
(V-)MoEs working well at the small end of the scale spectrum. Often we actually saw the largest gains with small models so it's a promising direction.
Also, the authors seem to have per-image routing working well, which is nice.

Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts
paper page:
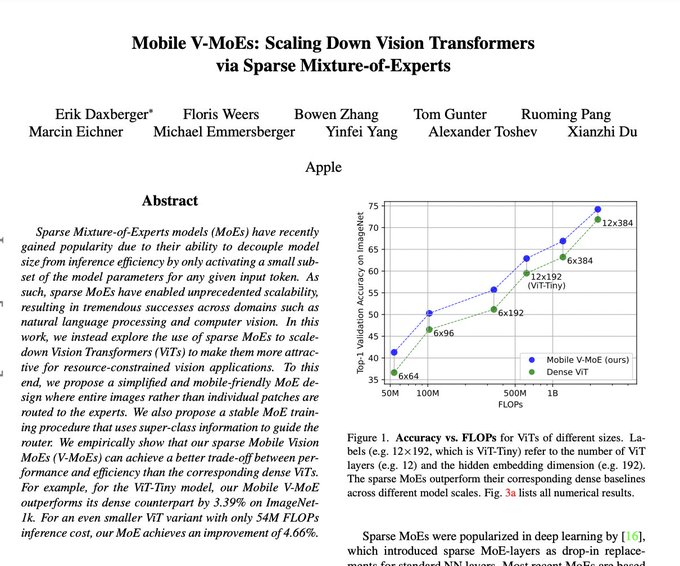
Sparse Mixture-of-Experts models (MoEs) have recently gained popularity due to their ability to decouple model size from inference efficiency by only activating a…
2
55
238
1
5
47
Replies

@neilhoulsby
@_akhaliq
Does 5% gain seem worth the incredible amount of additional complexity?
0
0
1