
Piotr Padlewski
@PiotrPadlewski
Followers
1,616
Following
327
Media
150
Statuses
787
Chief Meme Officer @ , ex-Google Deepmind/Brain Zurich
Zurich, Switzerland
Joined October 2015
Don't wanna be here?
Send us removal request.
Explore trending content on Musk Viewer
#RafahOnFıre
• 1799654 Tweets
Memorial Day
• 687766 Tweets
Christian
• 138001 Tweets
Cristiano Ronaldo
• 133056 Tweets
Bill Walton
• 132715 Tweets
#النصر_الاتحاد
• 90440 Tweets
İsrail
• 83104 Tweets
دوري روشن
• 57166 Tweets
Alejandra del Moral
• 52971 Tweets
كاس الملك
• 48219 Tweets
WE LOVE YOU JUNGKOOK
• 43963 Tweets
ابها
• 41747 Tweets
WE LOVE YOU TAEHYUNG
• 39773 Tweets
Arturo
• 37278 Tweets
#KingsWorldCup
• 36580 Tweets
الدوري السعودي
• 36508 Tweets
الدوري الذهبي
• 31410 Tweets
التعاون
• 29604 Tweets
大雨警報
• 23892 Tweets
الهداف التاريخي
• 19020 Tweets
رامي ربيعه
• 17592 Tweets
Amine
• 16390 Tweets
الرقم القياسي
• 14275 Tweets
Papa Francesco
• 12506 Tweets
جيسوس
• 12288 Tweets
الدون
• 11357 Tweets
الموسم القادم
• 11238 Tweets
سافيتش
• 10180 Tweets




















Pinned Tweet

For anyone wondering how to train model better than gpt-4-0613:

Along with Core, we have published a technical report detailing the training, architecture, data, and evaluation for the Reka models.


2
62
371
5
22
210
Today was my last day at Google Brain/Deepmind.
Really grateful for amazing colleagues.
Learned so much from closely working on Pathways, ViT-22B, PaLI, NaViT and Gemini with
@m__dehghani
,
@neilhoulsby
,
@_basilM
, Xi and others.
The team terminated me pretty well today :)




18
4
493


The GOAT of tennis
@DjokerNole
said: "35 is the new 25.” I say: “60 is the new 35.” AI research has kept me strong and healthy. AI could work wonders for you, too!

167
147
2K
0
26
394
@savvyRL
I totally agree, but I hope you understand that I am not responsible for hiring :)
Unfortunately I didn't have a chance to work closely with some of the great female co-workers except from one 20%er who did amazing work on PaLI-X - and it was her first time with research!
136
1
278
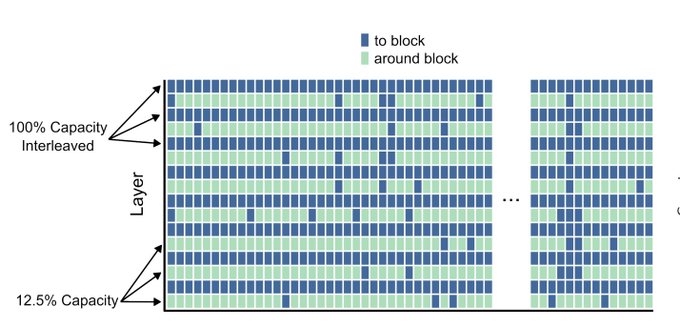
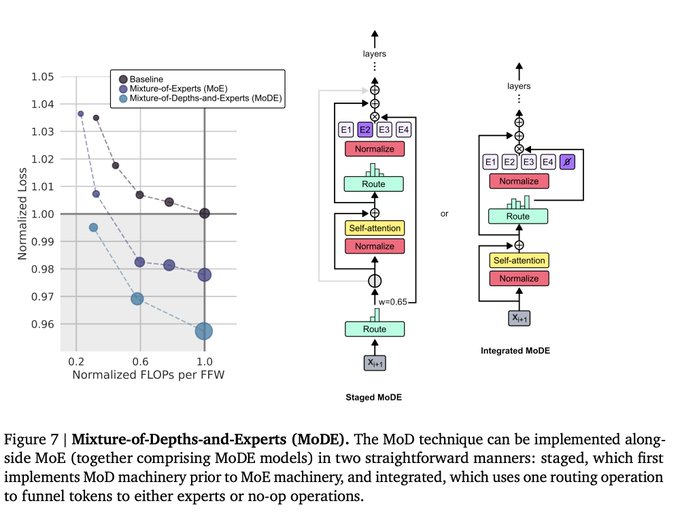
Mixture of Depths is an ingenious idea of scaling in depth dimension while keeping the flops constant - similarly how MoE does it in width.
This way the model can learn to route harder tokens through more layers (similarly how experts in MoE can specialize to certain domains):
6
38
267

