
PaLI-X () continued the joint vision / language scaling approach from PaLI (using ViT-22B and UL2-32B), with an updated pre-training mix.
Aside from good benchmark numbers, a few results I found most intriguing…

2
34
127
Replies
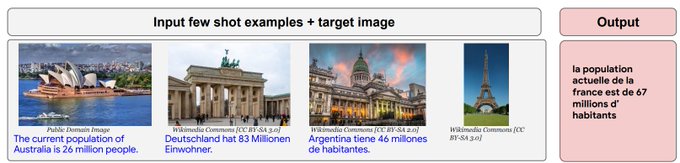
In-context / few-shot captioning worked in diverse scenarios absent (or present only in minute quantities) in the training mix.
In this e.g., PaLI-X must infer the location from the prompt, respond in the appropriate language, and combine with "world knowledge".
1
0
14
For object detection, performance on common objects was reasonable, but relatively, rare objects performed much better.
Concepts not explicit in the OD mix were handled: left vs. right, OCR, singular vs. plural, and multilingual. Encouraging positive transfer from pre-training.

1
0
11
Counting was not an explicit pre-training task, but performance really started to take off around 17B+ parameters, especially on the "complex" variety (counting some described subset of objects).

1
0
15
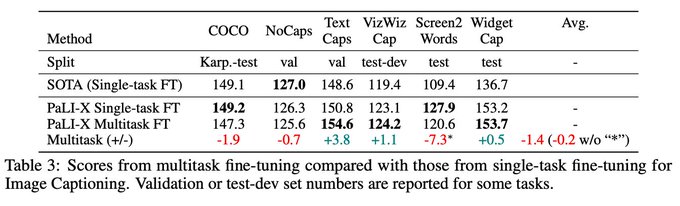
Finally, multitask finetuning, without fancy task-specific prompting, was almost on par with tuned task-specific finetuning. Quite encouraging for potential future work on massively-multitask finetuning of V&L models.
0
0
14
