
Michael Tschannen
@mtschannen
Followers
3K
Following
673
Media
23
Statuses
245
Research Scientist @GoogleDeepMind. Representation learning for multimodal understanding and generation. Personal account.
Zurich, Switzerland
Joined June 2012
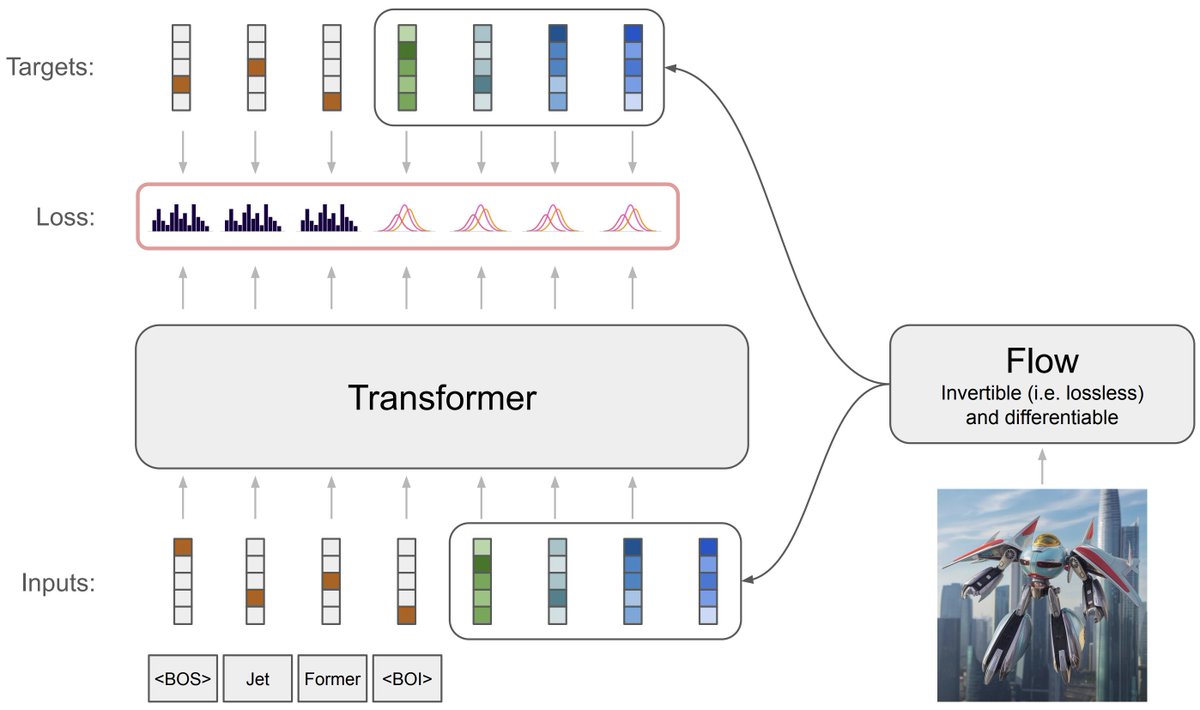
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?. We have been pondering this during summer and developed a new model: JetFormer 🌊🤖. A thread 👇. 1/
15
142
839
📢 We just released the code for JetFormer at. Enjoy!.
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?. We have been pondering this during summer and developed a new model: JetFormer 🌊🤖. A thread 👇. 1/
5
61
313
RT @MarioLucic_: Massive advancements in video understanding with Gemini 2.5! ✨ Unlock new capabilities to process hours of video, summariz….
0
2
0
We are presenting JetFormer at ICLR this morning, poster #190. Stop by if you’re interested in unified multimodal architectures!.
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?. We have been pondering this during summer and developed a new model: JetFormer 🌊🤖. A thread 👇. 1/
6
30
223
4o native image generation is confirmed to be some sort of autoregressive model. Maybe this is a good moment for AR skeptics to catch up on the recent literature on multimodal AR models.

7
35
268
RT @GoogleDeepMind: Think you know Gemini? 🤔 Think again. Meet Gemini 2.5: our most intelligent model 💡 The first release is Pro Experimen….
0
520
0
RT @osanseviero: I’m so happy to announce Gemma 3 is out! 🚀. 🌏Understands over 140 languages.👀Multimodal with image and video input.🤯LMAren….
0
444
0
RT @andrefaraujo: Excited to release a super capable family of image-text models from our TIPS #ICLR2025 paper! We….

github.com
Contribute to google-deepmind/tips development by creating an account on GitHub.
0
6
0
RT @visheratin: SigLIP2 is indeed a better encoder than SigLIP! Over the last two weekends, I trained a new SOTA multilingual model - mexma….
0
20
0
RT @borisdayma: Caught up on the new SigLip 2 paper 🤓. Cool things I learnt from it:. - finally using patch size of 16 with size multiple o….
0
8
0
HF model collection for transformers:. HF model collection for OpenCLIP and timm:. And of course big_vision checkpoints:.
github.com
Official codebase used to develop Vision Transformer, SigLIP, MLP-Mixer, LiT and more. - google-research/big_vision
0
1
6
Paper:. HF blog post from @ariG23498 et al. with a gentle intro to the training recipe and a demo:. Thread with results overview from @XiaohuaZhai:.