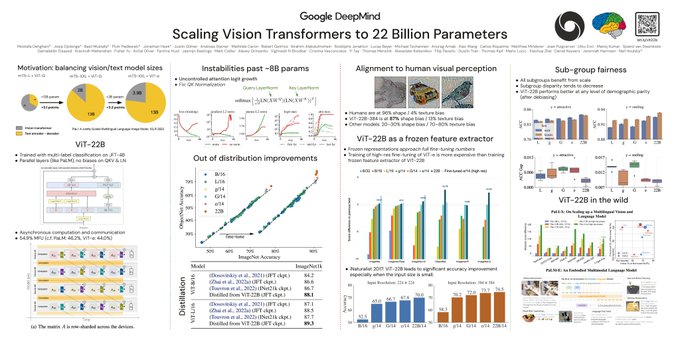
Delighted to share something I was focusing on heavily - Scaling Vision Transformers to 22 billion parameters
ViT-22B brings best of architectural choices and recipes from previous language and vision transformers for an encoder only model. (1/5)

3
25
127
What happens if ViT-22B meets 32B UL2 language model?
In PaLI-X: On Scaling up a Multilingual Vision and Language Model
we present scaled up version of PaLI having new capabilities, more benchmarks and new SOTA results.
Quick thread 1/n

1
29
118
Model evals are hard, that is why we are shedding some light on how we do it at Reka.
Along with the paper, we are releasing a dataset of challenging prompts with a golden reference and evaluation protocol using Reka Core as a judge.
Evals are notoriously difficult to get right but necessary to move the field forward. 🌟
As part of our commitment to science, we’re releasing a subset of our internal evals. 🙌
Vibe-Eval is an open and hard benchmark comprising 269 image-text prompts for measuring the

7
41
190
3
9
92
We are starting early access to Reka Core. LMK if you want to play with it
25
9
81
Won't spoil the next steps, but I can say that it has to do with AGI and a ferociously strong team :)
1
1
78
I will be at ICML presenting ViT-22B!
Feel free to grab me if you want to chat about it.
3
12
61
Do you want to accelerate your vision model without losing quality?
NaViT takes images of arbitrary resolutions and aspect ratios - no more resizing to square with constant resolution.
One cool implication is that you can control compute/quality tradeoff by resizing:

Patch n' Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution
paper page:
The ubiquitous and demonstrably suboptimal choice of resizing images to a fixed resolution before processing them with computer vision models has not yet been

2
52
229
2
11
57
@giffmana
@m__dehghani
@neilhoulsby
@_basilM
I really enjoyed the fact that you were always very direct in giving constructive feedback in a respectable way. But also easily convincible with sound arguments.
Most people don't care or they are afraid to hurt feelings.
2
0
41
tfw you are gpu rich but Jensen's inequality strikes again and you are gpu poor again
2
0
37
Quick summary of our recent work on scaling Vision Transformers - solving stability issues, making training more efficient and cool results:
1
8
33
- mom can we have sama?
-we have sama at home.
sama at home:
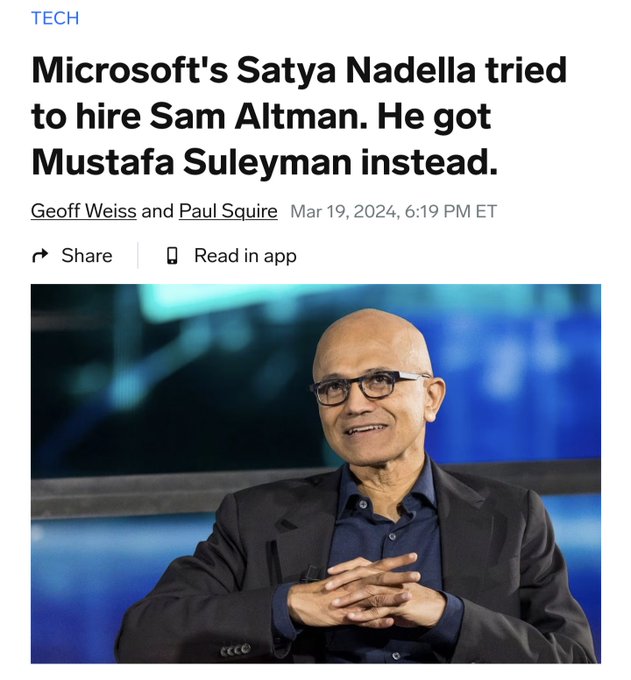
1
3
33
We are just starting 🔥

