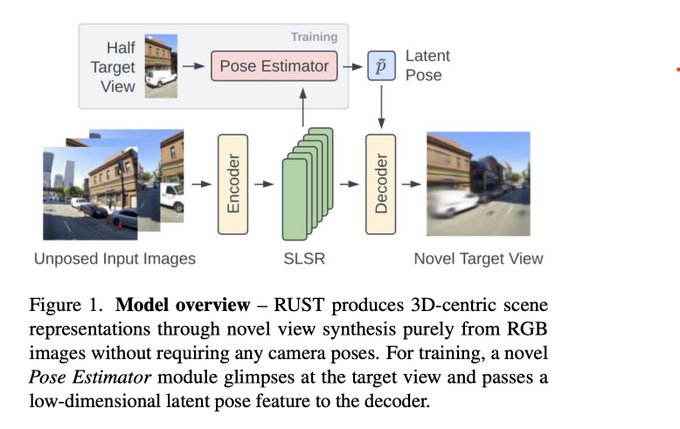
RUST []
The REALLY Unposed Scene Representation Transformer enables novel view synthesis without posed data through a nice trick where a latent pose encoder can peak at the target view to infer the camera position.
1
1
11
Of course, such scale is not yet widely available, and we are privileged to be able to perform and share such experiments.
But with public datasets and compute only growing, this might give us some glimpse into the model designs of the future.
1
0
11
A nice approach to adaptive computation from
@XueFz
taking advantage of sequence length flexibility in Transformers.

1/ Introducing AdaTape: an adaptive computation transformer with elastic input sequence! 🚀
* Flexible computation budget via elastic sequence length
* Dynamic memory read & write for adaptable input context
* Direct adaptive computation enhancement of input sequences
2
24
142
0
2
11
These Large LMs are large, but Large Vision Models are catching up.
Check out the team's blog on ViT-22B for more.
Quick summary of our recent work on scaling Vision Transformers - solving stability issues, making training more efficient and cool results:
1
8
33
0
2
11