huggingface.co

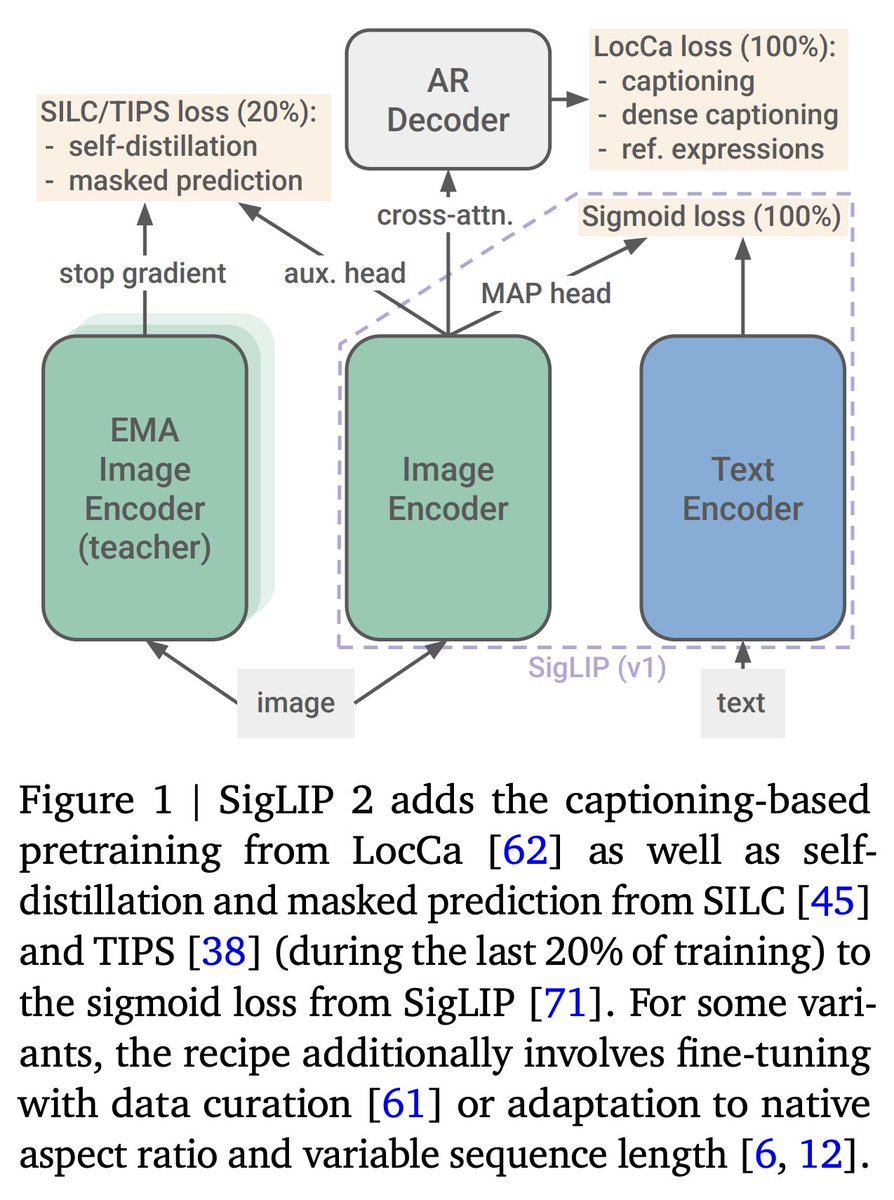
Introducing SigLIP2: now trained with additional captioning and self-supervised losses!. Stronger everywhere: .- multilingual.- cls. / ret. - localization.- ocr.- captioning / vqa. Try it out, backward compatible!. Models: Paper:

1
1
9
📢2⃣ Yesterday we released SigLIP 2! . TL;DR: Improved high-level semantics, localization, dense features, and multilingual capabilities via drop-in replacement for v1. Bonus: Variants supporting native aspect and variable sequence length. A thread with interesting resources👇
5
34
169
RT @_akhaliq: Google just dropped SigLIP 2. Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and D….
0
68
0
RT @ariG23498: Did @Google just release a better version of SigLIP?. SigLIP 2 is out on Hugging Face!. A new family of multilingual vision-….
0
20
0
RT @mervenoyann: SigLIP 2 is the most powerful image-text encoder. you can use it to do.> image-to-image search.> text-to-image-search.> im….
0
79
0
RT @iScienceLuvr: This is exciting. SigLIP was one of the best, highly performant image encoders used for a variety of applications, so….
0
24
0
RT @arankomatsuzaki: Google presents:. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization,….
0
67
0
RT @googleaidevs: PaliGemma 2 mix is an upgraded vision-language model that supports image captioning, OCR, image Q&A, object detection, an….
0
110
0