Exciting update - the latest leaderboard result is here!
We have collected fresh 30K votes for three new strong models from
@RekaAILabs
Reka Core and
@Alibaba_Qwen
Qwen Max/110B!
Reka Core has climbed to the 7th spot, matching Claude-3 Sonnet and almost Llama-3 70B! Meanwhile,
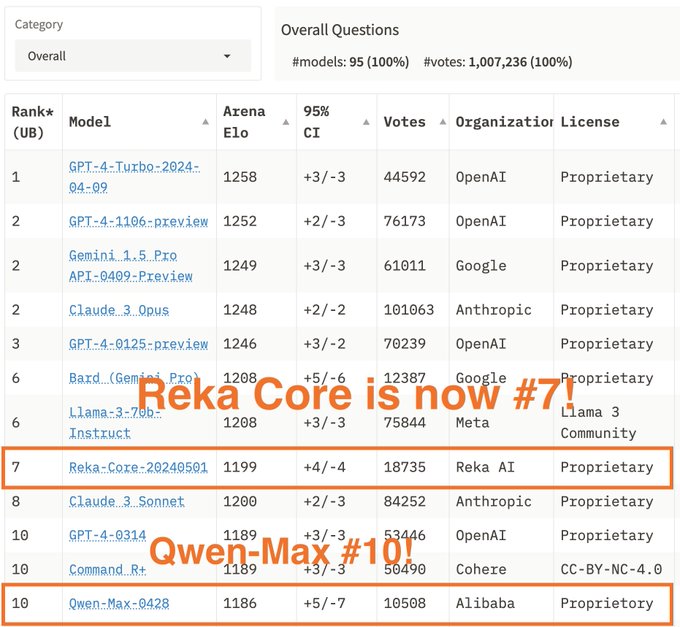
12
48
289
2
0
33
It's official now: I am delighted to inform that in the summer I will start working at
@GoogleAI
in Zurich Full time!
3
1
31
TL;DR I was too lazy to keep a fork of MHA, and I was too tired of my exps blowing up due to too high LR.
I am still amazed how useful this is even for small models - I can pre-train [Na]-ViT with 1e-2 (previously it blew up at ~5e-3).
Try it out!
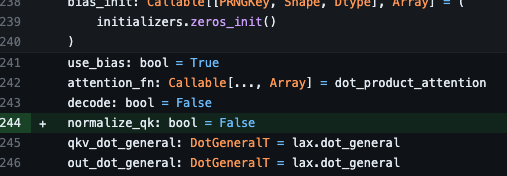
1
5
30

Meet Reka Core, our best and most capable multimodal language model yet. 🔮
It’s been a busy few months training this model and we are glad to finally ship it! 💪
Core has a lot of capabilities, and one of them is understanding video --- let’s see what Core thinks of the 3 body
54
238
1K
2
1
30
C++ IDE feature request: change colors of arguments passed
as non-const reference. This way it is much simpler to see what is being modified without a need for conventions -- like using pointers instead of
references (google coding style). CC
@clion_ide
@visualc
4
1
30

Authors found that routing ⅛ tokens through every second layer worked the best. They also make an observation that the cost of attention for those layers decreases quadratically, so this could be an interesting way of making ultra long context length much faster.
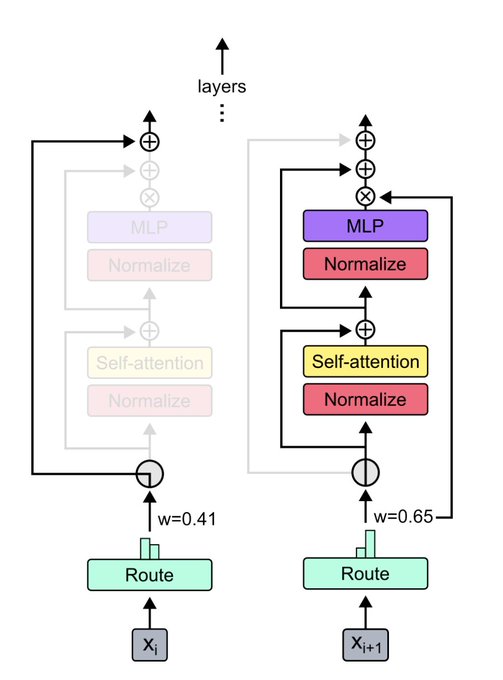
1
1
25
I am very happy I joined few months ago to be part of it.
We are live on

Introducing Reka Flash, our efficient and highly capable multimodal language model.
Try it at Reka playground 🛝 for free today.
🧵 Thread, blog & links below 👇
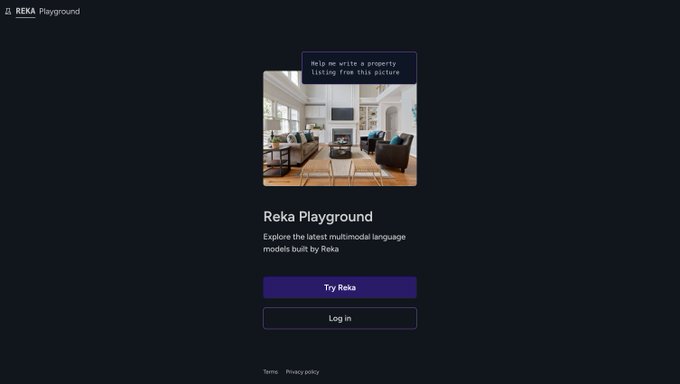
13
46
259
0
0
24

Finally the proposal for sound C++ Devirtualization for LLVM is here:
0
6
23


Gemini flash? Lol really?
Good to know I'm still contributing to google names after being a xoogler for some time. 🤔
6
1
101
1
0
21
Some compute providers are built differently ¯\_(ツ)_/��


Blogpost link:
Happy to hear feedback. I may get back to blogging more in general so ideas would also be welcome! 😄
12
58
396
1
0
21
With great leg room comes great responaibility.
Flying to SF to start my internship in Google Brain!

