

Elias Frantar
@elias_frantar
Followers
509
Following
1K
Media
26
Statuses
77
Researcher @OpenAI | prev. PhD @ISTAustria and intern @GoogleDeepmind | I also build super fast Lego Rubik's Cube robots.
San Francisco, CA
Joined February 2015
Excited to share our work "Scaling Laws for Sparsely-Connected Foundation Models" ( https://t.co/KGJ3kGpL1n) where we develop the first scaling laws for (fine-grained) parameter-sparsity in the context of modern Transformers trained on massive datasets. 1/10

arxiv.org
We explore the impact of parameter sparsity on the scaling behavior of Transformers trained on massive datasets (i.e., "foundation models"), in both vision and language domains. In this setting,...
3
25
124

👏 Give a big round of applause to our 2025 PhD Award Winners! The two main winners are: @ZhijingJin & @maksym_andr. Two runners-up were selected additionally: @SiweiZhang13 & @elias_frantar Learn even more about each outstanding scientist: https://t.co/3Pry7NnAYn
2
5
43

Happy to release the write-up on the MARLIN kernel for fast LLM inference, now supporting 2:4 sparsity! Led by @elias_frantar & @RobertoL_Castro Paper: https://t.co/lT6EtMoyEY Code: https://t.co/r58fIm8zWB MARLIN is integrated with @vllm_project thanks to @neuralmagic!
github.com
Boosting 4-bit inference kernels with 2:4 Sparsity - IST-DASLab/Sparse-Marlin
3
22
73

AutoGPTQ 0.7.0 is released and includes @elias_frantar's Marlin kernel for int4*fp16 matrix multiplication on Ampere GPUs. Check out https://t.co/UAwJCfaGp8 - This is usable with any int4 quantized Transformers model (symmetric quantization, no act-order) directly from the Hub!🧵

github.com
Marlin efficient int4*fp16 kernel on Ampere GPUs, AWQ checkpoints loading @efrantar, GPTQ author, released Marlin, an optimized CUDA kernel for Ampere GPUs for int4*fp16 matrix multiplication, with...
1
8
24
@DAlistarh and I hope that Marlin will help to unlock the full potential of 4-bit inference for open-source models, now also in settings that require batchsizes significantly larger than 1!
1
0
7
Marlin achieves its speed by simultaneously saturating global/L2/shared/tensor/vector performance via careful organization of computations, several levels of software-pipelining, ideal memory access patterns and generally extremely optimized (down to assembly level) code. 5/N
1
0
10
Further, we demonstrate how to create accurate Marlin-compatible models using an improved version of GPTQ, with better grid-clipping and non-uniform calibration sample length (WikiText2 and RedPajama are PPL and MMLU 0-shot below). 4/N
1
0
8
We also test performance that is sustainable over longer periods of time, thus forcing base clocks. Interestingly, we find that existing kernels lose significant performance if clocks must be lowered from boost due to continuous load; meanwhile, Marlin remains almost optimal. 3/N
1
0
8
Due to its "striped" partitioning scheme, which evenly balances (not necessarily consecutive) tiles across all SMs, Marlin delivers strong performance across most matrix shapes of popular models and GPUs. 2/N
1
0
8
Happy to release Marlin, a 4bitx16bit linear kernel for LLM inference with near-ideal (4x) speedup up to batchsizes of 16-32 tokens (4-8x bigger than prior work); aimed at larger-scale serving, speculative decoding, and multi-way inference schemes. 1/N https://t.co/Ro4oBWThZB
8
56
254
Happy to release QUIK, a new accurate post-training quantization method which processes the majority of weights and activations using 4bit precision. [1/N] With @AshkboosSaleh @elias_frantar @thoefler Paper: https://t.co/ErRgJ9Wnqw Code: https://t.co/WuAzZn3ugX Snapshot:
7
37
158
We hope that QMoE will make deployment of and research with massive MoEs cheaper and more accessible. Work done together with @DAlistarh at @ISTAustria! 8/8
0
0
1
With QMoE compression and kernels we can perform full end-to-end inference of the 1.6 trillion parameter SwitchTransformer-c2048 on 4x A6000 or 8x 3090 GPUs, at < 5% overhead relative to (ideal) uncompressed execution (requiring ~20x more GPUs). 7/8
1
0
1
Doing this in a way that allows fast on-the-fly decoding during GPU inference requires very careful co-design of a custom compression format and corresponding bespoke GPU kernels, to efficiently handle various issues introduced by variable-length codes. 6/8
1
0
1
Such highly compressed models also exhibit high natural sparsity, and correspondingly low entropy, which we can exploit to push compression rates even more, to < 1-bit per parameter. 5/8
1
0
1
With the help of this framework, we notice that such massive models can actually be compressed significantly further than standard dense models, to 2-bit or even ternary precision, at only a small accuracy loss. 4/8
1
0
1
Applying accurate compression methods like GPTQ to trillion-parameter MoEs is challenging and requires a variety of systems optimizations around memory management, compute utilization and (numerical) robustness. 3/8
1
0
1
Mixture of Expert (MoE) models are significantly faster than dense models of the same accuracy. However, they are also much larger, which limits their practicality. We address this challenge via QMoE with sub-1-bit compression. 2/8
1
0
2
Excited to announce QMoE, the first framework able to accurately compress a 1.6 trillion parameter model, by 20x = 0.8 bits per parameter, to run on 4 GPUs at close to no overhead over uncompressed inference. Paper: https://t.co/moTdmYsQDz GitHub: https://t.co/7WeAwDHHSy 🧵1/8

github.com
Code for the paper "QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models". - IST-DASLab/qmoe
3
25
111
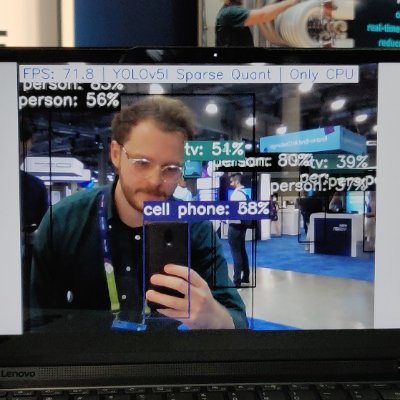
Exciting news from our latest LLM compression research! 🚀 Together with @ISTAustria and @neuralmagic, we’ve been exploring sparse finetuning for LLMs and achieved 7.7 tokens/second on a single core and at 26.7 tokens/second on 4 cores of an AMD Ryzen CPU! (1/n)
5
40
146
This paper is a result of my internship at Google DeepMind and is joint work with @rikelhood @neilhoulsby @DAlistarh and @utkuevci.
0
0
7