4
0
19
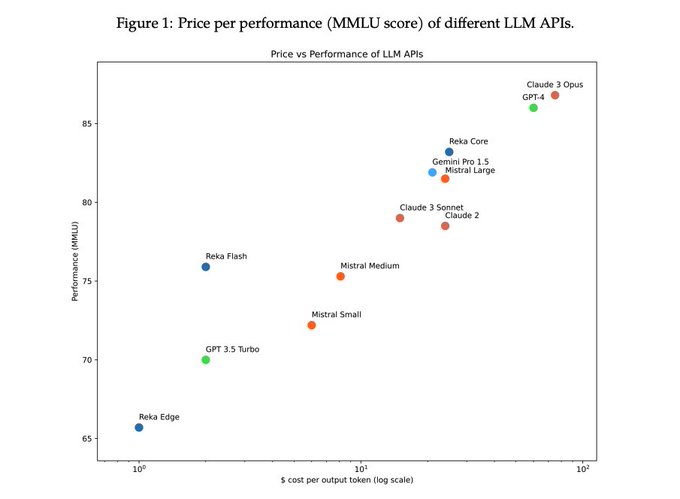
Finishing, here is nice plot comparing performance (MMLU) vs cost.
Notice the cost is in log scale - Core cost $10/$25 for milion input/output tokens, while Opus is $15/$75
3
4
19
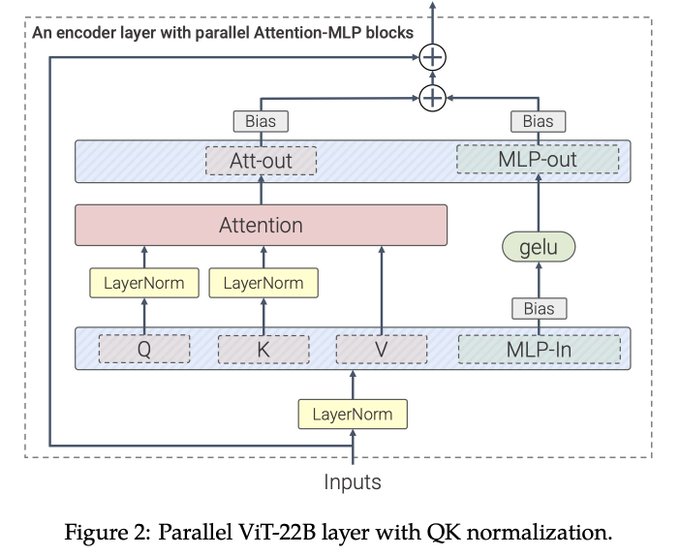
The first modification to the architecture is the use of Parallel layers like PaLM. In general it lets us do more flops in parallel, but it also gives the compiler more opportunities for optimizations, like fusion. (2/n)
1
1
16


1
3
16
One thing to keep in mind is that benefits in inference time might be limited to batch_size=1, as the bs grows, there is higher probability that one example will route with extra layers (for which other examples need to wait). May be solved with ideas like MoT(mixture of tokens)?
3
0
15
@chandlerc1024
@shafikyaghmour
@lefticus
@lunasorcery
@dascandy42
@mattgodbolt
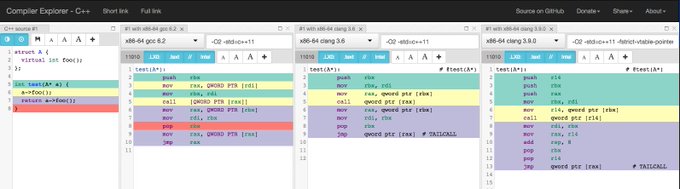
Yes, it is safe to assume this, and this is wxact what happens with -fstrict-vtable-pointers in clang. As far as legality goes:
@zygoloid
said we can do so I guess we can do so
2
0
14
@giffmana
@boazbaraktcs
One could say her tweets could use a bit of peer review before publishing
2
0
15
@johnregehr
This one is particularly fun if you turn on NDEBUG
if (a == 42)
doSomething();
else
assert(false && "a should be 42");
otherCode();
5
1
13
@m__dehghani
@_basilM
@GoogleAI
@neilhoulsby
@JonathanHeek
Secondly, ViT-22B omits biases QKV projections and LayerNorms, which increase utilization by 3%. In comparison, biases make up around 0.1% of total weights of large models. The non proportional cost of training biases comes from linear scaling in bandwidth connectivity: (3/5)
1
0
14
Essentially everyone from out team contributed with lots of pictures making (what we thought) will be hard questions. This also means that most of the pictures were not in any of the training sets (maybe apart from memes).
I think all of the sign recognitions were from me, which
2
0
13
Lastly, we normalize outputs Queries and Keys - QK Normalizations. This change was essential for training Vision Transformers of such scale - even with 8B parameters numerical issues caused training instabilities without this change. (5/5)

Pop quiz: Why must we reduce learning rate as we scale transformers?
@jmgilmer
has the answer - and the solution!
Attention logits can grow uncontrollably, destabilizing training. The fix: Layer norm on queries and keys!
(Follow Justin and 👀 for upcoming paper on this topic!)
11
27
210
1
0
12
We also found some interesting examples showing inverse scaling for multimodal models - it seems that the more knowledge VLM has, it is more biased towards answers that are more likely from the language alone, ignoring the content of the image.

2
0
12
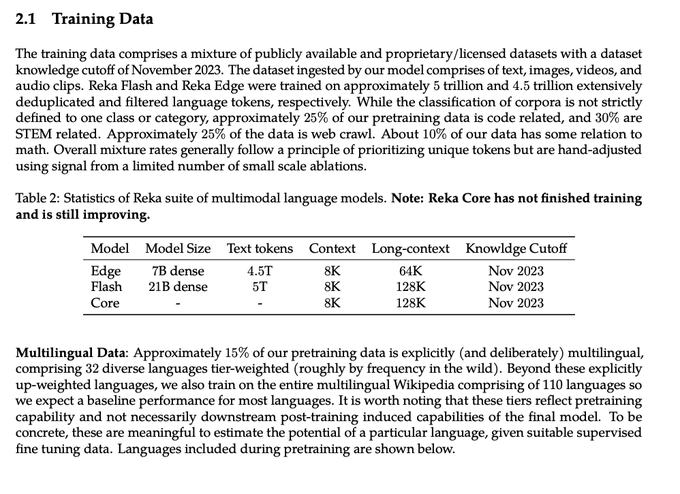
Quick summary of Reka Core:
- Edge and Flash are dense models
- 7B and 21B trained for 4.5T and 5T tokens.
- trained on 8k context, supporting 64k and 128k long-context
- text mixture: 25% code, 30% stem, 25% web crawl, 10% math (those percents are not disjoint)
- pretrained on
2
1
12
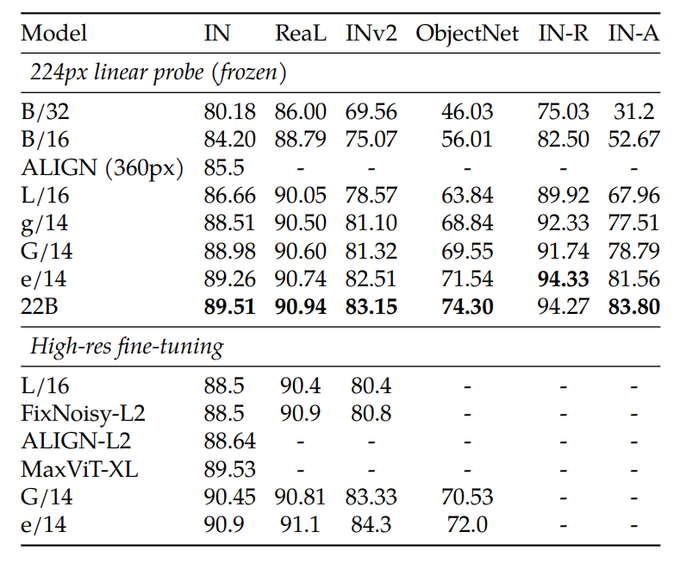
What is pretty mind blowing to me is that training a linear probe of 22B is cheaper than high resolution full fine-tuning of ViT-e (4B), while the results are pretty close. This makes it so much easier to use, and you can even precompute embeddings!

One thing that
@__kolesnikov__
and I looked at in the context of ViT-22B () is linear probes.
The headline number: linear probe on ImageNet gets 89.51%, that outperforms most existing models fine-tuned.
Raw i1k is slowing down, but generalization is not!
1
5
50
2
0
12
To improve efficiency of training we also heavily optimized sharding of the model, as well as the implementation (Asynchronous Parallel Linear operations). Just that last trick alone made the training 2x faster!

1/ ViT22B uses an asynchronous parallel linear operation “that can be configured differently for different parts of transformer blocks”, letting us maximize the throughput through overlapping computation and communication ().
1
4
24
1
0
11
ViT-22B used for robotics!

What happens when we train the largest vision-language model and add in robot experiences?
The result is PaLM-E 🌴🤖, a 562-billion parameter, general-purpose, embodied visual-language generalist - across robotics, vision, and language.
Website:
32
525
2K
0
0
11
@BartoszMilewski
I think it is a more about culture of scam, similar to not pricing in sales tax, or pretending the price is lower with hidden extra fees.
1
0
11
My first ever blog post.
Thanks for Krzysztof Pszeniczny for reviewing!
0
4
10
I am excited to share that Devirtualization in clang (-fstrict-vtable-pointers) shows overall 0.8% speedup on a range of benchmarks!
For more check out my and
@KPszeniczny
slides from
@llvmorg
dev meeting
0
1
10
Its perplexing to me why Spotify and Tidal are so bad.
Literally the only thing I am expecting is streaming music without interruptions. Bonus points for not forgetting songs that I already liked, using less that 2GB or RAM.
2
0
10
Men will do anything but fix windows explorer search.

Satya Nadella says Windows PCs will have a photographic memory feature called Recall that will remember and understand everything you do on your computer by taking constant screenshots
5K
4K
11K
2
0
10
Iceland really feels like another planet. In 9 days I've seen an active volcano, glacier with ice caves, northern lights, geyser and a lot more. Incredible.




1
1
10
Using only food, where did you grow up?








3
1
9
Doing some experiments with devirtualization on
@mattgodbolt
compiler explorer.
Comparing output is so awesome!
0
5
9
Addition of N biases requires N flops and transferring N numbers, whereas multiplication of matrices of size N^2 requires N^3 flops and transferring N^2 numbers. Omitting biases for QKV and LayerNorms can be done without losing quality. (4/5)
1
0
9
Friend sent me the most recent computerphile video, here is my short rant:
Claim: scaling will not lead to AGI, because you need exponential amounts of data to understand concepts better.
Premise: paper titled: No "Zero-Shot" Without Exponential Data: Pretraining Concept
0
0
9
@shafikyaghmour
These questions be like "without checking, what is the value of x <insert code for x = fibonacci(257229471) ^ 47382627284 *63826282>
1
0
9
One problem that they faced is sampling, since routing is done in the sequence dimension, it is based on the future tokens. They proposed two workarounds, one of them being a small predictor based on logits (based only on previous tokens) to predict the decisions of the router

1
1
9
Google is using thousands of machines, each probably costing 10k (10M total) just to serve a couple of queries for you.

There are only 2 possibilities:
1. GPT-4 is a 2T model and OpenAI uses an entire node of 8xH100 (that costs $400,000) to serve the inference just for you for $20/month.
or
2. GPT-4 is a model that is 10 times smaller (it cannot be smaller than 200B) and OpenAI uses one H100
167
84
948
1
0
8


My paper finally got published
We will see how the second round of Splash SRC will go.
2
0
8
Googlers! I am looking for interesting internship project in US for this summer. Interested in
- compilers
- performance
- machine learning
- blockchain
1
4
8
🤯


We're excited to announce DOCCI: A new dataset designed to advance vision-language research. DOCCI features 15k images with detailed descriptions crafted to capture complex visual concepts – spatial relations, counting, text and entities more.

4
38
237
2
0
8
Mixture of Depths is an ingenious idea of scaling in depth dimension while keeping the flops constant - similarly how MoE does it in width.
This way the model can learn to route harder tokens through more layers (similarly how experts in MoE can specialize to certain domains):
6
38
267
1
0
8
They also found that technique is complementary to MoE and can be easily combined - for example by having no-op expert
1
0
8
Thanks everyone for helping! This summer I will do some work on
@TensorFlow
in
@GoogleBrain
in Mountain View
Googlers! I am looking for interesting internship project in US for this summer. Interested in
- compilers
- performance
- machine learning
- blockchain
1
4
8
0
0
7
While digging into devirtualization I found this weird C++11 quirk
What will be printed?
AB
10
BB
4
AA
3
maybe Undefined behavior
29
3
0
7
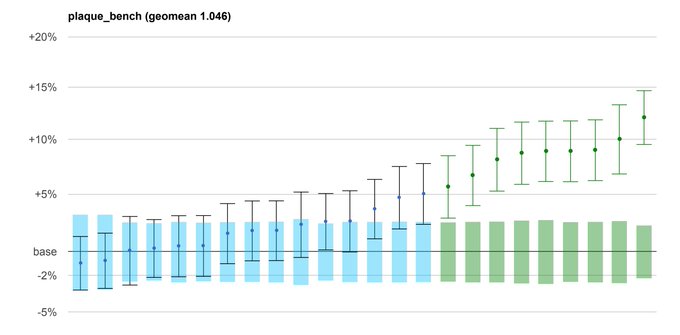
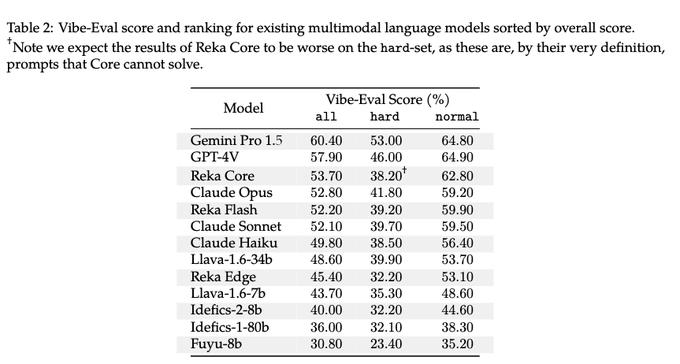
Overall, we found that Gemini Pro 1.5 does the best on hard subset of prompts, while GPT-4V is slightly better on normal category.
Reka and Anthropic models came out in the similar tier, but note that Core is nerfed here as hard prompts were designed to fail it.
1
0
7
@giffmana
Same, I know this Belgian dude that is a professional shitposter on Twitter, but in his free time he writes goated computer vision papers
1
0
7
Infra:
- pytorch (sorry JAX, maybe next time <3)
- peak 2.5k H100 and 2.5k A100 starting in Dec 23
- Ceph filesystem
- Kubernetes
- interesting graph about stability of compute providers (extending
@YiTayML
hardware lottery)
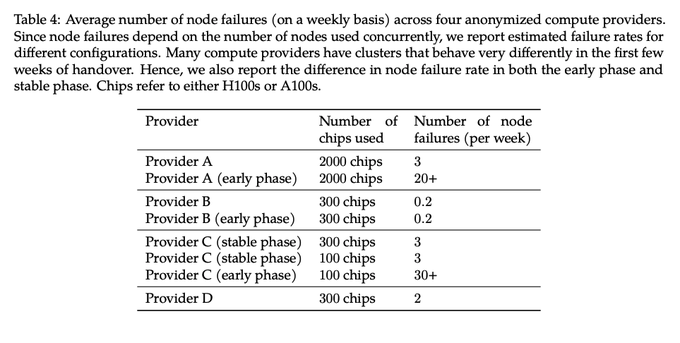
1
0
7
The bigger image you have, the more accurate prediction becomes.
By sacrificing 1% of accuracy your model can run 6x faster! Remember that this does not require any retraining because the model works with any resolution
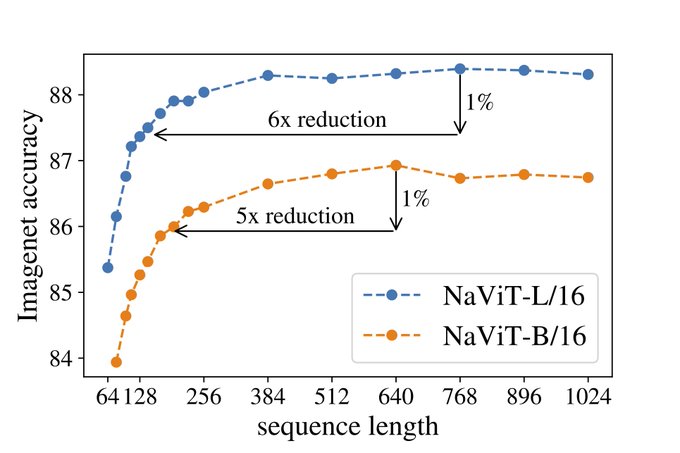
2
0
7
For text only we are between Opus and Sonnet, but higher than initial GPT4 (which was our goal for Q1)
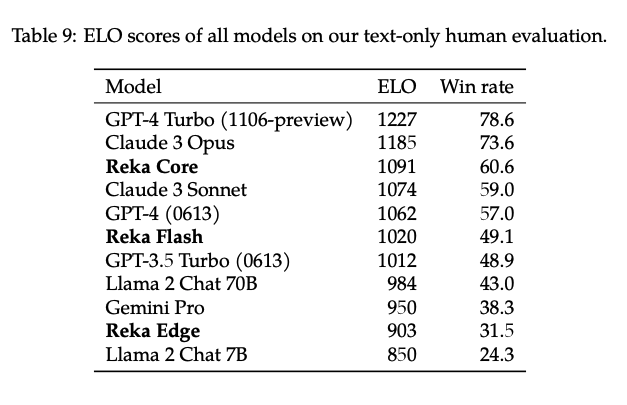
1
0
7
Hanabi is great, but Hanabi and set simultaneously is more fun

1
0
6
For B/L model sizes the runtime scales pretty much linearly with the sequence.
Comparing performance of those two shows that it is probably better to run L with smaller images than B with bigger ones (lower latency with higher quality).
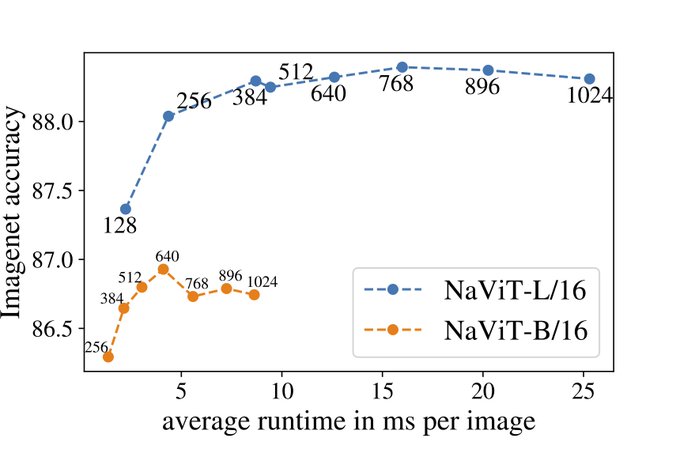
1
0
6
Fun fact: when you decide to cite Gemini tech report in your paper, 1/4 of it becomes Gemini as it takes 3 pages of authors.
1
0
6

@RickLamers
@alexgraveley
This is what I got:
Note that we didn't train it to do geoguesser, but you should expect that its good on famous landmarks. In general we don't want our model to enable stalkers
2
0
6
NaViT achieves much better quality for smaller resolutions compared to ViT.
For example NaViT-L/16 at resolution 384x384 is better than ViT-L/16 at resolution 512x512.
This means that in some cases NaViT is 2x faster to run! (Note that 384res = 576 tokens and 512res = 1024)
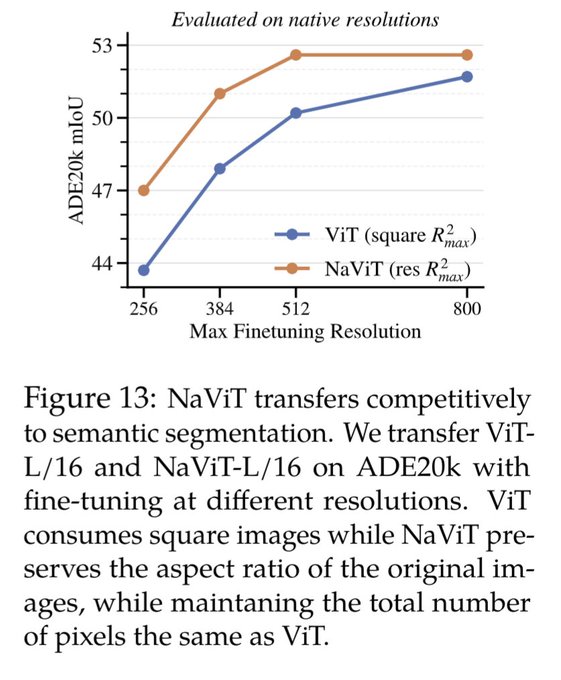
1
0
6
Last week a had a chance to visit
@zipline
in Rwanda and see a autonomous drones saving people's lives.
The package with medical materials (like blood) is packed within a minute after receiving an emergency. Within the next minute the drone is in the air at ~100km/h.



1
0
6
Vibe-Eval consist of 169 "normal" prompts and 100 prompts that were designed to make Reka Core fail. Here are some examples (and more can be seen in )



1
0
6


@YiTayML
@RekaAILabs
Openness (in publishing) and honesty (in recognizing
@RekaAILabs
is not the best yet). What a breath of fresh air compared to all the hype. And a great set of evals too!
1
1
17
0
0
6
Other method of reducing compute is dropping random tokens. This turned out to be much worse strategy, as the quality drops much faster
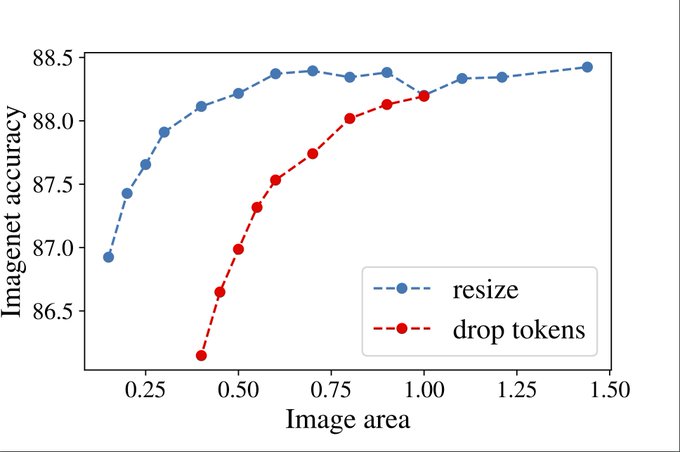
1
0
6
@giffmana
Do they define FLOP to be 32? Or does vector instructions count as one floating point operation? If not, they might get FMADD quickly
1
0
5

The architecture is the same as for PaLI:
1) ViT encodes patches of images ->
2) the embedding shape is adapted so it matches shape of text embeddings with FC layer
3) encoded patches are passed along with encoded tokens to enc-dec LLM
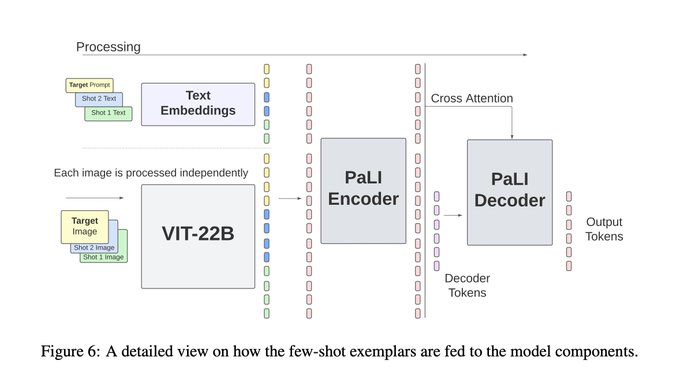
1
1
6